Recognition: 2 theorem links
· Lean TheoremML-CLIPSim: Multi-Layer CLIP Similarity for Machine-Oriented Image Quality
Pith reviewed 2026-05-12 03:56 UTC · model grok-4.3
The pith
ML-CLIPSim approximates machine image utility through multi-layer similarities from a frozen CLIP encoder.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Machine-oriented quality is captured by aggregating intermediate patch-token and final global similarities inside a frozen CLIP visual encoder, and this aggregation aligns with predictive consistency across models better than conventional fidelity or perceptual metrics.
What carries the argument
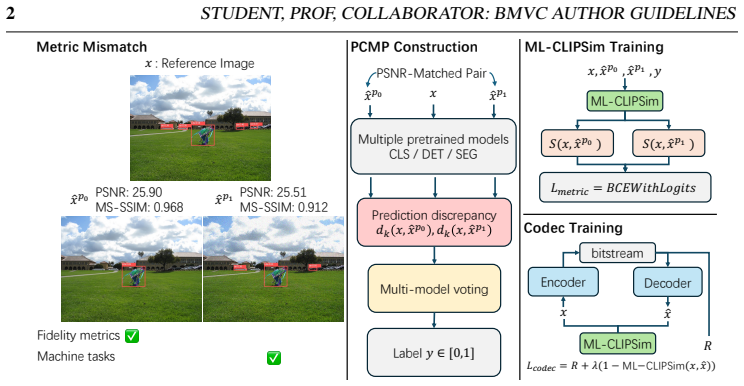
ML-CLIPSim, which computes a weighted sum of cosine similarities between corresponding patch tokens from multiple layers plus the global image embeddings of a frozen CLIP visual encoder.
If this is right
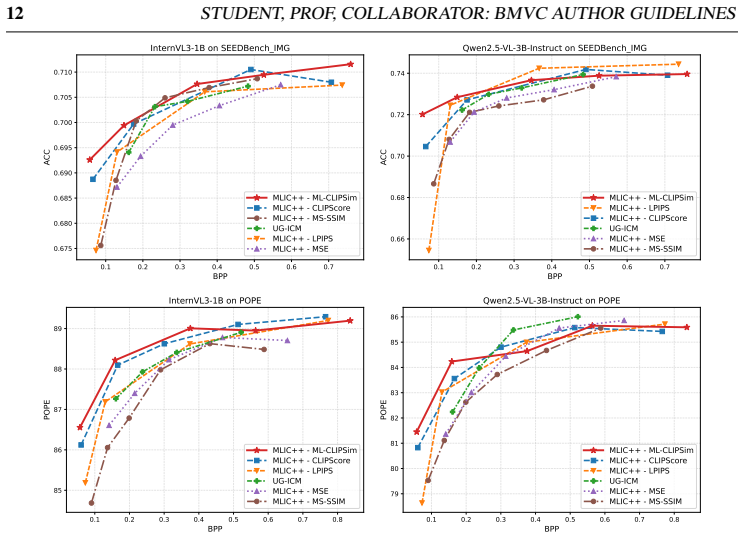
- Using ML-CLIPSim as the distortion loss in learned compression improves the rate versus downstream-task accuracy curve across multiple vision tasks.
- ML-CLIPSim correlates more strongly with machine-preference rankings than fidelity or single-layer perceptual metrics on dedicated benchmarks.
- The same metric remains competitive with human-oriented IQA methods on standard human judgment datasets.
- Pairwise consistency voting across pretrained models supplies a scalable label source that avoids task-specific annotations.
Where Pith is reading between the lines
- Compression models trained with ML-CLIPSim may generalize across tasks without per-task retraining because the metric targets shared machine utility.
- The multi-layer consistency idea could be applied to video or multimodal data by checking predictive agreement on temporally or cross-modal matched pairs.
- If model-consistency reliably signals utility, ML-CLIPSim could serve as an automatic filter for selecting high-utility training images for foundation models.
Load-bearing premise
Votes collected from several pretrained models on which of two PSNR-matched distorted images they classify or predict more consistently serve as a reliable stand-in for general machine utility across tasks.
What would settle it
A downstream task or new dataset in which images ranked higher by ML-CLIPSim produce systematically lower accuracy than images ranked higher by PSNR or LPIPS.
