Recognition: no theorem link
QueST: Persistent Queries as Semantic Monitors for Drift Suppression in Long-Horizon Tracking
Pith reviewed 2026-05-12 04:04 UTC · model grok-4.3
The pith
Persistent semantic queries with global attention and 3D grounding reduce drift in long-horizon video tracking.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
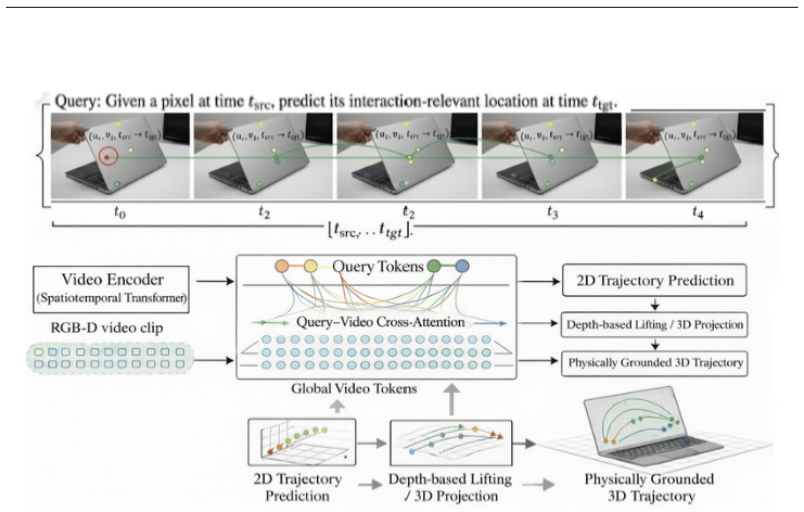
QueST models interaction-relevant entities as persistent semantic queries rather than transient point tracks; each query attends globally over spatio-temporal video features at every time-step to provide a stable semantic anchor, further constrained by lightweight 3D physical grounding to suppress unbounded drift under occlusion.
What carries the argument
Persistent semantic queries that perform global spatio-temporal attention with 3D physical grounding.
Load-bearing premise
Global spatio-temporal attention combined with lightweight 3D physical grounding will reliably suppress semantic drift in diverse real-world conditions without new failure modes or excessive compute.
What would settle it
Observing higher terminal drift or loss of identity in QueST compared to baselines on a challenging long video sequence with complex occlusions and articulations would falsify the claim.
Figures




read the original abstract
Tracking points in videos is typically formulated as frame-to-frame correspondence, where each point is matched locally to the next frame. While this works over short horizons, errors accumulate under articulation, occlusion, and viewpoint change, leading to silent semantic drift that existing trackers cannot detect or correct. In this work, we revisit long-horizon tracking from a monitoring perspective and introduce QueST, a monitoring-by-design framework that treats interaction-relevant entities as persistent semantic queries rather than transient point tracks. Instead of local propagation, each query attends globally over spatio-temporal video features at every time-step, providing a stable semantic anchor across time. We further constrain query trajectories with lightweight 3D physical grounding, using geometric plausibility to suppress unbounded drift under occlusion. We evaluate QueST on long-horizon articulated sequences from PartNet-Mobility in SAPIEN and compare against RAFT-3D, CoTracker, and TAP-Net. QueST substantially reduces terminal drift achieving a 67.7% Absolute Point Error (APE) improvement over TAP-Net while better preserving identity over extended horizons. Our results show that embedding semantic monitoring directly into perception enables more reliable long-horizon tracking under distribution shift.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes QueST, a monitoring-by-design framework for long-horizon point tracking that represents interaction-relevant entities as persistent semantic queries. Each query attends globally over spatio-temporal video features at every timestep rather than relying on local frame-to-frame propagation, and trajectories are further constrained by lightweight 3D physical grounding to enforce geometric plausibility. On long-horizon articulated sequences from PartNet-Mobility in SAPIEN, QueST is reported to achieve a 67.7% reduction in Absolute Point Error relative to TAP-Net while better preserving identity over extended horizons, with comparisons to RAFT-3D and CoTracker.
Significance. If the quantitative gains and the underlying monitoring mechanism prove robust, the work could meaningfully advance long-horizon tracking by reframing drift as a detectable semantic failure rather than an inevitable accumulation of local matching errors. The persistent-query formulation and its integration with 3D grounding represent a coherent conceptual shift from purely appearance-based propagation.
major comments (2)
- [Evaluation] Evaluation section: all quantitative results are obtained exclusively on PartNet-Mobility sequences in SAPIEN, which supplies perfect 3D geometry and controlled occlusions. No real-world video experiments, cross-domain transfer tests, or ablation on the effect of depth noise and texture variation are presented. This directly undercuts the abstract claim that the framework enables 'more reliable long-horizon tracking under distribution shift' and suppresses drift 'across diverse real-world conditions' without introducing new failure modes.
