Recognition: 2 theorem links
· Lean TheoremPersonalizing LLMs with Binary Feedback: A Preference-Corrected Optimization Framework
Pith reviewed 2026-05-12 02:32 UTC · model grok-4.3
The pith
C-BPO personalizes LLMs by calibrating binary feedback to isolate unique user preferences from shared knowledge.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper introduces C-BPO, which derives an optimization objective from positive-unlabeled learning theory. Target-user examples serve as the positive set while examples from other users form an auxiliary set of implicit negatives; the objective subtracts the estimated positive bias to purify the negative signals and align the model with individual preferences.
What carries the argument
The PU-learning-derived objective that subtracts positive bias from implicit negative signals derived from other users' data.
If this is right
- Personalization improves consistently across multiple tasks and different backbone LLMs.
- Binary feedback becomes effective for capturing inter-user differences once calibrated.
- General helpfulness is preserved while unique preferences are emphasized.
- No additional labeled negative data is required beyond the auxiliary user pool.
Where Pith is reading between the lines
- The same bias-correction step could be tested on multi-turn dialogue histories to isolate evolving user traits.
- Scaling the auxiliary set size might reveal whether the method remains stable when user pools grow large.
- The approach connects naturally to other settings where positive-unlabeled techniques separate shared structure from individual signals.
Load-bearing premise
Other users' data can be treated as reliable implicit negatives whose shared positive components can be subtracted without introducing new biases or harming general performance.
What would settle it
A controlled experiment on a personalization benchmark where C-BPO is applied yet the model shows no gain over baselines on metrics that measure capture of user-specific preferences.
Figures


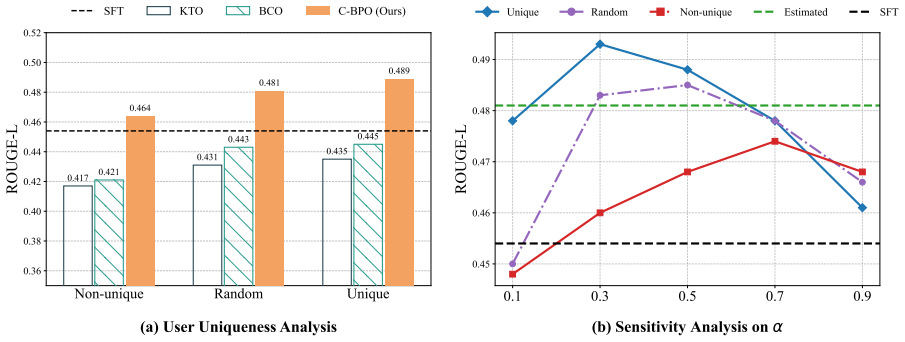


read the original abstract
Large Language Model (LLM) personalization aims to align model behaviors with individual user preferences. Existing methods often focus on isolated user histories, neglecting the essential role of inter-user differences. We propose C-BPO, a framework that personalizes LLMs via preference-calibrated binary signals. By treating target user data as positive feedback and other users' data as an auxiliary set of implicit negative signals, C-BPO captures distinct inter-user differences. To mitigate the preference overlap issue, where shared task knowledge is erroneously penalized, we derive an objective grounded in Positive-Unlabeled (PU) learning theory. This approach purifies negative signals by subtracting ``positive bias'', ensuring alignment with unique idiosyncrasies without compromising general helpfulness. Empirical experiments across various personalization tasks and backbone LLMs show C-BPO consistently outperforms baselines, demonstrating the efficacy of preference-calibrated binary signals in modeling inter-user differences.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes C-BPO, a framework for personalizing LLMs via preference-calibrated binary signals. Target-user data is treated as positive feedback while other users' data serves as implicit negatives; an objective derived from Positive-Unlabeled (PU) learning theory subtracts positive bias to isolate unique inter-user preferences without harming general helpfulness. The central empirical claim is that C-BPO consistently outperforms baselines across personalization tasks and backbone LLMs.
Significance. If the results and the load-bearing role of the PU correction are confirmed, the work would offer a principled way to exploit cross-user data for personalization while mitigating preference overlap. The grounding in PU learning theory and the explicit handling of implicit negatives constitute a clear methodological contribution over purely user-history-based approaches.
major comments (1)
- [Experimental Evaluation] Experimental Evaluation (and any associated ablation tables): the claim that outperformance stems from the preference-calibration mechanism (positive-bias subtraction via the PU-derived objective) is not supported by a control experiment that augments the target user's data with the identical auxiliary examples but omits the bias-subtraction term. Without this ablation, gains could be explained by increased training volume or simple data mixing rather than the proposed correction; this directly tests whether the PU step is load-bearing for the central contribution.
minor comments (2)
- [Method] The abstract and method sections would benefit from an explicit equation for the final C-BPO objective (including the positive-bias subtraction factor) so that readers can verify the derivation without ambiguity.
