Recognition: 2 theorem links
· Lean TheoremMuninn: Your Trajectory Diffusion Model But Faster
Pith reviewed 2026-05-12 03:44 UTC · model grok-4.3
The pith
Muninn speeds up diffusion trajectory planners up to 4.6 times by caching denoiser steps whose reuse is provably safe.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By tracking a running uncertainty budget built from a trajectory-change probe and analytic coefficients that propagate denoiser error through the sampler, Muninn decides at each diffusion step whether to reuse a cached network output or recompute it, delivering up to 4.6 times fewer evaluations while guaranteeing the final trajectory lies within a user-specified distance of the full-compute result.
What carries the argument
The per-step uncertainty score that upper-bounds final-trajectory deviation when a cached denoiser output is reused, obtained by calibrating an online trajectory-change probe against offline analytic error-propagation coefficients.
If this is right
- Wall-clock speedups of up to 4.6 times appear across several trajectory diffusion models on standard benchmarks.
- Task performance and safety metrics stay statistically unchanged.
- Cached trajectories are certified to lie inside a user-chosen distance of their full-compute versions.
- The wrapper works on any state-space diffusion architecture without retraining.
- The same speedups and certificates hold in real-time closed-loop navigation and manipulation experiments.
Where Pith is reading between the lines
- The same probe-and-bound idea could be applied to other iterative generative planners that expose cheap change signals.
- Tighter offline calibration on more diverse trajectories might shrink the uncertainty budget and yield still larger speedups.
- Because the bound is independent of the particular robot dynamics, the method might transfer to non-robotic diffusion sampling tasks where error certificates matter.
- Integration with downstream controllers that already consume trajectory uncertainty could turn Muninn's budget into an explicit safety margin.
Load-bearing premise
The per-step score supplies a valid upper bound on how far the finished trajectory can drift when a cached denoiser output is reused during closed-loop robot operation.
What would settle it
Any benchmark or hardware trial in which a Muninn trajectory deviates from its full-compute counterpart by more than the declared bound.
Figures



















read the original abstract
Diffusion-based trajectory planners can synthesize rich, multimodal robot motions, but their iterative denoising makes online planning and control prohibitively slow. Existing accelerations either modify the sampler or compress the network--sacrificing plan quality or requiring retraining without accounting for downstream control risk. We address the problem of making diffusion-based trajectory planners fast enough for real-time robot use without retraining the model or sacrificing trajectory quality, and in a way that works across diverse state-space diffusion architectures. Our key insight is that diffusion trajectory planners expose two signals we can exploit: a cheap probe of how their internal trajectory representation changes across steps, and analytic coefficients that describe how denoiser errors affect the sampler's state update. By calibrating the first signal against the second on offline runs, we obtain a per-step score that upper-bounds how far the final trajectory can deviate when we reuse a cached denoiser output, and we treat this bound as an uncertainty budget that we can spend over the denoising process. Building on this insight, we present Muninn, a training-free caching wrapper that tracks this uncertainty budget during sampling and, at each diffusion step, chooses between reusing a cached denoiser output when the predicted deviation is small and recomputing the denoiser when it is not. Across standard benchmarks Muninn delivers up to 4.6x wall-clock speedups across several trajectory diffusion models by reducing denoiser evaluations, while preserving task performance and safety metrics. Muninn further certifies that cached rollouts remain within a specified distance of their full-compute counterparts, and we validate these gains in real-time closed-loop navigation and manipulation hardware deployments. Project page: https://github.com/gokulp01/Muninn.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Muninn, a training-free caching wrapper for diffusion-based trajectory planners. It exploits a cheap trajectory-change probe and analytic denoiser-error coefficients, calibrated offline, to produce a per-step uncertainty score that upper-bounds final-trajectory deviation when cached denoiser outputs are reused. The method decides at each diffusion step whether to reuse the cache or recompute, treating the bound as an expendable uncertainty budget. Across benchmarks it reports up to 4.6x wall-clock speedups while preserving task performance and safety metrics, certifies that cached rollouts stay within a user-specified distance of full-compute counterparts, and validates the approach in real-time closed-loop hardware deployments for navigation and manipulation.
