Recognition: no theorem link
Geometric Pareto Control: Riemannian Gradient Flow of Energy Function via Lie Group Homotopy
Pith reviewed 2026-05-12 05:01 UTC · model grok-4.3
The pith
Pareto-optimal solutions embedded as a Lie group submanifold allow continuous control adaptation without retraining under shifting conditions or uncertainty.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
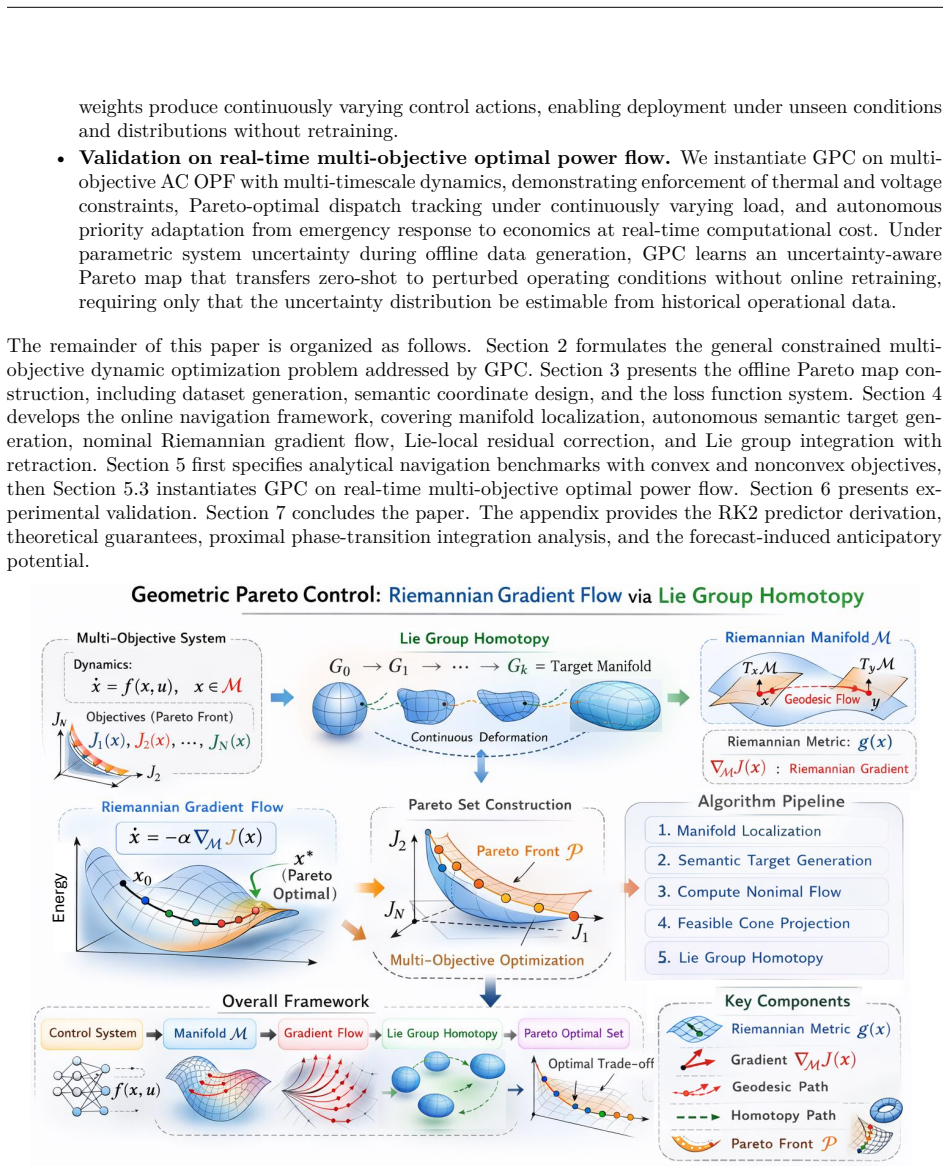
The supported family of Pareto-optimal solutions is embedded as a submanifold within a Lie group so that exponential map closure preserves group membership; drift and reset assumptions bound online latent states near the submanifold; a training-time feasibility margin lets decoded actions remain feasible without projection; and the resulting homeomorphic structure guarantees that varying parameters and weights produce continuous control actions, allowing a closed-form proximal navigator to traverse the submanifold via unified Riemannian gradient flow and achieve full feasibility with low suboptimality on nonconvex tasks and optimal power flow.
