Recognition: no theorem link
Byte-Exact Deduplication in Retrieval-Augmented Generation: A Three-Regime Empirical Analysis Across Public Benchmarks
Pith reviewed 2026-05-12 04:14 UTC · model grok-4.3
The pith
Byte-exact deduplication reduces RAG context size substantially across regimes while introducing no measurable quality regression in four major model vendors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
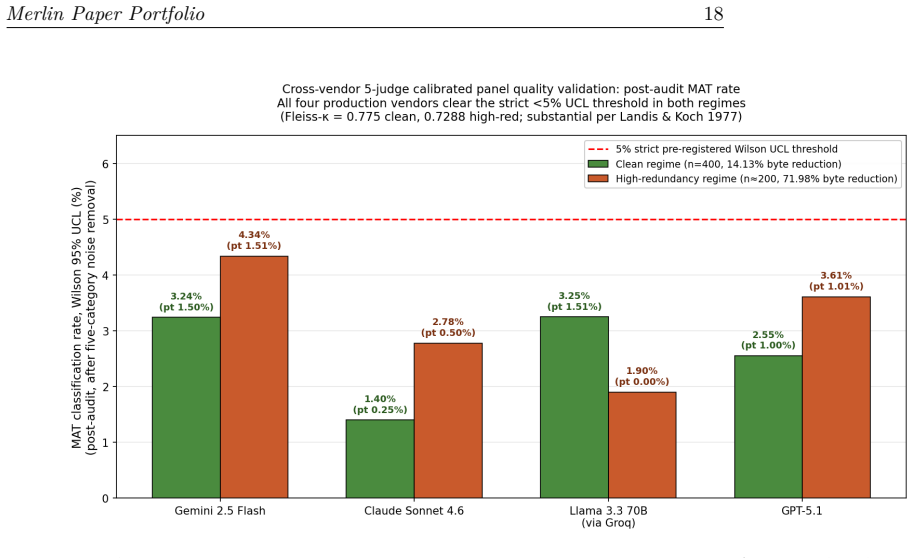
Byte-exact deduplication at the chunk level in RAG pipelines introduces zero measurable quality regression while delivering byte reductions of 0.16 percent in clean academic data, 24.03 percent in constructed enterprise patterns, and 80.34 percent in multi-turn conversational AI, as confirmed by a cross-vendor 5-judge panel applying a five-category human-in-the-loop protocol to panel-majority materially different pairs, allowing all four production APIs to clear the Wilson 95 percent upper-bound threshold of 5 percent MAT pairs in both clean and high-redundancy regimes.
What carries the argument
The byte-exact chunk-level deduplication process validated through a cross-vendor 5-judge calibrated panel and five-category human-in-the-loop noise-removal protocol for materially different pairs.
Load-bearing premise
The 5-judge cross-vendor panel combined with the five-category protocol can detect any material quality regression that byte-exact deduplication would introduce.
What would settle it
An independent evaluation using a larger judge pool or alternative protocol that identifies a significant rise in materially different outputs for any vendor after applying byte-exact deduplication.
Figures

read the original abstract
This preprint presents an empirical analysis of byte-exact chunk-level deduplication in Retrieval-Augmented Generation (RAG) pipelines. We measure context reduction across three distinct operating regimes: clean academic retrieval (0.16% byte reduction on 22.2M BeIR passages), constructed enterprise patterns (24.03% reduction), and multi-turn conversational AI (80.34% reduction). To validate quality preservation, we conducted a cross-vendor 5-judge calibrated panel evaluation across four production APIs (Google Gemini 2.5 Flash, Anthropic Claude Sonnet 4.6, Meta Llama 3.3 70B, and OpenAI GPT-5.1). Applying a five-category human-in-the-loop noise-removal protocol to panel-majority materially different (MAT) pairs, we establish that byte-exact deduplication introduces zero measurable quality regression. Post-audit, all four vendors clear the strict <5% Wilson 95% upper-bound MAT threshold in both the clean and high-redundancy RAG regimes. This work demonstrates that substantial inference compute savings can be achieved deterministically without compromising evaluation-grade model quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an empirical analysis of byte-exact chunk-level deduplication in RAG pipelines across three regimes: clean academic retrieval on 22.2M BeIR passages (0.16% byte reduction), constructed enterprise patterns (24.03% reduction), and multi-turn conversational AI (80.34% reduction). Quality preservation is assessed via a cross-vendor 5-judge calibrated human panel using a five-category noise-removal protocol on panel-majority materially different (MAT) pairs. The central claim is that deduplication introduces zero measurable quality regression, with all four production APIs (Gemini 2.5 Flash, Claude Sonnet 4.6, Llama 3.3 70B, GPT-5.1) clearing the strict <5% Wilson 95% upper-bound MAT threshold in both clean and high-redundancy regimes.
