Recognition: 2 theorem links
· Lean TheoremLearning-Augmented Scalable Linear Assignment Problem Optimization via Neural Dual Warm-Starts
Pith reviewed 2026-05-12 03:17 UTC · model grok-4.3
The pith
A neural network predicts dual variables to warm-start exact solvers for the linear assignment problem, achieving over 2x speedups while guaranteeing optimality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
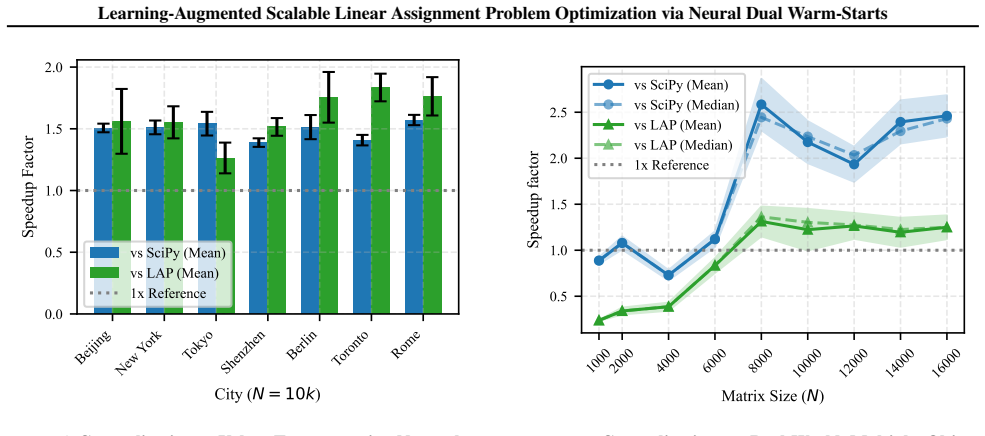
Predicting dual variables with RowDualNet allows the Jonker-Volgenant algorithm to find optimal assignments with significantly reduced search effort, delivering over 2× speedups on synthetic distributions and 1.25× to 1.5× improvements on real-world MOT tracking and LPT transportation datasets, all while preserving full optimality through a fallback mechanism and enabling scaling to N=16,384.
What carries the argument
RowDualNet, a row-independent neural network that predicts dual variables for each assignment row separately, together with the Min-Trick that constructs feasible duals from LP duality to warm-start the solver.
If this is right
- Classical exact solvers can be made faster on large LAP instances without any loss of optimality.
- The approach scales to problems with 16,384 variables due to linear memory usage.
- Robust zero-shot performance is achieved on real-world datasets from tracking and transportation.
- Worst-case runtime guarantees are maintained via the fallback when predictions are poor.
- Search effort in the solver is reduced on challenging synthetic distributions.
Where Pith is reading between the lines
- This method could extend to accelerating other primal-dual based combinatorial optimization algorithms.
- Hybrid learning-exact approaches like this may become standard for balancing speed and guarantees in optimization.
- Further gains might come from training the network on more diverse distributions or integrating it with adaptive solvers.
- Applications in dynamic or online assignment settings could benefit from the fast warm-starting.
Load-bearing premise
That the dual variable predictions are accurate enough on new, unseen problem distributions to reduce the solver's internal search steps enough to offset the cost of running the network.
What would settle it
A set of large-scale LAP instances from a new distribution where the total runtime of the neural warm-start method equals or exceeds the runtime of the unassisted LAPJV solver.
