Recognition: no theorem link
Prompt Compression in the Wild: Measuring Latency, Rate Adherence, and Quality for Faster LLM Inference
Pith reviewed 2026-05-13 18:14 UTC · model grok-4.3
The pith
Prompt compression via LLMLingua yields up to 18% end-to-end LLM speedups when prompt length, ratio, and hardware align, with no measurable quality drop on summarization, code generation, or QA.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LLMLingua achieves up to 18% end-to-end speed-ups when prompt length, compression ratio, and hardware capacity are well matched, with response quality remaining statistically unchanged across summarization, code generation, and question answering tasks. Outside this operating window the compression step dominates and cancels the gains. Effective compression can also reduce memory usage enough to offload workloads from data center GPUs to commodity cards with only a 0.3 s latency increase. An open-source profiler predicts the latency break-even point for each model-hardware pair.
What carries the argument
The separation of compression preprocessing time from decoding latency, combined with the requirement that prompt length, compression ratio, and hardware capacity be matched for net gains.
If this is right
- When prompt length, compression ratio, and hardware are matched, end-to-end inference time drops by as much as 18 percent.
- Response quality on summarization, code generation, and QA stays statistically indistinguishable from the uncompressed baseline.
- Memory savings from compression can move workloads onto commodity GPUs with only a 0.3-second latency penalty.
- The released profiler identifies the break-even point for any given model and GPU before deployment.
Where Pith is reading between the lines
- The same matching logic could be applied to decide when to compress prompts in production RAG pipelines serving many concurrent users.
- If task metrics miss subtle factual omissions, real-user error rates could rise even when reported scores stay flat.
- Extending the profiler to closed-source models would let practitioners test the same trade-off without changing the underlying LLM.
- Combining prompt compression with other latency techniques such as speculative decoding might widen the useful operating window.
Load-bearing premise
Standard downstream metrics on summarization, code, and QA tasks are sufficient to confirm that compressed prompts retain every piece of information the original prompt supplied for the intended use.
What would settle it
A set of factual QA items where the original prompt produces correct answers but the compressed prompt produces incorrect answers at a rate high enough to shift the task score beyond statistical noise.
Figures




read the original abstract
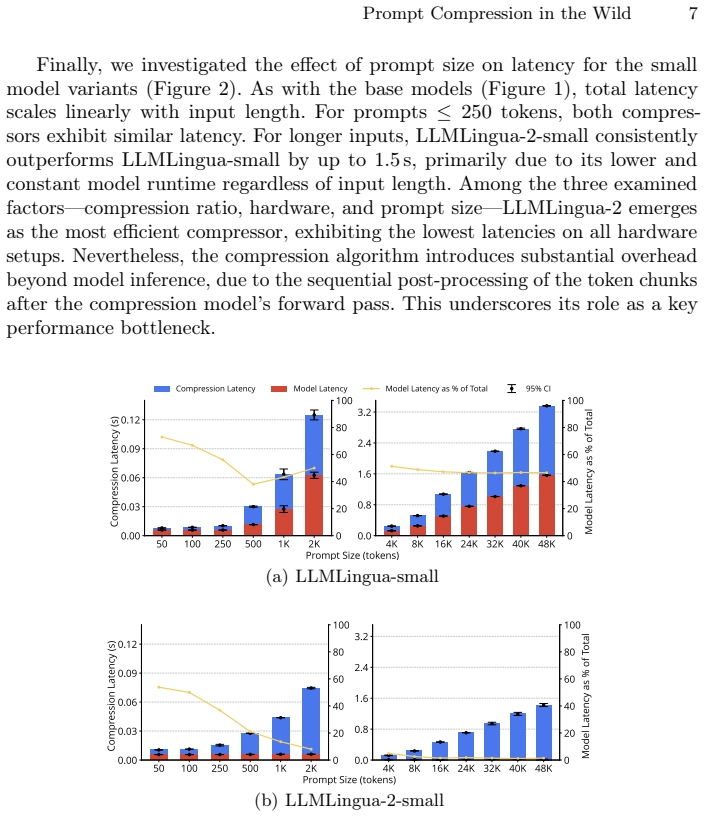
With the wide adoption of language models for IR -- and specifically RAG systems -- the latency of the underlying LLM becomes a crucial bottleneck, since the long contexts of retrieved passages lead large prompts and therefore, compute increase. Prompt compression, which reduces the size of input prompts while aiming to preserve performance on downstream tasks, has established itself as a cost-effective and low-latency method for accelerating inference in large language models. However, its usefulness depends on whether the additional preprocessing time during generation is offset by faster decoding. We present the first systematic, large-scale study of this trade-off, with thousands of runs and 30,000 queries across several open-source LLMs and three GPU classes. Our evaluation separates compression overhead from decoding latency while tracking output quality and memory usage. LLMLingua achieves up to 18% end-to-end speed-ups, when prompt length, compression ratio, and hardware capacity are well matched, with response quality remaining statistically unchanged across summarization, code generation, and question answering tasks. Outside this operating window, however, the compression step dominates and cancels out the gains. We also show that effective compression can reduce memory usage enough to offload workloads from data center GPUs to commodity cards, with only a 0.3s increase in latency. Our open-source profiler predicts the latency break-even point for each model-hardware setup, providing practical guidance on when prompt compression delivers real-world benefits.