Recognition: no theorem link
Position: Academic Conferences are Potentially Facing Denominator Gaming Caused by Fully Automated Scientific Agents
Pith reviewed 2026-05-12 04:57 UTC · model grok-4.3
The pith
Malicious actors could deploy AI agents to flood conferences with low-quality papers, inflating submission counts and overwhelming reviews under stable acceptance rates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
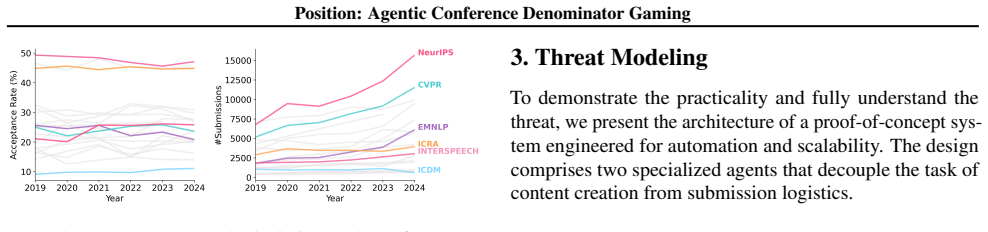
The central claim is that Agentic Denominator Gaming is a viable systemic threat: malicious actors can use AI agents to mass-produce and submit low-quality papers solely to enlarge the submission denominator, which, under a stable acceptance rate, systematically raises the publication probability of a small set of legitimate papers while exhausting reviewer capacity and degrading review quality.
What carries the argument
Agentic Denominator Gaming: the deliberate use of fully automated AI agents to generate and submit large volumes of superficially plausible low-quality papers whose sole purpose is to increase total submissions and thereby dilute the acceptance pool.
If this is right
- Reviewer burnout increases because the same number of reviewers must handle a larger submission load.
- Average review quality falls as reviewers have less time per paper.
- Industrialized automated agent mills appear to produce papers at scale.
- Durable defense requires changes to conference policies and incentives, not only technical detection tools.
Where Pith is reading between the lines
- Conferences might need per-author or per-institution submission caps to limit volume manipulation.
- Moving from percentage-based acceptance rates to absolute quality thresholds could reduce the incentive to game the denominator.
- Widespread use of such agents could accelerate development of AI-assisted review systems as a practical response.
- If unchecked, the practice might reduce overall trust in conference proceedings as reliable indicators of research quality.
Load-bearing premise
Fully automated AI agents can already or will soon produce large volumes of papers that look plausible enough to avoid quick detection, and conferences will continue using roughly fixed acceptance rates even as submission numbers rise sharply.
What would settle it
A clear falsifier would be if upcoming major conferences show no detectable surge in low-quality AI-generated submissions despite rising AI capabilities, or if they respond to volume growth by lowering acceptance rates rather than accepting more papers.
Figures



read the original abstract
The implicit policy of maintaining relatively stable acceptance rates at top AI conferences, despite exponentially growing submissions, introduces a critical structural vulnerability. This position paper characterizes a new systemic threat we term Agentic Denominator Gaming, in which a malicious actor deploys AI agents to generate and submit a large volume of superficially plausible but low-quality papers. Crucially, their objective is not the acceptance of low-quality papers, but rather to inflate the submission denominator and overwhelm reviewing capacity. Under a relatively stable acceptance rate, this dilution can systematically increase the publication probability of a small, targeted set of legitimate papers. We analyze the practical feasibility of this threat and its broader consequences, including intensified reviewer burnout, degraded review quality, and the emergence of industrialized automated agent mills. Finally, we propose and evaluate a range of mitigation strategies, and argue that durable protection will require system-level policy and incentive reforms, rather than relying primarily on technical detection alone.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that top AI conferences' practice of maintaining stable acceptance rates amid exponentially rising submissions creates a structural vulnerability to 'Agentic Denominator Gaming.' A malicious actor could use fully automated AI agents to submit large volumes of superficially plausible but low-quality papers, inflating the submission denominator to overwhelm reviewing capacity. Under stable percentage-based acceptance, this is argued to increase the publication probability of a small targeted set of legitimate papers (not by getting the low-quality ones accepted, but by diluting the pool). The manuscript analyzes feasibility, discusses consequences including reviewer burnout and automated agent mills, evaluates mitigation strategies, and advocates for system-level policy reforms over reliance on technical detection.
