Recognition: 2 theorem links
· Lean TheoremHyperbolic Distillation: Geometry-Guided Cross-Modal Transfer for Robust 3D Object Detection
Pith reviewed 2026-05-12 04:21 UTC · model grok-4.3
The pith
Hyperbolic geometry reduces semantic loss when fusing image and point cloud features for 3D object detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
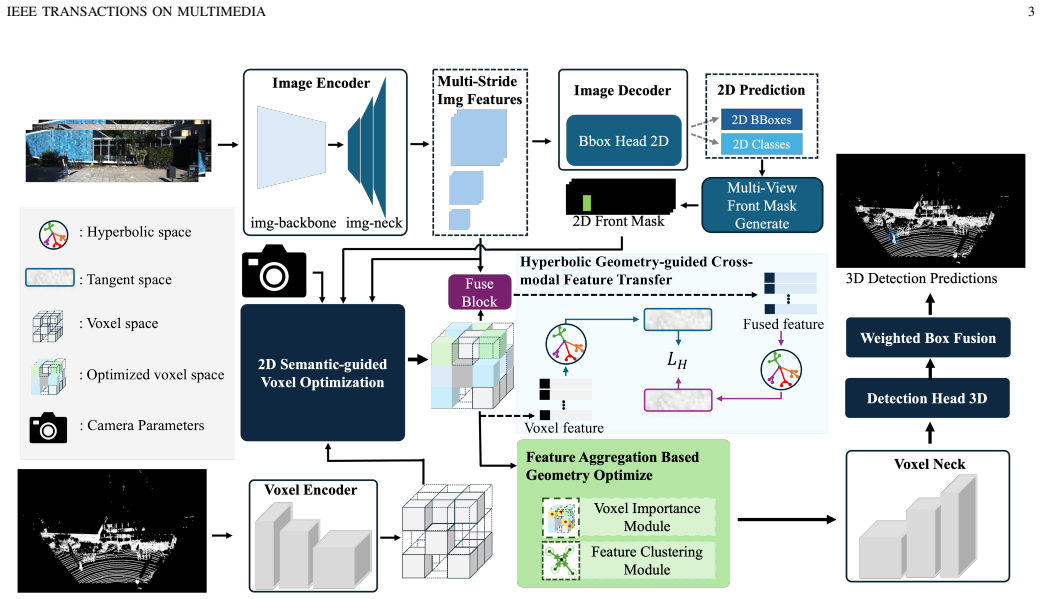
The authors claim that hyperbolic geometry constrained cross-modal feature transfer (HFT) alleviates semantic loss during the fusion of image and point cloud data. Combined with 2D semantic-guided voxel optimization and feature aggregation-based geometry optimization, the resulting HGC-Det framework produces more accurate 3D detections than existing cross-modal distillation techniques while maintaining a favorable accuracy-compute trade-off.
What carries the argument
The hyperbolic geometry constrained cross-modal feature transfer (HFT) component, which embeds image and point cloud features in hyperbolic space to exploit its exponential volume growth for hierarchical semantic preservation.
If this is right
- Image semantics can adaptively improve the spatial representation quality of the point cloud branch.
- Hyperbolic embedding limits information loss when combining features of mismatched dimensionality.
- Post-fusion geometry correction can offset any spatial degradation from 2D-guided voxel refinement.
- The overall pipeline achieves higher detection accuracy at lower computational cost on SUN RGB-D, ARKitScenes, KITTI, and nuScenes.
Where Pith is reading between the lines
- The same hyperbolic transfer idea could be tested on other multimodal perception tasks such as instance segmentation or tracking.
- Adjusting the curvature of the hyperbolic space might further tune performance for indoor versus outdoor scene statistics.
- The approach suggests non-Euclidean embeddings may help fusion problems in additional high-to-low dimensional sensor pairings.
Load-bearing premise
Mapping high-dimensional image features and low-dimensional point cloud features into hyperbolic space will reliably reduce semantic loss during fusion without introducing new distortions or alignment errors that cancel the gains.
What would settle it
Direct comparison on KITTI or nuScenes showing that HGC-Det yields no measurable gain in mean average precision or requires higher compute than standard Euclidean distillation baselines would falsify the central claim.
