Recognition: 2 theorem links
· Lean TheoremPhases of Muon: When Muon Eclipses SignSGD
Pith reviewed 2026-05-12 04:01 UTC · model grok-4.3
The pith
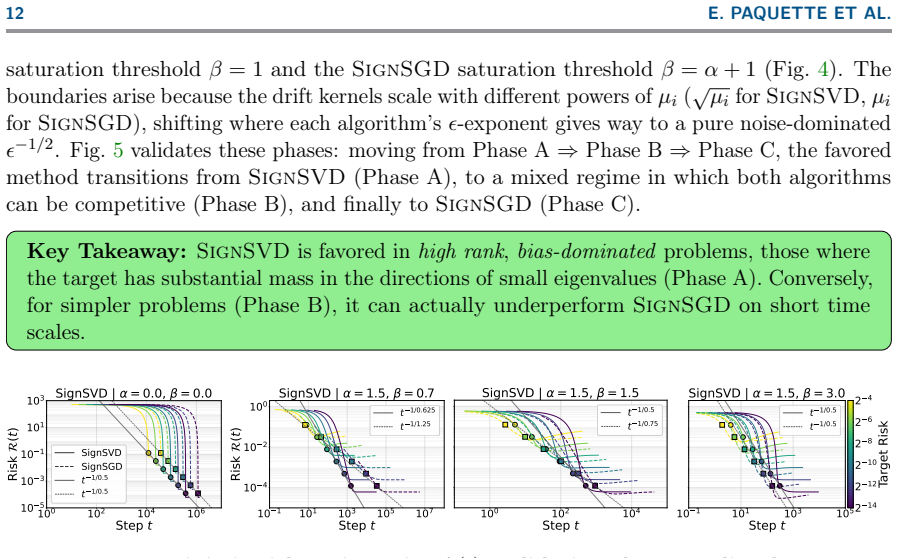
Power-law covariance splits Muon and SignSGD into three performance phases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We analyze stochastic spectral optimizers including Muon approximated by SignSVD and SignSGD as a proxy for Adam on a high-dimensional matrix-valued least squares problem. For large batch size SignSVD performs square-root preconditioning with respect to the data covariance spectrum while for small batch size smaller eigenmodes behave like SGD. SignSGD performs no preconditioning and has no transition, leading to different optimal learning rates and convergence characteristics. An analysis of a power law covariance model with data exponent alpha and target exponent beta shows there are three phases in the (alpha, beta) plane: one where SignSGD is uniformly favored, one where SignSVD is 1.0-f,
What carries the argument
The power-law covariance model with data exponent alpha and target exponent beta, which partitions the (alpha, beta) plane into three regions of relative performance between SignSVD and SignSGD.
Load-bearing premise
The high-dimensional matrix-valued least squares problem with power-law spectra is a faithful proxy for the learning dynamics of these optimizers in practical deep neural network training.
What would settle it
Simulating SignSVD and SignSGD on the matrix least-squares problem for a grid of alpha and beta values and finding that the measured convergence rates or final losses do not fall into the three predicted phases would falsify the claim.
Figures






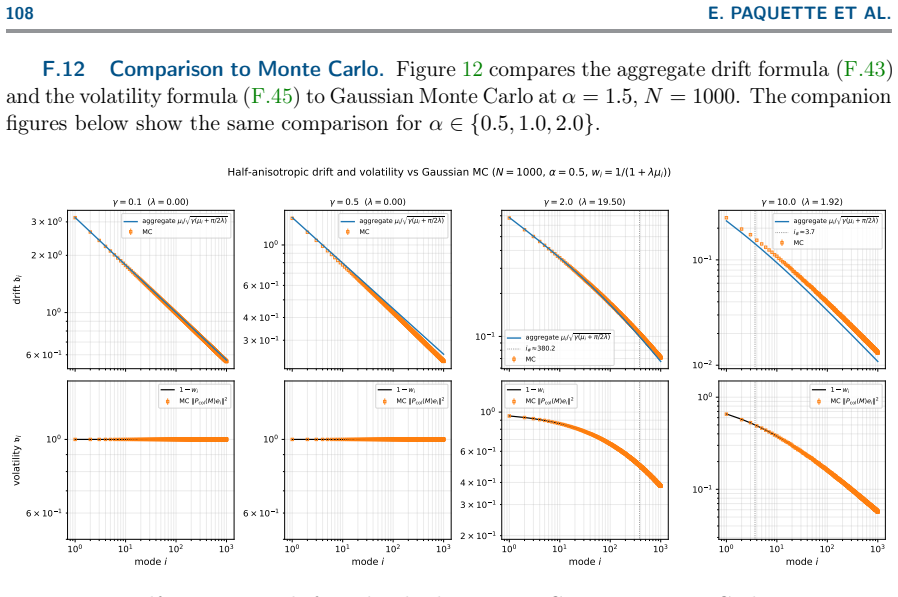
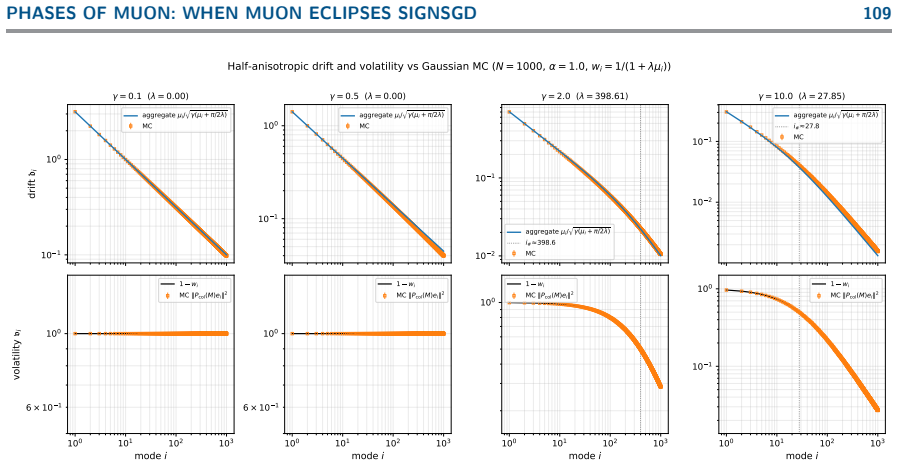
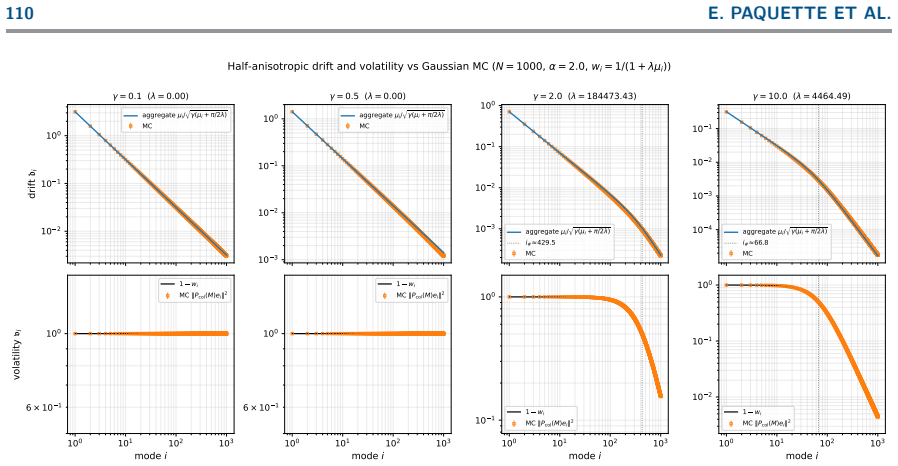
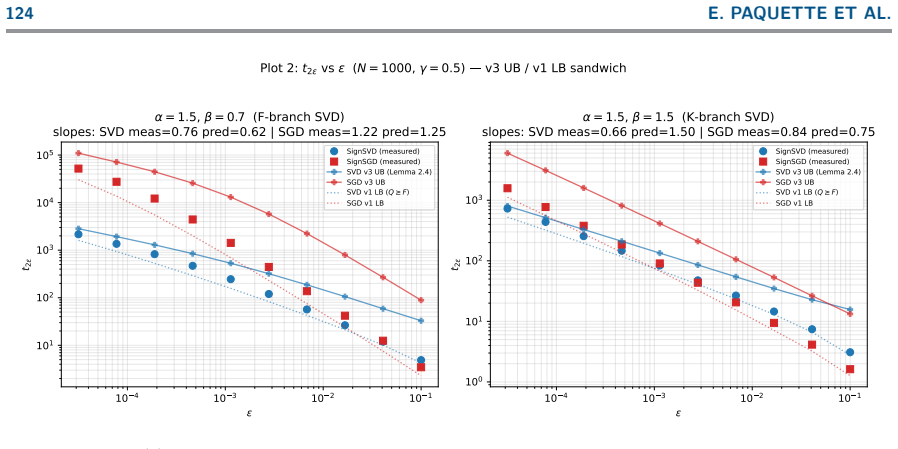


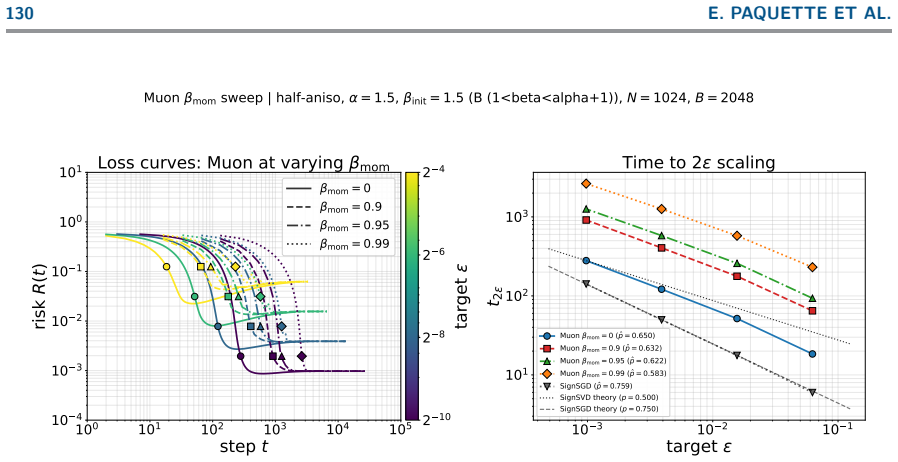
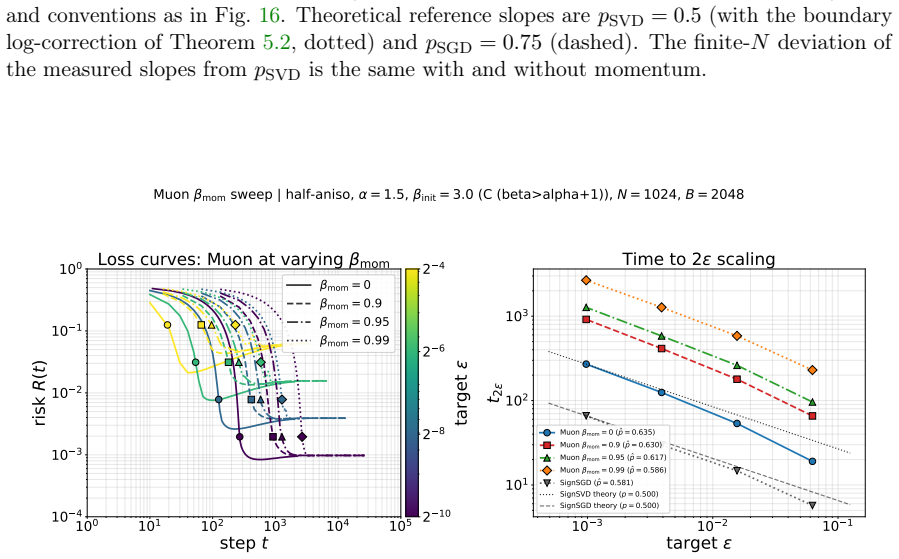

read the original abstract