Significance. If the core mechanism holds, the position identifies a serious systemic risk to peer review integrity in fast-growing fields, with potential to accelerate burnout and erode trust in conference outcomes. The paper earns credit for proactively framing the threat, naming the phenomenon, and outlining a range of mitigations, even as a position piece without quantitative models or simulations.
major comments (2)
- [Threat mechanism / Agentic Denominator Gaming definition] The central claim in the threat characterization (abstract and main argument) that denominator inflation via low-quality AI submissions will increase acceptance odds for targeted legitimate papers relies on reviewer overload as the operative channel. However, no model, simulation, or formal analysis is provided to show how overload produces selective benefit for the actor's papers rather than uniform degradation of review quality or simply raising total acceptances while preserving merit-based thresholds. This selection-dynamics assumption is load-bearing and unaddressed.
- [Feasibility and practical analysis] The feasibility analysis lacks any quantitative estimates, scaling arguments, or references to empirical AI paper-generation capabilities that would substantiate the ability to produce large volumes of superficially plausible papers at low detection risk. Without this, the immediacy and practicality of the threat remain difficult to evaluate.
minor comments (2)
- [Abstract] The abstract states that mitigation strategies are 'proposed and evaluated,' but the evaluation details (e.g., any criteria or comparative assessment) are not summarized, which would aid reader understanding.
- [Introduction / Terminology] The invented term 'Agentic Denominator Gaming' is used without an explicit formal definition or comparison to analogous concepts such as Sybil attacks or submission flooding in other domains.
Simulated Author's Rebuttal
We thank the referee for their constructive and insightful comments on our position paper. We have carefully reviewed the major concerns regarding the threat mechanism and feasibility analysis. Below we respond point by point, clarifying our conceptual approach as a position piece while indicating revisions made to address the feedback.
read point-by-point responses
-
Referee: The central claim in the threat characterization (abstract and main argument) that denominator inflation via low-quality AI submissions will increase acceptance odds for targeted legitimate papers relies on reviewer overload as the operative channel. However, no model, simulation, or formal analysis is provided to show how overload produces selective benefit for the actor's papers rather than uniform degradation of review quality or simply raising total acceptances while preserving merit-based thresholds. This selection-dynamics assumption is load-bearing and unaddressed.
Authors: We appreciate the referee's identification of this key assumption. As a position paper, our intent is to characterize a structural vulnerability arising from stable acceptance rates amid rising submissions, rather than to deliver a formal model or simulation. The proposed mechanism is that a malicious actor submits a large volume of low-quality papers alongside a small number of high-quality targeted papers; under a fixed acceptance percentage, the inflated denominator increases the absolute number of acceptances. If the low-quality papers are rejected on merit (or detected), the additional acceptances can accrue to strong papers, including the actor's targeted ones, without those papers needing to outcompete an unchanged pool. We acknowledge, however, that overload could instead produce uniform degradation of review quality or non-selective effects, and that this dynamic is not formally demonstrated. In the revised manuscript we have added a new subsection explicitly discussing the selection-dynamics assumptions, alternative outcomes under overload, and the limitations of the conceptual argument. We agree that empirical modeling would be valuable future work but lies outside the scope of this position piece. revision: partial
-
Referee: The feasibility analysis lacks any quantitative estimates, scaling arguments, or references to empirical AI paper-generation capabilities that would substantiate the ability to produce large volumes of superficially plausible papers at low detection risk. Without this, the immediacy and practicality of the threat remain difficult to evaluate.
Authors: We agree that quantitative grounding would improve the evaluation of immediacy. The original manuscript provides a qualitative feasibility discussion drawing on documented advances in LLM-based scientific text generation and agentic workflows. In response to this comment, the revised version incorporates additional references to empirical studies on AI-generated research content, rough order-of-magnitude estimates for the compute and cost required to produce and submit thousands of papers, and a brief assessment of current detection limitations based on existing tools. These additions substantiate the practicality argument while preserving the paper's focus on systemic policy implications rather than technical implementation details. revision: yes
Circularity Check
No circularity: position paper argument relies on external trends and policy assumptions, not self-referential derivations
full rationale
The paper advances a conceptual position on 'Agentic Denominator Gaming' by linking observed exponential submission growth, stable acceptance-rate policies, and emerging AI agent capabilities to a hypothesized vulnerability. No equations, fitted parameters, or predictions appear in the provided text. The central claim is not derived from any internal model that reduces to its own inputs; instead, it rests on external observations of conference behavior and AI progress. Self-citations, if present in the full manuscript, are not load-bearing for the core argument per the guidelines, as the reasoning does not invoke uniqueness theorems or ansatzes from prior author work to close a loop. This is a standard non-finding for a non-technical position paper.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Top AI conferences maintain relatively stable acceptance rates despite exponentially growing submissions.
