Recognition: 2 theorem links
· Lean TheoremTowards Generative Predictive Display for Vision-Based Teleoperation: A Zero-Shot Benchmark of Off-the-Shelf Video Models
Pith reviewed 2026-05-12 03:31 UTC · model grok-4.3
The pith
Current generative video models fall short of the accuracy, stability, and speed needed for predictive displays that could eliminate latency in teleoperation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
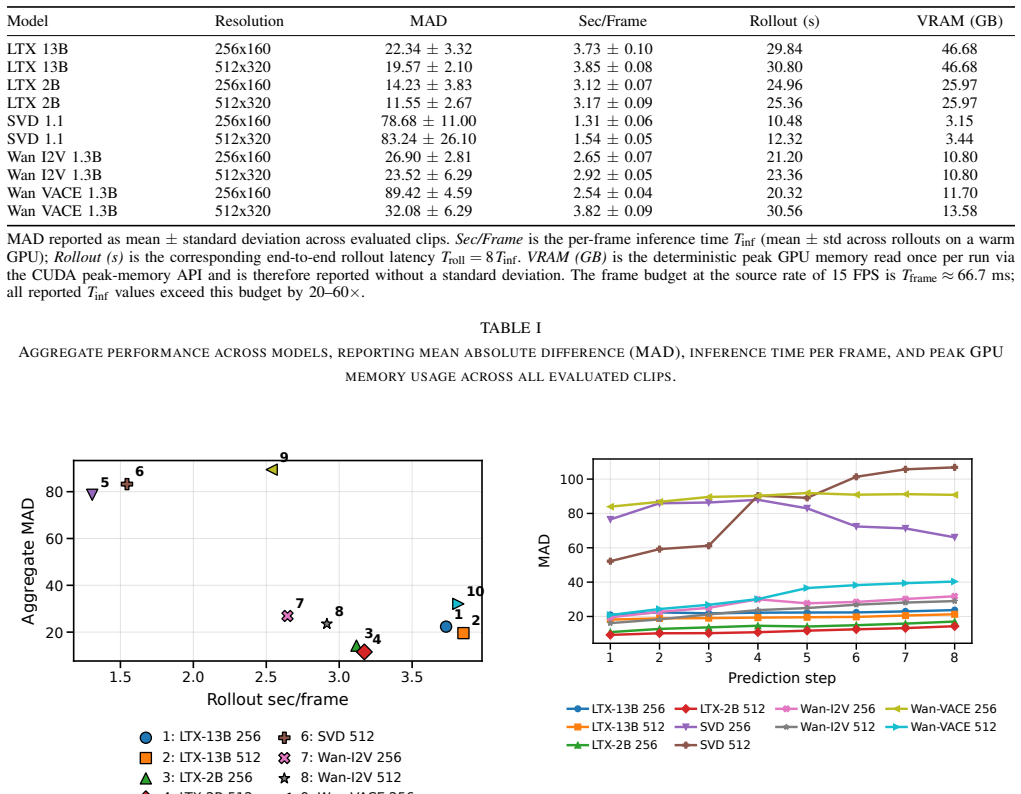
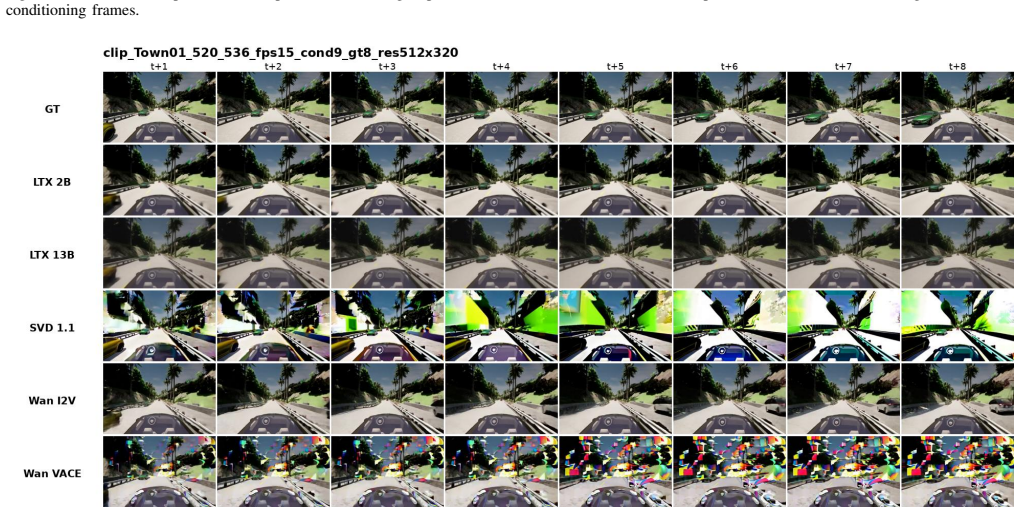
The paper establishes through direct testing that transformer-based and diffusion-based video models, applied without any task-specific training to future-frame prediction on CARLA driving sequences, produce rollouts whose average per-pixel difference from ground truth either starts high or grows over the horizon, while also exceeding real-time latency thresholds at the source rate.
