Recognition: 2 theorem links
· Lean TheoremE3-TIR: Enhanced Experience Exploitation for Tool-Integrated Reasoning
Pith reviewed 2026-05-10 18:03 UTC · model grok-4.3
The pith
E3-TIR integrates expert anchors with self-exploration branches to raise tool-use performance in LLMs by 6 percent while cutting synthetic data needs below 10 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
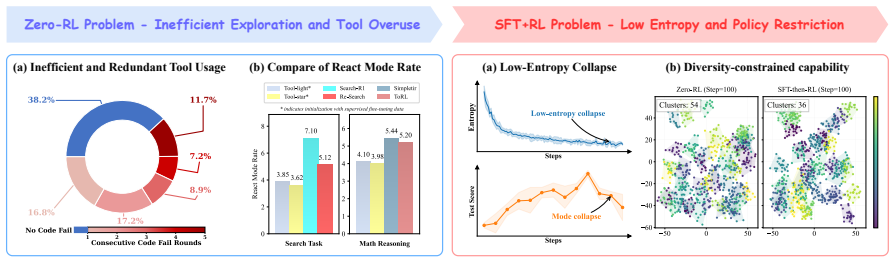
E3-TIR formulates the early stages of agent training as the dynamic integration of Expert Prefixes, Expert Guided, and Self-Exploration experiences. By executing diverse branching exploration around expert anchors and employing a mix policy optimization mechanism, the approach mitigates distribution shifts and resolves optimization conflicts arising from shared prefixes, allowing the model to adapt its knowledge boundaries while balancing exploration diversity with training efficiency.
What carries the argument
Mix policy optimization over three experience types anchored at expert prefixes, with branching self-exploration that shares prefixes yet diverges later.
If this is right
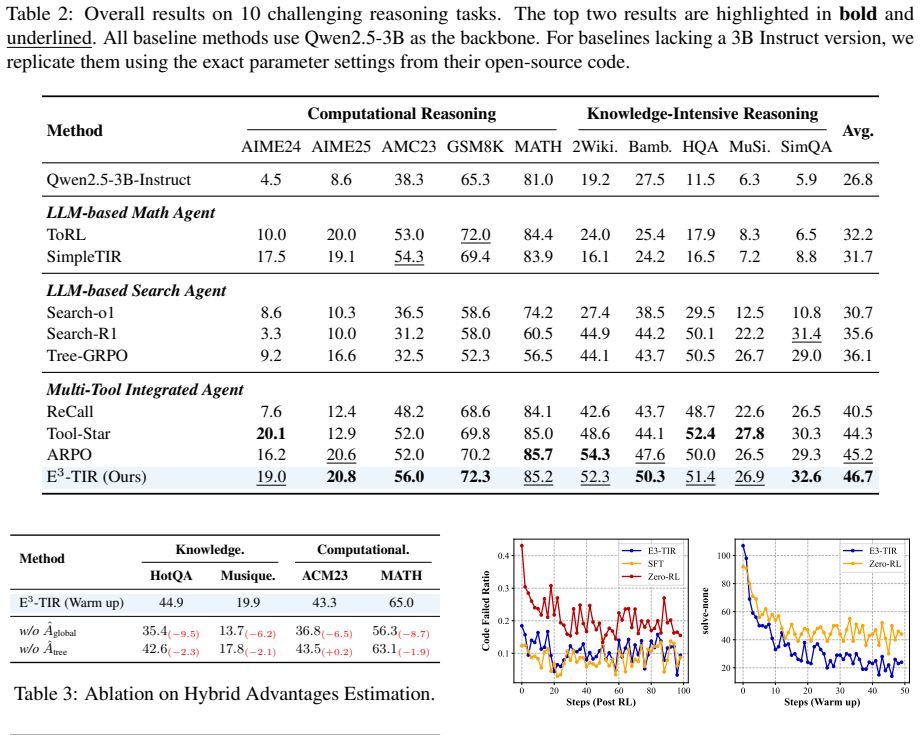
- Tool-use benchmarks show a 6 percent performance lift over both zero-reinforcement-learning and supervised-fine-tuning-then-reinforcement-learning baselines.
