Recognition: 2 theorem links
· Lean TheoremKAN Text to Vision? The Exploration of Kolmogorov-Arnold Networks for Multi-Scale Sequence-Based Pose Animation from Sign Language Notation
Pith reviewed 2026-05-12 03:42 UTC · model grok-4.3
The pith
Multi-scale supervision with Kolmogorov-Arnold modules translates sign language notation into lower-error 2D pose sequences using fewer parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
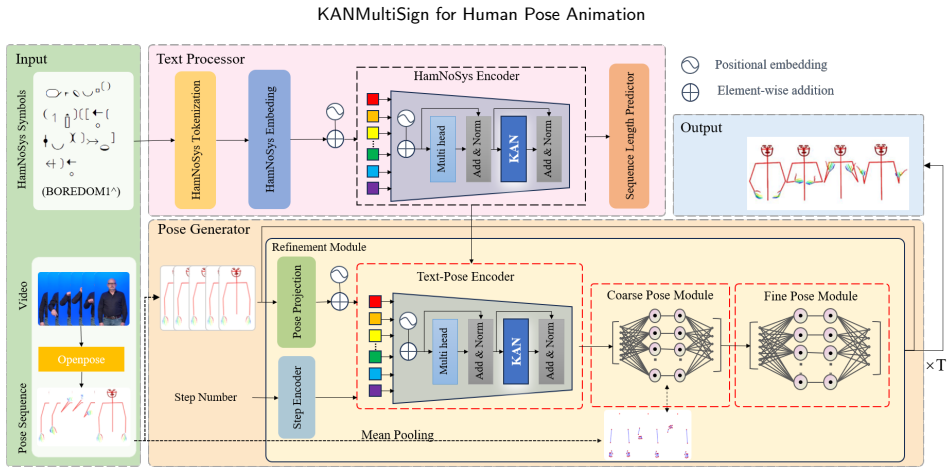
The authors present KANMultiSign, a Transformer-based sequence model that applies coarse-to-fine generation: an intermediate body-hand-face scaffold receives supervision first to enforce global coherence, after which hand articulations are refined. Kolmogorov-Arnold Network modules are inserted to model the mapping from discrete phonological symbols to continuous joint trajectories with fewer parameters than standard activations. Across four public sign-language corpora the combined system reduces dynamic time warping joint error relative to a notation-to-pose baseline while using substantially fewer parameters; controlled ablations confirm that multi-scale supervision supplies the main gain
What carries the argument
Coarse-to-fine multi-scale supervision that first aligns an intermediate body-hand-face scaffold and then refines hand joints, paired with Kolmogorov-Arnold Network modules that substitute learnable univariate function primitives for conventional activations inside a Transformer backbone.
If this is right
- Notation-conditioned pose generation can achieve tighter temporal alignment of body and hand joints when an explicit body-hand-face scaffold is supervised at an early stage.
- KAN modules allow the same accuracy level to be reached with a markedly smaller total parameter budget in sequence-to-sequence animation tasks.
- The framework supports language-independent scaling because the same multi-scale recipe produces gains on four distinct sign-language corpora.
- Parameter-efficient modeling of non-linear symbol-to-motion mappings becomes practical once multi-scale supervision is in place, reducing the need for very large Transformer models.
Where Pith is reading between the lines
- The same scaffold-plus-refinement pattern could be tested on other sparse-to-dense kinematic tasks such as generating gestures from text descriptions.
- If the KAN parameter savings hold under longer sequences, real-time sign animation on mobile devices becomes more feasible.
- Extending the notation input to include continuous signing streams rather than isolated glosses would test whether the learned mapping generalizes beyond short phrases.
- Similar hierarchical supervision might reduce error in other animation domains where global structure must precede local detail, such as facial expression synthesis from phonetic input.
Load-bearing premise
The coarse-to-fine multi-scale supervision together with the KAN modules will reliably map discrete notation symbols onto continuous body kinematics across languages without introducing timing artifacts or requiring per-language retuning.
What would settle it
Running the identical architecture on a held-out sign-language corpus while removing the intermediate scaffold supervision and measuring whether dynamic time warping joint error rises back to or above the baseline level.
