Recognition: no theorem link
The Silent Vote: Improving Zero-Shot LLM Reliability by Aggregating Semantic Neighborhoods
Pith reviewed 2026-05-12 03:17 UTC · model grok-4.3
The pith
Aggregating semantic neighborhoods recovers lost probability mass and reduces overconfidence in zero-shot LLM classification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
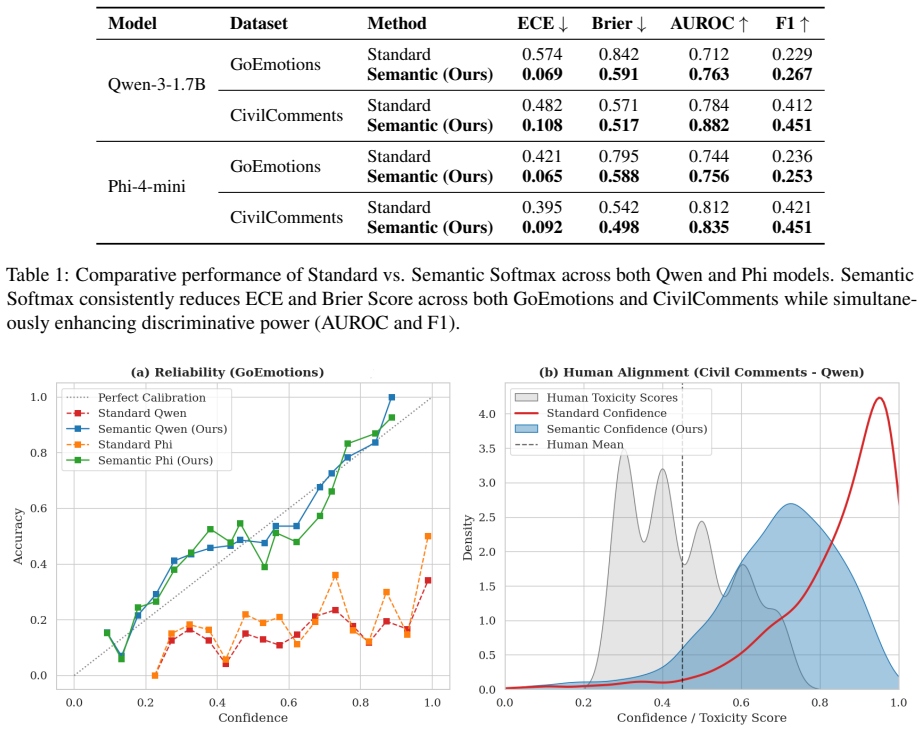
Standard constrained decoding applies softmax only over a small target vocabulary and thereby discards the probability mass that the model originally assigned to semantic synonyms of those labels. The paper terms this discarded mass the Silent Vote and the resulting distortion renormalization bias. Semantic Softmax, an inference-time layer, recovers the lost mass by aggregating the raw scores of the semantic neighborhood around each target label, yielding predictions that are both better calibrated and more discriminative.
What carries the argument
Semantic Softmax, an inference-time aggregation that sums the raw model scores over the semantic neighborhood surrounding each target label.
If this is right
- Substantially reduces Expected Calibration Error and Brier Score on the tested datasets.
- Increases AUROC and Macro-F1 scores for both Qwen-3 and Phi-4-mini.
- Yields more calibrated outputs while preserving or improving discriminative performance.
- Accounts for linguistic synonyms that standard constrained decoding ignores.
Where Pith is reading between the lines
- The same aggregation step could be applied to any constrained generation setting where output tokens carry overlapping meaning.
- Calibration problems in zero-shot classification may be partly an artifact of vocabulary restriction rather than a pure model defect.
- Automated identification of semantic neighborhoods could extend the method beyond manually chosen label sets.
Load-bearing premise
Semantic neighborhoods around target labels can be reliably identified and aggregating their raw scores recovers the discarded probability mass without introducing new systematic bias.
What would settle it
Applying Semantic Softmax to a synthetic vocabulary in which target labels have no semantic neighbors produces calibration error equal to or higher than standard softmax.
Figures
read the original abstract
Large Language Models are increasingly used as zero-shot classifiers in complex reasoning tasks. However, standard constrained decoding suffers from a phenomenon we define as Renormalization Bias. When a model is restricted to a small set of target labels, the standard softmax operation discards the probability mass assigned to semantic synonyms in the original distribution. This loss of information, which we call the Silent Vote, results in artificial overconfidence and poor calibration. We propose Semantic Softmax, an inference-time layer that recovers this lost information by aggregating the scores of the semantic neighborhood surrounding each target label. We evaluate this approach on Qwen-3 and Phi-4-mini models using GoEmotions and Civil Comments datasets. Our results demonstrate consistent improvements across all evaluation metrics: Semantic Softmax substantially reduces Expected Calibration Error (ECE) and Brier Score, while simultaneously enhancing discriminative performance in terms of AUROC and Macro-F1. By accounting for linguistic nuances, our method provides a more calibrated and accurate alternative for zero-shot classification.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Semantic Softmax, an inference-time technique to mitigate Renormalization Bias in zero-shot LLM classification by aggregating probability scores from semantic neighborhoods around target labels, thereby recovering the 'Silent Vote' discarded by standard softmax. It reports empirical improvements in calibration metrics (ECE, Brier Score) and discriminative performance (AUROC, Macro-F1) on the GoEmotions and Civil Comments datasets using Qwen-3 and Phi-4-mini models.