Significance. If the offline-calibrated bound remains valid under closed-loop state feedback, Muninn would offer a general, retraining-free route to real-time deployment of multimodal diffusion planners without sacrificing quality or safety. The analytic grounding of the error propagation and the training-free nature are notable strengths that could apply across diverse state-space architectures. Hardware validation is a positive indicator of practical utility, though the absence of direct bound-violation tests leaves the certification claim dependent on empirical margins.
major comments (3)
- [Abstract and §3] Abstract and §3 (Method): the per-step uncertainty score is calibrated on offline open-loop full-compute rollouts to match analytic coefficients; the manuscript provides no direct verification (e.g., measured vs. predicted deviation histograms or worst-case violation rates) that this score continues to upper-bound final-trajectory deviation once states are produced by previously cached trajectories inside a closed loop. This is load-bearing for the certification claim.
- [§5] §5 (Experiments): no ablation or sensitivity analysis is reported for the uncertainty-budget threshold (a free parameter); the reported 4.6x speedups and preserved safety metrics could be sensitive to its choice, yet only aggregate results are shown without error bars or per-seed statistics.
- [§4.2] §4.2 (Closed-loop validation): hardware deployments preserve safety metrics, but this does not constitute a test of the mathematical bound itself; an empirical safety margin could mask cases where the offline-calibrated score becomes optimistic under distribution shift induced by the caching policy.
minor comments (2)
- [§3] Notation for the trajectory-change probe and analytic coefficients should be introduced with explicit equations and a small worked example to improve readability.
- [Table 1] Table 1 (speedup results) would benefit from per-model breakdown of cache-hit rate and average deviation observed, rather than only aggregate wall-clock numbers.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights important aspects of our certification claims and experimental rigor. We address each major comment below, agreeing where revisions are needed and providing clarifications on the theoretical grounding. We will incorporate the suggested additions in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Method): the per-step uncertainty score is calibrated on offline open-loop full-compute rollouts to match analytic coefficients; the manuscript provides no direct verification (e.g., measured vs. predicted deviation histograms or worst-case violation rates) that this score continues to upper-bound final-trajectory deviation once states are produced by previously cached trajectories inside a closed loop. This is load-bearing for the certification claim.
Authors: We agree that direct verification of the bound under closed-loop state feedback is essential for the certification claim. The analytic error-propagation coefficients are derived from the sampler's deterministic update rule and hold independently of state origin, provided the per-step denoiser error remains within the calibrated range. However, the calibration data are open-loop. In the revision we will add closed-loop simulation experiments that (i) run Muninn with caching, (ii) compute both the predicted per-step uncertainty and the actual final-trajectory deviation from the full-compute baseline, and (iii) report histograms and worst-case violation rates across multiple seeds and environments. This will empirically confirm whether the offline-calibrated score remains a valid upper bound under the distribution shift induced by caching. revision: yes
-
Referee: [§5] §5 (Experiments): no ablation or sensitivity analysis is reported for the uncertainty-budget threshold (a free parameter); the reported 4.6x speedups and preserved safety metrics could be sensitive to its choice, yet only aggregate results are shown without error bars or per-seed statistics.
Authors: We acknowledge the value of characterizing sensitivity to the uncertainty-budget threshold. In the original experiments the threshold was chosen to achieve a target speedup while preserving task metrics, but no systematic ablation was presented. In the revised manuscript we will include an ablation study that varies the budget threshold over a range of values, reporting the resulting wall-clock speedup, task success rate, and safety metrics together with mean and standard deviation across at least five random seeds. Error bars will be added to all aggregate plots to quantify variability. revision: yes
-
Referee: [§4.2] §4.2 (Closed-loop validation): hardware deployments preserve safety metrics, but this does not constitute a test of the mathematical bound itself; an empirical safety margin could mask cases where the offline-calibrated score becomes optimistic under distribution shift induced by the caching policy.