Figures












read the original abstract
Sign language production from symbolic notation offers a scalable route to accessible sign animation. We present KANMultiSign, a multi-scale sequence generator that translates HamNoSys notation into two-dimensional human pose sequences. Our framework makes two complementary contributions. First, we introduce a coarse-to-fine generation strategy with multi-scale supervision: the model is first guided by an intermediate body--hand--face scaffold to encourage global structural coherence, and then refines fine-grained hand articulation to improve finger-level detail. Second, we investigate integrating Kolmogorov--Arnold Network modules into a Transformer backbone, using learnable univariate function primitives to model the highly non-linear mapping from discrete phonological symbols to continuous body kinematics with a compact parameterization. Experiments on multiple public corpora spanning Polish, German, Greek, and French sign languages show consistent reductions in dynamic time warping based joint error compared with a strong notation-to-pose baseline, while using substantially fewer parameters. Controlled ablations further indicate that KAN-based variants substantially reduce parameter count while maintaining competitive performance when coupled with multi-scale supervision, rather than serving as the main driver of accuracy gains. These findings position multi-scale supervision as the key mechanism for improving notation-conditioned pose generation, with KAN offering a compact alternative for efficient modeling. Our code will be publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces KANMultiSign, a Transformer-based sequence generator that converts HamNoSys sign-language notation into 2D pose sequences. It proposes two main ideas: a coarse-to-fine multi-scale supervision scheme that first uses an intermediate body-hand-face scaffold and then refines hand articulation, and the insertion of Kolmogorov-Arnold Network (KAN) modules to model the non-linear notation-to-kinematics mapping with fewer parameters than standard MLPs. Experiments across Polish, German, Greek, and French corpora are reported to yield lower dynamic-time-warping joint error than a strong baseline while using substantially fewer parameters; ablations attribute the accuracy gains primarily to the multi-scale supervision rather than to the KAN components.
Significance. If the quantitative results and ablation controls hold, the work would usefully demonstrate that multi-scale supervision can improve structural coherence in notation-conditioned pose generation and that KAN modules offer a compact parameterization alternative to MLPs in this domain. The cross-lingual evaluation on four public corpora and the stated intention to release code are positive elements that would support reproducibility and generalizability claims.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experiments): the claims of 'consistent reductions in dynamic time warping based joint error' and 'substantially fewer parameters' are presented without any numerical values, baseline specifications, error bars, or references to specific tables or figures. This absence prevents assessment of effect size and statistical reliability, which are load-bearing for the central empirical contribution.
- [§3.2] §3.2 (KAN integration): the description of how KAN modules replace or augment MLP layers in the Transformer backbone lacks explicit equations for the univariate function primitives, their initialization, or the precise locations of insertion. Without these details the claim of 'compact parameterization' for the non-linear mapping cannot be verified or reproduced.
minor comments (3)
- [Abstract] Define all acronyms (DTW, KAN, HamNoSys, etc.) on first use in the abstract and introduction.
- [§3.1] Add a diagram or pseudocode for the coarse-to-fine scaffold generation and loss weighting schedule to clarify the multi-scale supervision procedure.
- [§4.3] Ensure that the ablation tables explicitly isolate the contribution of KAN versus multi-scale supervision with matched parameter budgets.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that greater specificity in the abstract and experimental section, along with additional technical details on the KAN modules, will improve clarity and reproducibility. We address each major comment below and will incorporate revisions in the next version of the manuscript.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the claims of 'consistent reductions in dynamic time warping based joint error' and 'substantially fewer parameters' are presented without any numerical values, baseline specifications, error bars, or references to specific tables or figures. This absence prevents assessment of effect size and statistical reliability, which are load-bearing for the central empirical contribution.
Authors: We agree that the abstract and §4 would benefit from explicit numerical values, baseline details, and references to support the claims. In the revised manuscript, we will update the abstract to include specific DTW joint error reductions and parameter counts (with comparisons to the baseline), and we will add explicit cross-references to the relevant tables and figures in §4. We will also ensure error bars are reported where statistical reliability is assessed. These changes directly address the need for quantifiable effect sizes without altering the underlying experimental results. revision: yes
-
Referee: [§3.2] §3.2 (KAN integration): the description of how KAN modules replace or augment MLP layers in the Transformer backbone lacks explicit equations for the univariate function primitives, their initialization, or the precise locations of insertion. Without these details the claim of 'compact parameterization' for the non-linear mapping cannot be verified or reproduced.
