Recognition: 2 theorem links
· Lean TheoremAccelerating Power Method with Fast Sketching for Stronger Low-Rank Approximation
Pith reviewed 2026-05-12 03:05 UTC · model grok-4.3
The pith
Fast sketching accelerates the power method for low-rank matrix approximation by relying on regularized spectral properties.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
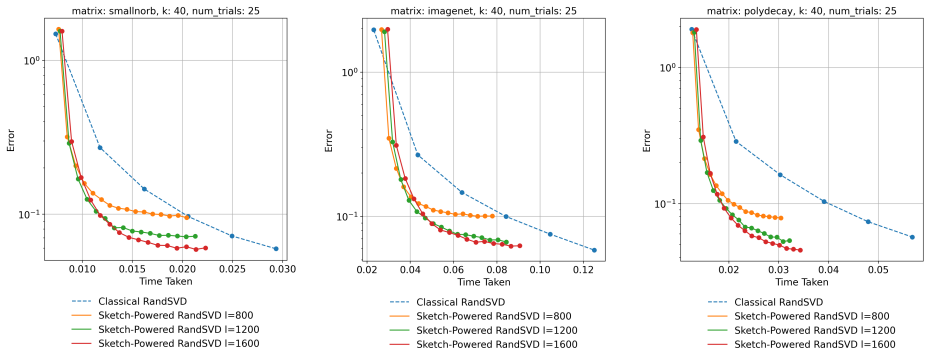
Fast sketching methods that obey regularized spectral approximation allow the power method to be accelerated for large target ranks while preserving provable efficiency, yielding practical algorithms for SVD, low-rank factorization, and Nyström approximation.
What carries the argument
Regularized spectral approximation, a property of fast sketching that bounds approximation error in a regularized sense and generalizes power-method analysis more flexibly than classical arguments.
If this is right
- Simple provably efficient methods for singular value decomposition
- Efficient low-rank factorization procedures
- Accelerated Nyström approximation algorithms
- Strong numerical performance on standard benchmark problems
Where Pith is reading between the lines
- The same sketching-plus-regularization idea could shorten iteration counts in other matrix iteration schemes such as subspace iteration.
- Implementation on very large sparse matrices from scientific computing would test whether the theoretical savings translate to wall-clock gains.
- Connections to existing randomized SVD libraries could be checked by replacing their internal power steps with the sketched variant.
Load-bearing premise
Fast sketching methods must satisfy regularized spectral approximation properties that generalize power-method guarantees more flexibly than traditional arguments for arbitrary data matrices.
What would settle it
A data matrix and sketching method where the regularized spectral approximation bound fails, causing the accelerated power iteration to lose its convergence rate or accuracy guarantees.
Figures

read the original abstract
The power method is one of the most fundamental tools for extracting top principal components from data through low-rank matrix approximation. Yet, when the target rank is large, the cost of matrix multiplication associated with this procedure becomes a major bottleneck. We develop an algorithmic and theoretical framework for accelerating the power method using fast sketching, which is a popular paradigm in randomized linear algebra. Our framework leads to simple and provably efficient methods for singular value decomposition, low-rank factorization, and Nystr\"om approximation, which attain strong numerical performance on benchmark problems. The key novelty in our analysis is the use of regularized spectral approximation, a property of fast sketching methods which proves more flexible in generalizing power method guarantees than traditional arguments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an algorithmic and theoretical framework to accelerate the classical power method for low-rank matrix approximation by incorporating fast sketching techniques from randomized linear algebra. The central novelty is the introduction of 'regularized spectral approximation' as a property of sketching methods, which is used to derive provably efficient algorithms for singular value decomposition, low-rank factorization, and Nyström approximation. The work claims these methods achieve strong numerical performance on benchmark problems while generalizing power-method guarantees more flexibly than traditional analyses.
Significance. If the central claims hold, this framework could provide a practical and theoretically grounded way to scale iterative low-rank methods to larger problems by leveraging sketching for reduced matrix-multiplication costs. The regularized spectral approximation concept, if properly conditioned, might offer broader applicability than standard perturbation or subspace arguments in randomized numerical linear algebra, and the reported empirical results on benchmarks indicate potential for immediate use in applications like PCA and kernel methods.
major comments (2)
- [§3] §3 (Theoretical Framework), Definition of regularized spectral approximation: The property is asserted to generalize power-method guarantees more flexibly than classical arguments, yet the manuscript does not delineate the precise requirements on the sketching distribution, regularization parameter, or matrix spectrum (e.g., singular-value gap or decay rate) needed for the property to hold for arbitrary data matrices. Without these conditions, it is unclear whether the accelerated iterates retain the claimed convergence rates or error bounds outside restricted regimes.