Authors: The referee is correct that preserved safety metrics in hardware do not directly validate the mathematical bound. The hardware results demonstrate practical feasibility and absence of safety violations under real-world conditions, but they rely on an empirical margin. To address this, the revision will add the closed-loop simulation analysis described in response to the first comment, explicitly comparing predicted versus realized trajectory deviations. These simulations will be performed on the same state distributions encountered in the hardware trials, thereby testing the bound under the precise distribution shift induced by the caching policy. revision: yes
Circularity Check
No significant circularity; calibration explicitly empirical and transparently stated
full rationale
The paper describes obtaining the per-step score explicitly via calibration of a trajectory-change probe against analytic denoiser-error coefficients on offline runs, then using the resulting score as an uncertainty budget for caching decisions. This is presented as a practical, training-free wrapper rather than a first-principles derivation claimed to hold by mathematical necessity. No equations or steps in the provided text reduce a claimed prediction or bound to its inputs by construction (e.g., no fitted threshold renamed as an independently derived guarantee). The method acknowledges its dependence on offline data and reports separate empirical validation on benchmarks and hardware; the closed-loop validity concern is a question of assumption strength, not a circular reduction in the derivation itself. No self-citations, ansatzes smuggled via prior work, or renaming of known results appear as load-bearing elements.
Axiom & Free-Parameter Ledger
free parameters (1)
- uncertainty budget threshold
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanJcost uniqueness and convexity echoesWe define the per-step trajectory cost associated with a ∥e_t∥ as c_t(e_t):= Γ L_t ∥e_t∥. Then (4) simply states that the total trajectory deviation is bounded by the sum of per-step costs, d(τ_full_0, τ̃_0) ≤ ∑ c_t(e_t). Muninn uses (5) as a budget rule
Reference graph
Works this paper leans on
-
[1]
Approximate caching for efficiently serving Text- to-Image diffusion models
Shubham Agarwal, Subrata Mitra, Sarthak Chakraborty, Srikrishna Karanam, Koyel Mukherjee, and Shiv Kumar Saini. Approximate caching for efficiently serving Text- to-Image diffusion models. InUSENIX Symposium on Networked Systems Design and Implementation, pages 1173–1189, 2024
work page 2024
-
[2]
Anurag Ajay, Yilun Du, Abhi Gupta, Joshua B. Tenen- baum, Tommi Jaakkola, and Pulkit Agrawal. Is conditional generative modeling all you need for decision-making? arXiv preprint arXiv:2211.15657, 2022
-
[3]
Training Diffusion Models with Reinforcement Learning
Kevin Black, Michael Janner, Yilun Du, Ilya Kostrikov, and Sergey Levine. Training diffusion models with reinforcement learning.arXiv preprint arXiv:2305.13301, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
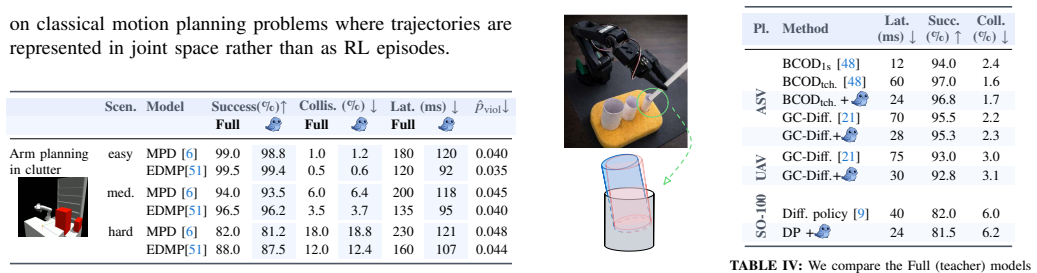
[4]
Token merging for fast stable diffusion
Daniel Bolya and Judy Hoffman. Token merging for fast stable diffusion. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4599–4603, 2023
work page 2023
-
[5]
Dicache: Let diffusion model determine its own cache
Jiazi Bu, Pengyang Ling, Yujie Zhou, Yibin Wang, Yuhang Zang, Tong Wu, Dahua Lin, and Jiaqi Wang. Dicache: Let diffusion model determine its own cache. arXiv preprint arXiv:2508.17356, 2025
-
[6]
Motion planning diffusion: Learning and planning of robot motions with diffusion models
Joao Carvalho, An T Le, Mark Baierl, Dorothea Koert, and Jan Peters. Motion planning diffusion: Learning and planning of robot motions with diffusion models. In IEEE/RSJ International Conference on Intelligent Robots and Systems, pages 1916–1923, 2023