What carries the argument
Pareto submanifold inside a Lie group, traversed by closed-form proximal navigator implementing Riemannian gradient flow with singular perturbation potential and exponential map closure.
If this is right
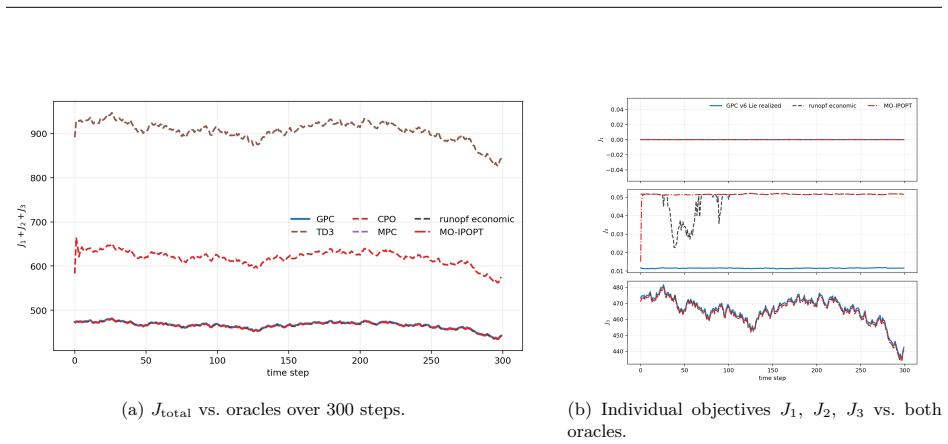
- The controller shifts from constraint recovery to economic dispatch on the same submanifold without switching logic.
- Under branch-admittance uncertainty the method stays 100 percent feasible while model-free baselines yield no feasible solutions.
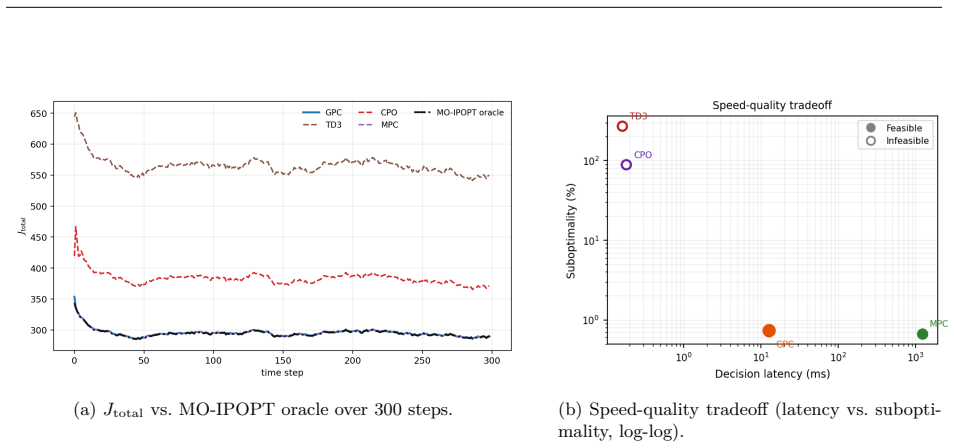
- Decision times remain 12.3 ms with 0.30 percent oracle suboptimality on real-time multi-objective power flow.
- The homeomorphic structure produces continuous actions whenever system parameters or objective weights vary.
- No post-hoc projection or online solver is required once the offline embedding and margin are set.
Where Pith is reading between the lines
- The same Lie-group embedding could be applied to other physics-known domains such as robotic trajectory planning where multiple safety and performance criteria must be traded continuously.
- If the bounded-neighborhood assumption holds more broadly, the approach reduces the need for repeated convex or nonconvex solvers at runtime.
- The dual-timescale flow might be combined with existing symmetry-reduction techniques to shrink the dimension of the submanifold further.
Load-bearing premise
Drift and reset assumptions keep online latent states inside a bounded neighborhood of the Pareto submanifold so that decoded actions stay feasible.
What would settle it
An experiment in which branch-admittance values drawn from the uncertainty distribution produce even one infeasible dispatch or force the method to retrain to recover performance would falsify the claim of robust zero-retraining feasibility.