- [§4] §4 (Applications to SVD, low-rank factorization, and Nyström), Theorems on provable efficiency: The efficiency claims for the three target problems rest on the regularized spectral approximation property, but the provided analysis does not include explicit error bounds or full derivations that would confirm the guarantees without additional post-hoc assumptions on the input matrix. This makes the central claim of 'provably efficient methods' difficult to verify as stated.
minor comments (2)
- [Abstract] Abstract: The phrase 'strong numerical performance on benchmark problems' should be accompanied by a brief indication of the baselines, metrics, and matrix sizes used, to allow readers to assess the empirical claims at a glance.
- [Notation section] Notation: The manuscript introduces several sketching-related quantities without a consolidated table of symbols; adding one would improve readability for the numerical linear algebra audience.
Simulated Author's Rebuttal
We thank the referee for their careful reading and valuable comments on our paper. We address the major comments point by point below, and we are prepared to make revisions to improve the clarity of the theoretical framework.
read point-by-point responses
-
Referee: [§3] §3 (Theoretical Framework), Definition of regularized spectral approximation: The property is asserted to generalize power-method guarantees more flexibly than classical arguments, yet the manuscript does not delineate the precise requirements on the sketching distribution, regularization parameter, or matrix spectrum (e.g., singular-value gap or decay rate) needed for the property to hold for arbitrary data matrices. Without these conditions, it is unclear whether the accelerated iterates retain the claimed convergence rates or error bounds outside restricted regimes.
Authors: We appreciate this observation. The definition of regularized spectral approximation in Section 3 is intentionally general to encompass a broad class of sketching methods. The specific conditions for common sketching distributions (such as sub-Gaussian or fast Johnson-Lindenstrauss transforms) and the dependence on the regularization parameter and spectral properties are derived in the proofs of the main theorems in Section 4. To address the concern, we will add a new subsection or remark in Section 3 that explicitly states the sufficient conditions on the sketching distribution and matrix spectrum required for the property to hold, including examples for Gaussian sketching and the role of the singular value gap. revision: yes
-
Referee: [§4] §4 (Applications to SVD, low-rank factorization, and Nyström), Theorems on provable efficiency: The efficiency claims for the three target problems rest on the regularized spectral approximation property, but the provided analysis does not include explicit error bounds or full derivations that would confirm the guarantees without additional post-hoc assumptions on the input matrix. This makes the central claim of 'provably efficient methods' difficult to verify as stated.
Authors: We thank the referee for pointing this out. The theorems in Section 4 do provide error bounds expressed in terms of the regularized spectral approximation error, and the proofs (some in the appendix) show how these translate to the final guarantees for SVD, low-rank factorization, and Nyström approximation. However, we agree that making the derivations more self-contained and explicit, without relying on implicit assumptions, would strengthen the paper. We will revise the theorems to include more detailed statements of the bounds and expand the proof sketches in the main text or appendix to cover all steps explicitly for each application. revision: yes
Circularity Check
Derivation chain is self-contained with no circularity
full rationale