work page 1916
-
[7]
Guanjie Chen, Xinyu Zhao, Yucheng Zhou, Tianlong Chen, and Cheng Yu. Accelerating vision diffu- sion transformers with skip branches.arXiv preprint arXiv:2411.17616, 2024
-
[8]
Adaptive time-stepping schedules for diffusion models
Yuzhu Chen, Fengxiang He, Shi Fu, Xinmei Tian, and Dacheng Tao. Adaptive time-stepping schedules for diffusion models. InConference on Uncertainty in Artificial Intelligence, 2024
work page 2024
-
[9]
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
work page 2025
-
[10]
End-to-end driving via conditional imitation learning
Felipe Codevilla, Matthias M¨ uller, Antonio L ´opez, Vladlen Koltun, and Alexey Dosovitskiy. End-to-end driving via conditional imitation learning. InIEEE International Conference on Robotics and Automation, pages 4693–4700, 2018
work page 2018
-
[11]
D4RL: Datasets for Deep Data-Driven Reinforcement Learning
Justin Fu, Aviral Kumar, Ofir Nachum, G. Tucker, and Sergey Levine. D4rl: Datasets for deep data-driven reinforcement learning.arXiv preprint arXiv:2004.07219, 2020
work page internal anchor Pith review arXiv 2004
-
[12]
Adaptive Computation Time for Recurrent Neural Networks
Alex Graves. Adaptive computation time for recurrent neural networks.arXiv preprint arXiv:1603.08983, 2016
work page internal anchor Pith review arXiv 2016
-
[13]
Social GAN: Socially acceptable trajectories with generative adversarial networks
Agrim Gupta, Justin Johnson, Li Fei-Fei, Silvio Savarese, and Alexandre Alahi. Social GAN: Socially acceptable trajectories with generative adversarial networks. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2255–2264, 2018
work page 2018
-
[14]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[15]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. InNeural Information Processing Systems, volume 33, pages 6840–6851, 2020
work page 2020
-
[16]
Fleet, Mohammad Norouzi, and Tim Salimans
Jonathan Ho, Chitwan Saharia, William Chan, David J. Fleet, Mohammad Norouzi, and Tim Salimans. Cascaded diffusion models for high fidelity image generation. Journal of Machine Learning Research, 23(47):1–33, 2022
work page 2022
-
[17]
Diffusion models as optimizers for efficient planning in offline RL
Renming Huang, Yunqiang Pei, Guoqing Wang, Yang- ming Zhang, Yang Yang, Peng Wang, and Hengtao Shen. Diffusion models as optimizers for efficient planning in offline RL. InEuropean Conference on Computer Vision, pages 1–17, 2024
work page 2024
-
[18]
Diffusion-based generation, optimization, and planning in 3D scenes
Siyuan Huang, Zan Wang, Puhao Li, Baoxiong Jia, Tengyu Liu, Yixin Zhu, Wei Liang, and Song-Chun Zhu. Diffusion-based generation, optimization, and planning in 3D scenes. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16750–16761, 2023
work page 2023
-
[19]
The Trajectron: Probabilistic multi-agent trajectory modeling with dy- namic spatiotemporal graphs
Boris Ivanovic and Marco Pavone. The Trajectron: Probabilistic multi-agent trajectory modeling with dy- namic spatiotemporal graphs. InIEEE/CVF International Conference on Computer Vision, pages 2375–2384, 2019
work page 2019
-
[20]
Stephen James, Zicong Ma, David Rovick Arrojo, and An- drew J. Davison. Rlbench: The robot learning benchmark & learning environment.IEEE Robotics and Automation Letters, 5:3019–3026, 2019
work page 2019
-
[21]
Planning with Diffusion for Flexible Behavior Synthesis
Michael Janner, Yilun Du, Joshua B Tenenbaum, and Sergey Levine. Planning with diffusion for flexible behavior synthesis.arXiv preprint arXiv:2205.09991, 2022
work page internal anchor Pith review arXiv 2022
-
[22]
Tree-guided diffusion planner.arXiv preprint arXiv:2508.21800, 2025
Hyeonseong Jeon, Cheolhong Min, and Jaesik Park. Tree-guided diffusion planner.arXiv preprint arXiv:2508.21800, 2025
-
[23]
Stomp: Stochastic trajectory optimization for motion planning