Figures


read the original abstract
We study full-reference image quality assessment from a machine-centric perspective, where images are evaluated by how well they preserve information for downstream models. We formulate machine-oriented quality as a latent machine utility and approximate it through pairwise predictive-consistency comparisons. To this end, we construct PCMP, a dataset of PSNR-matched distortion pairs labeled by consistency votes from multiple pretrained models. We further propose ML-CLIPSim, a differentiable quality metric built on a frozen CLIP visual encoder, which aggregates intermediate patch-token similarities and global image embeddings. Experiments on machine-preference benchmarks, human-IQA datasets, and learned image compression show that ML-CLIPSim better aligns with machine-oriented preferences than conventional fidelity and perceptual metrics, while remaining competitive for human quality prediction. Used as a compression distortion term, it improves rate--task trade-offs across multiple downstream tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ML-CLIPSim, a differentiable full-reference image quality metric derived from a frozen CLIP visual encoder that aggregates multi-layer patch-token similarities and global embeddings. Machine-oriented quality is formulated as latent utility and approximated via pairwise predictive-consistency votes; this leads to the construction of the PCMP dataset of PSNR-matched distortion pairs labeled by multiple pretrained models. Experiments on machine-preference benchmarks, human IQA datasets, and learned compression pipelines claim that ML-CLIPSim aligns better with machine preferences than conventional fidelity or perceptual metrics while remaining competitive for human prediction and improving rate-task trade-offs when used as a distortion term.
Significance. If the central claims hold after addressing validation independence, the work supplies a practical, training-free metric that can be directly inserted into optimization loops for machine-oriented image processing and compression. The use of a frozen encoder and explicit multi-layer aggregation is a clear strength that avoids training-time circularity and provides a concrete, differentiable surrogate for downstream task utility.
major comments (2)
- [PCMP dataset and Experiments sections] PCMP dataset construction and machine-preference benchmark evaluation: the labeling of distortion pairs relies on consistency votes from a fixed collection of pretrained models, yet the same model families appear to be used (or closely related ones) for the downstream machine-preference benchmarks. This risks the metric learning to reproduce the labeling models' biases rather than measuring general, task-agnostic machine utility; the central claim of superior alignment therefore requires explicit held-out model or task validation that is not described.
- [Experiments] Experiments section (machine-preference and compression results): the reported gains are presented without ablations on the layer-aggregation rule (e.g., uniform vs. learned weights, choice of which intermediate layers), without statistical significance tests, and without error analysis on the PCMP proxy itself. Because the proxy is load-bearing for all machine-oriented claims, these omissions prevent assessment of whether the improvements are robust or merely artifacts of the particular model ensemble.
minor comments (2)
- [Abstract] Abstract: quantitative performance numbers (e.g., correlation coefficients or rate-task deltas) are entirely absent; adding at least one representative figure or table reference would make the summary self-contained.
- [ML-CLIPSim formulation] Notation: the precise definition of how patch-token similarities are aggregated across layers (mean, weighted sum, etc.) and how global embeddings are combined should be stated with an equation in the metric definition section for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects of validation and experimental rigor that we will address in the revision. Below we respond point by point to the major comments.
read point-by-point responses
-
Referee: [PCMP dataset and Experiments sections] PCMP dataset construction and machine-preference benchmark evaluation: the labeling of distortion pairs relies on consistency votes from a fixed collection of pretrained models, yet the same model families appear to be used (or closely related ones) for the downstream machine-preference benchmarks. This risks the metric learning to reproduce the labeling models' biases rather than measuring general, task-agnostic machine utility; the central claim of superior alignment therefore requires explicit held-out model or task validation that is not described.
Authors: We acknowledge the referee's concern regarding possible overlap between the models used to label PCMP and those appearing in the machine-preference benchmarks. While the labeling ensemble consists of a diverse collection of pretrained networks and the benchmarks span multiple distinct tasks, we agree that explicit held-out validation would strengthen the claim of task-agnostic utility. In the revised manuscript we will add a new subsection that identifies the exact model families used for labeling versus evaluation and will include results on at least one fully held-out model family and task not involved in PCMP construction. This addition will be accompanied by a brief discussion of how the observed gains persist under stricter separation. revision: yes
-
Referee: [Experiments] Experiments section (machine-preference and compression results): the reported gains are presented without ablations on the layer-aggregation rule (e.g., uniform vs. learned weights, choice of which intermediate layers), without statistical significance tests, and without error analysis on the PCMP proxy itself. Because the proxy is load-bearing for all machine-oriented claims, these omissions prevent assessment of whether the improvements are robust or merely artifacts of the particular model ensemble.
