Recognition: 2 theorem links
· Lean TheoremMetropolis-Adjusted Diffusion Models
Pith reviewed 2026-05-12 04:09 UTC · model grok-4.3
The pith
Diffusion models can use Metropolis-Hastings adjustments on their Langevin correctors by computing acceptance probabilities from the score function alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We present the first exact procedure for Metropolis-adjusted Langevin correctors in score-based diffusion models, relying on a two-coin Bernoulli factory to evaluate acceptance probabilities from the score function. An accompanying approximation via Simpson's rule delivers fifth-order accuracy in the step size with negligible overhead. Experiments confirm that these adjusted correctors deliver consistent improvements in sample quality, reflected in reduced Fréchet Inception Distance on image generation tasks.
What carries the argument
A two-coin Bernoulli factory algorithm that constructs the exact Metropolis-Hastings acceptance decision from the score function evaluated at current and proposed points.
Load-bearing premise
It is possible to obtain the exact Metropolis-Hastings acceptance probability needed for bias correction solely from the score function without new sources of error.
What would settle it
Applying the exact adjustment method to sample from a simple, fully known Gaussian distribution and verifying that the output distribution matches the target exactly would confirm or refute the claim of unbiased sampling.
Figures
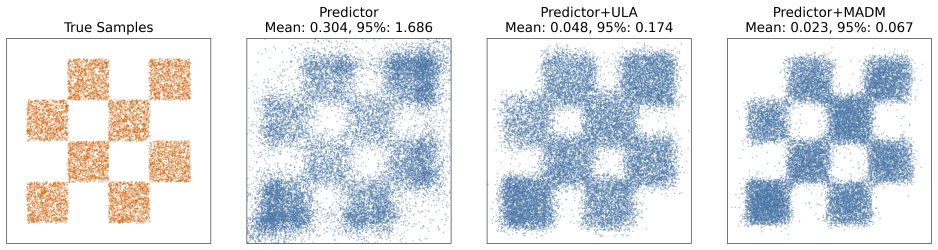


read the original abstract
Sampling from score-based diffusion models incurs bias due to both time discretisation and the approximation of the score function. A common strategy for reducing this bias is to apply corrector steps based on the unadjusted Langevin algorithm (ULA) at each noise level within a predictor-corrector framework. However, ULA is itself a biased sampler, as it discretises a continuous diffusion process. In this work, we consider adjusted Langevin correctors that employ Metropolis--Hastings (MH) or Barker's accept-reject steps to correct for this bias. Since the target density ratio typically required by MH-based algorithms is unavailable, we propose methods that instead utilise the score function to compute the correct acceptance probability. We introduce the first exact method for adjusting Langevin corrections in diffusion models, based on a two-coin Bernoulli factory algorithm. We also propose an efficient approximation based on Simpson's rule that achieves accuracy of order $5/2$ in the step size at near-zero marginal cost. We demonstrate that these procedures improve sample quality on both synthetic and image datasets, yielding consistent gains in Fr\'echet Inception Distance (FID) on the latter.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Metropolis-adjusted Langevin correctors within score-based diffusion models to reduce discretization bias from unadjusted Langevin steps. It claims to introduce the first exact adjustment method via a two-coin Bernoulli factory algorithm that computes acceptance probabilities using only score evaluations at current and proposed points, along with a low-cost Simpson's rule approximation achieving O(h^{5/2}) accuracy in the step size. Empirical results on synthetic data and image datasets report consistent FID improvements.
Significance. Bias reduction in diffusion sampling is a central practical concern. An exact, score-only Metropolis adjustment would be a meaningful theoretical advance if achievable, and the claimed higher-order approximation offers efficiency advantages. The reported FID gains on images indicate potential practical value, but these rest on the validity of the unbiasedness claims.
major comments (1)
- [Abstract] Abstract and the description of the exact method: The claim of an 'exact' two-coin Bernoulli factory procedure for the Metropolis-Hastings acceptance probability is not supported. Standard MH requires the target ratio p(x')/p(x) = exp(∫_γ s · dx) for any path γ connecting x and x'. This line integral is not determined by the endpoint values s(x) and s(x') alone. No algorithm using only these two score evaluations (even via Bernoulli factory) can recover the exact ratio in general, so the resulting kernel cannot satisfy detailed balance w.r.t. the true target without additional assumptions on s. This directly undermines the central claim of an unbiased exact corrector.