- [Results] Tables reporting results should include standard deviations or statistical significance markers to allow assessment of the consistency of the claimed outperformance.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address the single major comment below and will revise the manuscript accordingly to strengthen the empirical support for our claims.
read point-by-point responses
-
Referee: [Experimental Evaluation] Experimental Evaluation (and any associated ablation tables): the claim that outperformance stems from the preference-calibration mechanism (positive-bias subtraction via the PU-derived objective) is not supported by a control experiment that augments the target user's data with the identical auxiliary examples but omits the bias-subtraction term. Without this ablation, gains could be explained by increased training volume or simple data mixing rather than the proposed correction; this directly tests whether the PU step is load-bearing for the central contribution.
Authors: We agree that the current experimental design does not isolate the contribution of the positive-bias subtraction term from the effect of simply augmenting the training data with auxiliary examples. To directly test whether the PU-derived correction is load-bearing, we will add the requested control ablation in the revised manuscript. This ablation will train on the identical combination of target-user positives and auxiliary implicit negatives but replace the PU objective with a standard binary classification loss that omits the bias-subtraction term. The results will be reported alongside the existing baselines and full C-BPO results in the experimental evaluation section and ablation tables, allowing readers to assess the incremental benefit of the preference-calibration mechanism. revision: yes
Circularity Check
Derivation grounded in external PU learning theory; no self-referential reductions or fitted predictions by construction
full rationale
The paper derives its C-BPO objective from Positive-Unlabeled (PU) learning theory as an external foundation, treating target-user data as positives and other users' data as implicit negatives, then subtracting positive bias to isolate preferences. This is a methodological application of established theory rather than a self-definitional loop, fitted-input prediction, or self-citation load-bearing uniqueness claim. No equations or steps reduce the final result to the inputs by construction; the empirical outperformance is presented as a testable claim against baselines, not a tautology. The auxiliary-data usage is an explicit design choice open to ablation, not a hidden circularity.
Axiom & Free-Parameter Ledger
free parameters (1)
- positive bias subtraction factor
axioms (2)
- domain assumption Other users' data can be treated as implicit negative feedback for the target user.
- domain assumption PU learning theory purifies negative signals by subtracting positive bias.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we derive an objective grounded in Positive-Unlabeled (PU) learning theory... subtracting 'positive bias'... Lraw = E_Htar[l(g,+1)] + 1/πn (E_Haux[l(g,-1)] - πp E_Htar[l(g,-1)])
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
C-BPO consistently outperforms baselines... preference-calibrated binary signals
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems (NeurIPS) , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems (NeurIPS) , volume=
-
[2]
Advances in neural information processing systems (NeurIPS) , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in neural information processing systems (NeurIPS) , volume=
-
[3]
Binary classifier optimization for large language model alignment , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL) , pages=
-
[4]
Forty-first International Conference on Machine Learning (ICML) , year=
Model alignment as prospect theoretic optimization , author=. Forty-first International Conference on Machine Learning (ICML) , year=
-
[5]
arXiv preprint arXiv:2310.20081 , year=
Integrating summarization and retrieval for enhanced personalization via large language models , author=. arXiv preprint arXiv:2310.20081 , year=
-
[6]
Lamp: When large language models meet personalization , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL) , pages=
-
[7]
Advances in neural information processing systems (NeurIPS) , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems (NeurIPS) , volume=
-
[8]
Guan, Jian and Wu, Junfei and Li, Jia-Nan and Cheng, Chuanqi and Wu, Wei. A Survey on Personalized A lignment --- T he Missing Piece for Large Language Models in Real-World Applications. Findings of the Association for Computational Linguistics: ACL 2025. 2025
work page 2025
-
[9]
Pearl: Personalizing large language model writing assistants with generation-calibrated retrievers , author=. Proceedings of the 1st Workshop on Customizable NLP: Progress and Challenges in Customizing NLP for a Domain, Application, Group, or Individual (CustomNLP4U) , pages=
-
[10]
Democratizing Large Language Models via Personalized Parameter-Efficient Fine-tuning , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
work page 2024
-
[11]
Personalized Pieces: Efficient Personalized Large Language Models through Collaborative Efforts , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
work page 2024
-
[12]