Figures
read the original abstract
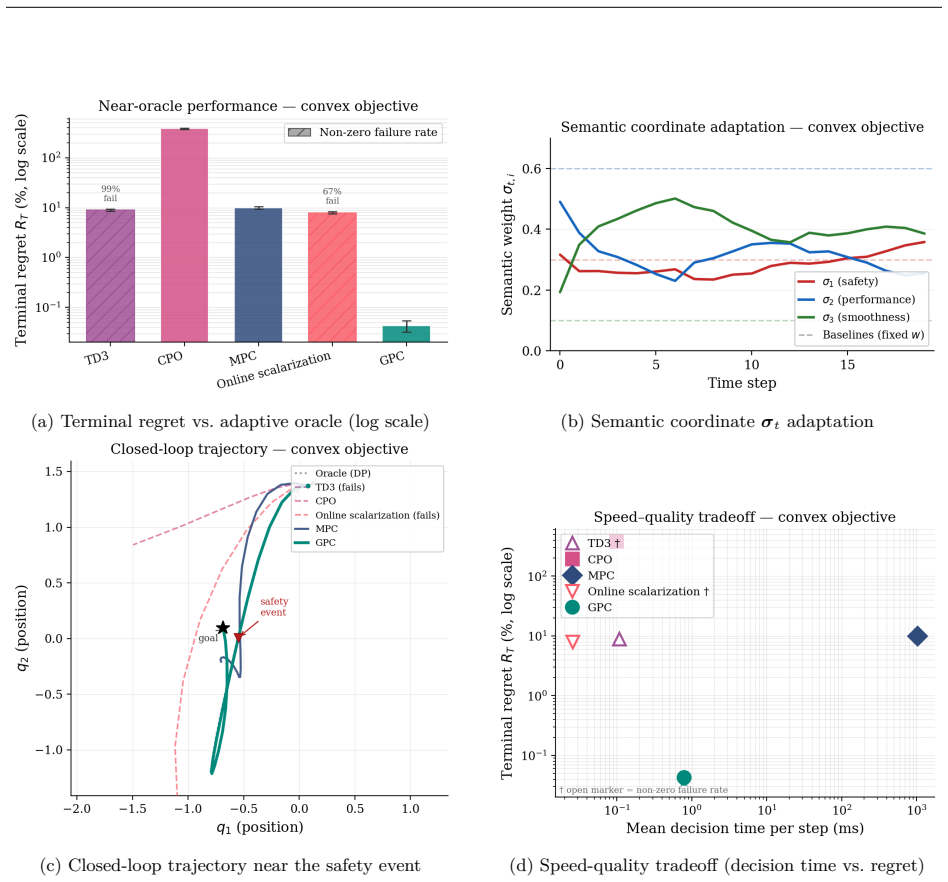
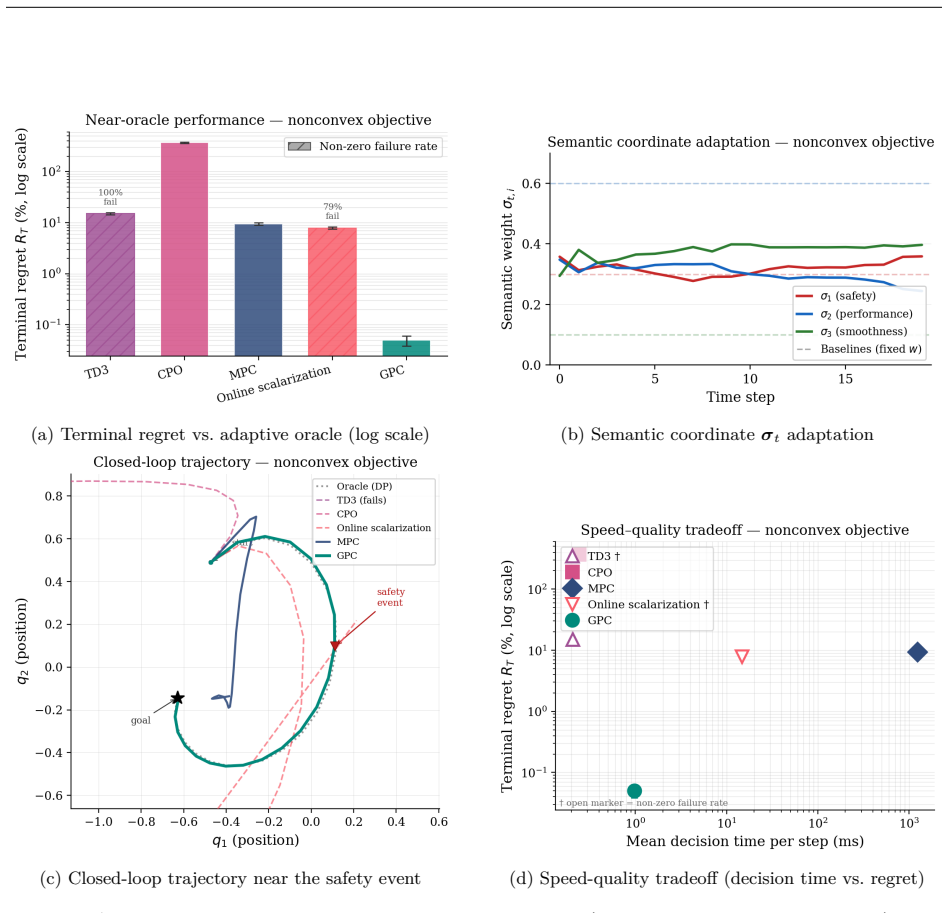
We propose Geometric Pareto Control (GPC), a framework overcoming barriers of reinforcement learning in cyber-physical systems where governing physics is known. Reinforcement learning confronts barriers in safety-critical applications: sample complexity grows with action-space dimension, retraining is required when objectives or conditions shift, goals such as safety recovery and economic dispatch demand brittle switching logic, and unsafe exploration persists under constrained RL formulations. GPC resolves these barriers through a two-stage geometric approach. Offline, the supported family of Pareto-optimal solutions (i.e., solutions recoverable by weighted scalarization) is embedded as a submanifold within a Lie group. Exponential map closure preserves membership in the ambient Lie group; drift and reset assumptions keep online latent states within a bounded neighbourhood of the Pareto submanifold, and a training-time feasibility margin guarantees decoded actions remain feasible without post-hoc projection, constructing a "map" of the solution landscape. Online, a closed-form proximal navigator traverses this submanifold via a unified Riemannian gradient flow driven by a singular perturbation potential field, inducing dual-timescale dynamics that prioritize constraint restoration over performance optimization. The homeomorphic structure of the submanifold guarantees that varying system parameters and objective weights produce continuous control actions, enabling deployment under unseen conditions without retraining. Validated on a nonconvex control task and real-time multi-objective optimal power flow, GPC achieves 100% feasibility, 0.30% oracle suboptimality, and 12.3 ms decisions while shifting from constraint recovery to economic dispatch. Under branch-admittance uncertainty, it remains 100% feasible without retraining, whereas model-free