Recognition: 2 theorem links
· Lean TheoremSafe Exploration for Nonlinear Processes Using Online Gaussian Process Learning
Pith reviewed 2026-05-12 02:58 UTC · model grok-4.3
The pith
A data-driven control method learns unknown nonlinear dynamics online with Gaussian processes while keeping the system stable and safe via expanding probabilistic invariant sets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By modeling unmodeled nonlinear dynamics as an online-learned Gaussian process residual and deriving a probabilistic control-invariant set from Lyapunov theory on the linear approximation, the framework computes controls via convex optimization that satisfy safety constraints with high probability while maximizing information gain, allowing the invariant set to expand adaptively as uncertainty decreases and providing finite-sample safety guarantees.
What carries the argument
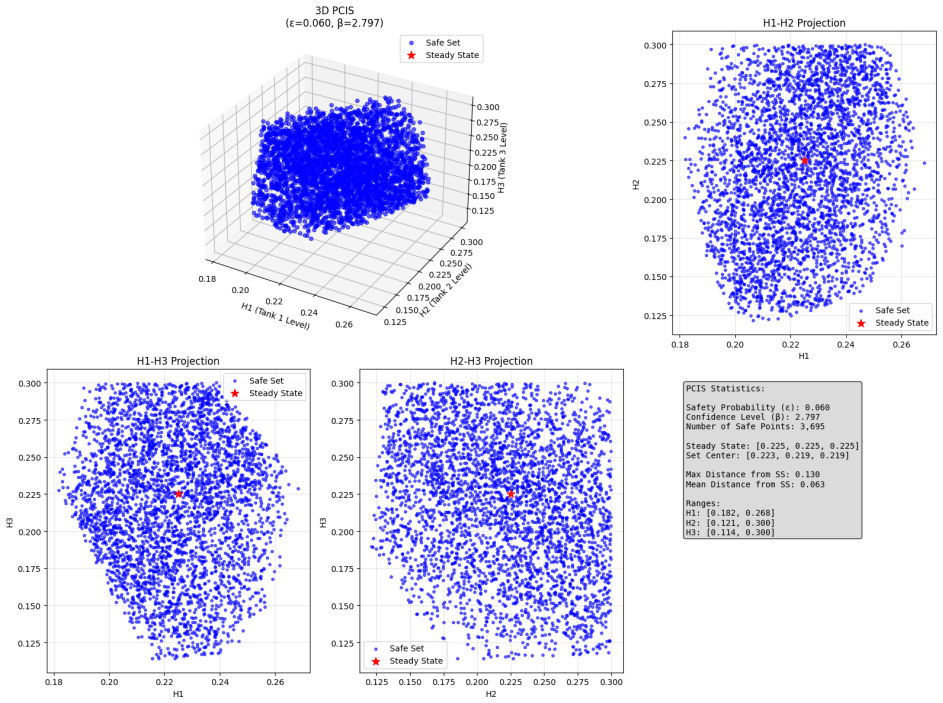
The probabilistic control-invariant set derived from Lyapunov theory, which folds in the Gaussian process uncertainty bounds to create time-varying high-probability safety constraints for the information-maximizing quadratic program.
If this is right
- The closed-loop system remains inside its constraints with high probability for the entire duration of online learning.