What carries the argument
A unified pipeline that generates multi-step video rollouts from single or multi-frame inputs and tracks error growth, latency, and memory across two resolutions and conditioning setups.
If this is right
- Practical predictive display systems will require either fine-tuning on driving data or new model designs optimized for short horizons.
- Simply using larger models or higher resolution inputs does not overcome the observed performance limits.
- Real-time inference at camera frame rates remains incompatible with the accuracy demands of teleoperation on the tested architectures.
Where Pith is reading between the lines
- Similar limitations likely apply to other domains where generative models are considered for low-latency forecasting, such as robotic manipulation.
- Testing the same models on real camera feeds from physical vehicles could reveal whether simulator artifacts hide or exaggerate the issues.
- Combining these models with lightweight correction networks trained only on error patterns might offer a path to usable systems without full retraining.
Load-bearing premise
That performance gaps observed on simulator sequences with the five chosen models accurately reflect what would be seen in actual teleoperation hardware and with the full range of available video generation techniques.
What would settle it
A new or existing generative video model that, when run zero-shot on the CARLA test sequences, keeps mean absolute pixel differences below a low threshold across an entire rollout, shows non-increasing per-step errors, and completes each prediction in less time than the interval between source frames.
Figures

read the original abstract
Teleoperation systems are fundamentally limited by communication latency, which degrades situational awareness and control performance. Predictive display aims to mitigate this limitation by presenting an estimate of the current visual state rather than delayed observations. While recent advances in generative video models enable high-quality video synthesis, their suitability for latency-sensitive predictive display remains unclear. This paper presents a zero-shot benchmark of off-the-shelf generative video models for short-horizon predictive display, without task-specific fine-tuning. We formulate the problem as rollout-based future frame prediction and develop a unified benchmarking pipeline using simulated driving data from the CARLA simulator. Five publicly released video models spanning transformer-based and diffusion-based families are evaluated across two resolutions and two conditioning regimes (multi-frame and single-frame). Performance is assessed using prediction accuracy (mean absolute difference), per-rollout latency, peak GPU memory usage, and temporal error evolution across the prediction horizon. On this zero-shot benchmark, no tested model simultaneously achieves low rollout error, non-divergent per-step error behavior, and real-time inference at the source frame rate. Increasing model scale or resolution yields limited and, in some cases, inverted improvements. These findings highlight a gap between general-purpose generative video synthesis and the requirements of predictive display in teleoperation, suggesting that practical deployment will require either explicit short-horizon temporal supervision, in-domain adaptation, or aggressive inference optimization rather than direct application of off-the-shelf models. Code, configurations, and qualitative results are released on the project page: https://bimilab.github.io/paper-GenPD
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a zero-shot benchmark of five off-the-shelf generative video models (spanning transformer- and diffusion-based families) for short-horizon predictive display in vision-based teleoperation. Using CARLA simulator data, it formulates the task as rollout-based future-frame prediction under single-frame and multi-frame visual conditioning at two resolutions. Performance is measured via mean absolute difference (prediction accuracy), per-rollout latency, peak GPU memory, and temporal error evolution. The central empirical claim is that no evaluated model simultaneously achieves low rollout error, non-divergent per-step error behavior, and real-time inference at the source frame rate; increasing scale or resolution yields limited or inverted gains. The authors release code, configurations, and qualitative results, concluding that practical use will require explicit short-horizon supervision, in-domain adaptation, or inference optimization.