Recently, Muon and related spectral optimizers have demonstrated strong empirical performance as scalable stochastic methods, often outperforming Adam. Yet their behaviour remains poorly understood. We analyze stochastic spectral optimizers, including Muon, on a high-dimensional matrix-valued least squares problem. We derive explicit deterministic dynamics that provide a tractable framework for studying learning behaviour with a focus on (stochastic) SignSVD, which Muon approximates, and (stochastic) SignSGD, the latter serving as a proxy for Adam. Our analysis shows that for large batch size, SignSVD performs a square-root preconditioning with respect to the data covariance spectrum, while for small batch size smaller eigenmodes behave like SGD, slowing down convergence. We contrast with SignSGD which for generic covariance performs no preconditioning and has no transition, leading to different optimal learning rates and convergence characteristics. The two methods match up to a constant factor with isotropic data, but behave differently with anisotropic data. An analysis of a power law covariance model with data exponent $\alpha$ and target exponent $\beta$ shows there are three phases in the $(\alpha,\beta)$ plane: one where SignSGD is uniformly favored, one where SignSVD is uniformly favored, and a third where the two methods exhibit a trade-off in performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes stochastic spectral optimizers including SignSVD (approximating Muon) and SignSGD (proxy for Adam) on a high-dimensional matrix-valued least-squares problem. It derives explicit deterministic dynamics for error evolution, shows that SignSVD performs square-root preconditioning for large batches (reverting to SGD-like behavior for small eigenmodes at small batches) while SignSGD performs no preconditioning, and uses a power-law covariance model with data exponent α and target exponent β to identify three phases in the (α, β) plane: one uniformly favoring SignSGD, one uniformly favoring SignSVD, and one with a performance trade-off.