Figures









read the original abstract
The Linear Assignment Problem (LAP) is a fundamental combinatorial optimization task with applications ranging from computer vision to logistics. Classical exact solvers such as the Hungarian and Jonker-Volgenant (LAPJV) algorithms guarantee optimality, but their cubic time complexity $\mathcal{O}(N^{3})$ becomes a bottleneck for large-scale instances. Recent learning-based approaches aim to replace these solvers with neural models, often sacrificing exactness or failing to scale due to memory constraints. We propose a learning-augmented framework that accelerates exact assignment solvers while maintaining optimality and worst-case guarantees. Our method predicts dual variables to warm-start a classical solver, with a fallback that prevents asymptotic runtime degradation when the learned advice is unreliable. We introduce RowDualNet, a lightweight row-independent architecture that avoids the $\mathcal{O}(N^{2})$ memory bottleneck of graph-based models, enabling neural warm-starting at large scale ($N=16{,}384$). Feasibility is ensured via a constructive mechanism based on LP duality (namely, the Min-Trick), eliminating costly iterative projection. Empirically, our approach reduces the search effort of LAPJV and achieves over $2{\times}$ speedups on challenging synthetic distributions, in addition to improving over $1.25{\times}$ and $1.5{\times}$ on real-world tracking (MOT) and transportation (LPT) datasets, respectively, while strictly maintaining full optimality, effectively yielding a robust zero-shot generalization to real-world tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a learning-augmented framework for the Linear Assignment Problem that uses a lightweight, row-independent neural network (RowDualNet) to predict dual variables for warm-starting the LAPJV solver. A constructive Min-Trick adjustment ensures feasibility of the predicted duals, while a classical fallback mechanism guarantees optimality and prevents asymptotic slowdown. The approach is claimed to deliver >2× speedups on challenging synthetic distributions and 1.25–1.5× improvements on real-world MOT tracking and LPT transportation instances while preserving exact optimality and enabling zero-shot generalization.
Significance. If the empirical claims hold under closer scrutiny, the work provides a pragmatic bridge between learned heuristics and exact combinatorial solvers, preserving worst-case guarantees while scaling to N=16k instances. The row-independent architecture and non-iterative Min-Trick are concrete strengths that address memory and projection costs of prior graph-based methods. The fallback design is a positive example of robust learning-augmented optimization.
major comments (2)
- [Experiments] Experiments section: aggregate speedups are reported for MOT and LPT, yet the manuscript provides no statistics on fallback invocation frequency, post-Min-Trick duality gaps, or the correlation between per-instance prediction error and observed runtime reduction. Without these, it is impossible to determine whether RowDualNet consistently reduces LAPJV search effort on out-of-distribution data or whether gains are driven by a minority of instances.
- [Method] Method and § on RowDualNet: because the network predicts duals independently per row, the paper should quantify how well the resulting (Min-Trick-adjusted) duals approximate the optimal dual solution on real-world instances; an ablation relating prediction error to search-tree pruning would directly test the central assumption that learned advice reliably accelerates the solver before fallback.
minor comments (1)
- [Abstract] The abstract and introduction would benefit from a brief statement of the precise form of the fallback (e.g., when it triggers and what solver state is reused).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the work's significance, particularly the row-independent architecture, Min-Trick, and fallback mechanism. We address each major comment below and commit to revisions that strengthen the empirical support without altering the core claims.
read point-by-point responses
-
Referee: [Experiments] Experiments section: aggregate speedups are reported for MOT and LPT, yet the manuscript provides no statistics on fallback invocation frequency, post-Min-Trick duality gaps, or the correlation between per-instance prediction error and observed runtime reduction. Without these, it is impossible to determine whether RowDualNet consistently reduces LAPJV search effort on out-of-distribution data or whether gains are driven by a minority of instances.
Authors: We agree that these statistics would improve transparency and allow better assessment of consistency. In the revised manuscript we will add: (i) fallback invocation rates on MOT and LPT, (ii) average and worst-case duality gaps after the Min-Trick adjustment, and (iii) a per-instance correlation analysis (scatter plot and coefficient) between prediction error and runtime reduction. This will clarify whether speedups are broadly distributed or driven by outliers on the real-world tasks. revision: yes
-
Referee: [Method] Method and § on RowDualNet: because the network predicts duals independently per row, the paper should quantify how well the resulting (Min-Trick-adjusted) duals approximate the optimal dual solution on real-world instances; an ablation relating prediction error to search-tree pruning would directly test the central assumption that learned advice reliably accelerates the solver before fallback.