Significance. If the empirical results hold under the described setup, the work usefully documents concrete limitations of current general-purpose generative video models for latency-sensitive applications. The public release of code, configurations, and results is a clear strength that supports reproducibility and follow-on research. The benchmark provides actionable evidence that off-the-shelf models fall short on temporal consistency and efficiency in simulated driving rollouts, motivating targeted adaptations rather than direct deployment.
major comments (2)
- [Abstract and §3] Abstract and §3 (Problem Formulation): The benchmark conditions future-frame prediction exclusively on visual observations (single- or multi-frame past frames) and does not incorporate action signals (steering, throttle, brake) that are present in the CARLA dataset and required for closed-loop prediction in teleoperation. This evaluates open-loop video extrapolation rather than the action-conditioned forecasting needed for predictive display, so the negative result (no model meets all three criteria) does not directly establish unsuitability of generative models for the stated application.
- [§4 and Table 2] §4 (Experimental Setup) and Table 2: The claim that 'no tested model simultaneously achieves low rollout error, non-divergent per-step error behavior, and real-time inference' is load-bearing, yet the manuscript provides no explicit numerical thresholds for 'low' error or 'non-divergent' behavior, nor per-model ablation of error growth versus horizon. Without these, it is unclear whether divergence stems from the visual-only conditioning or from model-intrinsic issues, weakening the cross-model comparison.
minor comments (2)
- Figure captions and axis labels in the error-evolution plots could more explicitly indicate the prediction horizon in frames and the source frame rate used for the real-time criterion.
- [§4] The manuscript should clarify the exact source frame rate of the CARLA recordings and how 'real-time at the source frame rate' is operationalized for each model.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the scope and presentation of our benchmark. We address each major comment below and outline the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Problem Formulation): The benchmark conditions future-frame prediction exclusively on visual observations (single- or multi-frame past frames) and does not incorporate action signals (steering, throttle, brake) that are present in the CARLA dataset and required for closed-loop prediction in teleoperation. This evaluates open-loop video extrapolation rather than the action-conditioned forecasting needed for predictive display, so the negative result (no model meets all three criteria) does not directly establish unsuitability of generative models for the stated application.
Authors: We agree that action conditioning is necessary for closed-loop predictive display in teleoperation. Our benchmark deliberately evaluates zero-shot performance of off-the-shelf generative video models, which are designed for visual conditioning and do not natively support action inputs without fine-tuning. This setup isolates the visual prediction capability that is a prerequisite for any action-augmented system. We will revise §3 to explicitly label the task as open-loop visual extrapolation and add a limitations paragraph discussing the gap to action-conditioned forecasting. The core empirical finding—that current models fail to maintain temporal consistency even under visual-only conditioning—remains valid as a baseline result. revision: partial
-
Referee: [§4 and Table 2] §4 (Experimental Setup) and Table 2: The claim that 'no tested model simultaneously achieves low rollout error, non-divergent per-step error behavior, and real-time inference' is load-bearing, yet the manuscript provides no explicit numerical thresholds for 'low' error or 'non-divergent' behavior, nor per-model ablation of error growth versus horizon. Without these, it is unclear whether divergence stems from the visual-only conditioning or from model-intrinsic issues, weakening the cross-model comparison.