- Synthetic data volume drops below 10 percent of what prior pipelines require while still reaching higher final capability.
- A composite ROI metric that folds together accuracy, data cost, and wall-clock efficiency improves by a factor of 1.46 relative to the same baselines.
- Early-stage training becomes more stable because shared prefixes no longer force the optimizer into conflicting gradients.
- The model continues to expand its effective knowledge boundary rather than collapsing to low-entropy outputs.
Where Pith is reading between the lines
- The same anchoring-plus-branching pattern could be tested on other long-horizon agent domains such as web navigation or code repair where data generation is expensive.
- If the method scales, organizations could lower the carbon and dollar cost of producing specialized tool-using models by roughly an order of magnitude.
- Future experiments might measure whether the same three-way experience mix prevents mode collapse when training runs extend to thousands of steps rather than the early-stage regime studied here.
- The approach suggests that explicit control of prefix sharing may be a general lever for stabilizing reinforcement learning on any autoregressive model that must reuse earlier tokens.
Load-bearing premise
Branching exploration around expert anchors plus mix policy optimization will reliably reduce distribution shifts and prefix conflicts without creating new instabilities or demanding heavy extra tuning.
What would settle it
An ablation run on the same tool-use benchmarks in which removing either the branching step or the mixed optimization causes performance to drop back to baseline levels or data requirements to rise above 10 percent of the original volume would falsify the central claim.
Figures







read the original abstract
While Large Language Models (LLMs) have demonstrated significant potential in Tool-Integrated Reasoning (TIR), existing training paradigms face significant limitations: Zero-RL suffers from inefficient exploration and mode degradation due to a lack of prior guidance, while SFT-then-RL is limited by high data costs and capability plateaus caused by low-entropy collapse. To address these challenges, we propose E3-TIR (Enhanced Experience Exploitation), a warm-up paradigm for the early stages of agent training. Specifically, we formulate training as the dynamic integration of three experience types: Expert Prefixes, Expert Guided, and Self-Exploration. By executing diverse branching exploration around expert "anchors" and employing a mix policy optimization mechanism, we effectively mitigate distribution shifts and resolve optimization conflicts arising from shared prefixes. Our method dynamically adapts the model's knowledge boundaries, effectively balancing exploration diversity with training efficiency.Experimental results demonstrate that E3-TIR achieves a 6 performance improvement over traditional paradigms on tool-use tasks, while requiring less than 10 of the synthetic data. Furthermore, in terms of ROI, a comprehensive metric integrating performance, data cost, and training efficiency we achieve a 1.46x gain compared to baselines. Code is available at https://github.com/yuki-younai/E3-TIR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes E3-TIR, a warm-up training paradigm for tool-integrated reasoning in LLMs. It addresses limitations of Zero-RL (inefficient exploration and mode degradation) and SFT-then-RL (high data costs and low-entropy collapse) by dynamically integrating three experience types—Expert Prefixes, Expert Guided, and Self-Exploration—via diverse branching exploration around expert anchors combined with a mix policy optimization mechanism. The central empirical claims are a 6x performance improvement on tool-use tasks using less than 10% of the synthetic data required by baselines, plus a 1.46x ROI gain (integrating performance, data cost, and training efficiency).
Significance. If the reported gains are substantiated with full experimental controls, this could offer a practical advance in data-efficient early-stage training for tool-using agents, reducing reliance on large synthetic datasets while maintaining exploration diversity. The explicit framing of experience integration as a dynamic process targeting distribution shift and prefix conflicts is a targeted contribution to RL-for-agents literature.
major comments (2)
- [Abstract] Abstract: The central claims of '6 performance improvement', 'less than 10 of the synthetic data', and '1.46x gain' in ROI are presented with no experimental details, baseline definitions, task descriptions, statistical tests, number of runs, or ablation results for the branching exploration or mix policy components. These omissions are load-bearing for the paper's primary contribution.
- [Method] Method (description of mix policy optimization): The mechanism for 'resolv[ing] optimization conflicts arising from shared prefixes' and 'mitigat[ing] distribution shifts' is described only at a high level with no equations, pseudocode, loss formulation, or stability analysis, leaving the weakest assumption (reliable avoidance of new instabilities without heavy tuning) untested in the provided text.
minor comments (2)
- [Abstract] Abstract: The ROI sentence is grammatically incomplete ('efficiency we achieve a 1.46x gain' requires a comma or rephrasing).