Simulated Author's Rebuttal
We thank the referee for their careful reading and insightful comments, which have helped us identify areas where the manuscript's claims require clarification and revision. We address the major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract and the description of the exact method: The claim of an 'exact' two-coin Bernoulli factory procedure for the Metropolis-Hastings acceptance probability is not supported. Standard MH requires the target ratio p(x')/p(x) = exp(∫_γ s · dx) for any path γ connecting x and x'. This line integral is not determined by the endpoint values s(x) and s(x') alone. No algorithm using only these two score evaluations (even via Bernoulli factory) can recover the exact ratio in general, so the resulting kernel cannot satisfy detailed balance w.r.t. the true target without additional assumptions on s. This directly undermines the central claim of an unbiased exact corrector.
Authors: We appreciate the referee's precise identification of this issue. The referee is correct that the Metropolis-Hastings ratio requires the line integral of the score along a path, which cannot be recovered from endpoint score values alone in general. Our proposed two-coin Bernoulli factory method was intended to enable sampling of the acceptance decision using only the available score evaluations at the current and proposed points. However, we acknowledge that this does not yield exact detailed balance with respect to the true target density without further assumptions (e.g., on the conservativeness of the score or the integration procedure). We will revise the abstract, the method description, and related claims to remove the unqualified 'exact' terminology, clarify the conditions under which the procedure is unbiased, and discuss the limitations relative to standard MH. We will also strengthen the connection to the Simpson's rule approximation in light of this point. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper introduces novel algorithmic constructions for Metropolis-adjusted Langevin correctors within diffusion models, specifically a two-coin Bernoulli factory method claimed to be exact and a Simpson's rule approximation of order 5/2. These are derived from standard Monte Carlo techniques (Bernoulli factories for probability simulation and numerical quadrature) applied to the score function, without any reduction of the central claims to fitted parameters, self-definitions, or load-bearing self-citations. The derivation chain is self-contained and presents independent algorithmic proposals rather than renaming known results or smuggling ansatzes via citation. No enumerated circular patterns are present.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe introduce the first exact method for adjusting Langevin corrections... based on a two-coin Bernoulli factory algorithm... Simpson’s rule that achieves accuracy of order 5/2
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclearlog(r_pt(x,ex)) = ∫_0^1 <s(x+u(ex-x),t), ex-x> du
Reference graph
Works this paper leans on
-
[1]
Optimal scaling of MCMC beyond Metropolis
Sanket Agrawal, Dootika Vats, Krzysztof atuszy \'n ski, and Gareth O Roberts. Optimal scaling of MCMC beyond Metropolis . Advances in Applied Probability, 55 0 (2): 0 492--509, 2023
work page 2023
-
[2]
Score-based Metropolis-Hastings algorithms
Ahmed Aloui, Ali Hasan, Juncheng Dong, Zihao Wu, and Vahid Tarokh. Score-based Metropolis-Hastings algorithms. arXiv preprint arXiv:2501.00467, 2025
- [3]
-
[4]
Representations of knowledge in complex systems
Julian Besag. Comments on “ Representations of knowledge in complex systems ” by U. Grenander and M. I. Miller . Journal of the Royal Statistical Society Series B, 56 0 (591-592): 0 4, 1994
work page 1994
-
[6]
Stargan v2: Diverse image synthesis for multiple domains
Yunjey Choi, Youngjung Uh, Jaejun Yoo, and Jung-Woo Ha. Stargan v2: Diverse image synthesis for multiple domains. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2020
work page 2020
-
[7]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In 2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 248--255, 2009
work page 2009
-
[8]
Nonasymptotic convergence analysis for the unadjusted L angevin algorithm