The paper introduces regularized spectral approximation as a property of fast sketching methods to generalize power-method guarantees more flexibly than traditional arguments. This is framed as an independent analytical device drawn from randomized linear algebra rather than being defined in terms of the SVD, low-rank factorization, or Nyström outputs it is used to prove. No step reduces a prediction to a fitted input, renames a known result, or relies on a load-bearing self-citation whose justification collapses into the present work. The claimed provable efficiency therefore rests on external sketching properties and does not collapse by construction to the paper's own inputs or definitions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Fast sketching methods satisfy regularized spectral approximation properties that generalize power method guarantees.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearregularized spectral approximation ... (1−ε)(AA⊤ + λI) ⪯ ASS⊤A⊤ + λI ⪯ (1+ε)(AA⊤ + λI)
-
IndisputableMonolith/Foundation/DimensionForcing.leanalexander_duality_circle_linking unclearTheorem 2.1 ... time ˜O(nnz(A)/ε + mlk/ε³)
Reference graph
Works this paper leans on
-
[1]
Halko, N., Martinsson, P.-G. & Tropp, J. A. Finding structure with randomness: Probabilistic algorithms for constructing approximate matrix decompositions.SIAM review53,217–288 (2011)
work page 2011
-
[2]
Rokhlin, V., Szlam, A. & Tygert, M. A randomized algorithm for principal component analysis. SIAM Journal on Matrix Analysis and Applications31,1100–1124 (2010)
work page 2010
-
[3]
Gu, M. Subspace iteration randomization and singular value problems.SIAM Journal on Scientific Computing37,A1139–A1173 (2015)
work page 2015
- [4]
-
[5]
Sarlos, T.Improved approximation algorithms for large matrices via random projectionsin2006 47th annual IEEE symposium on foundations of computer science (FOCS’06)(2006), 143–152
work page 2006
-
[6]
Clarkson, K. L. & Woodruff, D. P. Low-rank approximation and regression in input sparsity time.Journal of the ACM (JACM)63,1–45 (2017)
work page 2017
-
[7]
Woodruff, D. P. Sketching as a Tool for Numerical Linear Algebra.Foundations and Trends® in Theoretical Computer Science10,1–157 (2014)
work page 2014
-
[8]
Gittens, A. & Mahoney, M.Revisiting the nystrom method for improved large-scale machine learninginInternational Conference on Machine Learning(2013), 567–575
work page 2013
-
[9]
Cohen, M. B., Nelson, J. & Woodruff, D. P.Optimal Approximate Matrix Product in Terms of Stable Rankin43rd International Colloquium on Automata, Languages, and Programming (ICALP 2016)55(2016), 11:1–11:14
work page 2016
-
[10]
Fast and stable randomized low-rank matrix approximation.arXiv preprint arXiv:2009.11392(2020)
Nakatsukasa, Y. Fast and stable randomized low-rank matrix approximation.arXiv preprint arXiv:2009.11392(2020)
-
[11]
Hardt, M. & Price, E. The noisy power method: A meta algorithm with applications.Advances in neural information processing systems27(2014)
work page 2014
- [12]
- [13]
-
[14]
Alaoui, A. & Mahoney, M. W. Fast randomized kernel ridge regression with statistical guarantees. Advances in neural information processing systems28(2015)
work page 2015
-
[15]
Musco, C. & Musco, C. Recursive sampling for the nystrom method.Advances in neural information processing systems30(2017)
work page 2017
-
[16]
Rudi, A., Calandriello, D., Carratino, L. & Rosasco, L. On fast leverage score sampling and optimal learning.Advances in Neural Information Processing Systems31(2018)
work page 2018
-
[17]
Garg, S. & Dereziński, M.Faster Low-Rank Approximation and Kernel Ridge Regression via the Block-Nyström MethodinThe Thirty Eighth Annual Conference on Learning Theory(2025), 2291–2325
work page 2025
-
[18]
Nelson, J. & Nguyên, H. L.OSNAP: Faster numerical linear algebra algorithms via sparser subspace embeddingsin2013 ieee 54th annual symposium on foundations of computer science (2013), 117–126. 12
work page 2013
-
[19]
Chenakkod, S., Dereziński, M. & Dong, X.Optimal Oblivious Subspace Embeddings with Near- Optimal Sparsityin52nd International Colloquium on Automata, Languages, and Programming (ICALP 2025)(2025)
work page 2025
-
[20]
Williams, C. & Seeger, M. Using the Nyström method to speed up kernel machines.Advances in neural information processing systems13(2000)
work page 2000
-
[21]
Dereziński, M. & Sidford, A.Approaching Optimality for Solving Dense Linear Systems with Low-Rank StructureinACM-SIAM Symposium on Discrete Algorithms(2025)
work page 2025
-
[22]