- [Abstract and Results] Abstract and results reporting: the central 67.7% APE improvement over TAP-Net is stated without error bars, without ablation isolating the contribution of global spatio-temporal attention versus the 3D grounding term, and without failure-case analysis. These omissions make it impossible to assess whether the reported gain is statistically reliable or sensitive to particular sequence characteristics.
minor comments (1)
- [Abstract] The abstract lists comparisons to RAFT-3D, CoTracker, and TAP-Net but does not define the precise identity-preservation metric used alongside APE.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects of evaluation scope and result reporting that we will address through targeted revisions. We respond to each major comment below.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: all quantitative results are obtained exclusively on PartNet-Mobility sequences in SAPIEN, which supplies perfect 3D geometry and controlled occlusions. No real-world video experiments, cross-domain transfer tests, or ablation on the effect of depth noise and texture variation are presented. This directly undercuts the abstract claim that the framework enables 'more reliable long-horizon tracking under distribution shift' and suppresses drift 'across diverse real-world conditions' without introducing new failure modes.
Authors: We acknowledge that all reported results use PartNet-Mobility sequences in SAPIEN, which provides perfect 3D geometry and controlled occlusions. This choice enables precise, repeatable measurement of long-horizon drift with reliable ground truth, allowing isolation of articulation and occlusion effects. We agree that the current evaluation does not directly support claims about real-world conditions or robustness to depth noise and texture variation. In the revised manuscript we will (1) revise the abstract and introduction to limit claims to improvements demonstrated under distribution shifts within simulated articulated environments, (2) add a dedicated limitations section that explicitly discusses the sim-to-real gap, the lack of real-world experiments, and potential sensitivity to depth noise or texture changes, and (3) include qualitative discussion of how the persistent-query and 3D-grounding design may mitigate or remain vulnerable to such factors. New real-world experiments are not feasible without additional data collection and are therefore not planned for this revision. revision: partial
-
Referee: [Abstract and Results] Abstract and results reporting: the central 67.7% APE improvement over TAP-Net is stated without error bars, without ablation isolating the contribution of global spatio-temporal attention versus the 3D grounding term, and without failure-case analysis. These omissions make it impossible to assess whether the reported gain is statistically reliable or sensitive to particular sequence characteristics.
Authors: We will improve the reporting of results in the revised manuscript. We will add error bars (standard deviation across sequences) to the APE metric to indicate statistical variability. We will expand the ablation studies to separately quantify the contribution of the global spatio-temporal attention mechanism versus the 3D physical grounding term, reporting performance with each component disabled. We will also add a failure-case analysis section that identifies sequences or conditions (e.g., extreme occlusions or rapid articulations) where QueST still exhibits residual drift or identity loss. These additions will make the reliability and sensitivity of the reported gains clearer. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper introduces QueST as a new monitoring framework relying on persistent semantic queries, global spatio-temporal attention, and lightweight 3D grounding, with all claims supported by direct empirical comparisons to external baselines (RAFT-3D, CoTracker, TAP-Net) on PartNet-Mobility data. No equations, derivations, fitted parameters presented as predictions, or self-citations appear in the abstract or summary text. The result is not reduced to its inputs by construction; the 67.7% APE improvement is an observed experimental outcome rather than a definitional or fitted tautology.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Global attention over spatio-temporal features provides a stable semantic anchor across time
- domain assumption Lightweight 3D physical grounding can suppress unbounded drift under occlusion
invented entities (1)
-
Persistent semantic queries
no independent evidence
Reference graph
Works this paper leans on
-
[1]
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
work page 2000
-
[2]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
work page 1980
-
[3]
M. J. Kearns , title =
-
[4]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
work page 1983
-
[5]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
work page 2000
-
[6]
Suppressed for Anonymity , author=
-
[7]
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
work page 1981
-
[8]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
work page 1959
-
[9]
Dreamart: Generating interactable articulated objects from a single image,
Dreamart: Generating interactable articulated objects from a single image , author=. arXiv preprint arXiv:2507.05763 , year=
-
[10]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
CAP-Net: A Unified Network for 6D Pose and Size Estimation of Categorical Articulated Parts from a Single RGB-D Image , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[11]
2024 IEEE International Conference on Robotics and Automation (ICRA) , pages=
Capt: Category-level articulation estimation from a single point cloud using transformer , author=. 2024 IEEE International Conference on Robotics and Automation (ICRA) , pages=. 2024 , organization=
work page 2024
-