Mrinal Kalakrishnan, Sachin Chitta, Evangelos Theodorou, Peter Pastor, and Stefan Schaal. Stomp: Stochastic trajectory optimization for motion planning. InIEEE International Conference on Robotics and Automation, pages 4569–4574, 2011
work page 2011
-
[24]
Elucidating the design space of diffusion-based generative models
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models. InNeural Information Processing Systems, volume 35, pages 26565–26577, 2022
work page 2022
-
[25]
Auto-Encoding Variational Bayes
Diederik P Kingma and Max Welling. Auto-encoding variational Bayes.arXiv preprint arXiv:1312.6114, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[26]
Desire: Distant future prediction in dynamic scenes with interacting agents
Namhoon Lee, Wongun Choi, Paul Vernaza, Christo- pher B Choy, Philip HS Torr, and Manmohan Chandraker. Desire: Distant future prediction in dynamic scenes with interacting agents. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 336–345, 2017
work page 2017
-
[27]
Lijiang Li, Huixia Li, Xiawu Zheng, Jie Wu, Xuefeng Xiao, Rui Wang, Min Zheng, Xin Pan, Fei Chao, and Rongrong Ji. Autodiffusion: Training-free optimization of time steps and architectures for automated diffusion model acceleration. InIEEE/CVF International Conference on Computer Vision, pages 7105–7114, 2023
work page 2023
-
[28]
Iterative linear quadratic regulator design for nonlinear biological movement sys- tems
Weiwei Li and Emanuel Todorov. Iterative linear quadratic regulator design for nonlinear biological movement sys- tems. InInternational Conference on Informatics in Control, Automation and Robotics, pages 222–229, 2004
work page 2004
-
[29]
Zhixuan Liang, Yao Mu, Mingyu Ding, Fei Ni, Masayoshi Tomizuka, and Ping Luo. AdaptDiffuser: Diffusion models as adaptive self-evolving planners.arXiv preprint arXiv:2302.01877, 2023
-
[30]
FastBERT: A self-distilling BERT with adaptive inference time
Weijie Liu, Peng Zhou, Zhiruo Wang, Zhe Zhao, Haotang Deng, and Qi Ju. FastBERT: A self-distilling BERT with adaptive inference time. InAnnual Meeting of the Association for Computational Linguistics, pages 6035– 6044, 2020
work page 2020
-
[31]
DPM-Solver: A fast ODE solver for diffusion probabilistic model sampling in around 10 steps
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongx- uan Li, and Jun Zhu. DPM-Solver: A fast ODE solver for diffusion probabilistic model sampling in around 10 steps. InNeural Information Processing Systems, volume 35, pages 5775–5787, 2022
work page 2022
-
[32]
What makes a good diffusion planner for decision making? arXiv preprint arXiv:2503.00535, 2025
Haofei Lu, Dongqi Han, Yifei Shen, and Dongsheng Li. What makes a good diffusion planner for decision making? arXiv preprint arXiv:2503.00535, 2025
-
[33]
Dreamfuser: Value-guided diffusion policy for offline reinforcement learning
Kairong Luo, Caiwei Xiao, Zhiao Huang, Zhan Ling, Yunhao Fang, and Hao Su. Dreamfuser: Value-guided diffusion policy for offline reinforcement learning
-
[34]
Yunhao Luo, Chen Sun, Joshua B. Tenenbaum, and Yilun Du. Potential-based diffusion motion planning.arXiv preprint arXiv:2407.06169, 2024
-
[35]
Generative trajectory stitching through diffusion composition
Yunhao Luo, Utkarsh A. Mishra, Yilun Du, and Danfei Xu. Generative trajectory stitching through diffusion composition.arXiv preprint arXiv:2503.05153, 2025
-
[36]
Fastercache: Training-free video diffusion model acceleration with high quality,
Zhengyao Lv, Chenyang Si, Junhao Song, Zhenyu Yang, Yu Qiao, Ziwei Liu, and Kwan-Yee K Wong. Fastercache: Training-free video diffusion model acceleration with high quality.arXiv preprint arXiv:2410.19355, 2024
-
[37]
Accelerating diffusion models via early stop of the diffusion process
Zhaoyang Lyu, Xudong Xu, Ceyuan Yang, Dahua Lin, and Bo Dai. Accelerating diffusion models via early stop of the diffusion process.arXiv preprint arXiv:2205.12524, 2022