Authors: We acknowledge that the current description in §3.2 lacks the necessary mathematical specificity for full verification. We will revise this section to include the explicit equations defining the univariate function primitives (including the spline-based formulation), details on their initialization procedure, and precise information on the insertion points within the Transformer layers. These additions will substantiate the compact parameterization advantage and support reproducibility of the KAN integration. revision: yes
Circularity Check
No significant circularity: empirical evaluation on external benchmarks
full rationale
The paper proposes KANMultiSign, a Transformer-based model with multi-scale supervision and optional KAN modules for translating HamNoSys notation to pose sequences. All load-bearing claims rest on controlled experiments across four independent public sign-language corpora, using DTW joint error against a strong baseline and ablations that isolate multi-scale supervision versus KAN parameterization. No equations, predictions, or uniqueness theorems are presented that reduce by construction to fitted parameters or self-citations defined inside the paper; the reported gains are measured on held-out external data with standard metrics. This structure is self-contained and falsifiable outside the authors' fitted values.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption KAN modules provide a compact parameterization for highly non-linear mappings from discrete symbols to continuous kinematics
- domain assumption Multi-scale supervision with an intermediate scaffold improves global structural coherence and fine-grained detail
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
We investigate integrating Kolmogorov–Arnold Network modules into a Transformer backbone, using learnable univariate function primitives to model the highly non-linear mapping...
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
multi-scale coarse-to-fine generation strategy with an intermediate body–hand–face scaffold
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Adam: A Method for Stochastic Optimization
Adam, K.D.B.J., et al., 2014. A method for stochastic optimization. arXiv preprint arXiv:1412.6980 1412
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[2]
Ahuja, C., Morency, L.P., 2019. Language2pose: Natural language grounded pose forecasting, in: 2019 International Conference on 3D Vision (3DV), IEEE. pp. 719–728
work page 2019
-
[3]
Arkushin, R.S., Moryossef, A., Fried, O., 2023. Ham2pose: Animat- ingsignlanguagenotationintoposesequences,in:Proceedingsofthe IEEE/CVFConferenceonComputerVisionandPatternRecognition, pp. 21046–21056
work page 2023
-
[4]
URL: https://arxiv.org/abs/2406.09087, arXiv:2406.09087
Azam,B.,Akhtar,N.,2024.Suitabilityofkansforcomputervision:A preliminary investigation. URL: https://arxiv.org/abs/2406.09087, arXiv:2406.09087
-
[5]
Bangham,J.A.,Cox,S.,Elliott,R.,Glauert,J.R.,Marshall,I.,Rankov, S., Wells, M., 2000. Virtual signing: Capture, animation, storage and transmission-an overview of the visicast project, in: IEE Seminar on speechand languageprocessing fordisabledand elderlypeople (Ref. No. 2000/025), IET. pp. 6–1
work page 2000
-
[6]
Bhattacharya, U., Childs, E., Rewkowski, N., Manocha, D., 2021. Speech2affectivegestures: Synthesizing co-speech gestures with gen- erative adversarial affective expression learning, in: Proceedings of the 29th ACM International Conference on Multimedia, pp. 2027– 2036
work page 2021
-
[7]
Convolutional kolmogorov-arnold networks,
Bodner,A.D.,Tepsich,A.S.,Spolski,J.N.,Pourteau,S.,2025.Convo- lutional kolmogorov-arnold networks. URL:https://arxiv.org/abs/ 2406.13155, arXiv:2406.13155
-
[8]
Constructive approximation 30, 653–675