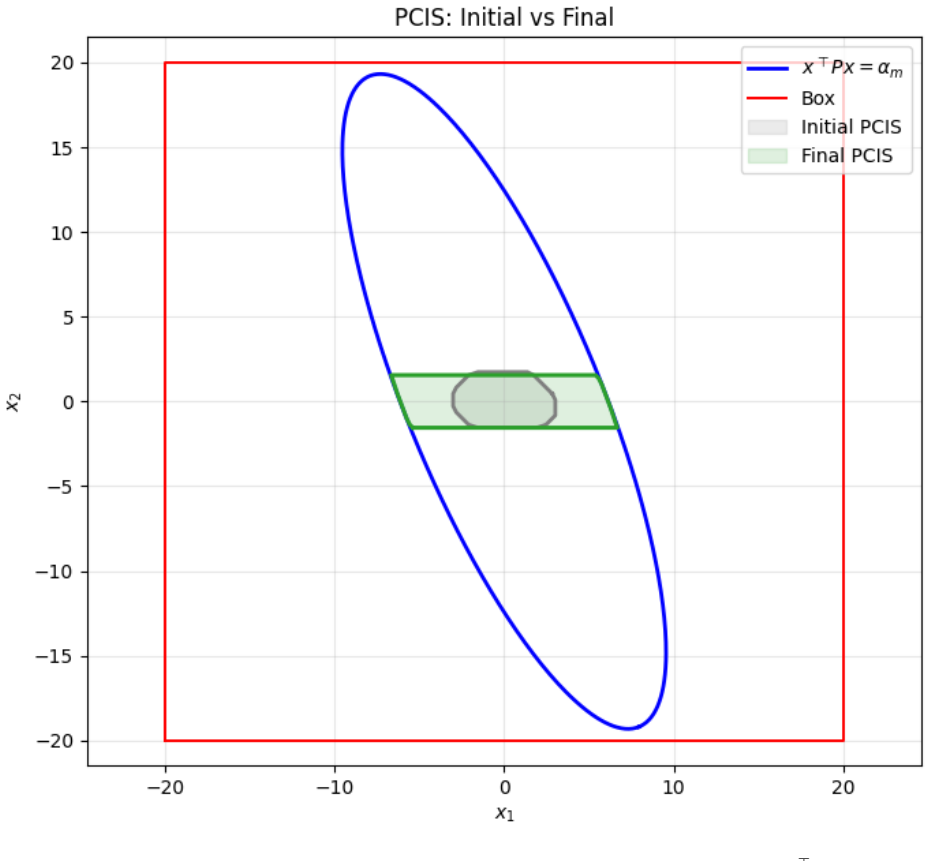
- The size of the provably safe operating region increases as the Gaussian process model accuracy improves.
- Exploration can continue indefinitely without separate safety overrides because the quadratic program always respects the current probabilistic bounds.
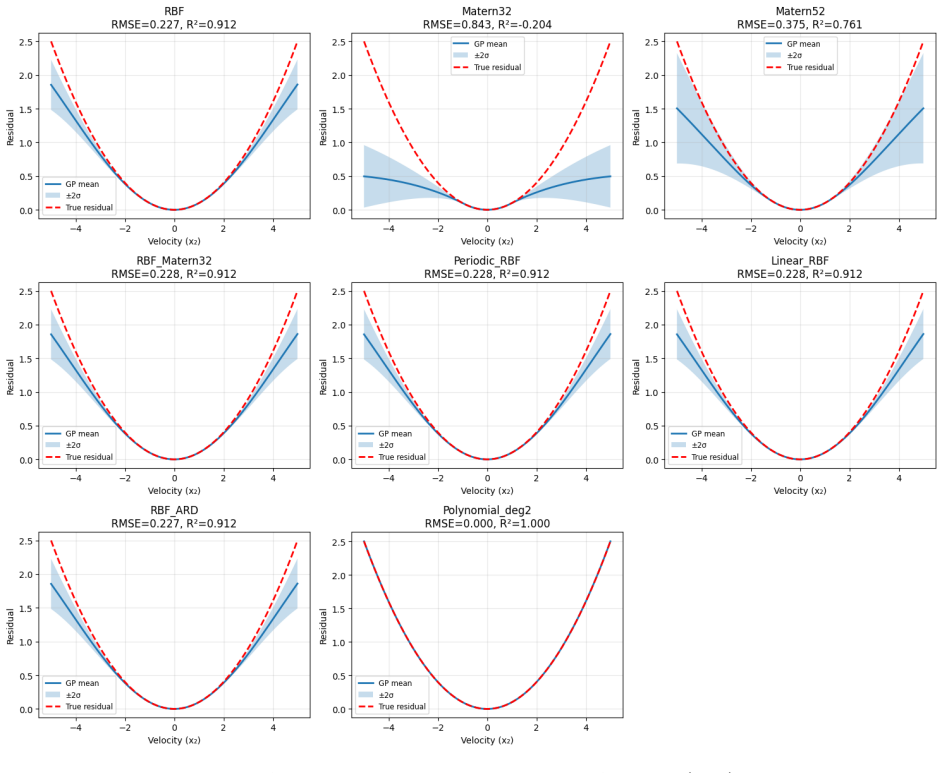
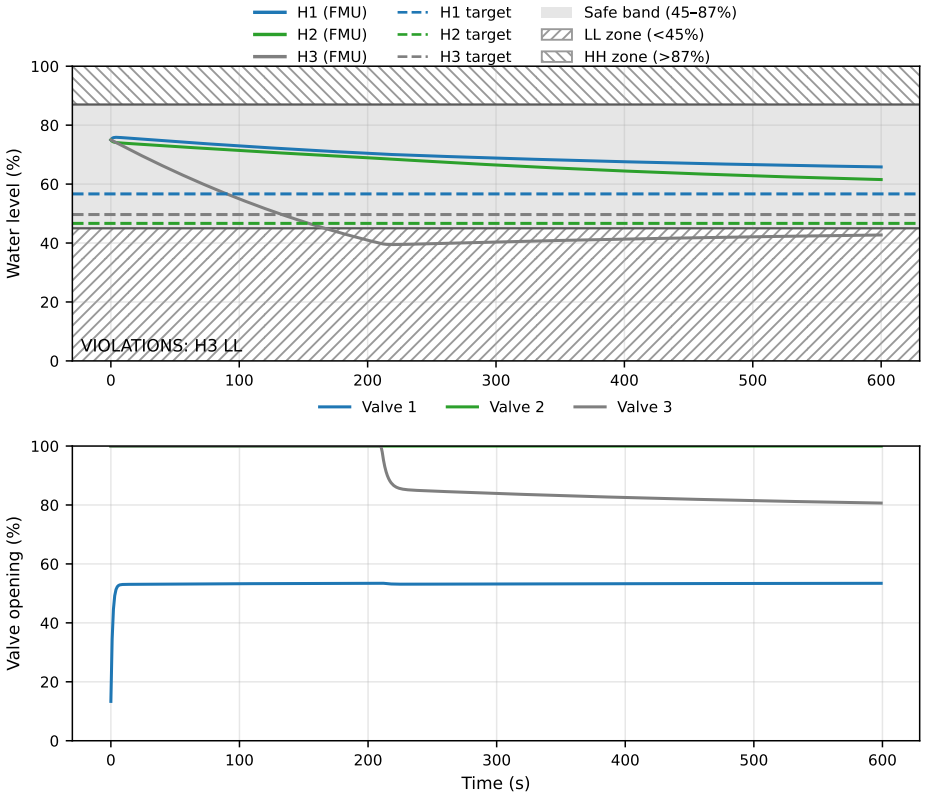
- Numerical results show the safe set growing by roughly 30 percent while model error falls from over 1 to under 0.05.
Where Pith is reading between the lines
- The same structure could be used to add safety layers to other online learning controllers that reduce uncertainty over time.