Significance. If the deterministic approximations and phase classification hold, the work supplies a tractable theoretical framework for predicting when spectral methods outperform simpler sign-based optimizers as a function of spectral anisotropy, with explicit scaling exponents and falsifiable phase boundaries. The derivation of closed-form deterministic dynamics and the power-law analysis constitute clear strengths that enable direct comparison of convergence rates.
major comments (2)
- [Deterministic dynamics derivation] The derivation of deterministic dynamics (via expectation or large-batch limits) for the sign nonlinearity does not address whether higher moments or finite-batch fluctuations alter the effective convergence rates for small eigenmodes; this directly affects the location and existence of the trade-off phase in the (α, β) plane.
- [Power-law covariance model analysis] The power-law analysis classifies phases by comparing asymptotic scaling exponents obtained from the deterministic rates; without an explicit check that the mean trajectory governs typical sample paths under stochastic sign operations (especially when batch size is small), the trichotomy claim rests on an unverified approximation.
minor comments (2)
- [Abstract] The abstract states that the two methods 'match up to a constant factor with isotropic data' but does not quantify the constant or the precise isotropic limit.
- [Power-law model] Notation for the data exponent α and target exponent β should be introduced with their precise definitions before the phase-plane analysis.
Simulated Author's Rebuttal
We thank the referee for the careful reading and valuable feedback on our analysis of stochastic spectral optimizers. We address the two major comments point by point below, clarifying the scope of our deterministic approximations while acknowledging their limitations.
read point-by-point responses
-
Referee: The derivation of deterministic dynamics (via expectation or large-batch limits) for the sign nonlinearity does not address whether higher moments or finite-batch fluctuations alter the effective convergence rates for small eigenmodes; this directly affects the location and existence of the trade-off phase in the (α, β) plane.