Braun,J.,Griebel,M.,2009.OnaconstructiveproofofKolmogorov’s superposition theorem. Constructive approximation 30, 653–675
work page 2009
-
[9]
Kagnns: Kolmogorov-arnold net- worksmeetgraphlearning
Bresson, R., Nikolentzos, G., Panagopoulos, G., Chatzianastasis, M., Pang, J., Vazirgiannis, M., 2025. Kagnns: Kolmogorov-arnold net- worksmeetgraphlearning. URL: https://arxiv.org/abs/2406.18380, arXiv:2406.18380
-
[10]
Can kan work? exploring the potential of kolmogorov-arnold networks in computer vision
Cang, Y., hang liu, Y., Shi, L., 2024. Can kan work? exploring the potential of kolmogorov-arnold networks in computer vision. URL: https://arxiv.org/abs/2411.06727, arXiv:2411.06727
-
[11]
Cao, Z., Simon, T., Wei, S.E., Sheikh, Y., 2017. Realtime multi- person 2d pose estimation using part affinity fields, in: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 7291–7299
work page 2017
-
[12]
Kolmogorov-arnold graph neural networks
Carlo, G.D., Mastropietro, A., Anagnostopoulos, A., 2025. Kolmogorov-arnold graph neural networks. URL: https: //arxiv.org/abs/2406.18354, arXiv:2406.18354
-
[13]
Everybody dance now, in: Proceedings of the IEEE/CVF international conference on computer vision, pp
Chan, C., Ginosar, S., Zhou, T., Efros, A.A., 2019. Everybody dance now, in: Proceedings of the IEEE/CVF international conference on computer vision, pp. 5933–5942
work page 2019
-
[14]
Dang, L., Nie, Y., Long, C., Zhang, Q., Li, G., 2021. Msr-gcn: Multi-scale residual graph convolution networks for human motion prediction,in:ProceedingsoftheIEEE/CVFinternationalconference on computer vision, pp. 11467–11476
work page 2021
- [15]
-
[16]
Diffusion models beat gans on image synthesis
Dhariwal, P., Nichol, A., 2021. Diffusion models beat gans on image synthesis. Advances in Neural Information Processing Systems 34, 8780–8794
work page 2021
-
[17]
Ebling, S., Glauert, J., 2016. Building a swiss german sign language avatar with jasigning and evaluating it among the deaf community. Universal Access in the Information Society 15, 577–587
work page 2016
-
[18]
Efthimiou, E., Fontinea, S.E., Hanke, T., Glauert, J., Bowden, R., Braffort, A., Collet, C., Maragos, P., Goudenove, F., 2010. Dicta- sign–signlanguagerecognition,generationandmodelling:aresearch effort with applications in deaf communication, in: Proceedings of the 4th Workshop on the Representation and Processing of Sign Languages: Corpora and Sign Lang...
work page 2010
-
[19]
Ghosh, A., Cheema, N., Oguz, C., Theobalt, C., Slusallek, P., 2021. Synthesis of compositional animations from textual descriptions, in: ProceedingsoftheIEEE/CVFInternationalConferenceonComputer Vision, pp. 1396–1406
work page 2021
-
[20]
Guo, C., Zou, S., Zuo, X., Wang, S., Ji, W., Li, X., Cheng, L.,
- [21]
-
[22]
Hanke, T., 2004. Hamnosys-representing sign language data in language resources and language processing contexts, in: LREC, pp. 1–6
work page 2004
-
[23]
Denoising diffusion probabilistic models
Ho, J., Jain, A., Abbeel, P., 2020. Denoising diffusion probabilistic models. Advances in Neural Information Processing Systems 33, 6840–6851
work page 2020
-
[24]
Motion puzzle: Arbitrary motion style transfer by body part
Jang, D.K., Park, S., Lee, S.H., 2022. Motion puzzle: Arbitrary motion style transfer by body part. ACM Transactions on Graphics (TOG) 41, 1–16
work page 2022
-
[25]
Machinetrans- lationbetweenspokenlanguagesandsignedlanguagesrepresentedin signwriting
Jiang,Z.,Moryossef,A.,Müller,M.,Ebling,S.,2022. Machinetrans- lationbetweenspokenlanguagesandsignedlanguagesrepresentedin signwriting. URL: https://arxiv.org/abs/2210.05404
-
[26]
Gkan: Graph kolmogorov-arnold networks,
Kiamari, M., Kiamari, M., Krishnamachari, B., 2024. Gkan: Graph kolmogorov-arnold networks. URL: https://arxiv.org/abs/2406. 06470, arXiv:2406.06470
-
[27]