Authors: We acknowledge that an explicit quantification of approximation quality would directly support the central hypothesis. While the current manuscript prioritizes end-to-end runtime and optimality guarantees, the revision will include an ablation on the MOT and LPT instances that reports the duality gap between Min-Trick-adjusted predictions and true optimal duals, together with a correlation between prediction error and LAPJV search-tree metrics (nodes explored or pruned). This ablation will be placed in the experimental section or appendix. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper trains RowDualNet on synthetic data to predict dual variables, then empirically measures runtime reductions on held-out synthetic and real-world instances while using a classical fallback (LAPJV) to enforce optimality. Speedups are reported as measured outcomes on unseen distributions, not derived by construction from the training objective. The Min-Trick is presented as a direct constructive adjustment from LP duality theory, independent of the neural predictions. No self-definitional equations, fitted parameters renamed as predictions, or load-bearing self-citations that collapse the central claim were identified. The framework remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math The linear assignment problem admits a linear programming formulation with strong duality
invented entities (2)
-
RowDualNet
no independent evidence
-
Min-Trick
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose a learning-augmented framework that accelerates exact assignment solvers while maintaining optimality... RowDualNet, a lightweight row-independent architecture... Min-Trick: ˆvj = mini(Cij − ˆui)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The LAP is a fundamental combinatorial optimization task... cubic time complexity O(N³)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Michael Mitzenmacher and Sergei Vassilvitskii , title =. Commun
-
[2]
Learning Predictions for Algorithms with Predictions , booktitle =
Misha Khodak and Maria. Learning Predictions for Algorithms with Predictions , booktitle =
-
[3]
Binary Search with Distributional Predictions , booktitle =
Michael Dinitz and Sungjin Im and Thomas Lavastida and Benjamin Moseley and Aidin Niaparast and Sergei Vassilvitskii , editor =. Binary Search with Distributional Predictions , booktitle =
-
[4]
Algorithms with Prediction Portfolios , booktitle =
Michael Dinitz and Sungjin Im and Thomas Lavastida and Benjamin Moseley and Sergei Vassilvitskii , editor =. Algorithms with Prediction Portfolios , booktitle =
-
[5]
SeedGNN: Graph Neural Network for Supervised Seeded Graph Matching , booktitle =
Liren Yu and Jiaming Xu and Xiaojun Lin , editor =. SeedGNN: Graph Neural Network for Supervised Seeded Graph Matching , booktitle =
-
[6]
Proceedings of the 40th International Conference on Machine Learning (
Shinsaku Sakaue and Taihei Oki , title =. Proceedings of the 40th International Conference on Machine Learning (. 2023 , volume =
work page 2023
-
[7]
Approximation algorithms for combinatorial optimisation with predictions , booktitle =
Antonios Antoniadis and Marek Eli. Approximation algorithms for combinatorial optimisation with predictions , booktitle =
-
[8]
2025 , howpublished =
work page 2025
- [9]
-
[10]
Journal of mathematics and physics , IGNOREvolume=
The distribution of a product from several sources to numerous localities , author=. Journal of mathematics and physics , IGNOREvolume=. 1941 , publisher=
work page 1941
-
[11]
International Journal of Neural Systems , IGNOREvolume=
A graph-based neural approach to linear sum assignment problems , author=. International Journal of Neural Systems , IGNOREvolume=. 2024 , publisher=
work page 2024
-
[12]
International Conference on Data Mining (ICDM) , IGNOREpages=
Computing optimal assignments in linear time for approximate graph matching , author=. International Conference on Data Mining (ICDM) , IGNOREpages=. 2019 , IGNOREorganization=
work page 2019
-
[13]
Artificial intelligence and statistics (AISTATS) , IGNOREpages=
Exploring the power of graph neural networks in solving linear optimization problems , author=. Artificial intelligence and statistics (AISTATS) , IGNOREpages=. 2024 , IGNOREorganization=
work page 2024
-
[14]
Neural Information Processing Systems (
Faster matchings via learned duals , author=. Neural Information Processing Systems (
-
[15]
Pattern Recognition , IGNOREvolume=
GLAN: A graph-based linear assignment network , author=. Pattern Recognition , IGNOREvolume=. 2024 , publisher=