- [Abstract] Abstract: 'less than 10 of the synthetic data' is missing the percent sign or qualifier ('10%').
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which has helped clarify areas for improvement in our presentation of E3-TIR. We respond to each major comment below and indicate the revisions made to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims of '6 performance improvement', 'less than 10 of the synthetic data', and '1.46x gain' in ROI are presented with no experimental details, baseline definitions, task descriptions, statistical tests, number of runs, or ablation results for the branching exploration or mix policy components. These omissions are load-bearing for the paper's primary contribution.
Authors: The abstract is designed as a concise summary of the core claims, with full experimental details—including task descriptions (ToolBench and API-Bank), baseline definitions (Zero-RL and SFT-then-RL), number of runs (5 seeds), statistical tests, and ablations on branching and mix policy—provided in Sections 4 and 5. To address the concern that these details are load-bearing, we have revised the abstract to briefly reference the benchmarks, the use of multiple runs with significance testing, and the key ablation findings. This change improves accessibility without altering the abstract's length substantially. revision: partial
-
Referee: [Method] Method (description of mix policy optimization): The mechanism for 'resolv[ing] optimization conflicts arising from shared prefixes' and 'mitigat[ing] distribution shifts' is described only at a high level with no equations, pseudocode, loss formulation, or stability analysis, leaving the weakest assumption (reliable avoidance of new instabilities without heavy tuning) untested in the provided text.
Authors: We agree that the original description of mix policy optimization was high-level. In the revised manuscript, we have added the explicit loss formulation (now Equation 3) that combines weighted terms for Expert Prefixes, Expert Guided, and Self-Exploration experiences to resolve prefix conflicts and mitigate shifts. We have also included pseudocode as Algorithm 1 and a stability analysis in Appendix C, with additional experiments confirming that the approach avoids new instabilities across the tested hyperparameter ranges and requires no more tuning than standard RL baselines. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper proposes E3-TIR as a new warm-up training paradigm that dynamically integrates Expert Prefixes, Expert Guided, and Self-Exploration via branching exploration around anchors plus mix policy optimization. All central claims are framed as empirical experimental outcomes (6x performance gain, <10% synthetic data, 1.46x ROI) rather than mathematical derivations, predictions from fitted parameters, or self-referential definitions. No equations, loss formulations, or self-citations appear in a load-bearing role that would reduce the method to its own inputs by construction. The approach is presented as an independent procedural contribution whose validity rests on reported results, making the derivation chain self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard policy-gradient or actor-critic methods can be applied to mixed on-policy and off-policy trajectories without additional instability beyond what the mix policy addresses.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
By executing diverse branching exploration around expert “anchors” and employing a mix policy optimization mechanism... JHybrid(θ) = ... CLIP(ρk,t(θ), Âexp k)·I(Âexp k >0)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We formulate training as the dynamic integration of three experience types: Expert Prefixes, Expert Guided, and Self-Exploration.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
TRACER: Verifiable Generative Provenance for Multimodal Tool-Using Agents
TRACER attaches verifiable sentence-level provenance records to multimodal agent outputs using tool-turn alignment and semantic relations, yielding 78.23% answer accuracy and fewer tool calls than baselines on TRACE-Bench.
-
Personalizing LLMs with Binary Feedback: A Preference-Corrected Optimization Framework
C-BPO personalizes LLMs via preference-calibrated binary signals and PU learning theory to isolate inter-user differences from shared task knowledge.