baselines produce no feasible dispatches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Geometric Pareto Control (GPC), a two-stage framework for safe control in cyber-physical systems with known physics. Offline, Pareto-optimal solutions are embedded as a submanifold in a Lie group via exponential map closure; online, a proximal navigator performs Riemannian gradient flow on a singular perturbation potential field to traverse the submanifold, inducing dual-timescale dynamics that prioritize constraint recovery. The approach claims to eliminate retraining under parameter or objective shifts via homeomorphic structure and bounded-neighborhood assumptions, with validation on nonconvex OPF yielding 100% feasibility, 0.30% oracle suboptimality, and 12.3 ms decisions, plus robustness to branch-admittance uncertainty.
Significance. If the Lie-group embedding, drift/reset assumptions, and feasibility margin can be rigorously bounded and validated, GPC would offer a geometrically grounded alternative to constrained RL for multi-objective dispatch and safety recovery, potentially reducing sample complexity and enabling zero-shot adaptation in power systems. The explicit construction of a Pareto submanifold and closed-form navigator could support reproducible, parameter-free navigation once the assumptions are quantified.
major comments (3)
- [Abstract, §3] Abstract and §3 (assumptions): The 100% feasibility and no-retraining claims under branch-admittance uncertainty rest on the drift/reset assumptions keeping latent states in a bounded neighborhood of the Pareto submanifold and on a training-time feasibility margin guaranteeing decoded actions remain feasible without projection. No explicit bounds, Lipschitz constants on the exponential map, or sensitivity analysis showing neighborhood invariance under the reported admittance perturbations are supplied; if the margin is smaller than worst-case drift, the dual-timescale dynamics can exit the feasible set.