Figures



read the original abstract
Cross-modal knowledge distillation has emerged as an effective strategy for integrating point cloud and image features in 3D perception tasks. However, the modality heterogeneity, spatial misalignment, and the representation crisis of multiple modalities often limit the efficient of these cross-modal distillation methods. To address these limitations in existing approaches, we propose a hyperbolic constrained cross-modal distillation method for multimodal 3D object detection (HGC-Det). The proposed HGC-Det framework includes an image branch and a point cloud branch to extract semantic features from two different modalities. The point cloud branch comprises three core components: a 2D semantic-guided voxel optimization component (SGVO), a hyperbolic geometry constrained cross-modal feature transfer component (HFT), and a feature aggregation-based geometry optimization component (FAGO). Specifically, the SGVO component adaptively refines the spatial representation of the 3D branch by leveraging semantic cues from the image branch, thereby mitigating the issue of inadequate representation fusion. The HFT component exploits the intrinsic geometric properties of hyperbolic space to alleviate semantic loss during the fusion of high-dimensional image features and low-dimensional point cloud features. Finally, the FAGO compensates for potential spatial feature degradation introduced by the 2D semantic-guided voxel optimization component. Extensive experiments on indoor datasets (SUN RGB-D, ARKitScenes) and outdoor datasets (KITTI, nuScenes) demonstrate that our method achieves a better trade-off between detection accuracy and computational cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes HGC-Det, a cross-modal distillation framework for multimodal 3D object detection that integrates an image branch with a point-cloud branch containing three modules: 2D semantic-guided voxel optimization (SGVO), hyperbolic geometry constrained cross-modal feature transfer (HFT), and feature aggregation-based geometry optimization (FAGO). SGVO uses image semantics to refine voxel representations, HFT maps high-dimensional image features into hyperbolic space to reduce semantic loss when fusing with low-dimensional point-cloud features, and FAGO compensates for spatial degradation. Experiments on SUN RGB-D, ARKitScenes, KITTI, and nuScenes are reported to yield a superior accuracy versus computational cost trade-off.
Significance. If the hyperbolic transfer in HFT can be shown to preserve the geometric cues needed for 3D bounding-box regression without introducing unquantified distortions, the approach would provide a geometrically motivated solution to modality heterogeneity and representation crisis in cross-modal 3D detection. This could improve efficiency in both indoor and outdoor settings. The current description, however, supplies no ablations, curvature schedules, or error analysis that would allow assessment of whether the claimed gains are attributable to the hyperbolic constraint rather than the 2D guidance or aggregation steps.
major comments (1)
- [Abstract] Abstract: The central claim that HFT 'exploits the intrinsic geometric properties of hyperbolic space to alleviate semantic loss during the fusion of high-dimensional image features and low-dimensional point cloud features' is load-bearing for the accuracy-cost trade-off reported on KITTI and nuScenes, yet the abstract (and the provided manuscript description) contains no derivation of the embedding, no value or schedule for curvature, no exponential-map formulation, and no ablation that isolates HFT from SGVO and FAGO. Without these elements it is impossible to verify that curvature-induced misalignment or distortion does not offset the reported gains.
minor comments (1)
- [Abstract] Abstract: The phrase 'limit the efficient of these cross-modal distillation methods' is grammatically incorrect and should read 'limit the efficiency of these cross-modal distillation methods.'
Simulated Author's Rebuttal
We thank the referee for the careful review and for identifying areas where the presentation of the HFT component can be strengthened. We address the major comment below and will revise the manuscript to incorporate the requested clarifications and additional experiments.
read point-by-point responses
-
Referee: The central claim that HFT 'exploits the intrinsic geometric properties of hyperbolic space to alleviate semantic loss during the fusion of high-dimensional image features and low-dimensional point cloud features' is load-bearing for the accuracy-cost trade-off reported on KITTI and nuScenes, yet the abstract (and the provided manuscript description) contains no derivation of the embedding, no value or schedule for curvature, no exponential-map formulation, and no ablation that isolates HFT from SGVO and FAGO. Without these elements it is impossible to verify that curvature-induced misalignment or distortion does not offset the reported gains.
