Recognition: no theorem link
HS-FNO: History-Space Fourier Neural Operator for Non-Markovian Partial Differential Equations
Pith reviewed 2026-05-13 07:04 UTC · model grok-4.3
The pith
HS-FNO halves rollout error for non-Markovian PDEs by lifting states to include exact history shifts instead of learning them.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
HS-FNO formulates a neural operator directly on the lifted history-state field and splits each time step into a learned future-slice predictor and an exact shift-append transport; this structure produces the lowest aggregate errors on delayed reaction-diffusion, spatial epidemiology, nonlocal neural fields, delayed waves, and distributed-memory closures, with the clearest improvement appearing in long autoregressive prediction.
What carries the argument
History-state lifting to u_t(θ,x) combined with learned future-slice prediction plus exact shift-append transport.
If this is right
- Autoregressive forecasts of delay and nonlocal PDEs become stable enough for practical surrogate use without retraining at each step.
- The same model size produces lower error than unconstrained history-to-history operators, freeing parameters for finer spatial resolution.
- The inductive bias applies across reaction-diffusion, epidemiology, neural-field, and wave benchmarks without per-family redesign.
- One-step and history-space errors also improve, indicating the structure helps even when full rollouts are not required.
Where Pith is reading between the lines
- The same split-predictor-plus-exact-transport pattern could be inserted into other operator families beyond Fourier bases to handle memory effects.
- Testing on systems with slowly decaying memory kernels would reveal whether the fixed-tau window must be made adaptive.
- If the shift-append step is replaced by a learned transport with small regularization, error accumulation might be further reduced on very long horizons.
Load-bearing premise
A fixed finite history window of length tau is sufficient to capture all relevant non-Markovian memory effects and the shift-append step stays numerically stable over long rollouts.
What would settle it
Measure whether rollout error stays below 0.12 when the same trained model is tested on trajectories whose required memory exceeds the fixed tau or when run for 10x longer autoregressive steps than the training horizon.
Figures




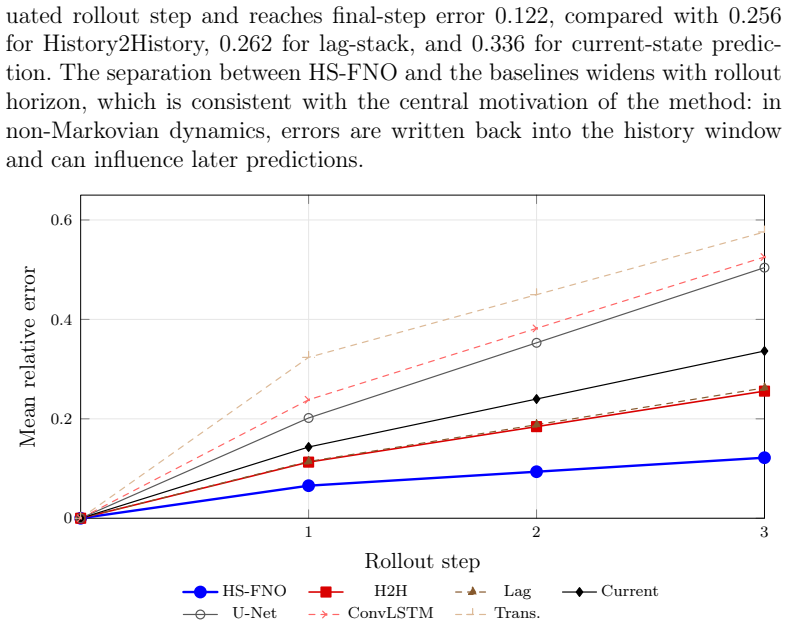



read the original abstract
Neural operators provide fast surrogate models for time-dependent partial differential equations, but their standard autoregressive use usually assumes that the instantaneous field $u(t,\cdot)$ is a complete state. This assumption fails for delay equations, distributed-memory systems, and other non-Markovian dynamics: two trajectories may agree at time $t$ and nevertheless have different futures because their histories differ. We introduce the History-Space Fourier Neural Operator (HS-FNO), a neural operator for delay and memory-driven PDEs formulated on the lifted state $u_t(\theta,x)=u(t+\theta,x)$, $\theta\in[-\tau,0]$. The key computational step is to decompose one history-state update into a learned predictor for the newly exposed future slice and an exact shift-append transport for the portion of the history window already known from the previous state. This avoids learning deterministic history coordinates, reduces the learned output dimension, and enforces the natural discrete history update. We test HS-FNO on five benchmark families covering delayed reaction--diffusion, spatial epidemiology, nonlocal neural-field dynamics, delayed waves, and distributed-memory closures. Across ten random seeds, HS-FNO attains the lowest aggregate one-step, history-space, and rollout errors among the principal baselines. The largest gain occurs in autoregressive prediction, where aggregate rollout error decreases