Authors: Our derivation obtains deterministic dynamics by computing the expectation of the sign update (or taking the large-batch limit), which produces explicit per-eigenmode error recursions. In the manuscript we already note that small eigenmodes revert to SGD-like behavior under small batches because the sign operation on low-magnitude signals becomes effectively stochastic. We agree, however, that higher moments and finite-batch fluctuations are not analyzed in detail and could modify the effective rates, thereby shifting the trade-off phase boundaries. We will add a new subsection discussing the validity regime of the mean-field approximation, including a qualitative argument on when fluctuations remain negligible (large batch or sufficiently strong signal-to-noise per mode) and explicitly stating that a full stochastic approximation theory lies beyond the present scope. revision: partial
-
Referee: The power-law analysis classifies phases by comparing asymptotic scaling exponents obtained from the deterministic rates; without an explicit check that the mean trajectory governs typical sample paths under stochastic sign operations (especially when batch size is small), the trichotomy claim rests on an unverified approximation.
Authors: The three phases in the (α, β) plane are obtained by comparing the asymptotic scaling exponents that follow directly from the deterministic rates under the assumed power-law spectra. This yields explicit, falsifiable boundaries. We concur that the classification assumes the mean trajectory is representative of typical paths and that this assumption is least secure for small batches and small eigenmodes, where sign stochasticity can produce larger deviations. We will revise the power-law section to include a short paragraph that (i) states the mean-field nature of the derivation, (ii) identifies the parameter regimes (batch size relative to eigenvalue magnitude) where the approximation is expected to be accurate, and (iii) notes that concentration or large-deviation analysis of the stochastic sign process is left for future work. revision: partial
Circularity Check
No circularity: phases derived from explicit deterministic dynamics on posited power-law model
full rationale
The paper posits a high-dimensional matrix least-squares problem with power-law spectra as a proxy model, derives deterministic dynamics for SignSVD and SignSGD error evolution (via expectation/large-batch limits), obtains asymptotic convergence rates as functions of exponents α and β, and partitions the (α,β) plane by comparing those rates. This chain is self-contained first-principles analysis within the model; no parameter is fitted to the target data, no prediction is renamed from a fit, and no load-bearing step reduces to a self-citation or self-definition. The trichotomy is a direct consequence of the derived scalings, not tautological with the inputs.
Axiom & Free-Parameter Ledger
free parameters (2)
- α
- β
axioms (2)
- domain assumption Stochastic gradient updates can be replaced by deterministic differential equations in the high-dimensional limit
- domain assumption Power-law spectra adequately capture the anisotropy present in real training data
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearAn analysis of a power law covariance model with data exponent α and target exponent β shows there are three phases in the (α,β) plane
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearSignSVD performs a square-root preconditioning with respect to the data covariance spectrum
Reference graph
Works this paper leans on
-
[1]
Understanding Double Descent Requires A Fine- Grained Bias-Variance Decomposition
Ben Adlam and Jeffrey Pennington. Understanding Double Descent Requires A Fine- Grained Bias-Variance Decomposition. InAdvances in Neural Information Processing Systems (NeurIPS), volume 33, pages 11022–11032, 2020
work page 2020
-
[2]
Noah Amsel, David Persson, Christopher Musco, and Robert M. Gower. The Polar Express: Optimal Matrix Sign Methods and Their Application to the Muon Algorithm. InInternational Conference on Learning Representations (ICLR), 2026
work page 2026
-
[3]
Zhidong Bai and Jack W Silverstein.Spectral analysis of large dimensional random matrices, volume 20. Springer, 2010
work page 2010
-
[4]
Dissecting Adam: The Sign, Magnitude and Variance of Stochastic Gradients
Lukas Balles and Philipp Hennig. Dissecting Adam: The Sign, Magnitude and Variance of Stochastic Gradients. InProceedings of the 35th International Conference on Machine Learning (ICML), volume 80 ofProceedings of Machine Learning Research, pages 404–413. PMLR, PMLR, 2018
work page 2018
-
[5]