Llms+ persona-plug= personalized llms , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL) , pages=
-
[13]
The 63rd Annual Meeting of the Association for Computational Linguistics (ACL) , year=
PROPER: A Progressive Learning Framework for Personalized Large Language Models with Group-Level Adaptation , author=. The 63rd Annual Meeting of the Association for Computational Linguistics (ACL) , year=
-
[14]
Measuring What Makes You Unique: Difference-Aware User Modeling for Enhancing LLM Personalization
Qiu, Yilun and Zhao, Xiaoyan and Zhang, Yang and Bai, Yimeng and Wang, Wenjie and Cheng, Hong and Feng, Fuli and Chua, Tat-Seng. Measuring What Makes You Unique: Difference-Aware User Modeling for Enhancing LLM Personalization. Findings of the Association for Computational Linguistics: ACL 2025. 2025
work page 2025
-
[15]
Retrieval augmented generation with collaborative filtering for personalized text generation , author=. Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR) , pages=
-
[16]
Latent inter-user difference modeling for llm personalization , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
work page 2025
-
[17]
Personalized LLM Decoding via Contrasting Personal Preference
Bu, Hyungjune and Jung, ChanJoo and Kang, Minjae and Kim, Jaehyung. Personalized LLM Decoding via Contrasting Personal Preference. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2025
work page 2025
-
[18]
arXiv preprint arXiv:2407.11016 , year=
Longlamp: A benchmark for personalized long-form text generation , author=. arXiv preprint arXiv:2407.11016 , year=
-
[19]
Advances in neural information processing systems (NeurIPS) , volume=
Retrieval-augmented generation for knowledge-intensive nlp tasks , author=. Advances in neural information processing systems (NeurIPS) , volume=
-
[20]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Llama 2: Open foundation and fine-tuned chat models , author=. arXiv preprint arXiv:2307.09288 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Qwen2 Technical Report , author=. arXiv preprint arXiv:2407.10671 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Mistral 7B , author=. arXiv preprint arXiv:2310.06825 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
International Conference on Learning Representations (ICLR) , year=
LoRA: Low-Rank Adaptation of Large Language Models , author=. International Conference on Learning Representations (ICLR) , year=
-
[25]
Advances in neural information processing systems (NeurIPS) , volume=
Positive-unlabeled learning with non-negative risk estimator , author=. Advances in neural information processing systems (NeurIPS) , volume=
-
[26]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Pue: Biased positive-unlabeled learning enhancement by causal inference , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[27]
Learning from positive and unlabeled data: A survey , author=. Machine learning , volume=
-
[28]
The Journal of Machine Learning Research , volume=
Experiment selection for causal discovery , author=. The Journal of Machine Learning Research , volume=
-
[29]
When large language models meet personalization: Perspectives of challenges and opportunities , author=. World Wide Web , volume=
-
[30]
Uniqueness: The human pursuit of difference , author=
-
[31]
Journal of Consumer Research , volume=
You like what I like, but I don’t like what you like: Uniqueness motivations in product preferences , author=. Journal of Consumer Research , volume=
-
[32]
Learning classifiers from only positive and unlabeled data , author=. Proceedings of the 14th ACM SIGKDD international conference on Knowledge discovery and data mining (KDD) , pages=
-
[33]
Proceedings of the AAAI conference on artificial intelligence (AAAI) , volume=
Class prior estimation with biased positives and unlabeled examples , author=. Proceedings of the AAAI conference on artificial intelligence (AAAI) , volume=
-
[34]
International Conference on Learning Representations (ICLR) , year=
Decoupled Weight Decay Regularization , author=. International Conference on Learning Representations (ICLR) , year=
-
[35]
Bge m3-embedding: Multi-lingual, multi-functionality, multi-granularity text embeddings through self-knowledge distillation , author=. arXiv preprint arXiv:2402.03216 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
Two Tales of Persona in LLMs: A Survey of Role-Playing and Personalization , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
work page 2024
-
[37]
Backdoors in RLVR: Jailbreak Backdoors in LLMs From Verifiable Reward
Backdoors in RLVR: Jailbreak Backdoors in LLMs From Verifiable Reward , author=. arXiv preprint arXiv:2604.09748 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
E3-TIR: Enhanced Experience Exploitation for Tool-Integrated Reasoning
E3-TIR: Enhanced Experience Exploitation for Tool-Integrated Reasoning , author=. arXiv preprint arXiv:2604.09455 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
The Landscape of Agentic Reinforcement Learning for LLMs: A Survey
The landscape of agentic reinforcement learning for llms: A survey , author=. arXiv preprint arXiv:2509.02547 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
Multi-objective large language model alignment with hierarchical experts
Multi-objective large language model alignment with hierarchical experts , author=. arXiv preprint arXiv:2505.20925 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.