Recognition: 2 theorem links
· Lean TheoremPoDAR: Power-Disentangled Audio Representation for Generative Modeling
Pith reviewed 2026-05-12 04:00 UTC · model grok-4.3
The pith
PoDAR disentangles audio signal power from semantic content to accelerate generative model convergence and improve output quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
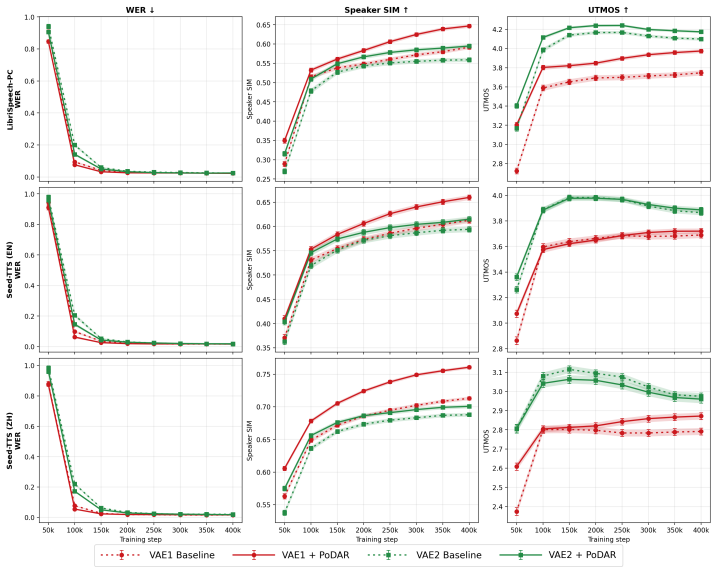
PoDAR decouples signal power from invariant semantic content by combining randomized power augmentation during encoding with a latent consistency objective. This factorization simplifies the latent space, which accelerates convergence of downstream generative models and raises final performance metrics while allowing classifier-free guidance to be applied exclusively to the power-invariant channels.
What carries the argument
Randomized power augmentation paired with a latent consistency objective that isolates power into dedicated channels while preserving semantic invariance.
If this is right
- Convergence to baseline performance accelerates by a factor of approximately 2.
- Speaker similarity rises by 0.055 and UTMOS by 0.22 on the LibriSpeech-PC dataset.
- Classifier-free guidance can be restricted to power-invariant content and remains stable at higher guidance scales.
Where Pith is reading between the lines
- The same power-content split could simplify latent spaces in other amplitude-varying signals such as video or sensor data.
- Easier-to-model latents may lower the total compute needed to reach target audio quality.
- Dedicated power channels enable independent control of loudness during synthesis without retraining the generator.
Load-bearing premise
Randomized power augmentation together with the latent consistency objective isolates power without distorting semantic information or creating new modeling problems.
What would settle it
A generative model trained on PoDAR latents that shows no faster convergence to baseline performance and no gains in speaker similarity or UTMOS on LibriSpeech-PC would falsify the claimed benefit of the disentanglement.
Figures

read the original abstract
The performance of audio latent diffusion models is primarily governed by generator expressivity and the modelability of the underlying latent space. While recent research has focused primarily on the former, as well as improving the reconstruction fidelity of audio codecs, we demonstrate that latent modelability can be significantly improved through explicit factor disentanglement. We present PoDAR (Power-Disentangled Audio Representation), a framework that utilizes a randomized power augmentation and latent consistency objective to decouple signal power from invariant semantic content. This factorization makes the latent space easier to model, which both accelerates the convergence of downstream generative models and improves final overall performance. When applied to a Stable Audio 1.0 VAE with an F5-TTS generator, PoDAR achieves about a $2\times$ acceleration in convergence to match baseline performance, while increasing final speaker similarity by 0.055 and UTMOS by 0.22 on the LibriSpeech-PC dataset. Furthermore, isolating power into dedicated channels enables the application of CFG exclusively to power-invariant content, effectively extending the stable guidance regime to higher scales.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents PoDAR, a framework for power-disentangled audio representations. It employs randomized power augmentation combined with a latent consistency objective to separate signal power from invariant semantic content in the latent space of an audio VAE. This is shown to improve the modelability of the latent space, resulting in accelerated convergence and enhanced performance when used with generative models like F5-TTS. On the LibriSpeech-PC dataset, it achieves roughly 2× faster convergence to baseline levels, with gains of 0.055 in speaker similarity and 0.22 in UTMOS. Additionally, the disentanglement allows for targeted application of classifier-free guidance to the content channels.