Significance. Should the method prove robust and free of artifacts like double-counting, it would offer a lightweight, training-free enhancement to zero-shot classification reliability, addressing a common issue in LLM-based labeling. The reported gains across multiple metrics on two datasets and models indicate practical value for applications requiring calibrated predictions, though stronger baselines and statistical validation would strengthen the case.
major comments (2)
- Abstract: The description of Semantic Softmax as 'aggregating the scores of the semantic neighborhood surrounding each target label' supplies neither a definition of how neighborhoods are constructed (e.g., embedding similarity or prompting) nor the aggregation formula. This is load-bearing for the central claim that the procedure recovers discarded probability mass without systematic bias or double-counting, as overlapping tokens (e.g., 'happy' across 'joy' and 'optimism' in GoEmotions) would otherwise inflate recovered mass.
- Evaluation section: No error bars, statistical significance tests, or comparisons to established calibration methods such as temperature scaling or label smoothing are reported, despite the claim of 'substantial' reductions in ECE and Brier Score alongside gains in AUROC and Macro-F1. This prevents assessment of whether the observed improvements exceed what could arise from over-allocation artifacts.
minor comments (2)
- The manuscript introduces 'Renormalization Bias' and 'Silent Vote' without situating them against existing calibration literature (e.g., temperature scaling or post-hoc recalibration techniques).
- Reproducibility would be aided by an explicit pseudocode or equation block detailing neighborhood extraction and score aggregation, currently absent from the provided description.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights opportunities to improve clarity and empirical rigor in our work on Semantic Softmax. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: Abstract: The description of Semantic Softmax as 'aggregating the scores of the semantic neighborhood surrounding each target label' supplies neither a definition of how neighborhoods are constructed (e.g., embedding similarity or prompting) nor the aggregation formula. This is load-bearing for the central claim that the procedure recovers discarded probability mass without systematic bias or double-counting, as overlapping tokens (e.g., 'happy' across 'joy' and 'optimism' in GoEmotions) would otherwise inflate recovered mass.
Authors: We agree the abstract is overly concise and omits key operational details. Section 3 of the manuscript defines semantic neighborhoods via embedding-based retrieval (cosine similarity threshold on token embeddings from a sentence encoder) and specifies the aggregation as a sum of probabilities over the neighborhood tokens, followed by renormalization to the target label set. To prevent double-counting from overlaps, the implementation uses a deduplication step that assigns each token to at most one neighborhood based on maximum similarity. We will expand the abstract with a brief description of neighborhood construction, the aggregation formula, and the overlap-handling mechanism to make the central claim self-contained. revision: yes
-
Referee: Evaluation section: No error bars, statistical significance tests, or comparisons to established calibration methods such as temperature scaling or label smoothing are reported, despite the claim of 'substantial' reductions in ECE and Brier Score alongside gains in AUROC and Macro-F1. This prevents assessment of whether the observed improvements exceed what could arise from over-allocation artifacts.
Authors: We acknowledge that the current evaluation lacks these elements, which limits the strength of the claims. We will add error bars by averaging results over multiple random seeds and reporting standard deviations. We will also include statistical significance testing (paired t-tests across runs) for the reported metric improvements. In addition, we will introduce baselines using temperature scaling and label smoothing applied to the standard softmax, allowing direct comparison to show that Semantic Softmax gains exceed those obtainable from simple recalibration. These changes will appear in the revised evaluation section and tables. revision: yes
Circularity Check
No circularity: Semantic Softmax is an independent post-hoc aggregation layer
full rationale
The paper defines Renormalization Bias and Silent Vote descriptively from the known behavior of softmax under label constraints, then introduces Semantic Softmax as a separate inference-time aggregation over semantic neighborhoods. No equations, fitted parameters, or self-citations are shown that would make the claimed ECE/Brier reductions equivalent to the input distribution by construction. The method is presented as recovering information via external neighborhood identification rather than renaming or re-deriving the original probabilities. Empirical gains on GoEmotions and Civil Comments are therefore not forced by the definition itself.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Language Models are Few-Shot Learners , url =
Brown, Tom and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared D and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and Agarwal, Sandhini and Herbert-Voss, Ariel and Krueger, Gretchen and Henighan, Tom and Child, Rewon and Ramesh, Aditya and Ziegler, Daniel and Wu, Jeffrey and Winte...