The Geometry of Sign Gradient Descent
Lukas Balles, Fabian Pedregosa, and Nicolas Le Roux. The Geometry of Sign Gradient Descent. InInternational Conference on Learning Representations (ICLR), pages 1–24, 2020
work page 2020
-
[6]
Gérard Ben Arous, Murat A Erdogdu, Nuri Mert Vural, and Denny Wu. Learning quadratic neural networks in high dimensions: SGD dynamics and scaling laws.arXiv preprint arXiv:2508.03688, 2025
-
[7]
Gérard Ben Arous, Reza Gheissari, and Aukosh Jagannath. High-dimensional limit theorems for SGD: Effective dynamics and critical scaling.Advances in Neural Information Processing Systems (NeurIPS), 35:25349–25362, 2022
work page 2022
-
[8]
Old optimizer, new norm: An anthology
Jeremy Bernstein and Laker Newhouse. Old optimizer, new norm: An anthology.arXiv preprint arXiv:2409.20325, 2024
-
[9]
signSGD: Compressed optimisation for non-convex problems
Jeremy Bernstein, Yu-Xiang Wang, Kamyar Azizzadenesheli, and Animashree Anandkumar. signSGD: Compressed optimisation for non-convex problems. InProceedings of the 35th 14 E. PAQUETTE ET AL. International Conference on Machine Learning (ICML), volume 80 ofProceedings of Machine Learning Research, pages 560–569. PMLR, 2018
work page 2018
-
[10]
A Dynamical Model of Neural Scaling Laws
Blake Bordelon, Alexander Atanasov, and Cengiz Pehlevan. A Dynamical Model of Neural Scaling Laws. InProceedings of the 41st International Conference on Machine Learning (ICML), volume 235 ofProceedings of Machine Learning Research, pages 4345–4382. PMLR, 2024
work page 2024
-
[11]
Blake Bordelon, Alexander Atanasov, and Cengiz Pehlevan. How Feature Learning Can Improve Neural Scaling Laws .International Conference on Learning Representations (ICLR), 2025
work page 2025
-
[12]
Andrea Caponnetto and Ernesto De Vito. Optimal rates for the regularized least-squares algorithm.Foundations of Computational Mathematics, 7:331–368, 2007
work page 2007
-
[13]
Stochastic spectral descent for restricted boltzmann machines
David Carlson, Volkan Cevher, and Lawrence Carin. Stochastic spectral descent for restricted boltzmann machines. InArtificial intelligence and statistics, pages 111–119. PMLR, 2015
work page 2015
-
[14]
Luigi Carratino, Alessandro Rudi, and Lorenzo Rosasco. Learning with sgd and random features.Advances in Neural Information Processing Systems (NeurIPS), 31, 2018
work page 2018
-
[15]
Lizhang Chen, Jonathan Li, and Qiang Liu. Muon optimizes under spectral norm con- straints.Transactions on Machine Learning Research (TMLR), 2026
work page 2026
-
[16]
Adaptive gradient methods at the edge of stability.arXiv preprint arXiv:2207.14484, 2022
Jeremy M Cohen, Behrooz Ghorbani, Shankar Krishnan, Naman Agarwal, Sourabh Medapati, Michal Badura, Daniel Suo, David Cardoze, Zachary Nado, George E Dahl, et al. Adaptive gradient methods at the edge of stability.arXiv preprint arXiv:2207.14484, 2022
-
[17]
Gradient descent on neural networks typically occurs at the edge of stability
Jeremy M Cohen, Simran Kaur, Yuanzhi Li, J Zico Kolter, and Ameet Talwalkar. Gradient descent on neural networks typically occurs at the edge of stability. InInternational Conference on Learning Representations (ICLR), pages 1–80, 2021
work page 2021
-
[18]
Elizabeth Collins-Woodfin, Courtney Paquette, Elliot Paquette, and Inbar Seroussi. Hitting the high-dimensional notes: an ODE for SGD learning dynamics on GLMs and multi-index models.Inf. Inference, 13(4):Paper No. iaae028, 107, 2024
work page 2024
-
[19]
The High Line: Exact Risk and Learning Rate Curves of Stochastic Adaptive Learning Rate Algorithms
Elizabeth Collins-Woodfin, Inbar Seroussi, Begoña García Malaxechebarría, Andrew W Mackenzie, Elliot Paquette, and Courtney Paquette. The High Line: Exact Risk and Learning Rate Curves of Stochastic Adaptive Learning Rate Algorithms. InAdvances in Neural Information Processing Systems (NeurIPS), volume 37, 2024
work page 2024
-
[20]
Cambridge University Press, 2022
Romain Couillet and Zhenyu Liao.Random Matrix Methods for Machine Learning. Cambridge University Press, 2022
work page 2022
-
[21]
arXiv preprint arXiv:2512.04299 , year =
Damek Davis and Dmitriy Drusvyatskiy. When do spectral gradient updates help in deep learning?arXiv preprint arXiv:2512.04299, 2025
-
[22]
The PHASES OF MUON: WHEN MUON ECLIPSES SIGNSGD 15 DeepMind JAX Ecosystem
DeepMind, Igor Babuschkin, Kate Baumli, Alison Bell, Surya Bhupatiraju, Jake Bruce, Peter Buchlovsky, David Budden, Trevor Cai, Aidan Clark, Ivo Danihelka, Antoine Dedieu, Claudio Fantacci, Jonathan Godwin, Chris Jones, Ross Hemsley, Tom Hennigan, Matteo Hessel, Shaobo Hou, Steven Kapturowski, Thomas Keck, Iurii Kemaev, Michael King, Markus Kunesch, Lena ...