Authors: We agree that the abstract is concise and omits key technical details of the HFT module, making it difficult to fully assess the source of the reported gains. In the revised manuscript we will expand the abstract to briefly state that HFT employs the exponential map to embed image features into hyperbolic space with a fixed curvature of -1 (standard for such feature hierarchies) and that this mapping is used to mitigate dimension-induced semantic loss. We will also insert a short derivation of the embedding and the hyperbolic distance formulation into the methods section. To isolate the contribution of the hyperbolic constraint, we will add a dedicated ablation that replaces HFT with Euclidean feature concatenation while keeping SGVO and FAGO unchanged; the resulting performance drop on KITTI and nuScenes will be reported to quantify the benefit attributable to hyperbolic geometry. We will further include a short sensitivity analysis on curvature values to address potential distortion concerns. These additions will allow readers to verify that the geometric properties of hyperbolic space are responsible for the observed accuracy-efficiency improvements rather than the other modules alone. revision: yes
Circularity Check
No circularity: framework components rest on external geometric properties and experimental validation
full rationale
The paper proposes HGC-Det with SGVO, HFT and FAGO modules that apply hyperbolic geometry and semantic guidance to cross-modal fusion. No equations, derivations, or parameter-fitting steps are shown in the abstract or described components that reduce by construction to fitted inputs, self-definitions, or self-citation chains. The central claims are supported by experiments across SUN RGB-D, ARKitScenes, KITTI and nuScenes rather than internal redefinitions. This matches the default expectation of a non-circular method paper.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel (J-cost uniqueness) and dAlembert_cosh_solution_aczel (hyperbolic embedding) echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
The HFT component exploits the intrinsic geometric properties of hyperbolic space to alleviate semantic loss during the fusion of high-dimensional image features and low-dimensional point cloud features... map ... to hyperbolic space using Eq. (3) ... tangent space ... LH = sum ||FTg,t 2d3d − FTg,t voxel||
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction (hyperbolic geometry forced by recognition cost) echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
hyperbolic space ... natural advantage in encoding hierarchical structures
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
A survey on occupancy perception for autonomous driving: The information fusion perspective,
H. Xu, J. Chen, S. Meng, Y . Wang, and L.-P. Chau, “A survey on occupancy perception for autonomous driving: The information fusion perspective,”Information Fusion, vol. 114, p. 102671, 2025
work page 2025
-
[2]
Is-fusion: Instance-scene collaborative fusion for multimodal 3d object detection,
J. Yin, J. Shen, R. Chen, W. Li, R. Yang, P. Frossard, and W. Wang, “Is-fusion: Instance-scene collaborative fusion for multimodal 3d object detection,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 14 905–14 915
work page 2024
-
[3]
Bevfusion: A simple and robust lidar-camera fusion frame- work,
T. Liang, H. Xie, K. Yu, Z. Xia, Z. Lin, Y . Wang, T. Tang, B. Wang, and Z. Tang, “Bevfusion: A simple and robust lidar-camera fusion frame- work,”Advances in Neural Information Processing Systems, vol. 35, pp. 10 421–10 434, 2022
work page 2022
-
[4]
V oxel field fusion for 3d object detection,
Y . Li, X. Qi, Y . Chen, L. Wang, Z. Li, J. Sun, and J. Jia, “V oxel field fusion for 3d object detection,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 1120– 1129
work page 2022
-
[5]
Mv2dfusion: Lever- aging modality-specific object semantics for multi-modal 3d detection,
Z. Wang, Z. Huang, Y . Gao, N. Wang, and S. Liu, “Mv2dfusion: Lever- aging modality-specific object semantics for multi-modal 3d detection,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
work page 2025
-
[6]