-
[2]
doi:10.1073/pnas.2305016120 , author =
Fabrizio Gilardi and Meysam Alizadeh and Maël Kubli , title =. Proceedings of the National Academy of Sciences , volume =. 2023 , doi =. https://www.pnas.org/doi/pdf/10.1073/pnas.2305016120 , abstract =
-
[3]
The 64th Annual Meeting of the Association for Computational Linguistics -- Industry Track , year=
Prompt-Level Distillation: A Non-Parametric Alternative to Model Fine-Tuning for Efficient Reasoning , author=. The 64th Annual Meeting of the Association for Computational Linguistics -- Industry Track , year=
-
[4]
Constrained Language Models Yield Few-Shot Semantic Parsers
Shin, Richard and Lin, Christopher and Thomson, Sam and Chen, Charles and Roy, Subhro and Platanios, Emmanouil Antonios and Pauls, Adam and Klein, Dan and Eisner, Jason and Van Durme, Benjamin. Constrained Language Models Yield Few-Shot Semantic Parsers. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021. doi:10.1...
-
[5]
and Zhang, Hao and Gonzalez, Joseph E
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric P. and Zhang, Hao and Gonzalez, Joseph E. and Stoica, Ion , title =. Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =. 2023 , publisher =
work page 2023
-
[6]
Exploiting Cloze-Questions for Few-Shot Text Classification and Natural Language Inference
Schick, Timo and Sch. Exploiting Cloze-Questions for Few-Shot Text Classification and Natural Language Inference. Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume. 2021. doi:10.18653/v1/2021.eacl-main.20
-
[7]
Distributed Representations of Words and Phrases and their Compositionality , url =
Mikolov, Tomas and Sutskever, Ilya and Chen, Kai and Corrado, Greg S and Dean, Jeff , booktitle =. Distributed Representations of Words and Phrases and their Compositionality , url =
-
[8]
arXiv preprint arXiv:2604.00323 , year=
Large Language Models in the Abuse Detection Pipeline , author=. arXiv preprint arXiv:2604.00323 , year=
-
[9]
Proceedings of the 34th International Conference on Machine Learning , pages =
On Calibration of Modern Neural Networks , author =. Proceedings of the 34th International Conference on Machine Learning , pages =. 2017 , editor =
work page 2017
-
[10]
Revisiting the Calibration of Modern Neural Networks , url =
Minderer, Matthias and Djolonga, Josip and Romijnders, Rob and Hubis, Frances and Zhai, Xiaohua and Houlsby, Neil and Tran, Dustin and Lucic, Mario , booktitle =. Revisiting the Calibration of Modern Neural Networks , url =
-
[11]
Adversarial NLI : A new benchmark for natural language understanding
Nie, Yixin and Williams, Adina and Dinan, Emily and Bansal, Mohit and Weston, Jason and Kiela, Douwe. Adversarial NLI : A New Benchmark for Natural Language Understanding. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.441
-
[12]
Toxicity Detection: Does Context Really Matter?
Pavlopoulos, John and Sorensen, Jeffrey and Dixon, Lucas and Thain, Nithum and Androutsopoulos, Ion. Toxicity Detection: Does Context Really Matter?. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.396
-
[13]
G o E motions: A Dataset of Fine-Grained Emotions
Demszky, Dorottya and Movshovitz-Attias, Dana and Ko, Jeongwoo and Cowen, Alan and Nemade, Gaurav and Ravi, Sujith. G o E motions: A Dataset of Fine-Grained Emotions. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.372
-
[14]
Making Pre-trained Language Models Better Few-shot Learners
Gao, Tianyu and Fisch, Adam and Chen, Danqi. Making Pre-trained Language Models Better Few-shot Learners. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 2021. doi:10.18653/v1/2021.acl-long.295
-
[15]
Efficient Guided Generation for Large Language Models , author=. 2023 , eprint=
work page 2023
-
[16]
Language Models (Mostly) Know What They Know , author=. 2022 , eprint=
work page 2022
-
[17]
Robert Kirk and Ishita Mediratta and Christoforos Nalmpantis and Jelena Luketina and Eric Hambro and Edward Grefenstette and Roberta Raileanu , booktitle=. Understanding the Effects of. 2024 , url=
work page 2024
-
[18]
Tian, Katherine and Mitchell, Eric and Zhou, Allan and Sharma, Archit and Rafailov, Rafael and Yao, Huaxiu and Finn, Chelsea and Manning, Christopher. Just Ask for Calibration: Strategies for Eliciting Calibrated Confidence Scores from Language Models Fine-Tuned with Human Feedback. Proceedings of the 2023 Conference on Empirical Methods in Natural Langua...
- [19]
-
[20]
Publications Manual , year = "1983", publisher =
work page 1983
-
[21]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
- [22]
-
[23]
Dan Gusfield , title =. 1997
work page 1997
-
[24]
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
work page 2015
-
[25]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.