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a large-scale empirical study of prompt compression (focusing on LLMLingua) for accelerating LLM inference in IR/RAG settings. Across thousands of runs and 30k queries on multiple open-source LLMs and three GPU classes, it separates compression preprocessing overhead from decoding latency, measures memory usage, and evaluates output quality on summarization, code generation, and QA tasks. The central result is an operating window yielding up to 18% end-to-end speedups when prompt length, compression ratio, and hardware are matched, with quality remaining statistically unchanged; outside this window gains are canceled, and compression can enable offloading to lower-end hardware with modest latency cost. An open-source profiler is released to predict per-setup break-even points.
Significance. If the measurements hold, the work supplies concrete, hardware-aware guidance for when prompt compression delivers net benefits in production RAG pipelines rather than assuming universal gains. The scale, explicit overhead separation, cross-hardware coverage, and released profiler address a practical gap in efficient LLM deployment for information retrieval; the emphasis on the narrow operating window is a strength that prevents over-generalization.
minor comments (3)
- [§3] §3 (Methods): the description of how the 30k queries were sampled and balanced across tasks should include explicit criteria or statistics on prompt length distribution to support claims of representativeness.
- [§4.1] §4.1 (Latency results): the 18% speedup figure is reported for matched conditions; add a table or plot showing the exact prompt-length / ratio / GPU combinations that achieve it versus those that do not, to make the operating window reproducible.
- [§5] §5 (Profiler): the prediction accuracy of the open-source latency model should be quantified (e.g., mean absolute percentage error on held-out runs) rather than described qualitatively.
Simulated Author's Rebuttal
We thank the referee for the positive and accurate summary of our large-scale empirical study on prompt compression for LLM inference in IR/RAG settings. We appreciate the recognition of the practical value of separating compression overhead from decoding latency, the cross-hardware evaluation, and the released profiler for predicting break-even points. The recommendation for minor revision is noted.
Circularity Check
No significant circularity
full rationale
The paper reports purely empirical measurements of end-to-end latency, compression overhead, decoding time, quality metrics (ROUGE, exact match, pass@k), and memory usage across 30k queries, multiple LLMs, and GPU classes. No derivation chain, equations, or fitted parameters are presented as predictions; the profiler simply extrapolates observed break-even points from the collected data. No self-citation load-bearing steps, uniqueness theorems, or ansatzes appear. The central claim (up to 18% speedup inside a measured operating window) is a direct reporting of experimental outcomes rather than a reduction to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard statistical tests suffice to establish that quality remains unchanged
Forward citations
Cited by 2 Pith papers
-
Merlin: Deterministic Byte-Exact Deduplication for Lossless Context Optimization in Large Language Model Inference
Merlin achieves byte-exact deduplication of text at up to 8.7 GB/s using SIMD-optimized hashing, reducing LLM context sizes by 13.9-71% with no data loss.