LeCun, Y., Huang, F. J. & Bottou, L.Learning methods for generic object recognition with invariance to pose and lightinginProceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2004. CVPR 2004.2(2004), II–104
work page 2004
-
[23]
Deng, J.et al. Imagenet: A large-scale hierarchical image databasein2009 IEEE conference on computer vision and pattern recognition(2009), 248–255
work page 2009
-
[24]
Charikar, M., Chen, K. & Farach-Colton, M.Finding Frequent Items in Data Streamsin Proceedings of the 29th International Colloquium on Automata, Languages and Programming (Springer-Verlag, Berlin, Heidelberg, 2002), 693–703.isbn: 3540438645
work page 2002
-
[25]
Kuczyński, J. & Woźniakowski, H. Estimating the largest eigenvalue by the power and Lanczos algorithms with a random start.SIAM Journal on Matrix Analysis and Applications13,1094– 1122 (1992)
work page 1992
-
[26]
Musco, C. & Musco, C. Randomized block krylov methods for stronger and faster approximate singular value decomposition.Advances in neural information processing systems28(2015)
work page 2015
- [27]
-
[28]
Chen, T., Epperly, E. N., Meyer, R. A., Musco, C. & Rao, A.Does block size matter in randomized block Krylov low-rank approximation?inProceedings of the 2026 Annual ACM- SIAM Symposium on Discrete Algorithms (SODA)(2026), 1026–1046
work page 2026
-
[29]
Meyer, R., Musco, C. & Musco, C.On the unreasonable effectiveness of single vector Krylov methods for low-rank approximationinProceedings of the 2024 Annual ACM-SIAM Symposium on Discrete Algorithms (SODA)(2024), 811–845
work page 2024
-
[30]
Jain, P., Netrapalli, P. & Sanghavi, S.Low-rank matrix completion using alternating minimiza- tioninProceedings of the forty-fifth annual ACM symposium on Theory of computing(2013), 665–674
work page 2013
-
[31]
Hardt, M. & Roth, A.Beyond worst-case analysis in private singular vector computationin Proceedings of the forty-fifth annual ACM symposium on Theory of computing(2013), 331–340
work page 2013
-
[32]
Drineas,P.&Mahoney,M.W.RandNLA:randomizednumericallinearalgebra.Communications of the ACM59,80–90 (2016)
work page 2016
-
[33]
Martinsson, P.-G. & Tropp, J. A. Randomized numerical linear algebra: Foundations and algorithms.Acta Numerica29,403–572 (2020)
work page 2020
- [34]
-
[35]
Dereziński, M. & Mahoney, M. W.Recent and upcoming developments in randomized numerical linear algebra for machine learninginProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining(2024), 6470–6479. 13
work page 2024
-
[36]
Drineas, P., Kannan, R. & Mahoney, M. W. Fast Monte Carlo algorithms for matrices II: Computing a low-rank approximation to a matrix.SIAM Journal on computing36,158–183 (2006)
work page 2006
-
[37]
Musco, C. & Woodruff, D. P.Sublinear time low-rank approximation of positive semidefinite matricesin2017 IEEE 58th Annual Symposium on Foundations of Computer Science (FOCS) (2017), 672–683. A Related Work Early work in numerical linear algebra focused on using the power method for estimating the largest singular vector of a matrix [25]. The modern analys...
work page 2017
-
[38]
study a noisy version of the power method, where each application ofAis accompanied by some additive noise, a model that arises in applications to matrix completion [30], streaming algorithms [13], and differential privacy [31]. While [11] introduce constraints on the additive noise that scale with the spectral gap ofA, in our work, we are dealing with a ...
-
[39]
This is not a problem sincePBΩ =P eBΩ. IfBΩis a λ2-regularized1 /2-spectral approximation ofB, theneBΩis a λ2/θ2(2q+1)-regularized 1/2-spectral approximation of eB. Since θ2(2q+1) = λ′2q+1 1 ≥λ 2, we may assume thateBΩis a 1-regularized1/2-spectral approximation of eB. Thus, by the proof of Lemma 3.3,I−P⪯2( eBeB⊤ +I) −1. For any fixedi, this givesu⊤ i (I ...
-
[40]
S⊤ satisfies the( k, p ν/8)-AMM property forUA andP ¯AB, whereU A is an orthonormal basis for the column space ofA,PA is the orthogonal projection onto the column space ofA, andP ¯A :=I−P A; 2.S ⊤ s a (1/2)-subspace embedding for the column space ofA. 21 Proof of Lemma 3.6.We may assume thatShas the( ε/2 √ 2, δ′, 2k, p)-OSE moments property by adjusting c...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.