Logonet: Towards accurate 3d object detection with local-to-global cross-modal fusion,
X. Li, T. Ma, Y . Hou, B. Shi, Y . Yang, Y . Liu, X. Wu, Q. Chen, Y . Li, Y . Qiaoet al., “Logonet: Towards accurate 3d object detection with local-to-global cross-modal fusion,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 17 524–17 534
work page 2023
-
[7]
2dpass: 2d priors assisted semantic segmentation on lidar point clouds,
X. Yan, J. Gao, C. Zheng, C. Zheng, R. Zhang, S. Cui, and Z. Li, “2dpass: 2d priors assisted semantic segmentation on lidar point clouds,” inEuropean conference on computer vision. Springer, 2022, pp. 677– 695
work page 2022
-
[8]
X- trans2cap: Cross-modal knowledge transfer using transformer for 3d dense captioning,
Z. Yuan, X. Yan, Y . Liao, Y . Guo, G. Li, S. Cui, and Z. Li, “X- trans2cap: Cross-modal knowledge transfer using transformer for 3d dense captioning,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 8563–8573
work page 2022
-
[9]
Uni-to-multi modal knowledge distillation for bidirectional lidar-camera semantic segmentation,
T. Sun, Z. Zhang, X. Tan, Y . Peng, Y . Qu, and Y . Xie, “Uni-to-multi modal knowledge distillation for bidirectional lidar-camera semantic segmentation,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 12, pp. 11 059–11 072, 2024
work page 2024
-
[10]
From global to hybrid: a review of supervised deep learning for 2-d image feature representation,
X. Dong, Q. Wang, H. Deng, Z. Yang, W. Ruan, W. Liu, L. Lei, X. Wu, and Y . Tian, “From global to hybrid: a review of supervised deep learning for 2-d image feature representation,”IEEE Transactions on Artificial Intelligence, vol. 6, no. 6, pp. 1540–1560, 2025
work page 2025
-
[11]
Revisiting nonlocal self-similarity from continuous representation,
Y . Luo, X. Zhao, and D. Meng, “Revisiting nonlocal self-similarity from continuous representation,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 47, no. 1, pp. 450–468, 2024
work page 2024
-
[12]
Parameterized low-rank regularizer for high-dimensional visual data,
S. Xu, Z. Zhao, X. Cao, J. Peng, X.-L. Zhao, D. Meng, Y . Zhang, R. Timofte, and L. Van Gool, “Parameterized low-rank regularizer for high-dimensional visual data,”International Journal of Computer Vision, vol. 133, no. 12, pp. 8546–8569, 2025
work page 2025
-
[13]
Deep learning frontiers in 3d object detection: a comprehensive review for autonomous driving,
A. Pravallika, M. F. Hashmi, and A. Gupta, “Deep learning frontiers in 3d object detection: a comprehensive review for autonomous driving,” IEEE Access, 2024
work page 2024
-
[14]
Fully-connected transformer for multi-source image fusion,
X. Wu, Z.-H. Cao, T.-Z. Huang, L.-J. Deng, J. Chanussot, and G. Vivone, “Fully-connected transformer for multi-source image fusion,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 47, no. 3, pp. 2071–2088, 2025
work page 2071
-
[15]
Binarized neural network for multi-spectral image fusion,
J. Hou, X. Chen, R. Ran, X. Cong, X. Liu, J. W. You, and L.-J. Deng, “Binarized neural network for multi-spectral image fusion,” inProceed- ings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 2236–2245
work page 2025
-
[16]
Inf 3: Implicit neural feature fusion function for multispectral and hyperspectral image fusion,
R.-C. Wu, S. Deng, R. Ran, H.-X. Dou, and L.-J. Deng, “Inf 3: Implicit neural feature fusion function for multispectral and hyperspectral image fusion,”IEEE Transactions on Computational Imaging, vol. 10, pp. 1547–1558, 2024
work page 2024
-
[17]
Tr3d: Towards real- time indoor 3d object detection,
D. Rukhovich, A. V orontsova, and A. Konushin, “Tr3d: Towards real- time indoor 3d object detection,” in2023 IEEE International Conference on Image Processing (ICIP). IEEE, 2023, pp. 281–285
work page 2023
-
[18]
Cross modal transformer via coordinates encoding for 3d object dectection,
J. Yan, Y . Liu, J. Sun, F. Jia, S. Li, T. Wang, and X. Zhang, “Cross modal transformer via coordinates encoding for 3d object dectection,” arXiv preprint arXiv:2301.01283, vol. 2, no. 3, p. 4, 2023
-
[19]
Unitr: A unified and efficient multi-modal transformer for bird’s-eye- view representation,