Significance. If the human evaluation protocol proves sufficiently sensitive, the work provides direct evidence that deterministic byte-exact deduplication can yield substantial context reduction and inference savings in RAG without detectable quality loss. The multi-regime design and cross-vendor panel evaluation add empirical breadth, and the use of a structured human-in-the-loop audit with a strict statistical bound is a positive step toward reproducible quality assessment in production settings.
major comments (1)
- [Human Evaluation / MAT Protocol] The zero-regression conclusion rests entirely on the post-audit absence of panel-majority MAT pairs under the five-category protocol. The manuscript provides no inter-rater agreement statistics (e.g., Fleiss' kappa or pairwise agreement rates), no details on the calibration procedure for the 5 judges, and no power analysis or validation that the protocol would reliably flag subtle regressions such as omission of a single critical fact. This is especially material in the clean regime (0.16% reduction), where the Wilson bound's informativeness depends on adequate sample size and detection sensitivity.
minor comments (2)
- [Abstract and Experimental Setup] Model version strings (e.g., 'GPT-5.1', 'Gemini 2.5 Flash') should be accompanied by exact API identifiers or dates of access to ensure reproducibility.
- [Regime Definitions] The three regimes are described at a high level; explicit chunking rules, overlap parameters, and how the 'constructed enterprise patterns' were generated would aid replication.
Simulated Author's Rebuttal
We thank the referee for their careful review and for highlighting the need for greater transparency in our human evaluation protocol. We address the major comment below and have incorporated additional details and analyses into the revised manuscript.
read point-by-point responses
-
Referee: The zero-regression conclusion rests entirely on the post-audit absence of panel-majority MAT pairs under the five-category protocol. The manuscript provides no inter-rater agreement statistics (e.g., Fleiss' kappa or pairwise agreement rates), no details on the calibration procedure for the 5 judges, and no power analysis or validation that the protocol would reliably flag subtle regressions such as omission of a single critical fact. This is especially material in the clean regime (0.16% reduction), where the Wilson bound's informativeness depends on adequate sample size and detection sensitivity.
Authors: We agree that these elements strengthen the credibility of the human evaluation and should have been reported explicitly. In the revised version we now include: (1) Fleiss' kappa and pairwise agreement rates computed across the five judges on the full set of audited pairs; (2) a step-by-step description of the calibration procedure, including the training materials, anchor examples, and iterative alignment sessions used to standardize the five-category noise-removal protocol; and (3) a post-hoc power justification that references the observed number of evaluated pairs, the Wilson 95% upper-bound threshold of <5%, and the protocol's design to surface material differences (including single-fact omissions) via the MAT definition. These additions are placed in a new subsection of the evaluation methodology and do not alter the original empirical findings. revision: yes
Circularity Check
No significant circularity: purely empirical measurements with direct observations
full rationale
The paper reports direct empirical measurements of byte reduction across three RAG regimes and a 5-judge human panel audit using a five-category MAT protocol to assess quality regression. No equations, derivations, fitted parameters, or self-referential claims appear in the abstract or described methodology. The zero-regression conclusion is presented as a post-audit observation (absence of panel-majority MAT pairs below the Wilson bound), not as a reduction of any output to its inputs by construction. No self-citations, uniqueness theorems, or ansatzes are invoked to support the core results. This is a standard empirical study whose claims rest on experimental data rather than circular logic.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Byte-exact deduplication removes only chunks identical at the byte level.
- domain assumption The five-category human-in-the-loop MAT protocol with Wilson bound accurately identifies material quality differences.