Kolmogorov, A.N., 1961. On the representation of continuous func- tions of several variables by superpositions of continuous functions of a smaller number of variables. American Mathematical Society
work page 1961
-
[28]
U-kan makes strong backbone for medical image seg- mentation and generation
Li, C., Liu, X., Li, W., Wang, C., Liu, H., Liu, Y., Chen, Z., Yuan, Y., 2024. U-kan makes strong backbone for medical image seg- mentation and generation. URL:https://arxiv.org/abs/2406.02918, arXiv:2406.02918
-
[29]
Linde-Usiekniewicz, J., Czajkowska-Kisil, M., Łacheta, J., Rutkowski, P., 2014. A corpus-based dictionary of polish sign language(pjm),in:ProceedingsoftheXVIEURALEXInternational Page 18 of 19 KANMultiSign for Human Pose Animation Congress: The user in focus, pp. 365–376
work page 2014
-
[30]
KAN: Kolmogorov-Arnold Networks
Liu, Z., Wang, Y., Vaidya, S., Ruehle, F., Halverson, J., Soljačić, M., Hou, T.Y., Tegmark, M., 2024. Kan: Kolmogorov-arnold networks. arXiv:2404.19756
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Liu, Z., Zhang, H., Chen, Z., Wang, Z., Ouyang, W., 2020. Disen- tangling and unifying graph convolutions for skeleton-based action recognition, in: Proceedings of the IEEE/CVF conference on com- puter vision and pattern recognition, pp. 143–152
work page 2020
-
[32]
Matthes, S., Hanke, T., Regen, A., Storz, J., Worseck, S., Efthimiou, E.,Dimou,A.L.,Braffort,A.,Glauert,J.,Safar,E.,2012. Dicta-sign- building a multilingual sign language corpus, in: 5th Workshop on the Representation and Processing of Sign Languages: Interactions between Corpus and Lexicon. Satellite Workshop to the eighth Inter- national Conference on ...
work page 2012
-
[33]
International day of sign languages
Nations, U., 2022. International day of sign languages. https: //www.un.org/en/observances/sign-languages-day
work page 2022
-
[34]
Temos: Generating diverse human motions from textual descriptions, in: ECCV
Petrovich, M., Black, M.J., Varol, G., 2022. Temos: Generating diverse human motions from textual descriptions, in: ECCV
work page 2022
-
[35]
Prillwitz, S., Hanke, T., König, S., Konrad, R., Langer, G., Schwarz, A., 2008. Dgs corpus project–development of a corpus based electronic dictionary german sign language/german, in: sign-lang@ LREC2008,EuropeanLanguageResourcesAssociation(ELRA).pp. 159–164
work page 2008
-
[36]
All you need in sign language production
Rastgoo,R.,Kiani,K.,Escalera,S.,Athitsos,V.,Sabokrou,M.,2022. All you need in sign language production. URL:http://arxiv.org/ abs/2201.01609, arXiv:2201.01609 [cs]
-
[37]
Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
Saharia, C., Chan, W., Saxena, S., Li, L., Whang, J., Denton, E.L., Ghasemipour, S.K.S., Ayan, B.K., Mahdavi, S.S., Lopes, R.G., Sali- mans, T., Ho, J., Fleet, D.J., Norouzi, M., 2022. Photorealistic text- to-image diffusion models with deep language understanding. ArXiv abs/2205.11487
work page internal anchor Pith review arXiv 2022
-
[38]
Sign language and linguistic universals
Sandler, W., Lillo-Martin, D., 2006. Sign language and linguistic universals. Cambridge University Press
work page 2006
-
[39]
Saunders, B., Camgoz, N.C., Bowden, R., 2020. Progressive trans- formers for end-to-end sign language production, in: European Con- ference on Computer Vision, Springer. pp. 687–705
work page 2020
-
[40]
Pose- guided fine-grained sign language video generation
Shi, T., Hu, L., Shang, F., Feng, J., Liu, P., Feng, W., 2024. Pose- guided fine-grained sign language video generation. URL:https: //arxiv.org/abs/2409.16709, arXiv:2409.16709
-
[41]
Sohl-Dickstein, J., Weiss, E., Maheswaranathan, N., Ganguli, S.,
-
[42]
Deep unsupervised learning using nonequilibrium thermody- namics, in: International Conference on Machine Learning, PMLR. pp. 2256–2265
-
[43]
Stoll, S., Camgoz, N.C., Hadfield, S., Bowden, R., 2020. Text2sign: towards sign language production using neural machine translation and generative adversarial networks. International Journal of Com- puter Vision 128, 891–908