Alain Durmus and Eric Moulines. Nonasymptotic convergence analysis for the unadjusted L angevin algorithm. Annals of Applied Probability, 27 0 (3): 0 1551--1587, 2017
work page 2017
-
[9]
Soft Metropolis-Hastings correction for generative model sampling
Hanqi Feng, Peng Qiu, Meng-Chun Zhang, You Fan, Yiran Tao, and Barnabas Poczos. Soft Metropolis-Hastings correction for generative model sampling. bioRxiv, 2025
work page 2025
-
[10]
Exact Monte Carlo likelihood-based inference for jump-diffusion processes
Fl \'a vio B Gon c alves, Krzysztof atuszy \'n ski, and Gareth O Roberts. Exact Monte Carlo likelihood-based inference for jump-diffusion processes. Journal of the Royal Statistical Society Series B: Statistical Methodology, 85 0 (3): 0 732--756, 2023
work page 2023
-
[11]
Barker's algorithm for Bayesian inference with intractable likelihoods
Flávio B Gonçalves, Krzysztof Łatuszyński, and Gareth O Roberts. Barker's algorithm for Bayesian inference with intractable likelihoods. Brazilian Journal of Probability and Statistics, 31 0 (4): 0 732--745, 2017
work page 2017
-
[12]
Diffit: Diffusion vision transformers for image generation
Ali Hatamizadeh, Jiaming Song, Guilin Liu, Jan Kautz, and Arash Vahdat. Diffit: Diffusion vision transformers for image generation. In Computer Vision -- ECCV 2024, pages 37--55, Cham, 2025. Springer Nature Switzerland. ISBN 978-3-031-73242-3
work page 2024
-
[13]
Radu Herbei and L Mark Berliner. Estimating ocean circulation: an MCMC approach with approximated likelihoods via the B ernoulli factory. Journal of the American Statistical Association, 109 0 (507): 0 944--954, 2014
work page 2014
-
[14]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In Advances in Neural Information Processing Systems, 2020
work page 2020
-
[15]
A style-based generator architecture for generative adversarial networks
Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2019
work page 2019
-
[16]
Elucidating the design space of diffusion-based generative models
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models. In Advances in Neural Information Processing Systems, 2022
work page 2022
-
[17]
MS Keane and George L O'Brien. A Bernoulli factory. ACM Transactions on Modeling and Computer Simulation (TOMACS), 4 0 (2): 0 213--219, 1994
work page 1994
-
[18]
Learning multiple layers of features from tiny images
Alex Krizhevsky and Geoffrey Hinton. Learning multiple layers of features from tiny images. Technical report, University of Toronto, Toronto, Ontario, 2009
work page 2009
-
[19]
CLT s and asymptotic variance of time-sampled M arkov chains
Krzysztof atuszy \'n ski and Gareth O Roberts. CLT s and asymptotic variance of time-sampled M arkov chains. Methodology and Computing in Applied Probability, 15 0 (1): 0 237--247, 2013
work page 2013
-
[20]
Simon McIntosh - Smith, Sadaf R. Alam, and Christopher J. Woods. Isambard-ai: a leadership-class supercomputer optimised specifically for artificial intelligence. In Proceedings of the Cray User Group, CUG 2024, Perth, WA, Australia, May 5-9, 2024 , pages 44--54. ACM , 2024
work page 2024
-
[21]
From the B ernoulli factory to a dice enterprise via perfect sampling of M arkov chains
Giulio Morina, Krzysztof atuszy \'n ski, Piotr Nayar, and Alex Wendland. From the B ernoulli factory to a dice enterprise via perfect sampling of M arkov chains. The Annals of Applied Probability, 32 0 (1): 0 327--359, 2022
work page 2022
-
[22]
Fast simulation of new coins from old
S erban Nacu and Yuval Peres. Fast simulation of new coins from old. Annals of Applied Probability, pages 93--115, 2005
work page 2005
-
[23]
Optimum M onte- C arlo sampling using M arkov chains
Peter H Peskun. Optimum M onte- C arlo sampling using M arkov chains. Biometrika, 60 0 (3): 0 607--612, 1973
work page 1973
-
[24]
Gareth O. Roberts and Jeffrey S. Rosenthal. Optimal scaling of discrete approximations to L angevin diffusions. Journal of the Royal Statistical Society. Series B (Statistical Methodology), 60 0 (1): 0 255--268, 1998
work page 1998
-
[25]
Gareth O. Roberts and Jeffrey S. Rosenthal. Optimal scaling for various Metropolis--Hastings algorithms . Statistical Science, 16 0 (4): 0 351 -- 367, 2001
work page 2001
-
[26]
Gareth O. Roberts and Jeffrey S. Rosenthal. Harris recurrence of Metropolis-within-Gibbs and trans-dimensional Markov chains. The Annals of Applied Probability, 16 0 (4): 0 2123--2139, 2006