from $0.241$, $0.188$, and $0.185$ for current-state, lag-stack, and unconstrained history-to-history operators, respectively, to $0.094$. The same model uses fewer parameters than unconstrained history prediction. These results indicate that enforcing the discrete shift structure of history-state evolution is an effective inductive bias for non-Markovian PDE surrogate modeling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the History-Space Fourier Neural Operator (HS-FNO) for non-Markovian time-dependent PDEs. It lifts the state to a history window u_t(θ, x) with θ ∈ [-τ, 0] and decomposes each update into a learned neural-operator prediction for the newly exposed future slice plus an exact shift-append transport on the known portion of the history. Experiments across five benchmark families (delayed reaction-diffusion, spatial epidemiology, nonlocal neural fields, delayed waves, distributed-memory closures) and ten random seeds show HS-FNO attaining the lowest aggregate one-step, history-space, and rollout errors, with rollout error dropping from 0.185 (unconstrained history-to-history) to 0.094 while using fewer parameters.
Significance. If the empirical gains hold under closer scrutiny, the explicit separation of learned prediction from exact discrete transport supplies a useful inductive bias for surrogate modeling of memory-driven systems, improving long-horizon autoregressive accuracy and parameter efficiency. The architecture's reduction of the learned output dimension via the exact-transport step is a concrete strength that could transfer to other operator families.
major comments (3)
- [Abstract and Experiments] Abstract and Experiments: the central claim that HS-FNO attains the lowest aggregate rollout error (0.094 versus 0.185 for the unconstrained baseline) is reported without details on exact baseline implementations, hyperparameter-matching protocols, or statistical significance testing of the gap across the ten seeds. This information is load-bearing for the empirical superiority statement.
- [Method] Method (history-state update decomposition): the shift-append transport is exact only when the incoming history is perfect. Once the learned future-slice predictor introduces approximation error, that error is shifted into subsequent windows; the manuscript provides no analysis or per-benchmark error-growth curves showing how such drift behaves over rollouts longer than τ, which directly affects the autoregressive-prediction claim.
- [Experiments] Experiments: the formulation assumes a fixed finite τ suffices to capture all relevant non-Markovian effects for each benchmark family, yet no τ-sensitivity sweeps or comparison of rollout horizons against the intrinsic memory scale of the PDEs are presented. This limits evaluation of whether the reported gains generalize beyond the chosen window lengths.
minor comments (2)
- [Method] Notation: the lifted state u_t(θ, x) and the precise mechanics of the shift-append operation would benefit from an explicit equation or schematic diagram in the method section.
- [Experiments] References: the principal baselines (current-state, lag-stack, unconstrained history-to-history) should be cited with their original papers to allow readers to verify implementation details.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below with clarifications from the manuscript and outline specific revisions that will be incorporated to strengthen the empirical claims and analysis.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments: the central claim that HS-FNO attains the lowest aggregate rollout error (0.094 versus 0.185 for the unconstrained baseline) is reported without details on exact baseline implementations, hyperparameter-matching protocols, or statistical significance testing of the gap across the ten seeds. This information is load-bearing for the empirical superiority statement.
