Recognition: no theorem link
Minimizing Worst-Case Weighted Latency for Multi-Robot Persistent Monitoring: Theory and RL-Based Solutions
Pith reviewed 2026-05-12 03:56 UTC · model grok-4.3
The pith
Tail-performance objectives reformulated as average-reward MDPs let RL minimize worst-case weighted latency in multi-robot persistent monitoring.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the proposed tail-performance objectives generalize the standard worst-case latency objective, admit optimal strategies, can be approximated to arbitrary accuracy by periodic solutions, and reduce to the average-reward optimization problem of the TWLO-MDP, an event-driven model with discretized waiting times. Reinforcement-learning methods applied to this MDP therefore solve the original functional optimization problems and yield monitoring policies that outperform representative baselines.
What carries the argument
The TWLO-MDP, an event-driven Markov decision process obtained by discretizing waiting times at nodes, which converts the tail-performance objective into an equivalent average-reward criterion.
If this is right
- Optimal strategies exist for each member of the new family of tail-performance objectives.
- Any tail objective can be approximated to arbitrary accuracy by a periodic joint trajectory.
- The infinite-horizon problem reduces to a finite-state average-reward MDP with event-driven transitions.
- Reinforcement learning on the TWLO-MDP produces trajectories whose realized worst-case weighted latency is lower than that of representative heuristic baselines.
- The introduced M2Bench platform supplies a common testbed for comparing heuristic and learning-based monitoring algorithms.
Where Pith is reading between the lines
- The same tail-objective construction could be applied to other infinite-horizon multi-robot tasks such as coverage or data ferrying where steady-state performance matters more than initial transients.
- Because the state space grows with the number of robots rather than with the time horizon, the approach may remain tractable for moderate team sizes once discretization granularity is fixed.
- The explicit reduction to an average-reward MDP opens the possibility of importing exact solution techniques from average-reward theory for graphs with special structure.
Load-bearing premise
The tail-performance objectives meaningfully separate transient from asymptotic behavior in a way that produces practically superior monitoring trajectories compared with the standard worst-case latency objective.
What would settle it
A collection of monitoring instances in which policies obtained by solving the TWLO-MDP via reinforcement learning achieve worst-case weighted latency no lower than that of simple periodic or round-robin baselines.
Figures



read the original abstract
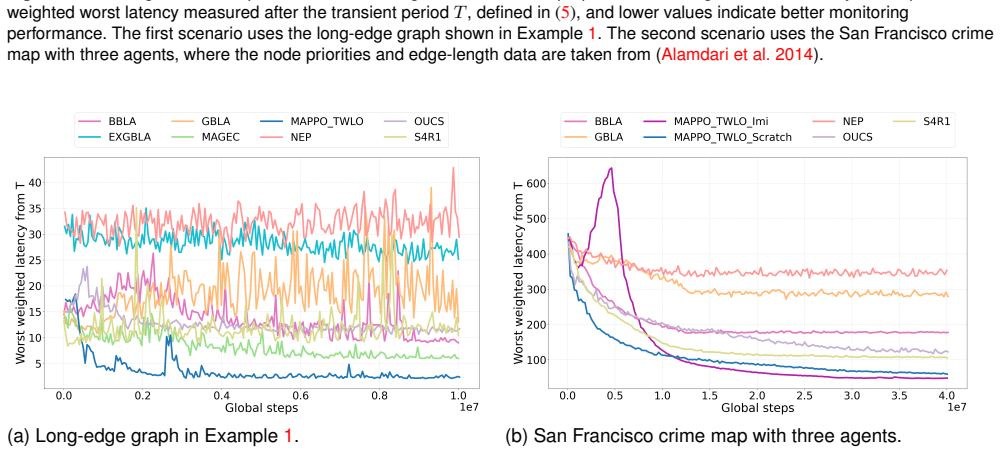
We study multi-robot persistent monitoring on weighted graphs, where node weights encode monitoring priorities and edge weights encode travel distances. The goal is to design joint robot trajectories that minimize the worst-case weighted latency across all nodes over an infinite time horizon. The widely adopted worst-case latency objective evaluates team performance over the entire time horizon and therefore may fail to distinguish strategies with poor transient behavior but strong asymptotic performance. To address this limitation, we propose a family of tail-performance objectives that generalize the standard objective and study the resulting functional optimization problems. We establish several key theoretical properties, including the existence of optimal strategies, relationships among the proposed objectives and their corresponding optimization problems, approximation by periodic solutions to arbitrary accuracy, and reductions to event-driven decision models with discretized waiting times. Building on these results, we construct an equivalent event-driven Markov decision process (MDP), called the Tail Worst-case Latency-Optimizing Markov Decision Process (TWLO-MDP), which reformulates the tail-performance objective as a standard average-reward criterion. We then develop reinforcement-learning-based solution methods for the TWLO-MDP and introduce the multi-robot monitoring benchmark (M2Bench), a unified platform that supports the evaluation and comparison of heuristic and learning-based monitoring algorithms. Experiments on synthetic and realistic monitoring scenarios show that our methods effectively reduce the worst-case weighted latency and outperform representative baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies multi-robot persistent monitoring on weighted graphs to minimize worst-case weighted latency over an infinite horizon. It introduces a family of tail-performance objectives that generalize the standard objective, establishes theoretical properties including existence of optimal strategies, relationships among objectives, periodic approximations to arbitrary accuracy, and reductions to an event-driven MDP (TWLO-MDP) reformulated as an average-reward criterion. RL-based solution methods are developed, the M2Bench benchmark is introduced, and experiments on synthetic and realistic scenarios claim that the methods reduce worst-case weighted latency and outperform baselines.