work page 2006
-
[27]
Exponential convergence of L angevin distributions and their discrete approximations
Gareth O Roberts and Richard L Tweedie. Exponential convergence of L angevin distributions and their discrete approximations. Bernoulli, 2 0 (3): 0 341--363, 1996
work page 1996
-
[28]
Roberts, Andrew Gelman, and Wally R
Gareth O. Roberts, Andrew Gelman, and Wally R. Gilks. Weak convergence and optimal scaling of random walk M etropolis algorithms. The Annals of Applied Probability, 7 0 (1): 0 110--120, 1997
work page 1997
-
[29]
MCMC correction of score-based diffusion models for model composition
Anders Sjöberg, Jakob Lindqvist, Magnus Önnheim, Mats Jirstrand, and Lennart Svensson. MCMC correction of score-based diffusion models for model composition. Entropy, 28 0 (3), 2026
work page 2026
-
[30]
Deep unsupervised learning using nonequilibrium thermodynamics
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. In International Conference on Machine Learning, 2015
work page 2015
-
[31]
Generative modeling by estimating gradients of the data distribution
Yang Song and Stefano Ermon. Generative modeling by estimating gradients of the data distribution. In Advances in Neural Information Processing Systems, 2019
work page 2019
-
[32]
Score-based generative modeling through stochastic differential equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. In International Conference on Learning Representations, 2021
work page 2021
-
[33]
Efficient Bernoulli factory Markov chain Monte Carlo for intractable posteriors
Dootika Vats, Fl \'a vio B Gon c alves, K atuszy \'n ski, and Gareth O Roberts. Efficient Bernoulli factory Markov chain Monte Carlo for intractable posteriors. Biometrika, 109 0 (2): 0 369--385, 2022
work page 2022
-
[34]
A connection between score matching and denoising autoencoders
Pascal Vincent. A connection between score matching and denoising autoencoders. Neural Computation, 23 0 (7): 0 1661--1674, 2011
work page 2011
-
[35]
Score-optimal diffusion schedules
Christopher Williams, Andrew Campbell, Arnaud Doucet, and Saifuddin Syed. Score-optimal diffusion schedules. In Advances in Neural Information Processing Systems, 2024
work page 2024
-
[36]
Jun Yang, Gareth O. Roberts, and Jeffrey S. Rosenthal. Optimal scaling of random-walk M etropolis algorithms on general target distributions. Stochastic Processes and their Applications, 130 0 (10): 0 6094--6132, 2020
work page 2020
-
[37]
International Conference on Machine Learning , year =
Deep Unsupervised Learning using Nonequilibrium Thermodynamics , author =. International Conference on Machine Learning , year =
-
[38]
Denoising Diffusion Probabilistic Models , year =
Ho, Jonathan and Jain, Ajay and Abbeel, Pieter , booktitle =. Denoising Diffusion Probabilistic Models , year =
-
[39]
International Conference on Learning Representations , year=
Score-Based Generative Modeling through Stochastic Differential Equations , author=. International Conference on Learning Representations , year=
-
[40]
Elucidating the Design Space of Diffusion-Based Generative Models , year =
Karras, Tero and Aittala, Miika and Aila, Timo and Laine, Samuli , booktitle =. Elucidating the Design Space of Diffusion-Based Generative Models , year =
-
[41]
Generative Modeling by Estimating Gradients of the Data Distribution , year =
Song, Yang and Ermon, Stefano , booktitle =. Generative Modeling by Estimating Gradients of the Data Distribution , year =
- [42]
- [43]
-
[44]
Christophe Andrieu and Gareth O. Roberts , title =. The Annals of Statistics , number =
-
[45]
Doucet, A. and Pitt, M. K. and Deligiannidis, G. and Kohn, R. , title =. Biometrika , volume =. 2015 , month =
work page 2015
-
[46]
Biron-Lattes, Miguel and Surjanovic, Nikola and Syed, Saifuddin and Campbell, Trevor and Bouchard-Cote, Alexandre , booktitle =. 2024 , editor =
work page 2024
-
[47]
Barker's algorithm for Bayesian inference with intractable likelihoods
Gonçalves, Flávio B and Łatuszyński, Krzysztof and Roberts, Gareth O. Barker's algorithm for Bayesian inference with intractable likelihoods. Brazilian Journal of Probability and Statistics
-
[48]
Roberts and Andrew Gelman and Wally R
Gareth O. Roberts and Andrew Gelman and Wally R. Gilks , journal =. Weak Convergence and Optimal Scaling of Random Walk