work page 2020
-
[23]
Deepseek-v4: Towards highly efficient million-token context intelligence, 2026
DeepSeek-AI. Deepseek-v4: Towards highly efficient million-token context intelligence, 2026
work page 2026
-
[24]
Aymeric Dieuleveut and Francis Bach. Nonparametric stochastic approximation with large step-sizes.The Annals of Statistics, 44(4):1363 – 1399, 2016
work page 2016
-
[25]
TheNewton-MuonOptimizer.arXiv preprint arXiv:2604.01472, 2026
ZhehangDuand WeijieSu. TheNewton-MuonOptimizer.arXiv preprint arXiv:2604.01472, 2026
-
[26]
arXiv preprint arXiv:2502.04664 , year=
Chen Fan, Mark Schmidt, and Christos Thrampoulidis. Implicit Bias of Spectral Descent and Muon on Multiclass Separable Data.arXiv preprint arXiv:2502.04664, 2025
-
[27]
Dimension-adapted Momentum Outscales SGD.arXiv preprint arXiv:2505.16098, 2025
Damien Ferbach, Katie Everett, Gauthier Gidel, Elliot Paquette, and Courtney Paquette. Dimension-adapted Momentum Outscales SGD.arXiv preprint arXiv:2505.16098, 2025
-
[28]
Reza Gheissari and Aukosh Jagannath. Universality of high-dimensional scaling limits of stochastic gradient descent.arXiv preprint arXiv:2512.13634, 2025
-
[29]
Insights on Muon from Simple Quadratics.arXiv preprint arXiv:2602.11948, 2026
Antoine Gonon, Andreea-Alexandra Muşat, and Nicolas Boumal. Insights on Muon from Simple Quadratics.arXiv preprint arXiv:2602.11948, 2026
-
[30]
Shampoo: Preconditioned stochastic tensor optimization
Vineet Gupta, Tomer Koren, and Yoram Singer. Shampoo: Preconditioned stochastic tensor optimization. InProceedings of the 35th International Conference on Machine Learning (ICML), volume 80 ofProceedings of Machine Learning Research, pages 1842–1850. PMLR, 2018
work page 2018
-
[31]
David L. Hanson and F. T. Wright. A bound on tail probabilities for quadratic forms in independent random variables.The Annals of Mathematical Statistics, 42(3):1079–1083, 1971
work page 1971
-
[32]
Hong Hu and Yue M Lu. Universality laws for high-dimensional learning with random features.IEEE Transactions on Information Theory, 69(3):1932–1964, 2022
work page 1932
-
[33]
Aukosh Jagannath, Taj Jones-McCormick, and Varnan Sarangian. High-dimensional limit theorems for SGD: Momentum and Adaptive Step-sizes.arXiv preprint arXiv:2511.03952, 2025
-
[34]
Ruichen Jiang, Zakaria Mhammedi, Mehryar Mohri, and Aryan Mokhtari. Adaptive Matrix Online Learning through Smoothing with Guarantees for Nonsmooth Nonconvex Optimization.arXiv preprint arXiv:2602.08232, 2026
-
[35]
Muon: An optimizer for hidden layers in neural networks.URL https://kellerjordan
Keller Jordan, Yuchen Jin, Vlado Boza, You Jiacheng, Franz Cesista, Laker Newhouse, and Jeremy Bernstein. Muon: An optimizer for hidden layers in neural networks.URL https://kellerjordan. github. io/posts/muon, 6(3):4, 2024
work page 2024
-
[36]
Convergence of Muon with Newton-Schulz
Gyu Yeol Kim and Min-hwan Oh. Convergence of Muon with Newton-Schulz. InInterna- tional Conference on Learning Representations (ICLR), pages 1–29, 2026
work page 2026
-
[37]
Jihwan Kim, Dogyoon Song, and Chulhee Yun. Scaling Laws of SignSGD in Linear Regression: When Does It Outperform SGD? InInternational Conference on Learning Representations (ICLR), pages 1–89, 2026
work page 2026
-
[38]
Sharp Capacity Scaling of Spectral Optimizers in Learning Associative Memory
Juno Kim, Eshaan Nichani, Denny Wu, Alberto Bietti, and Jason D Lee. Sharp Ca- pacity Scaling of Spectral Optimizers in Learning Associative Memory.arXiv preprint arXiv:2603.26554, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[39]
Kiwon Lee, Andrew Cheng, Elliot Paquette, and Courtney Paquette. Trajectory of mini- batch momentum: batch size saturation and convergence in high dimensions.Advances in Neural Information Processing Systems (NeurIPS), 35:36944–36957, 2022. 16 E. PAQUETTE ET AL
work page 2022
-
[40]
Binghui Li, Kaifei Wang, Han Zhong, Pinyan Lu, and Liwei Wang. Muon in Associative Memory Learning: Training Dynamics and Scaling Laws.arXiv preprint arXiv:2602.05725, 2026
-
[41]
Risk bounds of accelerated SGD for overparameterized linear regression
Xuheng Li, Yihe Deng, Jingfeng Wu, Dongruo Zhou, and Quanquan Gu. Risk bounds of accelerated SGD for overparameterized linear regression. InInternational Conference on Learning Representations (ICLR), pages 1–69, 2024
work page 2024
-
[42]
Licong Lin, Jingfeng Wu, Sham M. Kakade, Peter L. Bartlett, and Jason D. Lee. Scaling Laws in Linear Regression: Compute, Parameters, and Data. InAdvances in Neural Information Processing Systems (NeurIPS), volume 37, pages 60556–60606, 2024
work page 2024
-
[43]
Muon is Scalable for LLM Training
Jingyuan Liu, Jianlin Su, Xingcheng Yao, Zhejun Jiang, Guokun Lai, Yulun Du, Yidao Qin, Weixin Xu, Enzhe Lu, Junjie Yan, et al. Muon is Scalable for LLM Training.arXiv preprint arXiv:2502.16982, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Cosmos: A Hybrid Adaptive Optimizer for Efficient Training of Large Language Models