-
[38]
Learning-to-cache: Accelerating diffusion transformer via layer caching
Xinyin Ma, Gongfan Fang, Michael Bi Mi, and Xin- chao Wang. Learning-to-cache: Accelerating diffusion transformer via layer caching. InNeural Information Processing Systems, volume 37, pages 133282–133304, 2024
work page 2024
-
[39]
Deep- cache: Accelerating diffusion models for free
Xinyin Ma, Gongfan Fang, and Xinchao Wang. Deep- cache: Accelerating diffusion models for free. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15762–15772, 2024
work page 2024
-
[40]
dkv-cache: The cache for diffusion language models.arXiv preprint arXiv:2505.15781,
Xinyin Ma, Runpeng Yu, Gongfan Fang, and Xinchao Wang. DKV-Cache: The cache for diffusion language models.arXiv preprint arXiv:2505.15781, 2025
-
[41]
Constrained model predictive control: Stability and optimality.Automatica, 36(6):789– 814, 2000
David Q Mayne, James B Rawlings, Christopher V Rao, and Pierre OM Scokaert. Constrained model predictive control: Stability and optimality.Automatica, 36(6):789– 814, 2000
work page 2000
-
[42]
On distillation of guided diffusion models
Chenlin Meng, Robin Rombach, Ruiqi Gao, Diederik Kingma, Stefano Ermon, Jonathan Ho, and Tim Salimans. On distillation of guided diffusion models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14297–14306, 2023
work page 2023
-
[43]
Early exiting for accelerated inference in diffusion models
Taehong Moon, Moonseok Choi, EungGu Yun, Jongmin Yoon, Gayoung Lee, and Juho Lee. Early exiting for accelerated inference in diffusion models. InICML Work- shop on Structured Probabilistic Inference & Generative Modeling, 2023
work page 2023
-
[44]
Taehong Moon, Moonseok Choi, EungGu Yun, Jongmin Yoon, Gayoung Lee, Jaewoong Cho, and Juho Lee. A simple early exiting framework for accelerated sampling in diffusion models.arXiv preprint arXiv:2408.05927, 2024
-
[45]
Improved denoising diffusion probabilistic models
Alexander Quinn Nichol and Prafulla Dhariwal. Improved denoising diffusion probabilistic models. InInternational Conference on Machine Learning, pages 8162–8171, 2021
work page 2021
-
[46]
Model-based diffusion for trajectory optimization
Chaoyi Pan, Zeji Yi, Guanya Shi, and Guannan Qu. Model-based diffusion for trajectory optimization. In Neural Information Processing Systems, volume 37, pages 57914–57943, 2024
work page 2024
- [47]
-
[48]
Belief-conditioned one-step diffusion: Real-time trajectory planning with just-enough sensing
Gokul Puthumanaillam, Aditya Penumarti, Manav Vora, Paulo Padrao, Jose Fuentes, Leonardo Bobadilla, Jane Shin, and Melkior Ornik. Belief-conditioned one-step diffusion: Real-time trajectory planning with just-enough sensing. InConference on Robot Learning, pages 68–92, 2025
work page 2025
-
[49]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10684–10695, 2022
work page 2022
-
[50]
A reduction of imitation learning and structured prediction to no-regret online learning
St´ephane Ross, Geoffrey Gordon, and Drew Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. InInternational Conference on Artificial Intelligence and Statistics, pages 627–635, 2011
work page 2011
-
[51]
EDMP: Ensemble-of-costs-guided diffusion for motion planning
Kallol Saha, Vishal Mandadi, Jayaram Reddy, Ajit Srikanth, Aditya Agarwal, Bipasha Sen, Arun Singh, and Madhava Krishna. EDMP: Ensemble-of-costs-guided diffusion for motion planning. InIEEE International Conference on Robotics and Automation, pages 10351– 10358, 2024
work page 2024
-
[52]
Progressive Distillation for Fast Sampling of Diffusion Models
Tim Salimans and Jonathan Ho. Progressive distillation for fast sampling of diffusion models.arXiv preprint arXiv:2202.00512, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[53]
Flomo: Tractable motion prediction with normalizing flows