Authors: We accept that explicit thresholds and horizon-wise ablations would improve interpretability. In the revised manuscript we will (i) define quantitative thresholds for 'low' rollout error (MAD < 0.05 normalized) and 'non-divergent' behavior (error slope < 0.01 per frame over the horizon) based on teleoperation control requirements, and (ii) add per-model error-vs-horizon plots (extending the existing temporal error evolution analysis) to Table 2 and §4. These additions will allow readers to distinguish conditioning effects from model-intrinsic drift. revision: yes
Circularity Check
Pure empirical benchmark with direct measurements; no derivations or self-referential reductions
full rationale
The paper conducts a zero-shot empirical evaluation of off-the-shelf video models on CARLA simulator data. It defines a rollout-based prediction task, implements a unified pipeline, and reports direct metrics (mean absolute difference, latency, memory, error evolution) without any fitted parameters, self-citations as load-bearing premises, or equations that reduce predictions to inputs by construction. The central negative result follows immediately from the measured values across the tested models and regimes. No load-bearing step collapses to a tautology or prior self-reference.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Off-the-shelf generative video models can be evaluated zero-shot for short-horizon frame prediction using standard image-difference metrics
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe formulate the problem as rollout-based future frame prediction... evaluate... Mean Absolute Difference (MAD)... per-rollout latency... temporal error evolution
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearno tested model simultaneously achieves low rollout error, non-divergent per-step error behavior, and real-time inference
Reference graph
Works this paper leans on
-
[1]
Yingshi Zheng, Mark J Brudnak, Paramsothy Jayakumar, Jeffrey L Stein, and Tulga Ersal. An experimental evaluation of a model-free predictor framework in teleoperated vehicles.IF AC-PapersOnLine, 49(10):157–164, 2016
work page 2016
-
[2]
Improving the prediction accuracy of predictive displays for teleoperated autonomous vehicles
Gaetano Graf, Hao Xu, Dmitrij Schitz, and Xiao Xu. Improving the prediction accuracy of predictive displays for teleoperated autonomous vehicles. In2020 6th International Conference on Control, Automation and Robotics (ICCAR), pages 440–445. IEEE, 2020
work page 2020
-
[3]
Yingshi Zheng, Mark J Brudnak, Paramsothy Jayakumar, Jeffrey L Stein, and Tulga Ersal. Evaluation of a predictor-based framework in high-speed teleoperated military ugvs.IEEE Transactions on Human- Machine Systems, 50(6):561–572, 2020
work page 2020
-
[4]
Hossein Mirinejad, Paramsothy Jayakumar, and Tulga Ersal. Modeling human steering behavior during path following in teleoperation of unmanned ground vehicles.Human factors, 60(5):669–684, 2018
work page 2018
-
[5]
Motion prediction for teleoperating autonomous vehicles using a pid control model
Maximilian Prexl, Nicolas Zunhammer, and Ulrich Walter. Motion prediction for teleoperating autonomous vehicles using a pid control model. In2019 Australian & New Zealand Control Conference (ANZCC), pages 133–138. IEEE, 2019
work page 2019
-
[6]
Teleoperation with variable and large time delay based on mpc and model error com- pensator
Yuhei Hatori, Hiroki Nagakura, and Yutaka Uchimura. Teleoperation with variable and large time delay based on mpc and model error com- pensator. In2021 IEEE 30th International Symposium on Industrial Electronics (ISIE), pages 1–6. IEEE, 2021
work page 2021
-
[7]
Implemen- tation and evaluation of latency visualization method for teleoperated vehicle
Yudai Sato, Shuntaro Kashihara, and Tomohiko Ogishi. Implemen- tation and evaluation of latency visualization method for teleoperated vehicle. In2021 IEEE Intelligent V ehicles Symposium (IV), pages 1–7. IEEE, 2021
work page 2021
-
[8]
Rute Luz, Jos ´e Lu ´ıs Silva, and Rodrigo Ventura. Enhanced teleop- eration interfaces for multi-second latency conditions: System design and evaluation.IEEE Access, 11:10935–10953, 2023
work page 2023
-
[9]
Active safety system for semi-autonomous teleoperated vehicles
Smit Saparia, Andreas Schimpe, and Laura Ferranti. Active safety system for semi-autonomous teleoperated vehicles. In2021 IEEE Intelligent V ehicles Symposium Workshops (IV Workshops), pages 141–
-
[10]
Teleoperated vehicle-perspective predictive display accounting for network time delays
Jai Prakash, Michele Vignati, Stefano Arrigoni, Mattia Bersani, and Simone Mentasti. Teleoperated vehicle-perspective predictive display accounting for network time delays. InInternational Design Engineer- ing Technical Conferences and Computers and Information in Engi- neering Conference, volume 59216, page V003T01A022. American Society of Mechanical Eng...