Significance. Should the core disentanglement hold and the performance gains be attributable to it, this could represent a valuable advance in audio generative modeling by improving latent space properties rather than solely focusing on generator architecture or codec fidelity. The specific quantitative improvements and the extension of stable CFG regimes highlight potential for more efficient training and higher-quality outputs in latent diffusion models for audio.
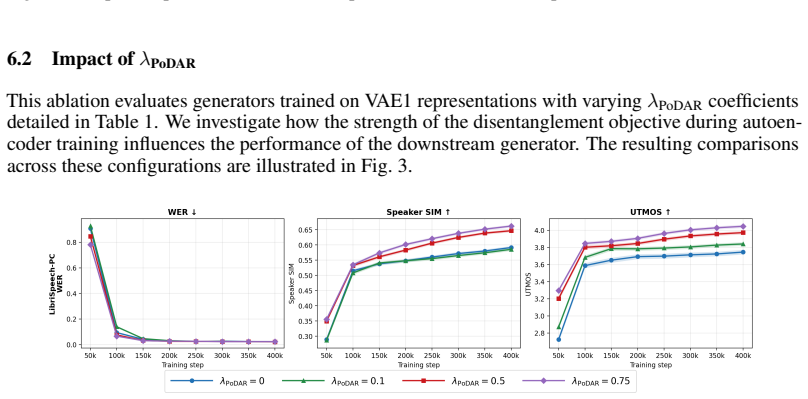
major comments (2)
- The assertion that the factorization 'makes the latent space easier to model' is justified exclusively through downstream generative performance (Abstract); no independent metrics of modelability such as reconstruction error on held-out power variations or intrinsic dimensionality are described.
- The reported numerical gains lack accompanying details on experimental controls, number of runs, statistical significance, or ablation studies isolating the randomized power augmentation and latent consistency objective (Abstract and experimental summary), leaving open the possibility that improvements arise from unmentioned factors.
Simulated Author's Rebuttal
We thank the referee for their constructive review and for recognizing the potential value of PoDAR in improving latent space properties for audio generative modeling. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: The assertion that the factorization 'makes the latent space easier to model' is justified exclusively through downstream generative performance (Abstract); no independent metrics of modelability such as reconstruction error on held-out power variations or intrinsic dimensionality are described.
Authors: We acknowledge that the abstract and initial presentation rely on downstream metrics (convergence speed, speaker similarity, and UTMOS) to evidence improved modelability. The manuscript motivates the claim through the design of the randomized power augmentation and latent consistency objective, which explicitly target power invariance. However, we agree that direct, independent metrics would provide stronger support. In the revised manuscript we will add a dedicated analysis subsection reporting reconstruction error on held-out power-augmented samples and estimates of effective latent dimensionality before and after applying PoDAR. revision: yes
-
Referee: The reported numerical gains lack accompanying details on experimental controls, number of runs, statistical significance, or ablation studies isolating the randomized power augmentation and latent consistency objective (Abstract and experimental summary), leaving open the possibility that improvements arise from unmentioned factors.
Authors: The full manuscript already contains ablation studies that isolate the contributions of the randomized power augmentation and the latent consistency objective, together with a description of the training protocol on LibriSpeech-PC. The abstract and summary sections are necessarily concise and therefore omit these details. We will revise the experimental section to explicitly state the number of independent runs performed, report standard deviations or statistical significance for the 0.055 speaker-similarity and 0.22 UTMOS gains, and provide additional controls confirming that the observed improvements are attributable to the PoDAR components rather than other factors. revision: partial
Circularity Check
No significant circularity; derivation self-contained
full rationale
The paper introduces PoDAR via randomized power augmentation plus a latent consistency objective to factor power from semantic content, then reports empirical gains in downstream generative modeling (2× convergence, +0.055 speaker similarity, +0.22 UTMOS). No equations, self-citations, or fitted parameters are shown reducing the central claim to its inputs by construction; the performance metrics constitute independent experimental evidence rather than a tautological restatement of the training procedure.