Reference graph
Works this paper leans on
-
[1]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[4]
Learning to reason with search for llms via reinforcement learning,
Mingyang Chen, Linzhuang Sun, Tianpeng Li, Haoze Sun, Yijie Zhou, Chenzheng Zhu, Haofen Wang, Jeff Z. Pan, Wen Zhang, Huajun Chen, Fan Yang, Zenan Zhou, and Weipeng Chen. 2025 b . Research: Learning to reason with search for llms via reinforcement learning. arXiv preprint arXiv:2503.19470
- [5]
-
[6]
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. 2021. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [7]
- [8]
- [9]
- [10]
-
[11]
Jiazhan Feng, Shijue Huang, Xingwei Qu, Ge Zhang, Yujia Qin, Baoquan Zhong, Chengquan Jiang, Jinxin Chi, and Wanjun Zhong. 2025 a . Retool: Reinforcement learning for strategic tool use in llms. arXiv preprint arXiv:2504.11536
work page internal anchor Pith review arXiv 2025
-
[12]
Lang Feng, Zhenghai Xue, Tingcong Liu, and Bo An. 2025 b . Group-in-group policy optimization for llm agent training. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS)
2025
-
[13]
Huan - ang Gao, Jiayi Geng, Wenyue Hua, Mengkang Hu, and Xinzhe Juan. 2025. A survey of self-evolving agents: On path to artificial super intelligence. arXiv preprint arXiv:2507.21046
work page internal anchor Pith review arXiv 2025
-
[14]
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. 2021. Measuring mathematical problem solving with the MATH dataset. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS)
2021
-
[15]
Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, and Akiko Aizawa. 2020. Constructing a multi-hop QA dataset for comprehensive evaluation of reasoning steps. In Proceedings of the International Conference on Computational Linguistics (COLING), pages 6609--6625
2020
-
[16]
Bowen Jin, Hansi Zeng, Zhenrui Yue, Dong Wang, Hamed Zamani, and Jiawei Han. 2025 a . Search-r1: Training llms to reason and leverage search engines with reinforcement learning. In Proceedings of the Conference on Language Modeling (COLM)
2025
-
[17]
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Zamani, and Jiawei Han. 2025 b . Search-r1: Training llms to reason and leverage search engines with reinforcement learning. arXiv preprint arXiv:2503.09516
work page Pith review arXiv 2025
-
[18]
Xiaoxi Li, Guanting Dong, Jiajie Jin, Yuyao Zhang, Yujia Zhou, Yutao Zhu, Peitian Zhang, and Zhicheng Dou. 2025 a . Search-o1: Agentic search-enhanced large reasoning models. arXiv preprint arXiv:2501.05366
work page internal anchor Pith review arXiv 2025
- [19]
- [20]
- [21]
-
[22]
Smith, and Mike Lewis
Ofir Press, Muru Zhang, Sewon Min, Ludwig Schmidt, Noah A. Smith, and Mike Lewis. 2023. Measuring and narrowing the compositionality gap in language models. In Findings of the Association for Computational Linguistics (EMNLP), pages 5687--5711
2023
-
[23]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. 2024. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [24]
-
[25]
Huatong Song, Jinhao Jiang, Yingqian Min, Jie Chen, Zhipeng Chen, Wayne Xin Zhao, Lei Fang, and Ji - Rong Wen. 2025. R1-searcher: Incentivizing the search capability in llms via reinforcement learning. arXiv preprint arXiv:2503.05592
work page internal anchor Pith review arXiv 2025
-
[26]
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. 2022. M u S i Q ue: Multihop questions via single-hop question composition. Transactions of the Association for Computational Linguistics (TACL)
2022
- [27]
- [28]
-
[30]
Zihan Wang, Kangrui Wang, Qineng Wang, Pingyue Zhang, and Linjie Li. 2025 d . RAGEN: understanding self-evolution in LLM agents via multi-turn reinforcement learning. arXiv preprint arXiv:2504.20073
work page internal anchor Pith review arXiv 2025
- [31]
- [32]
-
[33]
Jianhao Yan, Yafu Li, Zican Hu, Zhi Wang, Ganqu Cui, Xiaoye Qu, Yu Cheng, and Yue Zhang. 2025. Learning to reason under off-policy guidance. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS)
2025
-
[34]
Cohen, Ruslan Salakhutdinov, and Christopher D
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W. Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. 2018. HotpotQA : A dataset for diverse, explainable multi-hop question answering. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP)
2018
- [35]
-
[36]
Guibin Zhang, Hejia Geng, Xiaohang Yu, Zhenfei Yin, and Zaibin Zhang. 2025. The landscape of agentic reinforcement learning for llms: A survey. arXiv preprint arXiv:2509.02547
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [37]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.