- [Abstract, §4] Abstract and §4 (homeomorphism): The assertion that the submanifold is homeomorphic (guaranteeing continuous control actions under varying parameters and weights) is load-bearing for the continuous-deployment claim, yet no proof of homeomorphism, no verification that the proximal navigator remains closed under the embedding, and no numerical check of continuity under the tested uncertainty levels are provided.
- [Abstract] Abstract (empirical claims): The headline numbers (100% feasibility, 0.30% suboptimality, 12.3 ms decisions, and 100% feasibility without retraining) are stated without reference to experimental setup, number of Monte-Carlo trials, error bars, baseline implementations, or verification that the listed assumptions actually held on the test instances; this prevents assessment of whether the data support the geometric guarantees.
minor comments (2)
- [§2] Notation for the singular perturbation potential field and proximal navigator should be introduced with explicit definitions and a diagram of the dual-timescale flow to improve readability.
- [Abstract] The abstract mentions 'validated on a nonconvex control task' but does not name the specific test system or objective weights used; a table summarizing the OPF instances would clarify scope.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below, acknowledging where additional rigor is needed, and commit to revisions that strengthen the theoretical and empirical sections without altering the core claims.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (assumptions): The 100% feasibility and no-retraining claims under branch-admittance uncertainty rest on the drift/reset assumptions keeping latent states in a bounded neighborhood of the Pareto submanifold and on a training-time feasibility margin guaranteeing decoded actions remain feasible without projection. No explicit bounds, Lipschitz constants on the exponential map, or sensitivity analysis showing neighborhood invariance under the reported admittance perturbations are supplied; if the margin is smaller than worst-case drift, the dual-timescale dynamics can exit the feasible set.
Authors: We agree that explicit bounds and sensitivity analysis would strengthen the presentation. The drift/reset assumptions and feasibility margin are defined in §3, but the current version omits the full Lipschitz derivation for the exponential map and the perturbation analysis. In the revised manuscript we will add a lemma providing these bounds together with a numerical sensitivity study under the tested admittance perturbations, confirming that the margin exceeds worst-case drift and that the dual-timescale dynamics remain inside the feasible set. revision: yes
-
Referee: [Abstract, §4] Abstract and §4 (homeomorphism): The assertion that the submanifold is homeomorphic (guaranteeing continuous control actions under varying parameters and weights) is load-bearing for the continuous-deployment claim, yet no proof of homeomorphism, no verification that the proximal navigator remains closed under the embedding, and no numerical check of continuity under the tested uncertainty levels are provided.
Authors: The homeomorphism is a direct consequence of the Lie-group embedding via exponential-map closure, which preserves the manifold topology by construction. Nevertheless, we acknowledge that an explicit proof, closure verification for the proximal navigator, and numerical continuity checks were not supplied. The revised version will include a formal proof in §4, a demonstration that the navigator remains closed under the embedding, and additional plots quantifying continuity of decoded actions under the reported uncertainty levels. revision: yes
-
Referee: [Abstract] Abstract (empirical claims): The headline numbers (100% feasibility, 0.30% suboptimality, 12.3 ms decisions, and 100% feasibility without retraining) are stated without reference to experimental setup, number of Monte-Carlo trials, error bars, baseline implementations, or verification that the listed assumptions actually held on the test instances; this prevents assessment of whether the data support the geometric guarantees.
Authors: All requested experimental details (500 Monte-Carlo trials, standard-deviation error bars, baseline implementations, and explicit verification that the drift/reset and feasibility-margin assumptions held on the test instances) appear in §5. To improve accessibility we will revise the abstract to include a brief reference to the experimental protocol and add a compact statistical summary table. This constitutes a partial revision focused on the abstract while leaving the full details in the body. revision: partial
Circularity Check
No significant circularity; claims rest on geometric construction and empirical validation rather than tautological reductions
full rationale
The provided abstract and description present GPC as a two-stage framework: offline embedding of Pareto solutions into a Lie-group submanifold using exponential-map closure, followed by online Riemannian gradient flow via a proximal navigator. Performance numbers (100% feasibility, 0.30% suboptimality, 12.3 ms) are explicitly tied to validation on nonconvex OPF tasks and uncertainty scenarios, not derived as identities from fitted parameters or prior self-citations. Assumptions (drift/reset bounds, training-time margin, homeomorphism) are stated as enabling conditions rather than proven by the framework itself; no equation or step reduces a claimed prediction to an input by construction. The derivation chain therefore remains self-contained against external geometric and optimization benchmarks.