Authors: We agree that the current presentation lacks sufficient detail on baseline implementations and statistical validation. The manuscript already specifies the three baselines (current-state FNO, lag-stack FNO, unconstrained history-to-history FNO) and reports aggregate errors over ten seeds, but does not describe the hyperparameter search or significance tests. In the revised version we will add a dedicated experimental-setup subsection that (i) gives the exact architecture and training protocol for each baseline, (ii) documents the grid-search ranges used to match model capacity and training effort, and (iii) reports mean, standard deviation, and paired t-test p-values for the rollout-error differences across the ten seeds. These additions will directly support the superiority statement. revision: yes
-
Referee: [Method] Method (history-state update decomposition): the shift-append transport is exact only when the incoming history is perfect. Once the learned future-slice predictor introduces approximation error, that error is shifted into subsequent windows; the manuscript provides no analysis or per-benchmark error-growth curves showing how such drift behaves over rollouts longer than τ, which directly affects the autoregressive-prediction claim.
Authors: The referee correctly notes that approximation error introduced by the learned slice predictor will be exactly transported forward by the shift-append step. While the decomposition guarantees that known history coordinates are never re-learned, the manuscript indeed omits explicit long-horizon drift analysis. We will therefore add, in the revised Experiments section, per-benchmark error-growth curves for autoregressive rollouts extending to at least 5τ–10τ. These curves will quantify the accumulation of drift for HS-FNO versus the baselines and will be accompanied by a short discussion of how the exact-transport step limits error growth relative to fully learned history-to-history mappings. revision: yes
-
Referee: [Experiments] Experiments: the formulation assumes a fixed finite τ suffices to capture all relevant non-Markovian effects for each benchmark family, yet no τ-sensitivity sweeps or comparison of rollout horizons against the intrinsic memory scale of the PDEs are presented. This limits evaluation of whether the reported gains generalize beyond the chosen window lengths.
Authors: For each benchmark the value of τ was chosen to match the explicit delay or memory scale stated in the PDE definition (e.g., the fixed delay in the delayed reaction-diffusion and wave equations). Nevertheless, the manuscript does not present sensitivity sweeps. In the revision we will add τ-sensitivity plots for two representative families (delayed reaction-diffusion and nonlocal neural fields), varying τ around the nominal value and reporting rollout error versus τ. We will also include a brief discussion, referencing the benchmark descriptions in Section 4, that relates the chosen τ to the intrinsic memory scale of each PDE family. These results will be placed in the main Experiments section or as supplementary material. revision: partial
Circularity Check
No circularity: architectural design with exact transport and external benchmark validation
full rationale
The paper defines HS-FNO via an explicit decomposition of each history-state update into a learned predictor for the new future slice plus an exact shift-append transport on the known history window. This is presented as an inductive bias that reduces output dimension and enforces the discrete update rule, without any derivation that equates the claimed performance gains to fitted parameters or prior self-citations. All reported results (one-step, history-space, and rollout errors across five benchmark families and ten seeds) are measured against independent baselines on external test trajectories; they do not reduce by construction to quantities defined inside the model equations. No uniqueness theorems, ansatzes, or self-citations are invoked to justify the central claims.
Axiom & Free-Parameter Ledger
free parameters (1)
- neural network weights and biases
axioms (2)
- domain assumption A fixed finite history window of length tau captures all relevant memory effects for the target PDE families.
- standard math Fourier Neural Operator layers can be applied to the history-augmented field without loss of the underlying operator-learning guarantees.