Axiom & Free-Parameter Ledger
invented entities (1)
-
PoDAR framework
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquationwashburn_uniqueness_aczel unclearrandomized power augmentation and latent consistency objective to decouple signal power from invariant semantic content
-
IndisputableMonolith/Foundation/AbsoluteFloorClosureabsolute_floor_iff_bare_distinguishability unclearpartial CFG rule that applies guidance only to the power-invariant subspace
Reference graph
Works this paper leans on
-
[1]
Stability AI, “stable-audio-tools.” https://github.com/Stability-AI/ stable-audio-tools, 2025. GitHub repository
work page 2025
-
[2]
High-fidelity audio compression with improved RVQGAN,
R. Kumar, P. Seetharaman, A. Luebs, I. Kumar, and K. Kumar, “High-fidelity audio compression with improved RVQGAN,” inAdvances in Neural Information Processing Systems (NeurIPS), 2023
work page 2023
-
[3]
High-resolution image synthe- sis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High-resolution image synthe- sis with latent diffusion models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 10684–10695, 2022
work page 2022
-
[4]
Audioldm: Text-to-audio generation with latent diffusion models,
H. Liu, Z. Chen, Y . Yuan, X. Mei, X. Liu, D. Mandic, W. Wang, and M. D. Plumbley, “Audioldm: Text-to-audio generation with latent diffusion models,”arXiv preprint arXiv:2301.12503, 2023
-
[5]
Z. Evans, J. D. Parker, C. Carr, Z. Zukowski, J. Taylor, and J. Pons, “Stable audio open,” 2024
work page 2024
-
[6]
Taming transformers for high-resolution image synthesis,
P. Esser, R. Rombach, and B. Ommer, “Taming transformers for high-resolution image synthesis,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 12873–12883, 2021
work page 2021
-
[7]
Making reconstruction fid predictive of diffusion generation fid,
T. Xu, M. He, S. Abu-Hussein, J. M. Hernandez-Lobato, H. Zhang, K. Zhao, C. Zhou, Y .-Q. Zhang, and Y . Wang, “Making reconstruction fid predictive of diffusion generation fid,” 2026
work page 2026
-
[8]
Repa-e: Unlocking vae for end- to-end tuning of latent diffusion transformers,
X. Leng, J. Singh, Y . Hou, Z. Xing, S. Xie, and L. Zheng, “Repa-e: Unlocking vae for end- to-end tuning of latent diffusion transformers,” inProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 18262–18272, 2025
work page 2025
-
[9]
Diffusion Transformers with Representation Autoencoders
B. Zheng, N. Ma, S. Tong, and S. Xie, “Diffusion transformers with representation autoencoders,” arXiv preprint arXiv:2510.11690, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Moshi: a speech-text foundation model for real-time dialogue
A. Défossez, L. Mazaré, M. Orsini, A. Royer, P. Pérez, H. Jégou, E. Grave, and N. Zeghi- dour, “Moshi: a speech-text foundation model for real-time dialogue,”arXiv preprint arXiv:2410.00037, 2024
work page internal anchor Pith review arXiv 2024
-
[11]
DualCodec: A low-frame-rate, semantically- enhanced neural audio codec for speech generation,
J. Li, X. Lin, Z. Li, S. Huang, Y . Wang, C. Wang, Z. Zhan, and Z. Wu, “Dualcodec: A low- frame-rate, semantically-enhanced neural audio codec for speech generation,”arXiv preprint arXiv:2505.13000, 2025
-
[12]
Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think
S. Yu, S. Kwak, H. Jang, J. Jeong, J. Huang, J. Shin, and S. Xie, “Representation align- ment for generation: Training diffusion transformers is easier than you think,”arXiv preprint arXiv:2410.06940, 2024
work page internal anchor Pith review arXiv 2024
-
[13]
J. Singh, X. Leng, Z. Wu, L. Zheng, R. Zhang, E. Shechtman, and S. Xie, “What mat- ters for representation alignment: Global information or spatial structure?,”arXiv preprint arXiv:2512.10794, 2025
-
[14]
The unification of representation learning and generative modelling,
K. Didi, “The unification of representation learning and generative modelling,” 2025
work page 2025
-
[15]
Classifier-free diffusion guidance,
J. Ho and T. Salimans, “Classifier-free diffusion guidance,” 2022
work page 2022
-
[16]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” inProceedings of the 34th International Conference on Neural Information Processing Systems, NIPS ’20, (Red Hook, NY , USA), Curran Associates Inc., 2020
work page 2020
-
[17]