work page 2019
-
[11]
Predictive displays for high latency teleoperation
Mark J Brudnak. Predictive displays for high latency teleoperation. In Proc. NDIA Ground V eh. Syst. Eng. Technol. Symp, pages 1–16, 2016
work page 2016
-
[12]
Jai Prakash, Michele Vignati, Daniele Vignarca, Edoardo Sabbioni, and Federico Cheli. Predictive display with perspective projection of surroundings in vehicle teleoperation to account time-delays.IEEE Transactions on Intelligent Transportation Systems, 24(9):9084–9097, 2023
work page 2023
-
[13]
MD Moniruzzaman, Alexander Rassau, Douglas Chai, and Syed Mohammed Shamsul Islam. Long future frame prediction using op- tical flow-informed deep neural networks for enhancement of robotic teleoperation in high latency environments.Journal of Field Robotics, 40(2):393–425, 2023
work page 2023
-
[14]
Deserts: Delay-tolerant semi- autonomous robot teleoperation for surgery
Glebys Gonzalez, Mridul Agarwal, Mythra V Balakuntala, Md Ma- sudur Rahman, Upinder Kaur, Richard M V oyles, Vaneet Aggar- wal, Yexiang Xue, and Juan Wachs. Deserts: Delay-tolerant semi- autonomous robot teleoperation for surgery. In2021 IEEE Interna- tional Conference on Robotics and Automation (ICRA), pages 12693– 12700. IEEE, 2021
work page 2021
-
[15]
Neil Sachdeva, Misha Klopukh, Rachel St Clair, and William Edward Hahn. Using conditional generative adversarial networks to reduce the effects of latency in robotic telesurgery.Journal of Robotic Surgery, 15:635–641, 2021
work page 2021
-
[16]
A generative model-based predictive display for robotic teleoperation
Bowen Xie, Mingjie Han, Jun Jin, Martin Barczyk, and Martin J¨agersand. A generative model-based predictive display for robotic teleoperation. In2021 IEEE International Conference on Robotics and Automation (ICRA), pages 2407–2413. IEEE, 2021
work page 2021
-
[17]
Recurrent neural network based language model
Tomas Mikolov, Martin Karafi ´at, Lukas Burget, Jan Cernock `y, and Sanjeev Khudanpur. Recurrent neural network based language model. InInterspeech, volume 2, pages 1045–1048. Makuhari, 2010
work page 2010
-
[18]
Fawad Naseer, Muhammad Nasir Khan, Akhtar Rasool, and Nafees Ayub. A novel approach to compensate delay in communication by predicting teleoperator behaviour using deep learning and rein- forcement learning to control telepresence robot.Electronics Letters, 59(9):e12806, 2023
work page 2023
-
[19]
Sepp Hochreiter and J ¨urgen Schmidhuber. Long short-term memory. Neural computation, 9(8):1735–1780, 1997
work page 1997
-
[20]
Qiang Zhang, Zhouli Xu, Yihang Wang, Lingfang Yang, Xiaolin Song, and Zhi Huang. Predicted trajectory guidance control framework of teleoperated ground vehicles compensating for delays.IEEE Transactions on V ehicular Technology, 72(9):11264–11274, 2023
work page 2023
-
[21]
Jiajun Duan, Xiong Wei, Jiahua Zhou, Tingting Wang, Xuechao Ge, and Zhi Wang. Latency compensation and prediction for wireless train to ground communication network based on hybrid lstm model.IEEE Transactions on Intelligent Transportation Systems, 25(2):1637–1645, 2023
work page 2023
-
[22]
A brief survey of telerobotic time delay mitigation.Frontiers in Robotics and AI, 7:578805, 2020