invented entities (1)
-
History-space state u_t(theta,x)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Jack K. Hale and Sjoerd M. Verduyn Lunel.Introduction to Functional Differential Equations, volume 99 of Applied Mathematical Sciences. Springer, 1993
work page 1993
-
[2]
Jianhong Wu.Theory and Applications of Partial Functional Differential Equations, volume 119 ofApplied Mathematical Sciences. Springer, 1996
work page 1996
-
[3]
Taishan Yi, Yuming Chen, and Jianhong Wu. Threshold dynamics of a delayed reaction diffusion equation subject to the dirichlet condition.Journal of Biological Dynamics, 3(2-3):331–341, 2009. doi: 10.1080/17513750802425
-
[4]
URL https://doi.org/10.1080/17513750802425656. PMID: 22880838
-
[5]
Marc R. Roussel. The use of delay differential equations in chemical kinetics.The Journal of Physical Chemistry, 100(20):8323–8330, 1996. doi: 10.1021/jp9600672
-
[6]
S. M. Oliva. Reaction–diffusion equations with nonlinear boundary delay.Journal of Dynamics and Differential Equations, 11:279–296, 1999. doi: 10.1023/A:1021929413376
-
[7]
Eric J. Parish and Karthik Duraisamy. Non-markovian closure models for large eddy simulations using the mori-zwanzig formalism.Phys. Rev. Fluids, 2:014604, Jan 2017. doi: 10.1103/PhysRevFluids.2.014604. URL https://link.aps.org/doi/10.1103/PhysRevFluids.2.014604. 12 HS-FNO for Non-Markovian PDEsPREPRINT
-
[8]
Eric J. Parish and Karthik Duraisamy. A dynamic subgrid scale model for large eddy simulations based on the mori–zwanzig formalism.Journal of Computational Physics, 349:154–175, 2017. ISSN 0021-9991. doi: https: //doi.org/10.1016/j.jcp.2017.07.053. URL https://www.sciencedirect.com/science/article/pii/S0021999117305612
-
[9]
Vsevolod G. Sorokin and Andrei V . Vyazmin. Nonlinear reaction–diffusion equations with delay: Partial survey, exact solutions, test problems, and numerical integration.Mathematics, 10(11), 2022. ISSN 2227-7390. doi: 10.3390/math10111886. URL https://www.mdpi.com/2227-7390/10/11/1886
-
[10]
C.V . Pao. Finite difference solutions of reaction diffusion equations with continuous time delays.Computers & Mathematics with Applications, 42(3):399–412, 2001. ISSN 0898-1221. doi: https://doi.org/10.1016/S0898-122 1(01)00165-1. URL https://www.sciencedirect.com/science/article/pii/S0898122101001651
-
[11]
Yuan-Ming Wang. Asymptotic behavior of the numerical solutions of time-delayed reaction diffusion equations with non-monotone reaction term.ESAIM: Mathematical Modelling and Numerical Analysis, 37(2):259–276,
-
[12]
doi: 10.1051/m2an:2003025
-
[13]
Yuan-Ming Wang and C. V . Pao. Time-delayed finite difference reaction-diffusion systems with nonquasimonotone functions.Numerische Mathematik, 103:485–513, 2006. doi: 10.1007/s00211-006-0685-y
-
[14]
I. Amirali, G. M. Amiraliyev, M. Cakir, and E. Cimen. Explicit finite difference methods for the delay pseu- doparabolic equations.The Scientific World Journal, 2014:497393, 2014. doi: 10.1155/2014/497393
-
[15]
Gemeda Lubo and Gemechis File Duressa. Galerkin finite element method for the generalized delay reaction- diffusion equation.Research in Mathematics, 9:1–16, 12 2022. doi: 10.1080/27684830.2022.2071388
-
[16]
Yao-Lung L. Fang. Fdtd: Solving 1+1d delay pde in parallel.Computer Physics Communications, 235:422–432,
-
[17]
doi: https://doi.org/10.1016/j.cpc.2018.08.018
ISSN 0010-4655. doi: https://doi.org/10.1016/j.cpc.2018.08.018. URL https://www.sciencedirect.com/scie nce/article/pii/S001046551830314X
-
[18]
M. Raissi, P. Perdikaris, and G. E. Karniadakis. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations.Journal of Computational Physics, 378:686–707, 2019. ISSN 0021-9991. doi: 10.1016/j.jcp.2018.10.045. URL https://www.sciencedirect. com/science/article/pii/...