work page 2024
-
[16]
IEEE Robotics and Automation Letters , IGNOREvolume=
Graph neural network for decentralized multi-robot goal assignment , author=. IEEE Robotics and Automation Letters , IGNOREvolume=. 2024 , publisher=
work page 2024
-
[17]
HybridGNN: A Self-Supervised graph neural network for efficient maximum matching in bipartite graphs , author=. Symmetry , IGNOREvolume=. 2024 , publisher=
work page 2024
-
[18]
Autonomous Agents and Multiagent Systems (AAMAS) , IGNOREpages=
MAGNET: A Multi-Agent Graph Neural Network for Efficient Bipartite Task Assignment , author=. Autonomous Agents and Multiagent Systems (AAMAS) , IGNOREpages=
-
[19]
Results in Control and Optimization , IGNOREvolume=
New auction algorithms for the assignment problem and extensions , author=. Results in Control and Optimization , IGNOREvolume=. 2024 , publisher=
work page 2024
-
[20]
Solving Maximum Weighted Matching Problem Using Graph Neural Networks , author=. 2024 , school=
work page 2024
-
[21]
International Conference on Learning Representations (
Ziang Chen and Jialin Liu and Xinshang Wang and Wotao Yin , title =. International Conference on Learning Representations (
-
[22]
International Conference on Machine Learning (
Faster fundamental graph algorithms via learned predictions , author=. International Conference on Machine Learning (. 2022 , IGNOREpublisher=
work page 2022
-
[23]
Neural Information Processing Systems (
Discrete-convex-analysis-based framework for warm-starting algorithms with predictions , author=. Neural Information Processing Systems (
-
[24]
Kuhn, Harold W , journal=. The. 1955 , publisher=
work page 1955
-
[25]
Journal of the society for industrial and applied mathematics , IGNOREvolume=
Algorithms for the assignment and transportation problems , author=. Journal of the society for industrial and applied mathematics , IGNOREvolume=. 1957 , publisher=
work page 1957
-
[26]
A shortest augmenting path algorithm for dense and sparse linear assignment problems , author=. Computing , IGNOREvolume=. 1987 , publisher=
work page 1987
-
[27]
Jonker, Roy and Volgenant, Anton , journal=. Improving the. 1986 , publisher=
work page 1986
-
[28]
SciPy 1.0: fundamental algorithms for scientific computing in
Virtanen, Pauli and Gommers, Ralf and Oliphant, Travis E and Haberland, Matt and Reddy, Tyler and Cournapeau, David and Burovski, Evgeni and Peterson, Pearu and Weckesser, Warren and Bright, Jonathan and others , journal=. SciPy 1.0: fundamental algorithms for scientific computing in. 2020 , publisher=
work page 2020
-
[29]
European Conference on Computer Vision (ECCV) , IGNOREpages=
Large scale real-world multi-person tracking , author=. European Conference on Computer Vision (ECCV) , IGNOREpages=. 2022 , publisherpublisher=
work page 2022
-
[30]
A graph-based neural approach to linear sum assignment problems
Aironi, C., Cornell, S., and Squartini, S. A graph-based neural approach to linear sum assignment problems. International Journal of Neural Systems, 2024
work page 2024
-
[31]
Approximation algorithms for combinatorial optimisation with predictions
Antoniadis, A., Eli \' a s, M., Polak, A., and Venzin, M. Approximation algorithms for combinatorial optimisation with predictions. In International Conference on Learning Representations ( ICLR ) , 2025
work page 2025
-
[32]
New auction algorithms for the assignment problem and extensions
Bertsekas, D. New auction algorithms for the assignment problem and extensions. Results in Control and Optimization, 2024
work page 2024
-
[33]
Faster fundamental graph algorithms via learned predictions
Chen, J., Silwal, S., Vakilian, A., and Zhang, F. Faster fundamental graph algorithms via learned predictions. In International Conference on Machine Learning ( ICML ) , 2022
work page 2022
-
[34]
On representing linear programs by graph neural networks
Chen, Z., Liu, J., Wang, X., and Yin, W. On representing linear programs by graph neural networks. In International Conference on Learning Representations ( ICLR ) , 2023
work page 2023
-
[35]
Faster matchings via learned duals
Dinitz, M., Im, S., Lavastida, T., Moseley, B., and Vassilvitskii, S. Faster matchings via learned duals. Neural Information Processing Systems ( NeurIPS ) , 2021
work page 2021
-
[36]
Algorithms with prediction portfolios
Dinitz, M., Im, S., Lavastida, T., Moseley, B., and Vassilvitskii, S. Algorithms with prediction portfolios. In Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., and Oh, A. (eds.), Neural Information Processing Systems ( NeurIPS ) , 2022
work page 2022
-
[37]
Binary search with distributional predictions