Authors: We agree that the current experimental section would benefit from additional ablations and statistical support. In the revised version we will expand the Experiments section with: (i) ablations on the layer-aggregation strategy, comparing uniform averaging against learned per-layer weights and against subsets of intermediate layers; (ii) statistical significance testing (paired Wilcoxon signed-rank tests with reported p-values) on all reported performance differences; and (iii) an error analysis of the PCMP proxy, including inter-model agreement statistics and sensitivity of downstream results to the choice of voting ensemble. These results will be presented in new tables and figures. revision: yes
Circularity Check
No significant circularity; derivation remains self-contained
full rationale
The paper constructs PCMP as an external proxy dataset via consistency votes on PSNR-matched pairs from pretrained models, then defines ML-CLIPSim as a fixed aggregation over a frozen CLIP encoder's intermediate patch-token and global similarities. The central claim rests on empirical comparisons against separate machine-preference benchmarks, human IQA datasets, and compression tasks rather than any equation or parameter that reduces by construction to the evaluation data. No self-definitional loop, fitted-input-as-prediction, or load-bearing self-citation chain is present in the provided derivation; the frozen-encoder choice and proxy formulation are stated as design decisions, not tautologies.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pairwise predictive-consistency comparisons from pretrained models approximate latent machine utility for downstream tasks
invented entities (1)
-
PCMP dataset
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We formulate machine-oriented image quality as a latent machine utility... approximate it through pairwise predictive-consistency comparisons... ML-CLIPSim... aggregates intermediate patch-token similarities and global image embeddings.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
PCMP... PSNR-matched distortion pairs labeled by consistency votes from multiple pretrained models.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Variational image compression with a scale hyperprior
Johannes Ballé, David Minnen, Saurabh Singh, Sung Jin Hwang, and Nick John- ston. Variational image compression with a scale hyperprior.arXiv preprint arXiv:1802.01436, 2018
work page Pith review arXiv 2018
-
[2]
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24185– 24198, 2024
work page 2024
-
[3]
Keyan Ding, Kede Ma, Shiqi Wang, and Eero P Simoncelli. Image quality assessment: Unifying structure and texture similarity.IEEE transactions on pattern analysis and machine intelligence, 44(5):2567–2581, 2020
work page 2020
-
[4]
Lingyu Duan, Jiaying Liu, Wenhan Yang, Tiejun Huang, and Wen Gao. Video coding for machines: A paradigm of collaborative compression and intelligent analytics.IEEE Transactions on Image Processing, 29:8680–8695, 2020
work page 2020
-
[5]
Task-aware encoder control for deep video compression
Xingtong Ge, Jixiang Luo, Xinjie Zhang, Tongda Xu, Guo Lu, Dailan He, Jing Geng, Yan Wang, Jun Zhang, and Hongwei Qin. Task-aware encoder control for deep video compression. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 26036–26045, June 2024
work page 2024
-
[6]
Ahuja, Parual Datta, Bhavya Kanzariya, V
Alon Harell, Yalda Foroutan, Nilesh A. Ahuja, Parual Datta, Bhavya Kanzariya, V . Srinivasa Somayazulu, Omesh Tickoo, Anderson de Andrade, and Ivan V . Ba- ji´c. Rate-distortion theory in coding for machines and its applications.IEEE Trans- actions on Pattern Analysis and Machine Intelligence, 47:5501–5519, 2023. URL https://api.semanticscholar.org/Corpus...
work page 2023
-
[7]
Wei Jiang, Jiayu Yang, Yongqi Zhai, Feng Gao, and Ronggang Wang. Mlic++: Linear complexity multi-reference entropy modeling for learned image compression.ACM Transactions on Multimedia Computing, Communications and Applications, 21(5):1– 25, 2025
work page 2025
-
[8]
Wei Jiang, Jinyang Yang, Yifeng Zhai, Feng Gao, and Ronggang Wang. Mlic++: Linear complexity multi-reference entropy modeling for learned image compression.ACM Transactions on Multimedia Computing, Communications, and Applications, 21(5):1– 25, 2025
work page 2025
-
[9]
Image coding for machines: an end-to-end learned approach
Nam Le, Honglei Zhang, Francesco Cricri, Ramin Ghaznavi-Youvalari, and Esa Rahtu. Image coding for machines: an end-to-end learned approach. InICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1590–1594. IEEE, 2021. 16STUDENT, PROF, COLLABORA TOR: BMVC AUTHOR GUIDELINES
work page 2021
-
[10]
SEED-Bench: Benchmarking Multimodal LLMs with Generative Comprehension
Bohao Li, Rui Wang, Guangzhi Wang, Yuying Ge, Yixiao Ge, and Ying Shan. Seed- bench: Benchmarking multimodal llms with generative comprehension.arXiv preprint arXiv:2307.16125, 2023