Score-based generative modeling through stochastic differential equations,
Y . Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole, “Score-based generative modeling through stochastic differential equations,” in9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021, 2021
work page 2021
-
[18]
Elucidating the design space of diffusion-based generative models,
T. Karras, M. Aittala, T. Aila, and S. Laine, “Elucidating the design space of diffusion-based generative models,” inAdvances in Neural Information Processing Systems 35 (NeurIPS 2022), 2022
work page 2022
-
[19]
Flow matching for generative modeling,
Y . Lipman, R. T. Q. Chen, H. Ben-Hamu, M. Nickel, and M. Le, “Flow matching for generative modeling,” inThe Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[20]
Flow straight and fast: Learning to generate and transfer data with rectified flow,
X. Liu, C. Gong, and qiang liu, “Flow straight and fast: Learning to generate and transfer data with rectified flow,” inThe Eleventh International Conference on Learning Representations, 2023. 10
work page 2023
-
[21]
Emerging properties in self-supervised vision transformers,
M. Caron, H. Touvron, I. Misra, H. Jégou, J. Mairal, P. Bojanowski, and A. Joulin, “Emerging properties in self-supervised vision transformers,” inProceedings of the IEEE/CVF international conference on computer vision, pp. 9650–9660, 2021
work page 2021
-
[22]
Sigmoid loss for language image pre- training,
X. Zhai, B. Mustafa, A. Kolesnikov, and L. Beyer, “Sigmoid loss for language image pre- training,” inProceedings of the IEEE/CVF international conference on computer vision, pp. 11975–11986, 2023
work page 2023
-
[23]
Masked autoencoders are scalable vision learners,
K. He, X. Chen, S. Xie, Y . Li, P. Dollár, and R. Girshick, “Masked autoencoders are scalable vision learners,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 16000–16009, 2022
work page 2022
-
[24]
Wavlm: Large-scale self-supervised pre-training for full stack speech processing,
S. Chen, C. Wang, Z. Chen, Y . Wu, S. Wang, X. Tan, Y .-Q. Liu, J. Pan, W. Li, L. Zhou, et al., “Wavlm: Large-scale self-supervised pre-training for full stack speech processing,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 13138–13148, 2022
work page 2022
-
[25]
arXiv preprint arXiv:2312.05187 , year=
L. Barrault, Y .-A. Chung, M. C. Meglioli, D. Dale, N. Dong, M. Duppenthaler, P.-A. Duquenne, B. Ellis, H. Elsahar, J. Haaheim,et al., “Seamless: Multilingual expressive and streaming speech translation,”arXiv preprint arXiv:2312.05187, 2023
-
[26]
Guiding a diffusion model with a bad version of itself,
T. Karras, M. Aittala, T. Kynkäänniemi, J. Lehtinen, T. Aila, and S. Laine, “Guiding a diffusion model with a bad version of itself,”Advances in Neural Information Processing Systems, vol. 37, pp. 52996–53021, 2024
work page 2024
-
[27]
R. Yamamoto, E. Song, and J.-M. Kim, “Parallel WaveGAN: A fast waveform generation model based on generative adversarial networks with multi-resolution spectrogram,” inProceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 6199–6203, 2020
work page 2020
-
[28]
High fidelity neural audio compression,
A. Défossez, J. Copet, G. Synnaeve, and Y . Adi, “High fidelity neural audio compression,” 2022
work page 2022
-
[29]
G. J. Mysore, “Can we automatically transform speech recorded on common consumer devices in real-world environments into professional production quality speech? A dataset, insights, and challenges,”IEEE Signal Processing Letters, vol. 22, no. 8, pp. 1006–1010, 2015
work page 2015
-
[30]
ICASSP 2022 deep noise suppression challenge,
H. Dubey, V . Gopal, R. Cutler, A. Aazami, S. Matusevych, S. Braun, S. E. Eskimez, M. Thakker, T. Yoshioka, H. Gamper, and R. Aichner, “ICASSP 2022 deep noise suppression challenge,” in Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2022
work page 2022
-
[31]
Common voice: A massively-multilingual speech corpus,
R. Ardila, M. Branson, K. Davis, M. Henretty, M. Kohler, J. Meyer, R. Morais, L. Saunders, F. M. Tyers, and G. Weber, “Common voice: A massively-multilingual speech corpus,” 2019
work page 2019
-
[32]
CSTR VCTK corpus: English multi-speaker corpus for CSTR voice cloning toolkit (version 0.92)