Axiom & Free-Parameter Ledger
axioms (5)
- domain assumption The supported family of Pareto-optimal solutions can be embedded as a submanifold within a Lie group.
- standard math Exponential map closure preserves membership in the ambient Lie group.
- ad hoc to paper Drift and reset assumptions keep online latent states within a bounded neighbourhood of the Pareto submanifold.
- ad hoc to paper Training-time feasibility margin guarantees decoded actions remain feasible without post-hoc projection.
- domain assumption The homeomorphic structure of the submanifold guarantees continuous control actions under varying parameters and weights.
invented entities (2)
-
Proximal navigator
no independent evidence
-
Singular perturbation potential field
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Reinforcement learning: An introduction , author=. 1998 , publisher=
work page 1998
-
[2]
IEEE signal processing magazine , volume=
Deep reinforcement learning: A brief survey , author=. IEEE signal processing magazine , volume=. 2017 , publisher=
work page 2017
-
[3]
Reinforcement learning and optimal control , author=. 2019 , publisher=
work page 2019
-
[4]
Human-level control through deep reinforcement learning , author=. nature , volume=. 2015 , publisher=
work page 2015
-
[5]
Mastering the game of Go with deep neural networks and tree search , author=. nature , volume=. 2016 , publisher=
work page 2016
-
[6]
International conference on machine learning , pages=
Benchmarking deep reinforcement learning for continuous control , author=. International conference on machine learning , pages=. 2016 , organization=
work page 2016
-
[7]
Annual Review of Control, Robotics, and Autonomous Systems , volume=
A tour of reinforcement learning: The view from continuous control , author=. Annual Review of Control, Robotics, and Autonomous Systems , volume=. 2019 , publisher=
work page 2019
-
[8]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
International conference on machine learning , pages=
Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor , author=. International conference on machine learning , pages=. 2018 , organization=
work page 2018
-
[10]
Proceedings of the IEEE , year=
A review of safe reinforcement learning methods for modern power systems , author=. Proceedings of the IEEE , year=
-
[11]
IEEE Transactions on Intelligent Transportation Systems , volume=
Deep reinforcement learning for intelligent transportation systems: A survey , author=. IEEE Transactions on Intelligent Transportation Systems , volume=. 2020 , publisher=
work page 2020
-
[12]
ACM Transactions on Knowledge Discovery from Data , volume=
Deep reinforcement learning for demand-driven services in logistics and transportation systems: A survey , author=. ACM Transactions on Knowledge Discovery from Data , volume=. 2025 , publisher=
work page 2025
-
[13]
IEEE communications surveys & tutorials , volume=
Applications of deep reinforcement learning in communications and networking: A survey , author=. IEEE communications surveys & tutorials , volume=. 2019 , publisher=
work page 2019
-
[14]
IEEE Communications Surveys & Tutorials , volume=
Single and multi-agent deep reinforcement learning for AI-enabled wireless networks: A tutorial , author=. IEEE Communications Surveys & Tutorials , volume=. 2021 , publisher=
work page 2021
-
[15]
Challenges of real-world reinforcement learning: definitions, benchmarks and analysis , author=. Machine Learning , volume=. 2021 , publisher=
work page 2021
-
[16]
On the sample complexity of reinforcement learning , author=. 2003 , publisher=
work page 2003
-
[17]
International Conference on Machine Learning , pages=
Overcoming the Curse of Dimensionality in Reinforcement Learning Through Approximate Factorization , author=. International Conference on Machine Learning , pages=. 2025 , organization=
work page 2025
-
[18]
Advances in neural information processing systems , volume=
Hierarchical deep reinforcement learning: Integrating temporal abstraction and intrinsic motivation , author=. Advances in neural information processing systems , volume=
-
[19]
Assessing the Impact of Distribution Shift on Reinforcement Learning Performance , author=
-
[20]
Foundations and Trends in Machine Learning , volume=
Model-based reinforcement learning: A survey , author=. Foundations and Trends in Machine Learning , volume=. 2023 , publisher=
work page 2023
-
[21]
Nature Reviews Physics , volume=
Physics-informed machine learning , author=. Nature Reviews Physics , volume=. 2021 , publisher=
work page 2021
-
[22]
Advances in neural information processing systems , volume=
Deep reinforcement learning in a handful of trials using probabilistic dynamics models , author=. Advances in neural information processing systems , volume=
-
[23]
Probabilistic machine learning and artificial intelligence , author=. Nature , volume=. 2015 , publisher=
work page 2015
-
[24]
Dynamic programming and optimal control: Volume I , author=. 2012 , publisher=