Liming Liu, Zhenghao Xu, Zixuan Zhang, Hao Kang, Zichong Li, Chen Liang, Weizhu Chen, and Tuo Zhao. Cosmos: A Hybrid Adaptive Optimizer for Efficient Training of Large Language Models. InInternational Conference on Learning Representations (ICLR), 2026
work page 2026
-
[45]
Swan: SGD with Nor- malization and Whitening Enables Stateless LLM training
Chao Ma, Wenbo Gong, Meyer Scetbon, and Edward Meeds. Swan: SGD with Nor- malization and Whitening Enables Stateless LLM training. InProceedings of the 42nd International Conference on Machine Learning (ICML), volume 267 ofProceedings of Machine Learning Research, pages 41907–41942. PMLR, 2025
work page 2025
-
[46]
To Clip or not to Clip: the Dynamics of SGD with Gradient Clipping in High-dimensions
Noah Marshall, Ke Liang Xiao, Atish Agarwala, and Elliot Paquette. To Clip or not to Clip: the Dynamics of SGD with Gradient Clipping in High-dimensions. InInternational Conference on Learning Representations (ICLR), pages 1–37, 2025
work page 2025
-
[47]
Optimizing neural networks with Kronecker-factored approximate curvature
James Martens and Roger Grosse. Optimizing neural networks with Kronecker-factored approximate curvature. InProceedings of the 32nd International Conference on Machine Learning (ICML), volume 37 ofProceedings of Machine Learning Research, pages 2408–2417. PMLR, 2015
work page 2015
-
[48]
Song Mei and Andrea Montanari. The generalization error of random features regression: Precise asymptotics and the double descent curve.Communications on Pure and Applied Mathematics, 75(4):667–766, 2022
work page 2022
-
[49]
James A. Mingo and Roland Speicher.Free Probability and Random Matrices, volume 35 ofFields Institute Monographs. Springer New York, 2017
work page 2017
-
[50]
Phase transitions for feature learning in neural networks.arXiv preprint arXiv:2602.01434, 2026
Andrea Montanari and Zihao Wang. Phase transitions for feature learning in neural networks.arXiv preprint arXiv:2602.01434, 2026
-
[51]
Yuri Nesterov.Introductory lectures on convex optimization. Springer, 2004
work page 2004
-
[52]
SGD in the Large: Average-case Analysis, Asymptotics, and Stepsize Criticality
Courtney Paquette, Kiwon Lee, Fabian Pedregosa, and Elliot Paquette. SGD in the Large: Average-case Analysis, Asymptotics, and Stepsize Criticality. InProceedings of Thirty Fourth Conference on Learning Theory (COLT), volume 134, pages 3548–3626, 2021
work page 2021
-
[53]
Courtney Paquette and Elliot Paquette. Dynamics of Stochastic Momentum Methods on Large-scale, Quadratic Models.Advances in Neural Information Processing Systems (NeurIPS), 34:9229–9240, 2021
work page 2021
-
[54]
Courtney Paquette, Elliot Paquette, Ben Adlam, and Jeffrey Pennington. Homogenization of SGD in high-dimensions: exact dynamics and generalization properties.Mathematical Programming, pages 1–90, 2024. PHASES OF MUON: WHEN MUON ECLIPSES SIGNSGD 17
work page 2024
-
[55]
4+3 Phases of Compute-Optimal Neural Scaling Laws
Elliot Paquette, Courtney Paquette, Lechao Xiao, and Jeffrey Pennington. 4+3 Phases of Compute-Optimal Neural Scaling Laws. InAdvances in Neural Information Processing Systems (NeurIPS), volume 37, 2024
work page 2024
-
[56]
J. Pennington and P. Worah. Nonlinear random matrix theory for deep learning. In Advances in Neural Information Processing Systems (NeurIPS), 2017
work page 2017
-
[57]
Training Deep Learning Models with Norm-Constrained LMOs
Thomas Pethick, Wanyun Xie, Kimon Antonakopoulos, Zhenyu Zhu, Antonio Silveti-Falls, and Volkan Cevher. Training Deep Learning Models with Norm-Constrained LMOs. In Proceedings of the 42nd International Conference on Machine Learning (ICML), volume 267 ofProceedings of Machine Learning Research, pages 49069–49104. PMLR, 2025
work page 2025
-
[58]
Petrov.Sums of Independent Random Variables
Valentin V. Petrov.Sums of Independent Random Variables. Springer Berlin Heidelberg, 1975
work page 1975
-
[59]
Muon Dynamics as a Spectral Wasserstein Flow
Gabriel Peyré. Muon Dynamics as a Spectral Wasserstein Flow.arXiv preprint arXiv:2604.04891, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[60]
Loucas Pillaud-Vivien, Alessandro Rudi, and Francis Bach. Statistical optimality of stochastic gradient descent on hard learning problems through multiple passes.Advances in Neural Information Processing Systems (NeurIPS), 31, 2018
work page 2018
-
[61]
B.T. Polyak. Some methods of speeding up the convergence of iteration methods.USSR Computational Mathematics and Mathematical Physics, 04, 1964
work page 1964
-
[62]
Scaling collapse reveals universal dynamics in compute-optimally trained neural networks
Shikai Qiu, Lechao Xiao, Andrew Gordon Wilson, Jeffrey Pennington, and Atish Agarwala. Scaling collapse reveals universal dynamics in compute-optimally trained neural networks. InInternational Conference on Machine Learning, pages 50697–50720. PMLR, 2025
work page 2025
-
[63]
Artem Riabinin, Egor Shulgin, Kaja Gruntkowska, and Peter Richtárik. Gluon: Making Muon & Scion Great Again!(Bridging Theory and Practice of LMO-based Optimizers for LLMs).arXiv preprint arXiv:2505.13416, 2025