H. Wang, H. Tang, S. Shi, A. Li, Z. Li, B. Schiele, and L. Wang, “Unitr: A unified and efficient multi-modal transformer for bird’s-eye- view representation,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 6792–6802
work page 2023
-
[20]
A simple, unified and effective voxel fusion framework for multi-modal 3d object detection,
Z. Song, G. Zhang, J. Xie, L. Liu, C. Jia, and S. V . Xu, “A simple, unified and effective voxel fusion framework for multi-modal 3d object detection,”IEEE Trans. Geosci. Remote Sens, vol. 61, p. 5705412, 2023
work page 2023
-
[21]
Menet: Multi-modal mapping enhancement network for 3d object detection in autonomous driving,
M. Liu, Y . Chen, J. Xie, Y . Zhu, Y . Zhang, L. Yao, Z. Bing, G. Zhuang, K. Huang, and J. T. Zhou, “Menet: Multi-modal mapping enhancement network for 3d object detection in autonomous driving,”IEEE Trans- actions on Intelligent Transportation Systems, vol. 25, no. 8, pp. 9397– 9410, 2024
work page 2024
-
[22]
Imvotenet: Boosting 3d object detection in point clouds with image votes,
C. R. Qi, X. Chen, O. Litany, and L. J. Guibas, “Imvotenet: Boosting 3d object detection in point clouds with image votes,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 4404–4413
work page 2020
-
[23]
Sparsefusion: Fusing multi-modal sparse representations for multi-sensor 3d object detection,
Y . Xie, C. Xu, M.-J. Rakotosaona, P. Rim, F. Tombari, K. Keutzer, M. Tomizuka, and W. Zhan, “Sparsefusion: Fusing multi-modal sparse representations for multi-sensor 3d object detection,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 17 591–17 602
work page 2023
-
[24]
Sun rgb-d: A rgb-d scene understanding benchmark suite,
S. Song, S. P. Lichtenberg, and J. Xiao, “Sun rgb-d: A rgb-d scene understanding benchmark suite,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 567–576
work page 2015
-
[25]
ARKitScenes: A Diverse Real-World Dataset For 3D Indoor Scene Understanding Using Mobile RGB-D Data
G. Baruch, Z. Chen, A. Dehghan, T. Dimry, Y . Feigin, P. Fu, T. Gebauer, B. Joffe, D. Kurz, A. Schwartzet al., “Arkitscenes: A diverse real-world dataset for 3d indoor scene understanding using mobile rgb-d data,” arXiv preprint arXiv:2111.08897, 2021
work page internal anchor Pith review arXiv 2021
-
[26]
Distilling the Knowledge in a Neural Network
G. Hinton, O. Vinyals, and J. Dean, “Distilling the knowledge in a neural network,”arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[27]
W., Meng, T., Caine, B., Ngiam, J., Peng, D., and Tan, M
Y .-C. Liu, Y .-K. Huang, H.-Y . Chiang, H.-T. Su, Z.-Y . Liu, C.-T. Chen, C.-Y . Tseng, and W. H. Hsu, “Learning from 2d: Contrastive pixel-to-point knowledge transfer for 3d pretraining,”arXiv preprint arXiv:2104.04687, 2021
-
[28]
Image2point: 3d point-cloud understanding with pretrained 2d convnets,
C. Xu, S. Yang, B. Zhai, B. Wu, X. Yue, W. Zhan, P. Vajda, K. Keutzer, and M. Tomizuka, “Image2point: 3d point-cloud understanding with pretrained 2d convnets,”arXiv preprint arXiv:2106.04180, vol. 3, 2021
-
[29]
Hyperbolic geometry in computer vision: A survey,
P. Fang, M. Harandi, T. Le, and D. Phung, “Hyperbolic geometry in computer vision: A survey,”arXiv preprint arXiv:2304.10764, 2023
-
[30]
Hyperbolic image segmentation,
M. G. Atigh, J. Schoep, E. Acar, N. Van Noord, and P. Mettes, “Hyperbolic image segmentation,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 4453– 4462
work page 2022
-
[31]
Curved geometric networks for visual anomaly recognition,
J. Hong, P. Fang, W. Li, J. Han, L. Petersson, and M. Harandi, “Curved geometric networks for visual anomaly recognition,”IEEE transactions on neural networks and learning systems, 2023
work page 2023
-
[32]
Shmamba: Structured hyperbolic state space model for audio-visual question answering,
Z. Yang, W. Li, and G. Cheng, “Shmamba: Structured hyperbolic state space model for audio-visual question answering,”IEEE Transactions on Audio, Speech and Language Processing, 2025
work page 2025
-
[33]
Hyperbolic uncertainty-aware few-shot incremental point cloud segmentation,
T. Sur, S. Mukherjee, K. Rahaman, S. Chaudhuri, M. H. Khan, and B. Banerjee, “Hyperbolic uncertainty-aware few-shot incremental point cloud segmentation,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 11 810–11 821