-
[19]
Kevrekidis, Lu Lu, Paris Perdikaris, Sifan Wang, and Liu Yang
George Karniadakis, Yannis Kevrekidis, Lu Lu, Paris Perdikaris, Sifan Wang, and Liu Yang. Physics-informed machine learning.Nature Reviews Physics, 3:422–440, 2021. doi: 10.1038/s42254-021-00314-5
-
[20]
Double-activation neural network for solving parabolic equations with time delay
Qiumei Huang and Qiao Zhu. Double-activation neural network for solving parabolic equations with time delay. Neurocomputing, 635:129978, 2025. ISSN 0925-2312. doi: https://doi.org/10.1016/j.neucom.2025.129978. URL https://www.sciencedirect.com/science/article/pii/S0925231225006502
-
[21]
Housen Wang, Yuxing Chen, Sirong Cao, Xiaoli Wang, and Qiang Liu. A deep neural network framework for solving forward and inverse problems in delay differential equations.Journal of Computational and Applied Mathematics, 477:117154, 2026. ISSN 0377-0427. doi: https://doi.org/10.1016/j.cam.2025.117154. URL https://www.sciencedirect.com/science/article/pii/...
-
[22]
Jiacheng Feng, Lin Jiang, Lianshan Yan, Xingchen He, Anlin Yi, Wei Pan, and Bin Luo. Modeling of high- dimensional time-delay chaotic system based on fourier neural operator.Chaos, Solitons & Fractals, 188:115523,
-
[23]
doi: https://doi.org/10.1016/j.chaos.2024.115523
ISSN 0960-0779. doi: https://doi.org/10.1016/j.chaos.2024.115523. URL https://www.sciencedirect.com/ science/article/pii/S0960077924010750
-
[24]
Yuanran Zhu, Yu-Hang Tang, and Changho Kim. Learning stochastic dynamics with statistics-informed neural network.Journal of Computational Physics, 474:111819, 2023. ISSN 0021-9991. doi: 10.1016/j.jcp.2022.111819. URL https://www.sciencedirect.com/science/article/pii/S0021999122008828
-
[25]
Neural delay differential equations
Qunxi Zhu, Yao Guo, and Wei Lin. Neural delay differential equations. InInternational Conference on Learning Representations, 2021. URL https://openreview.net/forum?id=Q1jmmQz72M2
work page 2021
-
[26]
Neural piecewise-constant delay differential equations
Qunxi Zhu, Yifei Shen, Dongsheng Li, and Wei Lin. Neural piecewise-constant delay differential equations. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 36, 2022. doi: 10.1609/aaai.v36i8.20911
-
[27]
Learning stable deep dynamics models for partially observed or delayed dynamical systems
Andreas Schlaginhaufen, Philippe Wenk, Andreas Krause, and Florian Dorfler. Learning stable deep dynamics models for partially observed or delayed dynamical systems. In M. Ranzato, A. Beygelzimer, Y . Dauphin, P.S. Liang, and J. Wortman Vaughan, editors,Advances in Neural Information Processing Systems, volume 34, pages 11870–11882. Curran Associates, Inc...