-
[64]
arXiv preprint arXiv:2505.02222 , year=
Ishaan Shah, Anthony M Polloreno, Karl Stratos, Philip Monk, Adarsh Chaluvaraju, Andrew Hojel, Andrew Ma, Anil Thomas, Ashish Tanwer, Darsh J Shah, et al. Practical Efficiency of Muon for Pretraining.arXiv preprint arXiv:2505.02222, 2025
-
[65]
On the Convergence Analysis of Muon
Wei Shen, Ruichuan Huang, Minhui Huang, Cong Shen, and Jiawei Zhang. On the Convergence Analysis of Muon.arXiv preprint arXiv:2505.23737, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[66]
Hao-Jun Michael Shi, Tsung-Hsien Lee, Shintaro Iwasaki, Jose Gallego-Posada, Zhijing Li, Kaushik Rangadurai, Dheevatsa Mudigere, and Michael Rabbat. A Distributed Data- Parallel Pytorch Implementation of the Distributed Shampoo Optimizer for Training Neural Networks At-Scale.arXiv preprint arXiv:2309.06497, 2023
-
[67]
Beyond the ideal: Analyzing the inexact Muon update
Egor Shulgin, Sultan AlRashed, Francesco Orabona, and Peter Richtárik. Beyond the Ideal: Analyzing the Inexact Muon Update.arXiv preprint arXiv:2510.19933, 2025
-
[68]
Simon, Dhruva Karkada, Nikhil Ghosh, and Mikhail Belkin
James B. Simon, Dhruva Karkada, Nikhil Ghosh, and Mikhail Belkin. More is better in modern machine learning: when infinite overparameterization is optimal and overfitting is obligatory. InInternational Conference on Learning Representations (ICLR), pages 1–40, 2024
work page 2024
-
[69]
arXiv preprint arXiv:2511.00674 , year=
Weijie Su. Isotropic Curvature Model for Understanding Deep Learning Optimization: Is Gradient Orthogonalization Optimal?arXiv preprint arXiv:2511.00674, 2025
-
[70]
Flavors of Margin: Implicit Bias of Steepest Descent in Homogeneous Neural Networks
Nikolaos Tsilivis, Eitan Gronich, Julia Kempe, and Gal Vardi. Flavors of Margin: Implicit Bias of Steepest Descent in Homogeneous Neural Networks. InInternational Conference on Learning Representations (ICLR), pages 1–27, 2025. 18 E. PAQUETTE ET AL
work page 2025
-
[71]
Orthogonalising gradients to speed up neural network optimisation
Mark Tuddenham, Adam Prügel-Bennett, and Jonathan Hare. Orthogonalising gradients to speed up neural network optimisation. InInternational Conference on Learning Representations (ICLR), pages 1–15, 2022
work page 2022
-
[72]
Accelerated sgd for non-strongly-convex least squares
Aditya Varre and Nicolas Flammarion. Accelerated sgd for non-strongly-convex least squares. InProceedings of Thirty Fifth Conference on Learning Theory (COLT), volume 135 ofProceedings of Machine Learning Research, pages 2062–2126, 2022
work page 2062
-
[73]
How Muon’s Spectral Design Benefits Generalization: A Study on Imbalanced Data
Bhavya Vasudeva, Puneesh Deora, Yize Zhao, Vatsal Sharan, and Christos Thrampoulidis. How Muon’s Spectral Design Benefits Generalization: A Study on Imbalanced Data. In International Conference on Learning Representations (ICLR), pages 1–36, 2026
work page 2026
-
[74]
Vershynin.High-dimensional probability: An introduction with applications in data science
R. Vershynin.High-dimensional probability: An introduction with applications in data science. Cambridge University Press, 2018
work page 2018
-
[75]
SOAP: Improving and Stabilizing Shampoo Using Adam
NikhilVyas, DepenMorwani, RosieZhao, MujinKwun, ItaiShapira, DavidBrandfonbrener, Lucas Janson, and Sham Kakade. SOAP: Improving and Stabilizing Shampoo Using Adam. InInternational Conference on Learning Representations (ICLR), pages 1–22, 2025
work page 2025
-
[76]
High-dimensional isotropic scaling dynamics of Muon and SGD
Guangyuan Wang, Elliot Paquette, and Atish Agarwala. High-dimensional isotropic scaling dynamics of Muon and SGD. InOPT 2025: Optimization for Machine Learning, 2025
work page 2025
-
[77]
MuonOutperformsAdaminTail-EndAssociative Memory Learning
Shuche Wang, Fengzhuo Zhang, Jiaxiang Li, Cunxiao Du, Chao Du, Tianyu Pang, Zhuoran Yang, MingyiHong, andVincentYFTan. MuonOutperformsAdaminTail-EndAssociative Memory Learning. InInternational Conference on Learning Representations (ICLR), pages 1–38, 2026
work page 2026
-
[78]
More than a toy: Random matrix models predict how real-world neural representations generalize
Alexander Wei, Wei Hu, and Jacob Steinhardt. More than a toy: Random matrix models predict how real-world neural representations generalize. InInternational Conference on Machine Learning (ICML), 2022
work page 2022
-
[79]
Fantastic Pretraining Optimizers and Where to Find Them
Kaiyue Wen, David Hall, Tengyu Ma, and Percy Liang. Fantastic Pretraining Optimizers and Where to Find Them. InInternational Conference on Learning Representations (ICLR), pages 1–107, 2026
work page 2026
-
[80]
Ke Liang Xiao, Noah Marshall, Atish Agarwala, and Elliot Paquette. Exact risk curves of signSGD in High-Dimensions: quantifying preconditioning and noise-compression effects. InInternational Conference on Learning Representations (ICLR), pages 1–48, 2025
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.