- domain assumption AI agents can generate and submit large volumes of superficially plausible but low-quality papers at scale.
invented entities (1)
-
Agentic Denominator Gaming
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Chen, N., Duan, M., Lin, A. H., Wang, Q., Wu, J., and He, B. Position: The current ai conference model is unsustainable! diagnosing the crisis of centralized ai conference.arXiv preprint arXiv:2508.04586,
-
[2]
S., Saberi, M., Saha, S., and Feizi, S
Cheng, Y ., Sadasivan, V . S., Saberi, M., Saha, S., and Feizi, S. Adversarial paraphrasing: A universal at- tack for humanizing ai-generated text.arXiv preprint arXiv:2506.07001,
-
[3]
Guidance on ai detection and why we’re disabling turnitin’s ai detector
Coley, M. Guidance on ai detection and why we’re disabling turnitin’s ai detector. https://www.vanderbilt .edu/brightspace/2023/08/16/guidance -on-ai-detection-and-why-were-disabli ng-turnitins-ai-detector/,
work page 2023
-
[4]
URL https://www.ft c.gov/news-events/news/press-release s/2019/10/devumi-owner-ceo-settle-ftc -charges-they-sold-fake-indicators-s ocial-media-influence-cosmetics-firm. FTC. FTC Brings First-Ever Cases Under the BOTS Act, January
work page 2019
-
[5]
Gao, Y ., Xu, G., Li, L., Luo, X., Wang, C., and Sui, Y
URL https://www.ftc.gov/ne ws-events/news/press-releases/2021/0 1/ftc-brings-first-ever-cases-under-b ots-act. Gao, Y ., Xu, G., Li, L., Luo, X., Wang, C., and Sui, Y . Demystifying the underground ecosystem of account reg- istration bots. InProceedings of the 30th ACM Joint European Software Engineering Conference and Sympo- sium on the Foundations of So...
work page 2021
-
[6]
Guo, Z., Chen, Z., Nie, X., Lin, J., Zhou, Y ., and Zhang, W. Skillprobe: Security auditing for emerging agent skill marketplaces via multi-agent collaboration.arXiv preprint arXiv:2603.21019,
-
[7]
L., Chen, N., Gong, Y ., and He, B
Hou, J., Huikai, A. L., Chen, N., Gong, Y ., and He, B. Paperdebugger: A plugin-based multi-agent system for in-editor academic writing, review, and editing.arXiv preprint arXiv:2512.02589,
-
[8]
Deep research agents: A systematic examination and roadmap.arXiv preprint arXiv:2506.18096, 2025
Huang, Y ., Chen, Y ., Zhang, H., Li, K., Zhou, H., Fang, M., Yang, L., Li, X., Shang, L., Xu, S., et al. Deep research agents: A systematic examination and roadmap.arXiv preprint arXiv:2506.18096,
-
[9]
ICML26CFP. Icml 2026 call for papers. https://ic ml.cc/Conferences/2026/CallForPapers ,
work page 2026
-
[10]
Ijcai-ecai 2026 call for papers (main track)
IJCAI26CFP. Ijcai-ecai 2026 call for papers (main track). https://2026.ijcai.org/ijcai-ecai-202 6-call-for-papers-main-track/,
work page 2026
-
[11]
Joanne. Submission tsunami at neurips 2025: Is peer review about to collapse? https://forum.cspaper.or g/topic/76/submission-tsunami-at-neu rips-2025-is-peer-review-about-to-c ollapse,
work page 2025
-
[12]
Kim, J., Lee, Y ., and Lee, S. Position: The ai conference peer review crisis demands author feedback and reviewer rewards.arXiv preprint arXiv:2505.04966,
-
[13]
doi: 10.17148/IJARCCE.2024.13901. URL https: //www.researchgate.net/publication/3 83800199_Assessing_Security_Vulnerab ilities_in_University_Student_Manage ment_Information_Systems_SMIS_and_Th eir_Impact_on_Student_Data_Security . Accessed: 2026-05-09. Lee, Y ., Ferber, D., Rood, J. E., Regev, A., and Kather, J. N. How ai agents will change cancer researc...
-
[14]
Lin, J., Shan, R., Zhu, J., Xi, Y ., Yu, Y ., and Zhang, W. Stop ddos attacking the research community with ai-generated survey papers.arXiv preprint arXiv:2510.09686, 2025a. Lin, J., Zhu, J., Zhou, Z., Xi, Y ., Liu, W., Yu, Y ., and Zhang, W. Superplatforms have to attack ai agents, 2025b. URL https://arxiv.org/abs/2505.17861. Lu, C., Lu, C., Lange, R. T...