Dinitz, M., Im, S., Lavastida, T., Moseley, B., Niaparast, A., and Vassilvitskii, S. Binary search with distributional predictions. In Globersons, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J. M., and Zhang, C. (eds.), Neural Information Processing Systems ( NeurIPS ) , 2024
work page 2024
-
[38]
Hitchcock, F. L. The distribution of a product from several sources to numerous localities. Journal of mathematics and physics, 1941
work page 1941
-
[39]
Jonker, R. and Volgenant, A. Improving the H ungarian assignment algorithm. Operations research letters, 1986
work page 1986
-
[40]
Jonker, R. and Volgenant, A. A shortest augmenting path algorithm for dense and sparse linear assignment problems. Computing, 1987
work page 1987
-
[41]
LAP : L inear A ssignment P roblem solver
Kazmar, T. LAP : L inear A ssignment P roblem solver. https://github.com/gatagat/lap, 2021
work page 2021
-
[42]
Learning predictions for algorithms with predictions
Khodak, M., Balcan, M., Talwalkar, A., and Vassilvitskii, S. Learning predictions for algorithms with predictions. In Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., and Oh, A. (eds.), Neural Information Processing Systems ( NeurIPS ) , 2022
work page 2022
-
[43]
M., Giscard, P.-L., Bause, F., and Wilson, R
Kriege, N. M., Giscard, P.-L., Bause, F., and Wilson, R. C. Computing optimal assignments in linear time for approximate graph matching. In International Conference on Data Mining (ICDM), 2019
work page 2019
-
[44]
Kuhn, H. W. The H ungarian method for the assignment problem. Naval research logistics quarterly, 1955
work page 1955
-
[45]
Glan: A graph-based linear assignment network
Liu, H., Wang, T., Lang, C., Feng, S., Jin, Y., and Li, Y. Glan: A graph-based linear assignment network. Pattern Recognition, 2024
work page 2024
-
[46]
Magnet: A multi-agent graph neural network for efficient bipartite task assignment
Loveland, D., Usevitch, J., Serlin, Z., Koutra, D., and Caceres, R. Magnet: A multi-agent graph neural network for efficient bipartite task assignment. In Autonomous Agents and Multiagent Systems (AAMAS), 2025
work page 2025
-
[47]
Mitzenmacher, M. and Vassilvitskii, S. Algorithms with predictions. Commun. ACM , 2022
work page 2022
-
[48]
Algorithms for the assignment and transportation problems
Munkres, J. Algorithms for the assignment and transportation problems. Journal of the society for industrial and applied mathematics, 1957
work page 1957
-
[49]
Metropolises of major cities around the World
OpenStreetMap . Metropolises of major cities around the World . https://www.openstreetmap.org, 2025
work page 2025
-
[50]
Hybridgnn: A self-supervised graph neural network for efficient maximum matching in bipartite graphs
Pan, C.-H., Qu, Y., Yao, Y., and Wang, M.-J.-S. Hybridgnn: A self-supervised graph neural network for efficient maximum matching in bipartite graphs. Symmetry, 2024
work page 2024
-
[51]
Exploring the power of graph neural networks in solving linear optimization problems
Qian, C., Ch \'e telat, D., and Morris, C. Exploring the power of graph neural networks in solving linear optimization problems. In Artificial intelligence and statistics (AISTATS), 2024
work page 2024
-
[52]
Sakaue, S. and Oki, T. Discrete-convex-analysis-based framework for warm-starting algorithms with predictions. Neural Information Processing Systems ( NeurIPS ) , 2022
work page 2022
-
[53]
Sakaue, S. and Oki, T. Rethinking warm-starts with predictions: Learning predictions close to sets of optimal solutions for faster L- / L ^ -convex function minimization. In Proceedings of the 40th International Conference on Machine Learning ( ICML ) , volume 202 of PMLR, pp.\ 29760--29776, 2023
work page 2023
-
[54]
Large scale real-world multi-person tracking
Shuai, B., Bergamo, A., Buechler, U., Berneshawi, A., Boden, A., and Tighe, J. Large scale real-world multi-person tracking. In European Conference on Computer Vision (ECCV), 2022
work page 2022
-
[55]
Virtanen, P., Gommers, R., Oliphant, T. E., Haberland, M., Reddy, T., Cournapeau, D., Burovski, E., Peterson, P., Weckesser, W., Bright, J., et al. Scipy 1.0: fundamental algorithms for scientific computing in P ython. Nature methods, 2020
work page 2020
-
[56]
Seedgnn: Graph neural network for supervised seeded graph matching
Yu, L., Xu, J., and Lin, X. Seedgnn: Graph neural network for supervised seeded graph matching. In Krause, A., Brunskill, E., Cho, K., Engelhardt, B., Sabato, S., and Scarlett, J. (eds.), International Conference on Machine Learning ( ICML ) , 2023
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.