Significance. If the theoretical derivations hold and experiments are strengthened, the work could advance persistent monitoring by enabling objectives that explicitly address transient performance distinctions, with the TWLO-MDP reduction and RL methods providing a practical computational pathway and M2Bench offering a standardized evaluation platform for future comparisons in robotics.
major comments (2)
- [Abstract and Motivation] Abstract and Motivation: The central motivation states that standard worst-case latency 'may fail to distinguish strategies with poor transient behavior but strong asymptotic performance,' yet the experiments report only aggregate worst-case weighted latency reductions without time-resolved latency curves, transient-window metrics, or controlled comparisons (e.g., policies with matched long-run averages but differing early behavior). This leaves the practical advantage of the tail formulation unsubstantiated relative to the standard objective.
- [Theoretical Properties] Theoretical Properties and Reductions: The manuscript asserts existence of optimal strategies, periodic approximations to arbitrary accuracy, and the reduction to the TWLO-MDP, but provides no proof sketches, conditions, or error bounds for these claims, which are load-bearing for the validity of the MDP reformulation and subsequent RL methods.
minor comments (2)
- [Benchmark and Experiments] The description of M2Bench could specify the exact graph topologies, weight distributions, and number of runs for reproducibility.
- [Objectives] Notation for the family of tail-performance objectives should be introduced with explicit mathematical definitions before use in the MDP construction.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed report. We address each major comment below and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and Motivation] Abstract and Motivation: The central motivation states that standard worst-case latency 'may fail to distinguish strategies with poor transient behavior but strong asymptotic performance,' yet the experiments report only aggregate worst-case weighted latency reductions without time-resolved latency curves, transient-window metrics, or controlled comparisons (e.g., policies with matched long-run averages but differing early behavior). This leaves the practical advantage of the tail formulation unsubstantiated relative to the standard objective.
Authors: We agree that the current experimental evaluation reports primarily aggregate worst-case weighted latency values and does not include explicit time-resolved curves or controlled comparisons isolating transient differences. To substantiate the motivation for the tail-performance objectives, we will add new experimental results that include time-resolved latency plots, transient-window metrics, and direct comparisons of policies whose long-run averages are matched but whose early behavior differs. These additions will be placed in the experimental section and will use the same M2Bench scenarios. revision: yes
-
Referee: [Theoretical Properties] Theoretical Properties and Reductions: The manuscript asserts existence of optimal strategies, periodic approximations to arbitrary accuracy, and the reduction to the TWLO-MDP, but provides no proof sketches, conditions, or error bounds for these claims, which are load-bearing for the validity of the MDP reformulation and subsequent RL methods.
Authors: The existence of optimal strategies, relationships among the tail objectives, periodic approximations to arbitrary accuracy, and the reduction to the TWLO-MDP are formally stated and proved in the appendix. To improve readability and address the concern directly, we will insert concise proof sketches, the precise conditions under which the results hold, and the relevant error bounds for the periodic approximation into the main theoretical section. The appendix proofs themselves will remain unchanged. revision: yes
Circularity Check
No circularity: derivation derives TWLO-MDP equivalence from tail objectives without self-reference or fitted-input renaming.
full rationale
The paper's chain proceeds from the new tail-performance objectives (generalizing worst-case latency) to stated theoretical properties (existence, relationships, periodic approximation, event-driven reduction) and then to an explicit equivalence constructing the TWLO-MDP that recasts the objective as average-reward MDP. No equation or claim is shown to equal its own input by definition, no parameter is fitted on a subset and relabeled a prediction, and no load-bearing step rests on self-citation. The reformulation is derived rather than presupposed, and experiments supply independent empirical comparison. This is the normal self-contained case.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Existence of optimal strategies for the functional optimization problems on weighted graphs
- domain assumption Periodic solutions can approximate optimal strategies to arbitrary accuracy
invented entities (2)
-
Tail-performance objectives
no independent evidence
-
TWLO-MDP
no independent evidence
Reference graph
Works this paper leans on
-
[1]
PMLR, pp. 21937–21950. Machado A, Ramalho G, Zucker JD and Drogoul A (2003) Multi-agent patrolling: An empirical analysis of alternative architectures. In:Multi-Agent-Based Simulation II. Springer Berlin Heidelberg, pp. 155–170. Mallya D, Sinha A and Vachhani L (2022) Priority patrol with a single agent—bounds and approximations.IEEE Control Systems Lette...