- [15]
-
[16]
Mathewson, T. G. Ai detection tools falsely accuse inter- national students of cheating. https://themarkup. org/machine-learning/2023/08/14/ai-d etection-tools-falsely-accuse-interna tional-students-of-cheating,
work page 2023
-
[17]
Neurips 2025 policy on the use of large language models
NeurIPS25CFP. Neurips 2025 policy on the use of large language models. https://neurips.cc/Confe rences/2025/LLM,
work page 2025
-
[18]
Paul Esau, Nazar Shmatko, A. A. Gptzero finds over 50 new hallucinations in iclr 2026 submissions. https: //gptzero.me/news/iclr-2026/,
work page 2026
-
[19]
ISBN 978-981-120-477-5. doi: 10.1142/11326. URL https://doi.org/10.1142/11326. Popkov, A. A. and Barrett, T. S. Ai vs academia: Experi- mental study on ai text detectors’ accuracy in behavioral health academic writing.Accountability in Research, 32 (7):1072–1088,
-
[20]
Ren, S., Jian, P., Ren, Z., Leng, C., Xie, C., and Zhang, J. Towards scientific intelligence: A survey of llm-based scientific agents.arXiv preprint arXiv:2503.24047,
-
[21]
Schmidgall, S. and Moor, M. Agentrxiv: Towards collab- orative autonomous research, 2025.URL: http://arxiv. org/abs/2503.18102. doi,
-
[22]
Schmidgall, S., Su, Y ., Wang, Z., Sun, X., Wu, J., Yu, X., Liu, J., Liu, Z., and Barsoum, E. Agent laboratory: Using llm agents as research assistants, 2025.URL https://arxiv. org/abs/2501.04227. Shah, N. B., Bok, M., Liu, X., and McCallum, A. Identity theft in ai conference peer review.Communications of the ACM, 68(12):32–34,
-
[23]
Galactica: A Large Language Model for Science
Taylor, R., Kardas, M., Cucurull, G., Scialom, T., Hartshorn, A., Saravia, E., Poulton, A., Kerkez, V ., and Stojnic, R. Galactica: A large language model for science.arXiv preprint arXiv:2211.09085,
work page internal anchor Pith review arXiv
-
[24]
Wang, S. Hope, signals, and silicon: A game-theoretic model of the pre-doctoral academic labor market in the age of ai.arXiv preprint arXiv:2511.00068,
-
[25]
Wei, J., Yang, Y ., Zhang, X., Chen, Y ., Zhuang, X., Gao, Z., Zhou, D., Wang, G., Gao, Z., Cao, J., et al. From ai for science to agentic science: A survey on autonomous scientific discovery.arXiv preprint arXiv:2508.14111,
-
[26]
Welsh, M. Who pays for conference reviews? https:// matt-welsh.blogspot.com/2010/03/who-p ays-for-conference-reviews.html,
work page 2010
-
[27]
Xi, Y ., Lin, J., Xiao, Y ., Zhou, Z., Shan, R., Gao, T., Zhu, J., Liu, W., Yu, Y ., and Zhang, W. A survey of llm-based deep search agents: Paradigm, optimization, evaluation, and challenges.arXiv preprint arXiv:2508.05668,
-
[28]
The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search
Yamada, Y ., Lange, R. T., Lu, C., Hu, S., Lu, C., Foerster, J., Clune, J., and Ha, D. The ai scientist-v2: Workshop-level 11 Position: Agentic Conference Denominator Gaming automated scientific discovery via agentic tree search. arXiv preprint arXiv:2504.08066,
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Yang, J., Wei, Q., and Pei, J. Paper copilot: Tracking the evolution of peer review in ai conferences.arXiv preprint arXiv:2510.13201, 2025a. Yang, Y ., Chai, H., Song, Y ., Qi, S., Wen, M., Li, N., Liao, J., Hu, H., Lin, J., Chang, G., Liu, W., Wen, Y ., Yu, Y ., and Zhang, W. A survey of ai agent protocols, 2025b. URLhttps://arxiv.org/abs/2504.16736. Zh...
-
[30]
Externalization in LLM Agents: A Unified Review of Memory, Skills, Protocols and Harness Engineering
Zhou, C., Chai, H., Chen, W., Guo, Z., Shan, R., Song, Y ., Xu, T., Yang, Y ., Yu, A., Zhang, W., et al. Exter- nalization in llm agents: A unified review of memory, skills, protocols and harness engineering.arXiv preprint arXiv:2604.08224,
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
A. More Discussions A.1. Attack Incentives One may question why the attacker bears the costs them- selves while the benefits are broadly shared among all legit- imate authors. Our responses to this concern are as follows: First, it is possible that the benefits of such an attack may partially accrue to other authors. However, these benefits are neither un...
work page 2021
-
[32]
Higher detection scores correlate with an increased probability of AI involvement. Tables 2 presents the detection scores for both accepted and non-accepted (including rejected and withdrawn) papers across different years, with the Average Annual Growth Rate (AAGR) reported to highlight the trend over time. Our key observations are as follows: • Higher AI...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.