work page 2025
-
[34]
Hyperbolic contrastive learning for hierarchical 3d point cloud embedding,
Y . Liu, P. Zhang, Z. He, M. Chen, X. Tang, and X. Wei, “Hyperbolic contrastive learning for hierarchical 3d point cloud embedding,”arXiv preprint arXiv:2501.02285, 2025
-
[35]
Hyperbolic- constraint point cloud reconstruction from single rgb-d images,
W. Li, Z. Yang, W. Han, H. Man, X. Wang, and X. Fan, “Hyperbolic- constraint point cloud reconstruction from single rgb-d images,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 5, 2025, pp. 4959–4967
work page 2025
-
[36]
Second: Sparsely embedded convolutional detection,
Y . Yan, Y . Mao, and B. Li, “Second: Sparsely embedded convolutional detection,”Sensors, vol. 18, no. 10, p. 3337, 2018
work page 2018
-
[37]
V oxelnext: Fully sparse voxelnet for 3d object detection and tracking,
Y . Chen, J. Liu, X. Zhang, X. Qi, and J. Jia, “V oxelnext: Fully sparse voxelnet for 3d object detection and tracking,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 21 674–21 683
work page 2023
-
[38]
Center-based 3d object detection and tracking,
T. Yin, X. Zhou, and P. Krahenbuhl, “Center-based 3d object detection and tracking,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 11 784–11 793
work page 2021
-
[39]
Cotr: Compact occupancy transformer for vision-based 3d occupancy prediction,
Q. Ma, X. Tan, Y . Qu, L. Ma, Z. Zhang, and Y . Xie, “Cotr: Compact occupancy transformer for vision-based 3d occupancy prediction,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 19 936–19 945
work page 2024
-
[40]
Poincar ´e embeddings for learning hierarchical representations,
M. Nickel and D. Kiela, “Poincar ´e embeddings for learning hierarchical representations,”Advances in neural information processing systems, vol. 30, 2017
work page 2017
-
[41]
Cagroup3d: Class-aware grouping for 3d object detection on point clouds,
H. Wang, L. Ding, S. Dong, S. Shi, A. Li, J. Li, Z. Li, and L. Wang, “Cagroup3d: Class-aware grouping for 3d object detection on point clouds,”Advances in neural information processing systems, vol. 35, pp. 29 975–29 988, 2022
work page 2022
-
[42]
Spgroup3d: Superpoint grouping network for indoor 3d object detection,
Y . Zhu, L. Hui, Y . Shen, and J. Xie, “Spgroup3d: Superpoint grouping network for indoor 3d object detection,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 7, 2024, pp. 7811– 7819. IEEE TRANSACTIONS ON MULTIMEDIA 10
work page 2024
-
[43]
Unidet3d: Multi-dataset indoor 3d object detection,
M. Kolodiazhnyi, A. V orontsova, M. Skripkin, D. Rukhovich, and A. Konushin, “Unidet3d: Multi-dataset indoor 3d object detection,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 4, 2025, pp. 4365–4373
work page 2025
-
[44]
V-detr: Detr with vertex relative position encoding for 3d object detection,
Y . Shen, Z. Geng, Y . Yuan, Y . Lin, Z. Liu, C. Wang, H. Hu, N. Zheng, and B. Guo, “V-detr: Detr with vertex relative position encoding for 3d object detection,”arXiv preprint arXiv:2308.04409, 2023
-
[45]
Point-gcc: Universal self-supervised 3d scene pre-training via geometry-color contrast,
G. Fan, Z. Qi, W. Shi, and K. Ma, “Point-gcc: Universal self-supervised 3d scene pre-training via geometry-color contrast,” inProceedings of the 32nd ACM International Conference on Multimedia, 2024, pp. 4709– 4718
work page 2024
-
[46]
Rbgnet: Ray-based grouping for 3d object detection,
H. Wang, S. Shi, Z. Yang, R. Fang, Q. Qian, H. Li, B. Schiele, and L. Wang, “Rbgnet: Ray-based grouping for 3d object detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 1110–1119
work page 2022
-
[47]
One for all: Multi-domain joint training for point cloud based 3d object detection,
Z. Wang, Y .-L. Li, H. Zhao, and S. Wang, “One for all: Multi-domain joint training for point cloud based 3d object detection,”Advances in Neural Information Processing Systems, vol. 37, pp. 56 859–56 877, 2024
work page 2024
-
[48]
3det-mamba: State space model for end-to-end 3d object detection,
M. Li, J. Yuan, S. Chen, L. Zhang, A. Zhu, X. Chen, and T. Chen, “3det-mamba: State space model for end-to-end 3d object detection,” in Proceedings of the 38th International Conference on Neural Information Processing Systems, 2024, pp. 47 242–47 260