-
[2]
Lemma 5.Characterization of semicontinuity via sequences (Aliprantis and Border 2006, Lemma 2.42)
for everyx∈X, the set{f(x) :f∈F} ⊂Yhas compact closure. Lemma 5.Characterization of semicontinuity via sequences (Aliprantis and Border 2006, Lemma 2.42). Letf:X→[−∞,∞]be a function on a topological spaceX. Thenfis upper semicontinuous if and only if for x0 ∈X,lim sup x→x0 f(x)≤f(x 0). Lemma 6.Closure of lower semicontinuous functions (Aliprantis and Bord...
work page 2006
-
[3]
In this case, we have d|G|(πr(t′), v)>0for allr∈ Randt ′ ∈[0, t]
The nodevhas not been visited by any robot within[0, t], i.e.,h π(v, t) = 0. In this case, we have d|G|(πr(t′), v)>0for allr∈ Randt ′ ∈[0, t]. Since eachπ r(·)is continuous and the interval[0, t]is compact, by the extreme value theorem, we can find δ= min t′∈[0,t],r∈R d|G|(πr(t′), v)>0.(13) Prepared usingsagej.cls Wang et al.: Multi-robot Persistent Monit...
-
[4]
In this case, the nodevwill not be visited after hπ(v, t)
The nodevis visited during[0, t), i.e.h π(v, t)∈ [0, t). In this case, the nodevwill not be visited after hπ(v, t). So for any0< ε≤t−h π(v, t), we know that for allr∈ Rand for allt ′ ∈[h π(v, t) +ε, t], d|G|(πr(t′), v)>0. Similar to case1), we can find aδ ε = mint′∈[hπ(v,t)+ε,t],r∈R d|G|(πr(t′), v)> 0and anNsuch that whenn≥N, supt′∈[hπ(v,t)+ε,t] maxr∈R d|...
-
[5]
The nodevis visited exactly att. Then we have hπn(v, t)≤t=h π(v, t)and the following equation must hold: lim sup πn→π hπn(v, t)≤h π(v, t). In conclusion, for every sequenceπ n →π, we have lim supπn→π hπn(v, t)≤h π(v, t)and according to Lemma 5, with the compact-open topology, hπ(v, t)is upper semicontinuous with respect to π. SinceL π v (t) =t−h π(v, t), ...
-
[6]
=J ∗ ∞. Proof of Theorem 1 withT=∞.By definition, for any feasible strategyπ∈Π, we know thatJ ∞(π) = limT0→∞ supt≥T0 Lπ(t)≤sup t≥0 Lπ(t) =J 0(π). Thus, we haveJ ∗ ∞ ≤J ∗ 0 . On the other hand, we prove thatJ ∗ ∞ ≥J ∗ 0 by contradiction. Suppose there existsπ ∞ ∈Πsuch that J∞(π∞)< J ∗ 0 , then letδ=J ∗ 0 −J ∞(π∞)>0. By the property of the limit superior (R...
work page 1976
-
[7]
Thus,π ∗ 0 is also an optimal strategy toJ ∞(·)
= lim T0→∞ sup t≥T0 Lπ∗ 0(t)≤sup t≥0 Lπ∗ 0(t) =J ∗ 0 =J ∗ ∞. Thus,π ∗ 0 is also an optimal strategy toJ ∞(·). Since we have proved the existence ofπ ∗ 0 in Appendix B2, it is concluded that there exists at least one optimal strategy forT=∞. Combining the proofs presented in Appendix B2 and Appendix B3, we have proved Theorem 1. Prepared usingsagej.cls 22 ...
-
[8]
Construct a new strategy ˜πthat first follows the canonical motion defined in Appendix A fromp 0 to the initial configuration ofπ ∗ 0(0)at full speed and then executes π∗
-
[9]
By the definition of canonical motion, this steering takes no longer than the graph diameterD G. According to Lemma 3, within a time interval of lengthτ cov(J ∗), every node must be visited at least once underπ ∗ 0, and by Lemma 4, latency thereafter evolves identically to that underπ ∗
-
[10]
Hence, for allT > D G +J ∗/ϕmin, truncating the transient state does not change the tail objective, i.e., JT (˜π) =J 0(π∗
-
[11]
=J ∗. Therefore, ˜πis an optimal strategy starting fromp 0, which proves that for allT > D G + J ∗ ϕmin , Π∗ T ∩Π p0 ̸=∅. C Proof of Theorem 3 We will first prove that Theorem 3 holds forJ∞(π), and then extend the argument to the case of finiteT <∞. ForJ ∞(π), the proof proceeds by showing that along any feasible trajectory we can always find a finite seg...
work page 1976
-
[12]
+ 2ϕmax∆ =J ∗ + 2ϕmax∆. E Proof of Section 4 E1 Proof of Theorem 5 Proof of Theorem 5.We first show that, for any feasible stationary policyµto the constructed MDPM, its average objective value satisfies thatJ ave s0 (µ)≥J ∗, where J ∗ is the optimal value of Problem 1. Moreover, we construct a monitoring strategyπ µ ∈ ¯Πp0 according toµ whose performance...
work page 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.