- Hardware experiments on physical plants would test whether the finite-sample bounds remain valid when disturbances and unmodeled effects are present.
- The approach separates safety certification from the particular learning algorithm, suggesting it could be combined with other data-driven methods.
Load-bearing premise
A stabilizable linear approximation of the nonlinear process is known and can be used to build the initial Lyapunov function and invariant set.
What would settle it
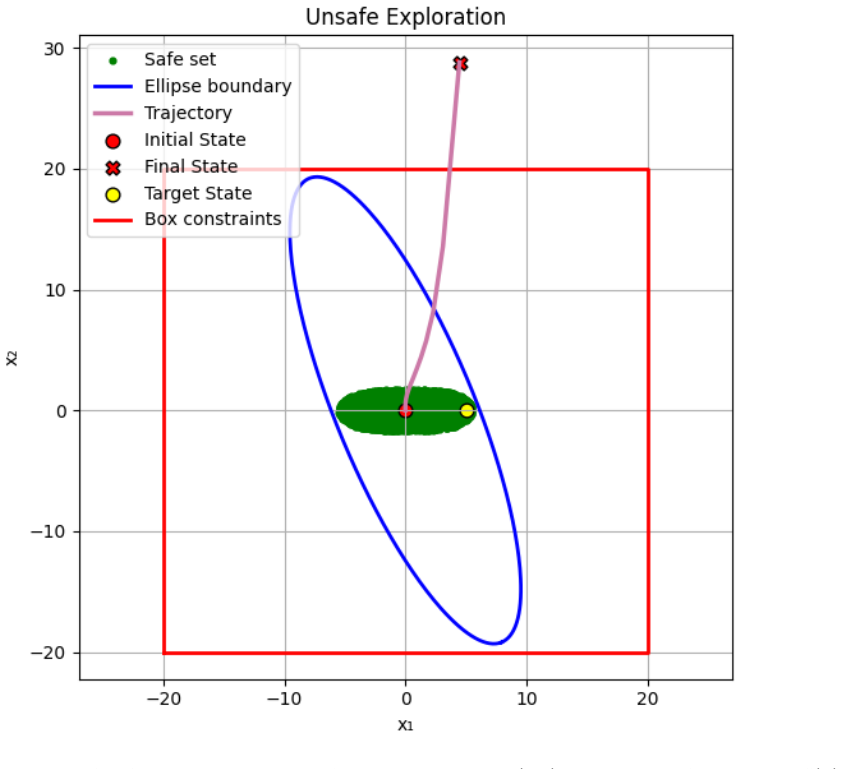
A closed-loop simulation or experiment on a nonlinear process in which the state trajectory exits the computed probabilistic invariant set more often than the claimed probability bound, or in which the safe set fails to expand despite a clear drop in Gaussian process prediction error.