-
Byte-Exact Deduplication in Retrieval-Augmented Generation: A Three-Regime Empirical Analysis Across Public Benchmarks
Byte-exact deduplication reduces RAG context size by 0.16% to 80.34% across three regimes with zero measurable quality regression per multi-vendor LLM evaluation.
Reference graph
Works this paper leans on
-
[1]
Bai, Y., Lv, X., Zhang, J., Lyu, H., Tang, J., Huang, Z., et al.: LongBench: A bilingual, multitask benchmark for long context understanding. In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (Aug 2024).https://doi.org/10.18653/v1/2024.acl-long.172
-
[2]
In: Pro- ceedings of the 38th International Conference on Neural Information Processing Systems
Cheng, X., Wang, X., Zhang, X., Ge, T., Chen, S.Q., Wei, F., et al.: xrag: extreme context compression for retrieval-augmented generation with one token. In: Pro- ceedings of the 38th International Conference on Neural Information Processing Systems. NIPS ’24 (2025),https://dl.acm.org/doi/10.5555/3737916.3741392
-
[3]
In: Vlachos, A., Augen- stein, I
Chevalier, A., Wettig, A., Ajith, A., Chen, D.: Adapting language models to compress contexts. In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (Dec 2023).https://doi.org/10.18653/v1/2023. emnlp-main.232
-
[4]
Dubey, A., Jauhri, A., Pandey, A., et al.: The llama 3 herd of models (2024), https://arxiv.org/abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
In: Findings of the Association for Computational Linguistics: ACL 2024 (Aug 2024).https://doi
Fei, W., Niu, X., Zhou, P., Hou, L., Bai, B., Deng, L., et al.: Extending context window of large language models via semantic compression. In: Findings of the Association for Computational Linguistics: ACL 2024 (Aug 2024).https://doi. org/10.18653/v1/2024.findings-acl.306
-
[6]
Ge, T., Jing, H., Wang, L., Wang, X., Chen, S.Q., Wei, F.: In-context autoencoder for context compression in a large language model. In: The Twelfth International Conference on Learning Representations (2024),https://openreview.net/forum? id=uREj4ZuGJE 14 C. Kummer et al
work page 2024
-
[7]
Hugging Face: Hugging face text generation inference (2023),https://github.com/ huggingface/text-generation-inference
work page 2023
-
[8]
Jha, S., Erdogan, L.E., Kim, S., Keutzer, K., Gholami, A.: Characterizing prompt compression methods for long context inference. In: Workshop on Efficient Systems for Foundation Models II @ ICML2024 (2024),https://openreview.net/forum? id=vs6CCDuK7l
work page 2024
-
[9]
Jiang, A.Q., Sablayrolles, A., Mensch, A., et al.: Mistral 7b (2023),https://arxiv. org/abs/2310.06825
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Jiang, H., Wu, Q., Lin, C.Y., Yang, Y., Qiu, L.: LLMLingua: Compressing prompts for accelerated inference of large language models. In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (Dec 2023). https://doi.org/10.18653/v1/2023.emnlp-main.825
-
[11]
InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
Jiang, H., Wu, Q., Luo, X., Li, D., Lin, C.Y., Yang, Y., et al.: LongLLMLingua: Accelerating and enhancing LLMs in long context scenarios via prompt compression. In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (Aug 2024).https://doi.org/10.18653/v1/ 2024.acl-long.91
-
[12]
Jung,H.,Kim,K.J.:Discretepromptcompressionwithreinforcementlearning.IEEE Access12, 72578–72587 (2024).https://doi.org/10.1109/ACCESS.2024.3403426
-
[13]
In: Proceedings of the 29th Symposium on Operating Systems Principles