work page 2021
-
[28]
Learning the delay in delay differential equations
Robert Stephany, Maria Antonia Oprea, Gabriella Torres Nothaft, Mark Walth, Arnaldo Rodriguez-Gonzalez, and William A Clark. Learning the delay in delay differential equations. InICLR 2024 Workshop on AI4DifferentialEquations In Science, 2024. URL https://openreview.net/forum?id=VTYhJLoOaR. 13 HS-FNO for Non-Markovian PDEsPREPRINT
work page 2024
-
[29]
Neural adaptive delay differential equations.Neurocomputing, 648:130634, 2025
Chao Zhou, Qieshi Zhang, and Jun Cheng. Neural adaptive delay differential equations.Neurocomputing, 648:130634, 2025. ISSN 0925-2312. doi: https://doi.org/10.1016/j.neucom.2025.130634. URL https: //www.sciencedirect.com/science/article/pii/S0925231225013062
-
[30]
Lu Lu, Pengzhan Jin, Guofei Pang, Zhongqiang Zhang, and George Em Karniadakis. Learning nonlinear operators via deeponet based on the universal approximation theorem of operators.Nature Machine Intelligence, 3(3): 218–229, 2021
work page 2021
-
[31]
Fourier neural operator for parametric partial differential equations
Zongyi Li, Nikola Borislavov Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Fourier neural operator for parametric partial differential equations. InInterna- tional Conference on Learning Representations, 2021. URL https://openreview.net/forum?id=c8P9NQVtmnO
work page 2021
-
[32]
Nikola Kovachki, Zongyi Li, Burigede Liu, Kamyar Azizzadenesheli, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Neural operator: Learning maps between function spaces with applications to pdes.Journal of Machine Learning Research, 24(89):1–97, 2023. URL http://jmlr.org/papers/v24/21-1524.html
work page 2023
-
[33]
Geometry-informed neural operator for large-scale 3d pdes, 2023
Zongyi Li, Nikola Borislavov Kovachki, Chris Choy, Boyi Li, Jean Kossaifi, Shourya Prakash Otta, Moham- mad Amin Nabian, Maximilian Stadler, Christian Hundt, Kamyar Azizzadenesheli, and Anima Anandkumar. Geometry-informed neural operator for large-scale 3d pdes, 2023. URL https://arxiv.org/abs/2309.00583
-
[34]
Convolutional neural operators for robust and accurate learning of pdes
Bogdan Raoni´c, Roberto Molinaro, Tim De Ryck, Tobias Rohner, Francesca Bartolucci, Rima Alaifari, Siddhartha Mishra, and Emmanuel de Bézenac. Convolutional neural operators for robust and accurate learning of pdes. In Advances in Neural Information Processing Systems, volume 36, pages 77187–77200, 2023. URL https://proceedi ngs.neurips.cc/paper_files/pap...
work page 2023
-
[35]
U-no: U-shaped neural operators.arXiv preprint arXiv:2204.11127, 2022
Md Ashiqur Rahman, Zachary E. Ross, and Kamyar Azizzadenesheli. U-no: U-shaped neural operators, 2023. URL https://arxiv.org/abs/2204.11127
-
[36]
Wang, Yuan Yin, Jean-Noël Vittaut, and Patrick Gallinari
Louis Serrano, Lise Le Boudec, Armand Kassaï Koupaï, Thomas X. Wang, Yuan Yin, Jean-Noël Vittaut, and Patrick Gallinari. Operator learning with neural fields: Tackling pdes on general geometries. InAdvances in Neural Information Processing Systems, volume 36, pages 70581–70611, 2023. URL https://proceedings.neurips. cc/paper_files/paper/2023/file/df543023...
work page 2023
-
[37]
Choose a transformer: Fourier or galerkin, 2021
Shuhao Cao. Choose a transformer: Fourier or galerkin, 2021. URL https://arxiv.org/abs/2105.14995
-
[38]
Transformer for partial differential equations’ operator learning, 2023
Zijie Li, Kazem Meidani, and Amir Barati Farimani. Transformer for partial differential equations’ operator learning, 2023. URL https://arxiv.org/abs/2205.13671
-
[39]
Latent neural operator for solving forward and inverse pde problems
Tian Wang and Chuang Wang. Latent neural operator for solving forward and inverse pde problems. InAdvances in Neural Information Processing Systems, volume 37, pages 33085–33107, 2024. doi: 10.52202/079017-1042. URL https://proceedings.neurips.cc/paper_files/paper/2024/file/39f6d5c2e310a5a629dcfc4d517aa0d1-Paper-C onference.pdf
-
[40]
arXiv preprint arXiv:2111.03794 , year =