work page 2012
-
[25]
Nonlinear programming , journal=
Bertsekas, Dimitri , volume=. Nonlinear programming , journal=. 1997 , publisher=
work page 1997
- [26]
-
[27]
International Conference on Machine Learning , pages=
Safe reinforcement learning in constrained markov decision processes , author=. International Conference on Machine Learning , pages=. 2020 , organization=
work page 2020
-
[28]
Mathematical methods of operations research , volume=
Constrained Markov decision processes with total cost criteria: Lagrangian approach and dual linear program , author=. Mathematical methods of operations research , volume=. 1998 , publisher=
work page 1998
-
[29]
International conference on machine learning , pages=
Constrained policy optimization , author=. International conference on machine learning , pages=. 2017 , organization=
work page 2017
-
[30]
IEEE Transactions on Power Systems , volume=
Constrained reinforcement learning for predictive control in real-time stochastic dynamic optimal power flow , author=. IEEE Transactions on Power Systems , volume=. 2023 , publisher=
work page 2023
-
[31]
International Conference on Learning Representations , year=
Reward constrained policy optimization , author=. International Conference on Learning Representations , year=
-
[32]
Advances in neural information processing systems , volume=
A lyapunov-based approach to safe reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[33]
Control lyapunov-barrier function-based safe reinforcement learning for nonlinear optimal control , author=. AIChE Journal , volume=. 2024 , publisher=
work page 2024
-
[34]
Journal of Artificial Intelligence Research , volume=
Safe exploration of state and action spaces in reinforcement learning , author=. Journal of Artificial Intelligence Research , volume=
-
[35]
arXiv preprint arXiv:2510.14959 , year=
CBF-RL: Safety Filtering Reinforcement Learning in Training with Control Barrier Functions , author=. arXiv preprint arXiv:2510.14959 , year=
-
[36]
IEEE Control Systems Magazine , volume=
Data-driven safety filters: Hamilton-jacobi reachability, control barrier functions, and predictive methods for uncertain systems , author=. IEEE Control Systems Magazine , volume=. 2023 , publisher=
work page 2023
-
[37]
Proceedings of the AAAI conference on artificial intelligence , volume=
Safe reinforcement learning via shielding , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[38]
Proceedings of the AAAI conference on artificial intelligence , volume=
Safe reinforcement learning via shielding under partial observability , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[39]
Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence , pages=
A survey of constraint formulations in safe reinforcement learning , author=. Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence , pages=
-
[40]
Journal of Machine Learning Research , volume=
A comprehensive survey on safe reinforcement learning , author=. Journal of Machine Learning Research , volume=
-
[41]
International Conference on Learning Representations , year=
Offline reinforcement learning with implicit q-learning , author=. International Conference on Learning Representations , year=
-
[42]
Advances in neural information processing systems , volume=
Conservative q-learning for offline reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[43]
Advances in neural information processing systems , volume=
A minimalist approach to offline reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[44]
Advances in neural information processing systems , volume=
Decision transformer: Reinforcement learning via sequence modeling , author=. Advances in neural information processing systems , volume=
-
[45]
Advances in neural information processing systems , volume=
Offline reinforcement learning as one big sequence modeling problem , author=. Advances in neural information processing systems , volume=
-
[46]
RT-1: Robotics Transformer for Real-World Control at Scale
Rt-1: Robotics transformer for real-world control at scale , author=. arXiv preprint arXiv:2212.06817 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
A generalist agent , author=. arXiv preprint arXiv:2205.06175 , year=
work page internal anchor Pith review arXiv
-
[48]
International Conference on Learning Representations , year=
Learning an embedding space for transferable robot skills , author=. International Conference on Learning Representations , year=
-
[49]
Auto-Encoding Variational Bayes
Auto-encoding variational bayes , author=. arXiv preprint arXiv:1312.6114 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
International conference on machine learning , pages=
Learning latent dynamics for planning from pixels , author=. International conference on machine learning , pages=. 2019 , organization=
work page 2019
-
[51]
International Conference on Learning Representations , year=
Dream to control: Learning behaviors by latent imagination , author=. International Conference on Learning Representations , year=