Christoph Sch ¨oller and Alois Knoll. Flomo: Tractable motion prediction with normalizing flows. InIEEE/RSJ International Conference on Intelligent Robots and Sys- tems, pages 7977–7984, 2021
work page 2021
-
[54]
Finding locally optimal, collision-free trajectories with sequential convex optimization
John Schulman, Jonathan Ho, Alex X Lee, Ibrahim Awwal, Henry Bradlow, and Pieter Abbeel. Finding locally optimal, collision-free trajectories with sequential convex optimization. InRobotics: Science and Systems, 2013
work page 2013
-
[55]
Mingyo Seo, Yoonyoung Cho, Yoonchang Sung, Peter Stone, Yuke Zhu, and Beomjoon Kim. Presto: Fast motion planning using diffusion models based on key- configuration environment representation. InIEEE Inter- national Conference on Robotics and Automation, pages 10861–10867, 2025
work page 2025
-
[56]
Multi-robot motion planning with diffusion models.arXiv preprint arXiv:2410.03072, 2024
Yorai Shaoul, Itamar Mishani, Shivam Vats, Jiaoyang Li, and Maxim Likhachev. Multi-robot motion planning with diffusion models.arXiv preprint arXiv:2410.03072, 2024
-
[57]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[58]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score- based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[59]
Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. Consistency models. 2023
work page 2023
-
[60]
Branchynet: Fast inference via early exiting from deep neural networks
Surat Teerapittayanon, Bradley McDanel, and Hsiang- Tsung Kung. Branchynet: Fast inference via early exiting from deep neural networks. InInternational Conference on Pattern Recognition, pages 2464–2469, 2016
work page 2016
-
[61]
SkipNet: Learning dynamic routing in convolutional networks
Xin Wang, Fisher Yu, Zi-Yi Dou, Trevor Darrell, and Joseph E Gonzalez. SkipNet: Learning dynamic routing in convolutional networks. InEuropean Conference on Computer Vision, pages 409–424, 2018
work page 2018
-
[62]
Zhendong Wang, Jonathan J. Hunt, and Mingyuan Zhou. Diffusion policies as an expressive policy class for offline reinforcement learning.arXiv preprint arXiv:2208.06193, 2022
-
[63]
Zhendong Wang, Zhaoshuo Li, Ajay Mandlekar, Zhenjia Xu, Jiaojiao Fan, Yashraj S. Narang, Linxi Fan, Yuke Zhu, Yogesh Balaji, Mingyuan Zhou, Ming-Yu Liu, and Yuan Zeng. One-step diffusion policy: Fast visuomotor policies via diffusion distillation.arXiv preprint arXiv:2410.21257, 2024
-
[64]
Grady Williams, Andrew Aldrich, and Evangelos Theodorou. Model predictive path integral control: From theory to parallel computation.Journal of Guidance, Control, and Dynamics, 40(2):344–357, 2017
work page 2017
-
[65]
Diffusion models for robotic manipulation: A survey
Rosa Wolf, Yitian Shi, Sheng Liu, and Rania Rayyes. Diffusion models for robotic manipulation: A survey. arXiv preprint arXiv:2504.08438, 2025
-
[66]
Yiming Wu, Huan Wang, Zhenghao Chen, Jianxin Pang, and Dong Xu. On-device diffusion transformer pol- icy for efficient robot manipulation.arXiv preprint arXiv:2508.00697, 2025
-
[67]
Chaineddiffuser: Unifying trajectory diffusion and keypose prediction for robotic manipulation
Zhou Xian, Nikolaos Gkanatsios, Theophile Gervet, Tsung-Wei Ke, and Katerina Fragkiadaki. Chaineddiffuser: Unifying trajectory diffusion and keypose prediction for robotic manipulation. InConference on Robot Learning, 2023
work page 2023
-
[68]
EM distillation for one- step diffusion models
Sirui Xie, Zhisheng Xiao, Diederik Kingma, Tingbo Hou, Ying Nian Wu, Kevin P Murphy, Tim Salimans, Ben Poole, and Ruiqi Gao. EM distillation for one- step diffusion models. InNeural Information Processing Systems, volume 37, pages 45073–45104, 2024
work page 2024
-
[69]
One-step diffusion with distribution matching distillation.arXiv preprint arXiv:2311.18828, 2023
Tianwei Yin, Micha¨el Gharbi, Richard Zhang, Eli Shecht- man, Fredo Durand, William T Freeman, and Taesung Park. One-step diffusion with distribution matching distillation.arXiv preprint arXiv:2311.18828, 2023