work page 2024
-
[49]
Unimode: Unified monocular 3d object detection,
Z. Li, X. Xu, S. Lim, and H. Zhao, “Unimode: Unified monocular 3d object detection,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 16 561–16 570
work page 2024
-
[50]
3difftection: 3d object detection with geometry-aware diffusion features,
C. Xu, H. Ling, S. Fidler, and O. Litany, “3difftection: 3d object detection with geometry-aware diffusion features,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 10 617–10 627
work page 2024
-
[51]
Pointpillars: Fast encoders for object detection from point clouds,
A. H. Lang, S. V ora, H. Caesar, L. Zhou, J. Yang, and O. Beijbom, “Pointpillars: Fast encoders for object detection from point clouds,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 12 697–12 705
work page 2019
-
[52]
Pv-rcnn: Point-voxel feature set abstraction for 3d object detection,
S. Shi, C. Guo, L. Jiang, Z. Wang, J. Shi, X. Wang, and H. Li, “Pv-rcnn: Point-voxel feature set abstraction for 3d object detection,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 10 529–10 538
work page 2020
-
[53]
V oxel-rcnn-complex: An effective 3-d point cloud object detector for complex traffic conditions,
H. Wang, Z. Chen, Y . Cai, L. Chen, Y . Li, M. A. Sotelo, and Z. Li, “V oxel-rcnn-complex: An effective 3-d point cloud object detector for complex traffic conditions,”IEEE Transactions on Instrumentation and Measurement, vol. 71, pp. 1–12, 2022
work page 2022
-
[54]
Se-ssd: Self-ensembling single-stage object detector from point cloud,
W. Zheng, W. Tang, L. Jiang, and C.-W. Fu, “Se-ssd: Self-ensembling single-stage object detector from point cloud,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 14 494–14 503
work page 2021
-
[55]
Point density-aware voxels for lidar 3d object detection,
J. S. Hu, T. Kuai, and S. L. Waslander, “Point density-aware voxels for lidar 3d object detection,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 8469–8478
work page 2022
-
[56]
Epnet: Enhancing point features with image semantics for 3d object detection,
T. Huang, Z. Liu, X. Chen, and X. Bai, “Epnet: Enhancing point features with image semantics for 3d object detection,” inEuropean conference on computer vision. Springer, 2020, pp. 35–52
work page 2020
-
[57]
Focal sparse convolutional networks for 3d object detection,
Y . Chen, Y . Li, X. Zhang, J. Sun, and J. Jia, “Focal sparse convolutional networks for 3d object detection,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 5428– 5437
work page 2022
-
[58]
Cat-det: Contrastively augmented transformer for multi-modal 3d object detection,
Y . Zhang, J. Chen, and D. Huang, “Cat-det: Contrastively augmented transformer for multi-modal 3d object detection,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 908–917
work page 2022
-
[59]
Hednet: A hierarchical encoder-decoder network for 3d object detection in point clouds,
G. Zhang, C. Junnan, G. Gao, J. Li, and X. Hu, “Hednet: A hierarchical encoder-decoder network for 3d object detection in point clouds,”Ad- vances in Neural Information Processing Systems, vol. 36, pp. 53 076– 53 089, 2023
work page 2023
-
[60]
EA-LSS: Edge-aware Lift-splat-shot Framework for 3D BEV Object Detection,
H. Hu, F. Wang, J. Su, Y . Wang, L. Hu, W. Fang, J. Xu, and Z. Zhang, “Ea-lss: Edge-aware lift-splat-shot framework for 3d bev object detection,”arXiv preprint arXiv:2303.17895, 2023
-
[61]
Sparselif: High- performance sparse lidar-camera fusion for 3d object detection,
H. Zhang, L. Liang, P. Zeng, X. Song, and Z. Wang, “Sparselif: High- performance sparse lidar-camera fusion for 3d object detection,” in European Conference on Computer Vision. Springer, 2024, pp. 109– 128
work page 2024
-
[62]
Dsgn++: Exploiting visual-spatial relation for stereo-based 3d detectors,
Y . Chen, S. Huang, S. Liu, B. Yu, and J. Jia, “Dsgn++: Exploiting visual-spatial relation for stereo-based 3d detectors,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 4, pp. 4416– 4429, 2022. Kanglin Ningreceived a B.S. degree from the Dalian University of Technology, Dalian, China, in 2016. and received the M.S. degree fro...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.