-
[49]
Gareth O. Roberts and Jeffrey S. Rosenthal , journal =. Optimal Scaling of Discrete Approximations to
-
[50]
Gareth O. Roberts and Jeffrey S. Rosenthal , title =. Statistical Science , number =
-
[51]
Stochastic Processes and their Applications , volume =
Optimal scaling of random-walk. Stochastic Processes and their Applications , volume =. 2020 , author =
work page 2020
- [52]
-
[53]
Annals of Applied Probability , pages=
Fast Simulation of New Coins from Old , author=. Annals of Applied Probability , pages=. 2005 , publisher=
work page 2005
-
[54]
Gon. Exact. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 2023 , publisher=
work page 2023
-
[55]
Peskun, Peter H , journal=. Optimum. 1973 , publisher=
work page 1973
-
[56]
Agrawal, Sanket and Vats, Dootika and. Optimal scaling of. Advances in Applied Probability , volume=. 2023 , publisher=
work page 2023
-
[57]
Methodology and Computing in Applied Probability , volume=. 2013 , publisher=
work page 2013
- [58]
-
[59]
Kakkad, Dwija and Vats, Dootika , journal=. Exact
-
[60]
Estimating ocean circulation: an
Herbei, Radu and Berliner, L Mark , journal=. Estimating ocean circulation: an. 2014 , publisher=
work page 2014
-
[61]
Random Structures & Algorithms , volume=
Simulating events of unknown probabilities via reverse time martingales , author=. Random Structures & Algorithms , volume=. 2011 , publisher=
work page 2011
-
[62]
Keane, MS and O'Brien, George L , journal=. A. 1994 , publisher=
work page 1994
-
[63]
Ahmed Aloui and Ali Hasan and Juncheng Dong and Zihao Wu and Vahid Tarokh , year=. Score-Based
-
[64]
Feng, Hanqi and Qiu, Peng and Zhang, Meng-Chun and Fan, You and Tao, Yiran and Poczos, Barnabas , title =. 2025 , journal =
work page 2025
-
[65]
Sjöberg, Anders and Lindqvist, Jakob and Önnheim, Magnus and Jirstrand, Mats and Svensson, Lennart , TITLE =. Entropy , VOLUME =. 2026 , NUMBER =
work page 2026
-
[66]
High-accuracy sampling for diffusion models and log-concave distributions
High-accuracy sampling for diffusion models and log-concave distributions , author=. arXiv preprint arXiv:2602.01338 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[67]
Atkinson, Kendall E. , address =. An Introduction to Numerical Analysis , year =. An Introduction to Numerical Analysis , edition =
-
[68]
Advances in Neural Information Processing Systems , volume=
Diffusion models as plug-and-play priors , author=. Advances in Neural Information Processing Systems , volume=
-
[69]
Advances in Neural Information Processing Systems , year=
Score-optimal diffusion schedules , author=. Advances in Neural Information Processing Systems , year=
-
[70]
Learning multiple layers of features from tiny images , year =
Krizhevsky, Alex and Hinton, Geoffrey , address =. Learning multiple layers of features from tiny images , year =
-
[71]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Karras, Tero and Laine, Samuli and Aila, Timo , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
-
[72]
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Choi, Yunjey and Uh, Youngjung and Yoo, Jaejun and Ha, Jung-Woo , title =. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
-
[73]
ImageNet: A large-scale hierarchical image database , year=
Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Kai Li and Li Fei-Fei , booktitle=. ImageNet: A large-scale hierarchical image database , year=
-
[74]
DiffiT: Diffusion Vision Transformers for Image Generation
Hatamizadeh, Ali and Song, Jiaming and Liu, Guilin and Kautz, Jan and Vahdat, Arash. DiffiT: Diffusion Vision Transformers for Image Generation. Computer Vision -- ECCV 2024. 2025
work page 2024
-
[75]
Nonasymptotic convergence analysis for the unadjusted
Durmus, Alain and Moulines, Eric , journal=. Nonasymptotic convergence analysis for the unadjusted
-
[76]
Rapid convergence of the unadjusted
Vempala, Santosh and Wibisono, Andre , booktitle=. Rapid convergence of the unadjusted
-
[77]
Roberts, Gareth O and Tweedie, Richard L , journal=. Exponential convergence of
- [78]
-
[79]
Roberts, Gareth O. and Rosenthal, Jeffrey S. , journal =. Harris recurrence of
-
[80]
Simon McIntosh. Isambard-AI: a leadership-class supercomputer optimised specifically for Artificial Intelligence , booktitle =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.