Zongyi Li, Hongkai Zheng, Nikola Kovachki, David Jin, Haoxuan Chen, Burigede Liu, Kamyar Azizzadenesheli, and Anima Anandkumar. Physics-informed neural operator for learning partial differential equations, 2023. URL https://arxiv.org/abs/2111.03794
-
[41]
Thomas O’Leary-Roseberry, Peng Chen, Umberto Villa, and Omar Ghattas. Derivative-informed neural operator: An efficient framework for high-dimensional parametric derivative learning.Journal of Computational Physics, 496:112555, 2024. ISSN 0021-9991. doi: 10.1016/j.jcp.2023.112555. URL https://www.sciencedirect.com/scienc e/article/pii/S0021999123006502
-
[42]
PDEBench: An extensive benchmark for scientific machine learning
Makoto Takamoto, Timothy Praditia, Raphael Leiteritz, Dan MacKinlay, Francesco Alesiani, Dirk Pflüger, and Mathias Niepert. PDEBench: An extensive benchmark for scientific machine learning. InAdvances in Neural Information Processing Systems Datasets and Benchmarks Track, 2022. URL https://openreview.net/forum?id=dh _MkX0QfrK
work page 2022
-
[43]
Detecting strange attractors in turbulence
Floris Takens. Detecting strange attractors in turbulence. In David Rand and Lai-Sang Young, editors,Dynamical Systems and Turbulence, Warwick 1980, pages 366–381, Berlin, Heidelberg, 1981. Springer Berlin Heidelberg. ISBN 978-3-540-38945-3
work page 1980
-
[44]
Tim Sauer, James A. Yorke, and Martin Casdagli. Embedology.Journal of Statistical Physics, 65:579–616, 1991. doi: 10.1007/BF01053745
-
[45]
Memory effects in irreversible thermodynamics.Phys
Robert Zwanzig. Memory effects in irreversible thermodynamics.Phys. Rev., 124:983–992, Nov 1961. doi: 10.1103/PhysRev.124.983. URL https://link.aps.org/doi/10.1103/PhysRev.124.983
-
[46]
Alexandre J. Chorin, Ole H. Hald, and Raz Kupferman. Optimal prediction and the mori–zwanzig representation of irreversible processes.Proceedings of the National Academy of Sciences, 97(7):2968–2973, 2000. doi: 10.1073/pnas.97.7.2968. URL https://www.pnas.org/doi/abs/10.1073/pnas.97.7.2968. 14 HS-FNO for Non-Markovian PDEsPREPRINT
-
[47]
Zhen Li, Xin Bian, Xiantao Li, and George Em Karniadakis. Incorporation of memory effects in coarse-grained modeling via the mori-zwanzig formalism.The Journal of Chemical Physics, 143(24):243128, 11 2015. ISSN 0021-9606. doi: 10.1063/1.4935490. URL https://doi.org/10.1063/1.4935490
-
[48]
Ayoub Gouasmi, Eric J. Parish, and Karthik Duraisamy. A priori estimation of memory effects in reduced-order models of nonlinear systems using the mori-zwanzig formalism.Proceedings of the Royal Society A: Mathematical, Physical and Engineering Sciences, 473(2205):20170385, 2017. doi: 10.1098/rspa.2017.0385
-
[49]
Long short-term memory.Neural Comput., 9(8):1735–1780, November
Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory.Neural Comput., 9(8):1735–1780, November
-
[50]
ISSN 0899-7667. doi: 10.1162/neco.1997.9.8.1735. URL https://doi.org/10.1162/neco.1997.9.8.1735
-
[51]
Convolutional lstm network: A machine learning approach for precipitation nowcasting
Xingjian SHI, Zhourong Chen, Hao Wang, Dit-Yan Yeung, Wai-kin Wong, and Wang-chun WOO. Convolutional lstm network: A machine learning approach for precipitation nowcasting. In C. Cortes, N. Lawrence, D. Lee, M. Sugiyama, and R. Garnett, editors,Advances in Neural Information Processing Systems, volume 28. Curran Associates, Inc., 2015. URL https://proceed...
work page 2015
-
[52]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. Attention is all you need. In I. Guyon, U. V on Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors,Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017. URL ht...
work page 2017
-
[53]
Diffusion convolutional recurrent neural network: Data-driven traffic forecasting
Yaguang Li, Rose Yu, Cyrus Shahabi, and Yan Liu. Diffusion convolutional recurrent neural network: Data-driven traffic forecasting. InInternational Conference on Learning Representations (ICLR ’18), 2018. 15
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.