Figures


read the original abstract
This paper proposes a safe data-driven control framework for nonlinear systems with partially known dynamics. The method ensures stability and constraint satisfaction during online learning, assuming only a stabilizable linear approximation of the process is available. Unmodeled nonlinear dynamics are captured by a Gaussian process residual learned in real time. Safety is enforced through a probabilistic control-invariant set derived from Lyapunov theory, guaranteeing high-probability stability. A convex quadratic program computes control inputs that maximize information gain while respecting probabilistic safety constraints. The framework provides finite-sample safety guarantees and allows adaptive expansion of the invariant set as uncertainty decreases. Numerical results validate the approach, demonstrating safe and informative exploration under model uncertainty: the safe set expands by about 30% while the Gaussian process root-mean-square error drops from 1.11 to 0.03.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This paper proposes a safe data-driven control framework for nonlinear systems with partially known dynamics. The method ensures stability and constraint satisfaction during online learning, assuming only a stabilizable linear approximation of the process is available. Unmodeled nonlinear dynamics are captured by a Gaussian process residual learned in real time. Safety is enforced through a probabilistic control-invariant set derived from Lyapunov theory, guaranteeing high-probability stability. A convex quadratic program computes control inputs that maximize information gain while respecting probabilistic safety constraints. The framework provides finite-sample safety guarantees and allows adaptive expansion of the invariant set as uncertainty decreases. Numerical results validate the approach, demonstrating safe and informative exploration under model uncertainty: the safe set expands by about 30% while the Gaussian process root-mean-square error drops from 1.11 to 0.03.
Significance. If the finite-sample guarantees hold under the adaptive data collection, the paper offers a significant advance in safe exploration for control systems by combining GP learning with probabilistic invariant sets and information-maximizing control. This could enable more efficient learning of nonlinear dynamics without risking instability. The numerical results indicate practical benefits in model accuracy and safe operating region expansion. The use of only a linear approximation as prior knowledge is a strength for applicability.
major comments (1)
- [§4 (proof of finite-sample safety guarantees)] The high-probability bound on the GP posterior used to define the probabilistic control-invariant set (invoked in the safety constraint of the QP) is based on standard GP concentration inequalities that typically require i.i.d. or fixed-design sampling. However, the sampling is performed adaptively by the QP that uses the current safety set to choose inputs maximizing information gain. This feedback loop may invalidate the direct application of the bound, and the manuscript does not appear to provide a martingale-based or sequential analysis to account for the dependence. This is load-bearing for the finite-sample guarantee claim.
minor comments (2)
- The abstract and introduction could more explicitly state the assumptions on the GP kernel and the form of the linear approximation.
- [§5] The numerical example would benefit from reporting the number of Monte Carlo runs and standard deviations for the RMSE and set expansion metrics to assess statistical significance.
Simulated Author's Rebuttal
We thank the referee for their careful reading of the manuscript and for identifying this important technical point regarding the finite-sample guarantees. We address the comment below.
read point-by-point responses
-
Referee: [§4 (proof of finite-sample safety guarantees)] The high-probability bound on the GP posterior used to define the probabilistic control-invariant set (invoked in the safety constraint of the QP) is based on standard GP concentration inequalities that typically require i.i.d. or fixed-design sampling. However, the sampling is performed adaptively by the QP that uses the current safety set to choose inputs maximizing information gain. This feedback loop may invalidate the direct application of the bound, and the manuscript does not appear to provide a martingale-based or sequential analysis to account for the dependence. This is load-bearing for the finite-sample guarantee claim.