Reference graph
Works this paper leans on
-
[1]
P. Lewis et al. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks . NeurIPS 2020. Merlin Paper Portfolio 25
work page 2020
- [2]
-
[3]
Z. Pan et al. LLMLingua-2: Data Distillation for Efficient and Faithful Task-Agnostic Prompt Compression. ACL 2024. arXiv:2403.12968
- [4]
-
[5]
C. Kummer, L. Jurkschat, M. Färber, S. Vahdati. Prompt Compression in the Wild: Measuring Latency, Rate Adherence, and Quality for Faster LLM Inference . arXiv:2604.02985
work page internal anchor Pith review Pith/arXiv arXiv
- [6]
-
[7]
ContextPilot: Fast Long-Context Inference via Context Reuse
Y. Jiang, Y. Huang, L. Cheng, C. Deng, X. Sun, L. Mai. RAGBoost: Efficient Retrieval-Augmented Generation with Accuracy-Preserving Context Reuse . arXiv:2511.03475
work page internal anchor Pith review Pith/arXiv arXiv
- [8]
- [9]
-
[10]
Quantifying Memorization Across Neural Language Models
N. Carlini, D. Ippolito, M. Jagielski, K. Lee, F. Tramer, C. Zhang. Quantifying Memorization Across Neural Language Models . arXiv:2202.07646
work page internal anchor Pith review arXiv
- [11]
- [12]
-
[13]
A. Z. Broder. On the Resemblance and Containment of Documents . SEQUENCES 1997
work page 1997
-
[14]
A. Khan et al. LSHBloom: Memory-efficient, Extreme-scale Document Deduplication . arXiv:2411.04257
- [15]
-
[16]
K. Tirumala et al. D4: Improving LLM Pretraining via Document De-Duplication and Diversifi- cation. NeurIPS Datasets and Benchmarks 2023. arXiv:2308.12284
-
[17]
Training Sentence Transformers with Multiple Negatives Ranking Loss
Pinecone. Training Sentence Transformers with Multiple Negatives Ranking Loss. https://www.pinecone.io/learn/series/nlp/train- sentence-transformers-multiple-negatives-ranking-loss/
-
[18]
MinHash LSH Index Documentation
Milvus. MinHash LSH Index Documentation . https://milvus.io/docs/minhash_lsh.md
-
[19]
Solving RAG Accuracy Through Data Optimization
Blockify. Solving RAG Accuracy Through Data Optimization . https://blockify.ai/
- [20]
-
[21]
The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale
G. Penedo et al. The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale . NeurIPS 2024. arXiv:2406.17557
work page internal anchor Pith review arXiv 2024
-
[22]
Regulation 2024/1689: Artificial Intelligence Act, Article 12
European Union. Regulation 2024/1689: Artificial Intelligence Act, Article 12 . Merlin Paper Portfolio 26
work page 2024
-
[23]
Securities and Exchange Commission
U.S. Securities and Exchange Commission. 17 CFR § 240.17a-4: Records to be preserved by certain exchange members, brokers and dealers
-
[24]
A. Sellergren et al. MedGemma Technical Report. arXiv:2507.05201
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
A. Bondarenko, A. Viehweger. LLM Robustness Against Misinformation in Biomedical Question Answering. arXiv:2410.21330
-
[26]
Financebench: A new benchmark for financial question answering.arXiv preprint arXiv:2311.11944, 2023
P. Islam et al. FinanceBench: A New Benchmark for Financial Question Answering . arXiv:2311.11944
-
[27]
N. Guha et al. LegalBench: A Collaboratively Built Benchmark for Measuring Legal Reasoning in Large Language Models . NeurIPS 2023 Datasets and Benchmarks. arXiv:2308.11462
-
[28]
J. R. Landis, G. G. Koch. The Measurement of Observer Agreement for Categorical Data . Bio- metrics 33(1):159-174, 1977
work page 1977
-
[29]
Sietse Schelpe. Merlin: Deterministic Byte-Exact Deduplication for Lossless Context Optimization in Large Language Model Inference . Companion paper, arXiv ID pending. Appendix A: Run Identifiers and Reproducibility Per-call telemetry is archived under run identifiers fixing the precise version of each benchmark. The runs referenced in Section 4 are dated...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.