work page internal anchor Pith review arXiv 2023
-
[11]
Image quality assessment: From human to machine preference
Chunyi Li, Yuan Tian, Xiaoyue Ling, Zicheng Zhang, Haodong Duan, Haoning Wu, Ziheng Jia, Xiaohong Liu, Xiongkuo Min, Guo Lu, et al. Image quality assessment: From human to machine preference. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 7570–7581, 2025
work page 2025
-
[12]
Evaluating object hallucination in large vision-language models
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen. Evaluating object hallucination in large vision-language models. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 292–305, 2023
work page 2023
-
[13]
Beyond cosine similarity: Magnitude-aware clip for no-reference image quality assessment
Zhicheng Liao, Dongxu Wu, Zhenshan Shi, Sijie Mai, Hanwei Zhu, Lingyu Zhu, Yuncheng Jiang, and Baoliang Chen. Beyond cosine similarity: Magnitude-aware clip for no-reference image quality assessment. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 6934–6942, 2026
work page 2026
-
[14]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ra- manan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. InEuropean conference on computer vision, pages 740–755. Springer, 2014
work page 2014
-
[15]
Rankiqa: Learning from rankings for no-reference image quality assessment
Xialei Liu, Joost Van De Weijer, and Andrew D Bagdanov. Rankiqa: Learning from rankings for no-reference image quality assessment. InProceedings of the IEEE inter- national conference on computer vision, pages 1040–1049, 2017
work page 2017
-
[16]
Nikolay Ponomarenko, Lina Jin, Oleg Ieremeiev, Vladimir Lukin, Karen Egiazarian, Jaakko Astola, Benoit V ozel, Kacem Chehdi, Marco Carli, Federica Battisti, et al. Im- age database tid2013: Peculiarities, results and perspectives.Signal processing: Image communication, 30:57–77, 2015
work page 2015
-
[17]
Pieapp: Perceptual image-error assessment through pairwise preference
Ekta Prashnani, Hong Cai, Yasamin Mostofi, and Pradeep Sen. Pieapp: Perceptual image-error assessment through pairwise preference. InProceedings of the IEEE Con- ference on Computer Vision and Pattern Recognition, pages 1808–1817, 2018
work page 2018
-
[18]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational confer- ence on machine learning, pages 8748–8763. PmLR, 2021
work page 2021
-
[19]
A statistical evaluation of recent full reference image quality assessment algorithms.IEEE Trans
Hamid R Sheikh, Muhammad F Sabir, Alan C Bovik, et al. A statistical evaluation of recent full reference image quality assessment algorithms.IEEE Trans. Image Process., 15(11):3440–3451, 2006
work page 2006
-
[20]
Clip-agiqa: Boosting the performance of ai-generated image quality assessment with clip
Zhenchen Tang, Zichuan Wang, Bo Peng, and Jing Dong. Clip-agiqa: Boosting the performance of ai-generated image quality assessment with clip. InInternational Con- ference on Pattern Recognition, pages 48–61. Springer, 2024
work page 2024
-
[21]
Exploring clip for assessing the look and feel of images
Jianyi Wang, Kelvin CK Chan, and Chen Change Loy. Exploring clip for assessing the look and feel of images. InProceedings of the AAAI conference on artificial intelli- gence, volume 37, pages 2555–2563, 2023. STUDENT, PROF, COLLABORA TOR: BMVC AUTHOR GUIDELINES17
work page 2023
-
[22]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Multiscale structural similarity for image quality assessment
Zhou Wang, Eero P Simoncelli, and Alan C Bovik. Multiscale structural similarity for image quality assessment. InThe thrity-seventh asilomar conference on signals, systems & computers, 2003, volume 2, pages 1398–1402. Ieee, 2003
work page 2003
-
[24]
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600–612, 2004
work page 2004
-
[25]
Wufeng Xue, Lei Zhang, Xuanqin Mou, and Alan C Bovik. Gradient magnitude simi- larity deviation: A highly efficient perceptual image quality index.IEEE transactions on image processing, 23(2):684–695, 2013
work page 2013
-
[26]
Unified coding for both human perception and generalized machine analytics with clip supervision
Kangsheng Yin, Quan Liu, Xuelin Shen, Yulin He, Wenhan Yang, and Shiqi Wang. Unified coding for both human perception and generalized machine analytics with clip supervision. InProceedings of the AAAI Conference on Artificial Intelligence, vol- ume 39, pages 9517–9525, 2025
work page 2025
-
[27]
Perceptual image quality assessment: a survey
Guangtao Zhai and Xiongkuo Min. Perceptual image quality assessment: a survey. Science China Information Sciences, 63(11):211301, 2020
work page 2020
-
[28]
Lin Zhang, Lei Zhang, Xuanqin Mou, and David Zhang. Fsim: A feature similarity index for image quality assessment.IEEE transactions on Image Processing, 20(8): 2378–2386, 2011
work page 2011
-
[29]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595, 2018
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.