J. Yamagishi, C. Veaux, and K. MacDonald, “CSTR VCTK corpus: English multi-speaker corpus for CSTR voice cloning toolkit (version 0.92).” [sound]. University of Edinburgh. The Centre for Speech Technology Research (CSTR), 2019
work page 2019
-
[33]
The MUSDB18 corpus for music separation
Z. Rafii, A. Liutkus, F.-R. Stöter, S. I. Mimilakis, and R. Bittner, “The MUSDB18 corpus for music separation.” Zenodo, Dec. 2017
work page 2017
-
[34]
The MTG-jamendo dataset for automatic music tagging,
D. Bogdanov, M. Won, P. Tovstogan, A. Porter, and X. Serra, “The MTG-jamendo dataset for automatic music tagging,” inMachine Learning for Music Discovery Workshop (ML4MD) at ICML, 2019
work page 2019
-
[35]
Audio set: An ontology and human-labeled dataset for audio events,
J. F. Gemmeke, D. P. W. Ellis, D. Freedman, A. Jansen, W. Lawrence, R. C. Moore, M. Plakal, and M. Ritter, “Audio set: An ontology and human-labeled dataset for audio events,” in Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 776–780, 2017
work page 2017
-
[36]
F5-tts: A fairytaler that fakes fluent and faithful speech with flow matching,
Y . Chen, Z. Niu, Z. Ma, K. Deng, C. Wang, J. Zhao, K. Yu, and X. Chen, “F5-tts: A fairytaler that fakes fluent and faithful speech with flow matching,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), (Vienna, Austria), Association for Computational Linguistics, July 2025
work page 2025
-
[37]
Emilia: An extensive, multilingual, and diverse speech dataset for large-scale speech generation,
H. He, Z. Shang, C. Wang, X. Li, Y . Gu, H. Hua, L. Liu, C. Yang, J. Li, P. Shi,et al., “Emilia: An extensive, multilingual, and diverse speech dataset for large-scale speech generation,” in 2024 IEEE Spoken Language Technology Workshop (SLT), pp. 885–890, IEEE, 2024. 11
work page 2024
-
[38]
ViSQOL: An objective speech quality model,
A. Hines, J. Skoglund, A. C. Kokaram, and N. Harte, “ViSQOL: An objective speech quality model,”EURASIP Journal on Audio, Speech, and Music Processing, vol. 2015, no. 1, p. 13, 2015
work page 2015
-
[39]
UTMOS: UTokyo- SaruLab system for V oiceMOS challenge 2022,
T. Saeki, D. Xin, W. Nakata, T. Koriyama, S. Takamichi, and H. Saruwatari, “UTMOS: UTokyo- SaruLab system for V oiceMOS challenge 2022,” inProc. INTERSPEECH, 2022
work page 2022
-
[40]
Librispeech: an asr corpus based on public domain audio books,
V . Panayotov, G. Chen, D. Povey, and S. Khudanpur, “Librispeech: an asr corpus based on public domain audio books,” in2015 IEEE international conference on acoustics, speech and signal processing (ICASSP), pp. 5206–5210, IEEE, 2015
work page 2015
-
[41]
A. Meister, M. Novikov, N. Karpov, E. Bakhturina, V . Lavrukhin, and B. Ginsburg, “Librispeech- pc: Benchmark for evaluation of punctuation and capitalization capabilities of end-to-end asr models,” 2023
work page 2023
-
[42]
Seed-tts: A family of high-quality versatile speech generation models,
P. Anastassiou, J. Chen, J. Chen, Y . Chen, Z. Chen, Z. Chen, J. Cong, L. Deng, C. Ding, L. Gao, M. Gong, P. Huang, Q. Huang, Z. Huang, Y . Huo, D. Jia, C. Li, F. Li, H. Li, J. Li, X. Li, X. Li, L. Liu, S. Liu, S. Liu, X. Liu, Y . Liu, Z. Liu, L. Lu, J. Pan, X. Wang, Y . Wang, Y . Wang, Z. Wei, J. Wu, C. Yao, Y . Yang, Y . Yi, J. Zhang, Q. Zhang, S. Zhang...
work page 2024
-
[43]
Didispeech: A large scale mandarin speech corpus,
T. Guo, C. Wen, D. Jiang, N. Luo, R. Zhang, S. Zhao, W. Li, C. Gong, W. Zou, K. Han, and X. Li, “Didispeech: A large scale mandarin speech corpus,” 2021
work page 2021
-
[44]
Robust speech recognition via large-scale weak supervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervision,” 2022
work page 2022
-
[45]
Funasr: A fundamental end-to-end speech recognition toolkit,
Z. Gao, Z. Li, J. Wang, H. Luo, X. Shi, M. Chen, Y . Li, L. Zuo, Z. Du, Z. Xiao, and S. Zhang, “Funasr: A fundamental end-to-end speech recognition toolkit,” 2023
work page 2023
-
[46]
B. Desplanques, J. Thienpondt, and K. Demuynck, “Ecapa-tdnn: Emphasized channel attention, propagation and aggregation in TDNN based speaker verification,” inProc. INTERSPEECH, 2020. 12 A Asset licenses Table 3 lists every code repository, dataset, and pretrained model used in this paper, together with its license and primary citation. All assets are publ...
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.