[12]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
VidBot: Learning Generalizable 3D Actions from In-the-Wild 2D Human Videos for Zero-Shot Robotic Manipulation , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[13]
Advances in Neural Information Processing Systems , volume=
Tap-vid: A benchmark for tracking any point in a video , author=. Advances in Neural Information Processing Systems , volume=
-
[14]
Advances in Neural Information Processing Systems , volume=
Tapvid-3d: A benchmark for tracking any point in 3d , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Flownet3d: Learning scene flow in 3d point clouds , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[16]
arXiv preprint arXiv:2512.08924 , year=
Efficiently Reconstructing Dynamic Scenes One D4RT at a Time , author=. arXiv preprint arXiv:2512.08924 , year=
-
[17]
European Conference on Computer Vision , pages=
Scenescript: Reconstructing scenes with an autoregressive structured language model , author=. European Conference on Computer Vision , pages=. 2024 , organization=
work page 2024
-
[18]
arXiv preprint arXiv:2506.07491 , year=
SpatialLM: Training Large Language Models for Structured Indoor Modeling , author=. arXiv preprint arXiv:2506.07491 , year=
-
[19]
Articulate-anything: Automatic modeling of articulated objects via a vision-language foundation model , author=. arXiv preprint arXiv:2410.13882 , year=
-
[20]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Where2act: From pixels to actions for articulated 3d objects , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[21]
European conference on computer vision , pages=
Cotracker: It is better to track together , author=. European conference on computer vision , pages=. 2024 , organization=
work page 2024
-
[22]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Trackformer: Multi-object tracking with transformers , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[23]
Masked-attention Mask Transformer for Universal Image Segmentation , author=. CVPR , year=
-
[24]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Tracking everything everywhere all at once , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[25]
2018 IEEE international conference on robotics and automation (ICRA) , pages=
Affordancenet: An end-to-end deep learning approach for object affordance detection , author=. 2018 IEEE international conference on robotics and automation (ICRA) , pages=. 2018 , organization=
work page 2018
-
[26]
The International Journal of Robotics Research , volume=
Diffusion policy: Visuomotor policy learning via action diffusion , author=. The International Journal of Robotics Research , volume=. 2025 , publisher=
work page 2025
-
[27]
Palm-e: An embodied multimodal language model , author=
-
[28]
Vima: Robot manipulation with multimodal prompts , author=
-
[29]
PartNet: A Large-Scale Benchmark for Fine-Grained and Hierarchical Part-Level 3D Object Understanding , author=. ECCV , year=
-
[30]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Sapien: A simulated part-based interactive environment , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[31]
Normalized Object Coordinate Space for Category-level 6D Object Pose and Size Estimation , author =. CVPR , year =
-
[32]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Partnet: A large-scale benchmark for fine-grained and hierarchical part-level 3d object understanding , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[33]
RAFT: Recurrent All-Pairs Field Transforms for Optical Flow , author=. ECCV , year=
-
[34]
International conference on machine learning , pages=
Wilds: A benchmark of in-the-wild distribution shifts , author=. International conference on machine learning , pages=. 2021 , organization=
work page 2021
- [35]
-
[36]
Deep Anomaly Detection with Outlier Exposure
Deep anomaly detection with outlier exposure , author=. arXiv preprint arXiv:1812.04606 , year=
-
[37]
Mastering diverse control tasks through world models , author=. Nature , pages=. 2025 , publisher=
work page 2025
-
[38]
Advances in Neural Information Processing Systems , volume=
Light field networks: Neural scene representations with single-evaluation rendering , author=. Advances in Neural Information Processing Systems , volume=
-
[39]
Advances in neural information processing systems , volume=
Large margin deep networks for classification , author=. Advances in neural information processing systems , volume=
-
[40]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
Qdtrack: Quasi-dense similarity learning for appearance-only multiple object tracking , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=. 2023 , publisher=
work page 2023
-
[41]
European conference on computer vision , pages=
End-to-end object detection with transformers , author=. European conference on computer vision , pages=. 2020 , organization=
work page 2020
-
[42]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Tapir: Tracking any point with per-frame initialization and temporal refinement , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[43]
Shi, Yahao and Cao, Xinyu and Lu, Feixiang and Zhou, Bin , booktitle=. p\^
-
[44]
2024 IEEE International Conference on Robotics and Automation (ICRA) , pages=
Gamma: Generalizable articulation modeling and manipulation for articulated objects , author=. 2024 IEEE International Conference on Robotics and Automation (ICRA) , pages=. 2024 , organization=
work page 2024
-
[45]
arXiv preprint arXiv:2510.26443 , year=
PointSt3R: Point Tracking through 3D Grounded Correspondence , author=. arXiv preprint arXiv:2510.26443 , year=
-
[46]
Advances in Neural Information Processing Systems , volume=
Embedding trajectory for out-of-distribution detection in mathematical reasoning , author=. Advances in Neural Information Processing Systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.