Kwon, W., Li, Z., Zhuang, S., Sheng, Y., Zheng, L., Yu, C.H., et al.: Efficient memory management for large language model serving with PagedAttention. In: Proceedings of the 29th Symposium on Operating Systems Principles. SOSP ’23 (2023).https://doi.org/10.1145/3600006.3613165
-
[14]
Li, Y., Dong, B., Guerin, F., Lin, C.: Compressing context to enhance inference efficiency of large language models. In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (Dec 2023).https://doi.org/ 10.18653/v1/2023.emnlp-main.391
-
[15]
Liu, J., Li, L., Xiang, T., Wang, B., Qian, Y.: TCRA-LLM: Token compression retrieval augmented large language model for inference cost reduction. In: Findings of the Association for Computational Linguistics: EMNLP 2023 (Dec 2023).https: //doi.org/10.18653/v1/2023.findings-emnlp.655
-
[16]
In: Proceedings of the ACM on Web Conference 2025
Liu, Q., Wang, B., Wang, N., Mao, J.: Leveraging passage embeddings for efficient listwise reranking with large language models. In: Proceedings of the ACM on Web Conference 2025. WWW ’25 (2025).https://doi.org/10.1145/3696410.3714554
-
[17]
In: Proceedings of the 38th International Conference on Neural Information Processing Systems
Nagle, A., Girish, A., Bondaschi, M., Gastpar, M., Makkuva, A.V., Kim, H.: Fundamental limits of prompt compression: a rate-distortion framework for black- box language models. In: Proceedings of the 38th International Conference on Neural Information Processing Systems. NIPS ’24 (2024),https://dl.acm.org/ doi/10.5555/3737916.3740925
-
[18]
Ning, X., Lin, Z., Zhou, Z., Wang, Z., Yang, H., Wang, Y.: Skeleton-of-Thought: Prompting LLMs for efficient parallel generation. In: The Twelfth International Conference on Learning Representations (2024),https://openreview.net/forum? id=mqVgBbNCm9
work page 2024
-
[19]
In: Findings of the Association for Computational Linguistics: ACL 2024 (Aug 2024)
Pan, Z., Wu, Q., Jiang, H., Xia, M., Luo, X., Zhang, J., et al.: LLMLingua-2: Data distillation for efficient and faithful task-agnostic prompt compression. In: Findings of the Association for Computational Linguistics: ACL 2024 (Aug 2024). https://doi.org/10.18653/v1/2024.findings-acl.57
-
[20]
Wang, C., Yang, Y., Li, R., Sun, D., Cai, R., Zhang, Y., et al.: Adapting LLMs for efficient context processing through soft prompt compression. In: Proceedings of the International Conference on Modeling, Natural Language Processing and Machine Learning. CMNM ’24 (2024).https://doi.org/10.1145/3677779.3677794 Prompt Compression in the Wild 15
- [21]
-
[22]
Transformers: State-of-the-Art Natural Language Processing
Wolf, T., Debut, L., Sanh, V., Chaumond, J., Delangue, C., Moi, A., et al.: Trans- formers: State-of-the-art natural language processing. In: Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demon- strations (Oct 2020).https://doi.org/10.18653/v1/2020.emnlp-demos.6
-
[23]
Xu, F., Shi, W., Choi, E.: RECOMP: Improving retrieval-augmented LMs with context compression and selective augmentation. In: The Twelfth International Conference on Learning Representations (2024),https://openreview.net/forum? id=mlJLVigNHp
work page 2024
-
[24]
Zhou, Z., Ning, X., Hong, K., Fu, T., Xu, J., Li, S., et al.: A survey on efficient inference for large language models (2024),https://arxiv.org/abs/2404.14294
work page internal anchor Pith review arXiv 2024
-
[25]
Zhu, Y., Yuan, H., Wang, S., Liu, J., Liu, W., Deng, C., et al.: Large language models for information retrieval: A survey. ACM Trans. Inf. Syst.44(1) (Nov 2025). https://doi.org/10.1145/3748304
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.