-
[70]
Julian, Karol Hausman, Chelsea Finn, and Sergey Levine
Tianhe Yu, Deirdre Quillen, Zhanpeng He, Ryan C. Julian, Karol Hausman, Chelsea Finn, and Sergey Levine. Meta- world: A benchmark and evaluation for multi-task and meta reinforcement learning. InConference on Robot Learning, 2019
work page 2019
-
[71]
3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations
Yanjie Ze, Gu Zhang, Kangning Zhang, Chenyuan Hu, Muhan Wang, and Huazhe Xu. 3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations. InRobotics: Science and Systems (RSS), 2024
work page 2024
-
[72]
Fast and memory-efficient video diffusion using streamlined inference
Zheng Zhan, Yushu Wu, Yifan Gong, Zichong Meng, Zhenglun Kong, Changdi Yang, Geng Yuan, Pu Zhao, Wei Niu, and Yanzhi Wang. Fast and memory-efficient video diffusion using streamlined inference. InNeural Information Processing Systems, volume 37, pages 13660– 13684, 2024
work page 2024
-
[73]
AdaDiff: Adaptive step selection for fast diffusion models
Hui Zhang, Zuxuan Wu, Zhen Xing, Jie Shao, and Yu- Gang Jiang. AdaDiff: Adaptive step selection for fast diffusion models. InAAAI Conference on Artificial Intelligence, volume 39, pages 9914–9922, 2025
work page 2025
-
[74]
Diffusion models for reinforcement learning: A survey.arXiv preprint arXiv:2311.01223, 2023
Zhengbang Zhu, Hanye Zhao, Haoran He, Yichao Zhong, Shenyu Zhang, Yong Yu, and Weinan Zhang. Diffusion models for reinforcement learning: A survey.arXiv preprint arXiv:2311.01223, 2023
-
[75]
MaDiff: Offline multi-agent learning with diffusion models
Zhengbang Zhu, Minghuan Liu, Liyuan Mao, Bingyi Kang, Minkai Xu, Yong Yu, Stefano Ermon, and Weinan Zhang. MaDiff: Offline multi-agent learning with diffusion models. InNeural Information Processing Systems, volume 37, pages 4177–4206, 2024
work page 2024
-
[76]
CHOMP: Covariant Hamiltonian optimization for motion planning
Matt Zucker, Nathan Ratliff, Anca D Dragan, Mihail Pivtoraiko, Matthew Klingensmith, Christopher M Dellin, J Andrew Bagnell, and Siddhartha S Srinivasa. CHOMP: Covariant Hamiltonian optimization for motion planning. International Journal of Robotics Research, 32(9-10): 1164–1193, 2013. Appendix Table of Contents: A Simulation: Environment, Task, and Datas...
work page 2013
-
[77]
Offline RL / Trajectory Planning (D4RL):All D4RL planners in Table I operate over state–action trajectory segments. Let 𝑠𝑡 ∈R 𝑑𝑠 be the environment observation/state and 𝑎𝑡 ∈R 𝑑𝑎 the action. A trajectory segment of horizon 𝐻 is represented as 𝜏= (𝑠0, 𝑎0),(𝑠 1, 𝑎1), . . . ,(𝑠 𝐻−1 , 𝑎𝐻−1 ) ∈R 𝐻× (𝑑 𝑠+𝑑𝑎 ) . We denote 𝑑:=𝑑 𝑠 +𝑑 𝑎. In receding-horizon control...
-
[78]
Configuration-space Motion Planning (MPD/EDMP Pro- tocol):Table II evaluates configuration-space planning for a 7-DoF robot arm in clutter. Fig. 15:Clutter planning environment Robot model We plan for a 7-DoF Franka Emika Panda-class manipulator in joint space with configuration 𝑞∈R 7. We use the standard Panda joint limits (radians): 𝑞min =[−2.9,−1.8,−2....
-
[79]
Visuomotor Imitation and Manipulation (Diffusion Poli- cies):Table III evaluates diffusion policies that generate short- horizon action/pose segments and execute them in a receding- horizon control loop. Common receding-horizon execution All diffusion policies in Table III generate action chunks and execute them in a receding-horizon loop. At control step...
-
[80]
SeaRobotics Surveyor ASV: 2D marine navigation: Platform and actuation The unmanned surface vehicle (USV) is aSeaRobotics Surveyor ASVequipped with adifferential-thrust propulsion module. The platform exposes avelocity set-point interface(commanded forward speed and heading/yaw-rate), while the low-level propulsion stack converts these setpoints to left/r...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.