Authors: We appreciate the referee highlighting this subtlety. The finite-sample safety argument in Section 4 applies the standard GP posterior concentration inequality (e.g., Theorem 2 of Chowdhury et al., 2017) directly to the learned residual after each update. While this inequality holds for any collection of observed points regardless of how they were selected, the adaptive feedback through the QP does introduce dependence between successive data points and the safety set itself. The current manuscript does not supply an explicit martingale or time-uniform analysis to convert the per-step conditional bound into a uniform high-probability guarantee over the entire closed-loop trajectory. We therefore agree that the claim would be strengthened by such an argument. In the revised version we will add a short lemma showing that, because the QP enforces the probabilistic control-invariant set at every step, the state remains inside a compact region with high probability; this boundedness permits a union-bound adjustment of the failure probability across a finite horizon, restoring the finite-sample guarantee. We view this as a clarification rather than a change to the core method. revision: yes
Circularity Check
No significant circularity; derivation relies on external Lyapunov and GP results
full rationale
The framework constructs a probabilistic control-invariant set from standard Lyapunov theory applied to the given stabilizable linear approximation plus a GP residual term. Finite-sample high-probability bounds are invoked from established GP concentration results (Srinivas et al. and related literature) rather than derived internally or via self-citation. The QP step maximizes information gain subject to the current invariant-set constraints; this is a standard constrained optimization and does not rename a fitted quantity as a prediction. No self-definitional loop, ansatz smuggling, or uniqueness theorem imported from the authors' prior work appears in the load-bearing steps. The adaptive expansion of the safe set follows directly from shrinking GP posterior variance and is not forced by construction from the inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Existence of a stabilizable linear approximation of the nonlinear process
invented entities (1)
-
Probabilistic control-invariant set
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Safety is enforced through a probabilistic control-invariant set derived from Lyapunov theory... A convex quadratic program computes control inputs that maximize information gain while respecting probabilistic safety constraints.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We use the finite-sample GP-UCB schedule... βt = σn √(2(γt−1 + 1 + ln(1/δt))) + B
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Felix Berkenkamp, Riccardo Moriconi, Angela P. Schoellig, and Andreas Krause. Safe learning of regions of attraction for uncertain, nonlinear systems with gaussian processes. InProceedings of the 55th IEEE Conference on Decision and Control (CDC), pages 4661–4666, 2016
work page 2016
-
[2]
Yulong Gao, Karl H. Johansson, and Lihua Xie. Computing probabilistic controlled invariant sets.IEEE Transactions on Automatic Control, 66(7):3138–3151, 2021. 16
work page 2021
-
[3]
Probabilistic invariance for gaussian process state–space models, 2023
Bastiaan Griffioen, Alex Devonport, and Murat Arcak. Probabilistic invariance for gaussian process state–space models, 2023
work page 2023
-
[4]
Wabersich, Marcel Menner, and Melanie N
Lukas Hewing, Kim P. Wabersich, Marcel Menner, and Melanie N. Zeilinger. Learning-based model predictive control: Toward safe learning in control.Annual Review of Control, Robotics, and Autonomous Systems, 3(1):269–296, 2020
work page 2020
-
[5]
Learning-based model predictive control for safe exploration
Torsten Koller, Felix Berkenkamp, Matteo Turchetta, and Andreas Krause. Learning-based model predictive control for safe exploration. In2018 IEEE Conference on Decision and Control (CDC), pages 6059–6066, 2018
work page 2018
-
[6]
Iga Pawlak, Soroush Rastegarpour, Hamid Reza Feyzmahdavian, and Alf J Isaksson. Hybrid reinforcement learning for continuous-time industrial systems with time-varying delays.2025 American Control Conference (ACC), pages 553–558, 2025
work page 2025
- [7]
- [8]
-
[9]
Carl Edward Rasmussen and Christopher K. I. Williams.Gaussian Processes for Machine Learning. MIT Press, Cambridge, MA, 2006
work page 2006
-
[10]
Soroush Rastegarpour, Hamid Reza Feyzmahdavian, and Alf J Isaksson. Enhancing reinforcement learning robustness via integrated multiple-model adaptive control.IF AC-PapersOnLine, 58(14):360–366, 2024
work page 2024
-
[11]
Soroush Rastegarpour, Hamid Reza Feyzmahdavian, and Alf J Isaksson. Adaptive ensemble reinforcement learning for industrial process control.Journal of Process Control, 156:103575, 2025
work page 2025
-
[12]
Niranjan Srinivas, Andreas Krause, Sham M. Kakade, and Matthias Seeger. Gaussian process optimization in the bandit setting: No regret and experimental design. InProceedings of the 27th International Conference on Machine Learning (ICML), 2010
work page 2010
-
[13]
Jiayue Wang, Hamid Reza Feyzmahdavian, Soroush Rastegarpour, and Alf J Isaksson. Robust tube-based reinforcement learning control for systems with parametric uncertainty.European Journal of Control, page 101326, 2025
work page 2025
-
[14]
Theodorou, and Magnus Egerstedt
Li Wang, Evangelos A. Theodorou, and Magnus Egerstedt. Safe learning of quadrotor dynamics using barrier certificates. InIEEE International Conference on Robotics and Automation (ICRA), pages 2460–2465, 2018. 17 Figure 4: PCIS expansion in the 2D case. The blue ellipse shows the Lyapunov level set x⊤P x = αm; the red rectangle is the state box constraints...
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.