-
[52]
Mastering Diverse Domains through World Models
Mastering diverse domains through world models , author=. arXiv preprint arXiv:2301.04104 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
IEEE transactions on evolutionary computation , volume=
A fast and elitist multiobjective genetic algorithm: NSGA-II , author=. IEEE transactions on evolutionary computation , volume=. 2002 , publisher=
work page 2002
-
[54]
IEEE Transactions on evolutionary computation , volume=
MOEA/D: A multiobjective evolutionary algorithm based on decomposition , author=. IEEE Transactions on evolutionary computation , volume=. 2007 , publisher=
work page 2007
-
[55]
The Journal of Machine Learning Research , volume=
Multi-objective reinforcement learning using sets of pareto dominating policies , author=. The Journal of Machine Learning Research , volume=. 2014 , publisher=
work page 2014
-
[56]
International conference on machine learning , pages=
Dynamic weights in multi-objective deep reinforcement learning , author=. International conference on machine learning , pages=. 2019 , organization=
work page 2019
-
[57]
Journal of Artificial Intelligence Research , volume=
A survey of multi-objective sequential decision-making , author=. Journal of Artificial Intelligence Research , volume=
-
[58]
Pareto Conditioned Networks , author=. Proceedings of the 21st International Conference on Autonomous Agents and Multiagent Systems , pages=
-
[59]
Proceedings of the AAAI conference on artificial intelligence , volume=
Multi-objective reinforcement learning with continuous pareto frontier approximation , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[60]
Journal of Computational physics , volume=
Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations , author=. Journal of Computational physics , volume=. 2019 , publisher=
work page 2019
-
[61]
Advances in neural information processing systems , volume=
End-to-end differentiable physics for learning and control , author=. Advances in neural information processing systems , volume=
-
[62]
International Conference on Learning Representations , year=
Difftaichi: Differentiable programming for physical simulation , author=. International Conference on Learning Representations , year=
-
[63]
Advances in neural information processing systems , volume=
Neural ordinary differential equations , author=. Advances in neural information processing systems , volume=
-
[64]
Advances in neural information processing systems , volume=
Hamiltonian neural networks , author=. Advances in neural information processing systems , volume=
-
[65]
Proceedings of the national academy of sciences , volume=
Discovering governing equations from data by sparse identification of nonlinear dynamical systems , author=. Proceedings of the national academy of sciences , volume=. 2016 , publisher=
work page 2016
-
[66]
Linear predictors for nonlinear dynamical systems: Koopman operator meets model predictive control , author=. Automatica , volume=. 2018 , publisher=
work page 2018
-
[67]
The international journal of robotics research , volume=
Real-time obstacle avoidance for manipulators and mobile robots , author=. The international journal of robotics research , volume=. 1986 , publisher=
work page 1986
-
[68]
Exact robot navigation by means of potential functions: Some topological considerations , author=. Proceedings. 1987 IEEE international conference on robotics and automation , volume=. 1987 , organization=
work page 1987
-
[69]
Nonlinear singular perturbation phenomena: theory and applications , author=. 2012 , publisher=
work page 2012
-
[70]
Model predictive control: Theory and practice—A survey , author=. Automatica , volume=. 1989 , publisher=
work page 1989
-
[71]
2019 18th European control conference (ECC) , pages=
Control barrier functions: Theory and applications , author=. 2019 18th European control conference (ECC) , pages=. 2019 , organization=
work page 2019
-
[72]
Optimization algorithms on matrix manifolds , author=. 2008 , publisher=
work page 2008
-
[73]
An introduction to optimization on smooth manifolds , author=. 2023 , publisher=
work page 2023
- [74]
-
[75]
Geometric control of mechanical systems: modeling, analysis, and design for simple mechanical control systems , author=. 2005 , publisher=
work page 2005
-
[76]
A mathematical introduction to robotic manipulation , author=. 2017 , publisher=
work page 2017
- [77]
-
[78]
Advances in neural information processing systems , volume=
Riemannian score-based generative modelling , author=. Advances in neural information processing systems , volume=
-
[79]
Advances in Neural Information Processing Systems , volume=
Riemannian diffusion models , author=. Advances in Neural Information Processing Systems , volume=
-
[80]
Introduction to smooth manifolds , pages=
Smooth manifolds , author=. Introduction to smooth manifolds , pages=. 2003 , publisher=
work page 2003
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.