Parinaz Farajiparvar, Hao Ying, and Abhilash Pandya. A brief survey of telerobotic time delay mitigation.Frontiers in Robotics and AI, 7:578805, 2020
work page 2020
-
[23]
Francis Boabang, Amin Ebrahimzadeh, Roch H Glitho, Halima El- biaze, Martin Maier, and Fatna Belqasmi. A machine learning framework for handling delayed/lost packets in tactile internet remote robotic surgery.IEEE Transactions on Network and Service Manage- ment, 18(4):4829–4845, 2021
work page 2021
-
[24]
An lstm-based bilateral active estima- tion model for robotic teleoperation with varying time delay
Xuhui Zhou, Weibang Bai, Yunxiao Ren, Ziqi Yang, Ziwei Wang, Benny Lo, and Eric M Yeatman. An lstm-based bilateral active estima- tion model for robotic teleoperation with varying time delay. In2022 International Conference on Advanced Robotics and Mechatronics (ICARM), pages 725–730. IEEE, 2022
work page 2022
-
[25]
Sarah Chams Bacha, Weibang Bai, Ziwei Wang, Bo Xiao, and Eric M Yeatman. Deep reinforcement learning-based control framework for multilateral telesurgery.IEEE Transactions on Medical Robotics and Bionics, 4(2):352–355, 2022
work page 2022
-
[26]
Hadi Beik-Mohammadi, Matthias Kerzel, Benedikt Pleintinger, Thomas Hulin, Philipp Reisich, Annika Schmidt, Aaron Pereira, Stefan Wermter, and Neal Y Lii. Model mediated teleoperation with a hand- arm exoskeleton in long time delays using reinforcement learning. In2020 29th IEEE International Conference on Robot and Human Interactive Communication (RO-MAN)...
work page 2020
-
[27]
Collision-free path generation for teleoperation of unmanned vehicles
Fatima Kashwani, Bilal Hassan, Majid Khonji, and Jorge Dias. Collision-free path generation for teleoperation of unmanned vehicles. In2023 21st International Conference on Advanced Robotics (ICAR), pages 21–27. IEEE, 2023
work page 2023
-
[28]
Evaluation of predictive display for teleoperated driving using carla simulator
Fatima Kashwani, Bilal Hassan, Peng-Yong Kong, Majid Khonji, and Jorge Dias. Evaluation of predictive display for teleoperated driving using carla simulator. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 12190–12195. IEEE, 2024
work page 2024
-
[29]
Anthony Hu, Gianluca Corrado, Nicolas Griffiths, Zachary Murez, Corina Gurau, Hudson Yeo, Alex Kendall, Roberto Cipolla, and Jamie Shotton. Model-based imitation learning for urban driving.Advances in Neural Information Processing Systems, 35:20703–20716, 2022
work page 2022
-
[30]
End-to-end urban driving by imitating a reinforcement learning coach
Zhejun Zhang, Alexander Liniger, Dengxin Dai, Fisher Yu, and Luc Van Gool. End-to-end urban driving by imitating a reinforcement learning coach. InProceedings of the IEEE/CVF international conference on computer vision, pages 15222–15232, 2021
work page 2021
-
[31]
LTX-Video: Realtime Video Latent Diffusion
Yoav HaCohen, Nisan Chiprut, Benny Brazowski, Daniel Shalem, Dudu Moshe, Eitan Richardson, Eran Levin, Guy Shiran, Nir Zabari, Ori Gordon, et al. Ltx-video: Realtime video latent diffusion.arXiv preprint arXiv:2501.00103, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendele- vitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen- Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.