work page 2020
-
[44]
Tevet, G., Raab, S., Gordon, B., Shafir, Y., Cohen-Or, D., Bermano, A.H.,2022. Humanmotiondiffusionmodel. ArXivabs/2209.14916
work page internal anchor Pith review arXiv 2022
-
[45]
Vaca-Rubio, C.J., Blanco, L., Pereira, R., Caus, M., 2024. Kolmogorov-arnold networks (kans) for time series analysis, in: 2024 IEEE Globecom Workshops (GC Wkshps), IEEE. p. 1–6. URL: http://dx.doi.org/10.1109/GCWkshp64532.2024.11100692, doi:10.1109/gcwkshp64532.2024.11100692
-
[46]
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez, A.N., Kaiser, Ł., Polosukhin, I., 2017. Attention is all you need. Advances in neural information processing systems 30
work page 2017
-
[47]
Walsh, H., Saunders, B., Bowden, R., 2022. Changing the represen- tation: Examining language representation for neural sign language production,in:Proceedingsofthe7thInternationalWorkshoponSign Language Translation and Avatar Technology: The Junction of the Visual and the Textual: Challenges and Perspectives, pp. 117–124
work page 2022
-
[48]
Advanced sign language video generation with compressed and quantized multi-condition tokenization
Wang, C., Deng, Z., Jiang, Z., Yin, Y., Shen, F., Cheng, Z., Ge, S., Gan, S., Gu, Q., 2025. Advanced sign language video generation with compressed and quantized multi-condition tokenization. URL: https://arxiv.org/abs/2506.15980, arXiv:2506.15980
-
[49]
WHO, 2021. Deafness and hearing loss. https://www.who.int/ news-room/fact-sheets/detail/deafness-and-hearing-loss
work page 2021
-
[50]
Wu, P., Wen, W., Li, H., Li, Z., Zeng, N., 2026. Ai- driven automation of aviation equipment inspection: Insights from a complex adaptive systems perspective. The Innovation 7, 101084. URL: https://www.sciencedirect.com/science/article/pii/ S2666675825002875, doi:https://doi.org/10.1016/j.xinn.2025.101084
-
[51]
Signmask: Structure-aware masked modeling for holistic 3d sign language pro- duction
Xia, Y., Zhan, Q., Luo, X., Shi, X., Wang, Y., 2026. Signmask: Structure-aware masked modeling for holistic 3d sign language pro- duction. ACMTrans.MultimediaComput.Commun.Appl.22. URL: https://doi.org/10.1145/3776750, doi:10.1145/3776750
-
[52]
Kolmogorov-arnold networks for time series: Bridging predictive power and interpretability
Xu, K., Chen, L., Wang, S., 2024. Kolmogorov-arnold networks for time series: Bridging predictive power and interpretability. URL: https://arxiv.org/abs/2406.02496, arXiv:2406.02496
-
[53]
Signavatars: A large- scale 3d sign language holistic motion dataset and benchmark
Yu, Z., Huang, S., Cheng, Y., Birdal, T., 2024. Signavatars: A large- scale 3d sign language holistic motion dataset and benchmark. URL: https://arxiv.org/abs/2310.20436, arXiv:2310.20436
-
[54]
Auxiliary domain joint adaptation and selection for cross-domain few-shot object detection
Zeng,N.,Li,Z.,Cheng,Z.,Teng,D.,Wu,P.,Li,M.,2026. Auxiliary domain joint adaptation and selection for cross-domain few-shot object detection. Neurocomputing 680, 133294. URL: https: //www.sciencedirect.com/science/article/pii/S0925231226006910, doi:https://doi.org/10.1016/j.neucom.2026.133294
-
[55]
Zhou, Q., Pei, C., Sun, F., HanJing, Gao, Z., Zhang, H., Xie, G., Pei, D., li, J., 2025. KAN-AD: Time series anomaly detection with kolmogorov–arnoldnetworks,in:Forty-secondInternationalConfer- ence on Machine Learning. URL:https://openreview.net/forum?id= LWQ4zu9SdQ
work page 2025
-
[56]
Zwitserlood, I., Verlinden, M., Ros, J., Van Der Schoot, S., Nether- lands,T.,2004. Syntheticsigningforthedeaf:Esign,in:Proceedings of the conference and workshop on assistive technologies for vision and hearing impairment (CVHI), Citeseer. Page 19 of 19
work page 2004
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.