Recognition: no theorem link
GELATO: Generative Entropy- and Lyapunov-based Adaptive Token Offloading for Device-Edge Speculative LLM Inference
Pith reviewed 2026-05-12 03:13 UTC · model grok-4.3
The pith
GELATO uses drift-plus-penalty control and per-token entropy checks to optimize long-term throughput under energy limits in device-edge speculative LLM decoding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
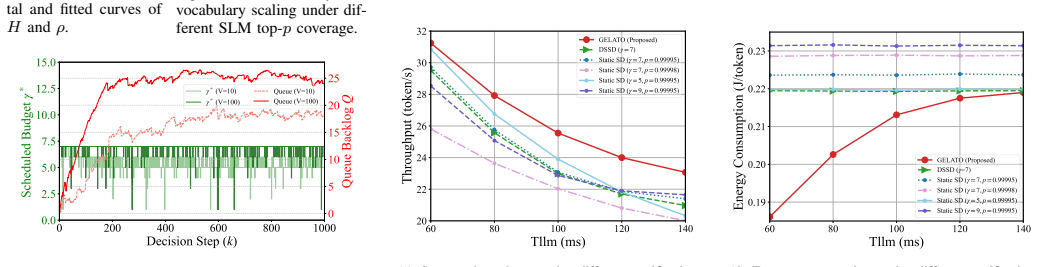
GELATO achieves a globally optimal tradeoff in device-edge collaborative SD systems by maximizing decoding throughput under energy constraints. The outer drift-plus-penalty loop manages the reference drafting budget for long-term balance, and the nested entropy-driven generation performs early exiting to adapt to per-token uncertainty. Theoretical analysis establishes a rigorous bound on long-term throughput. Evaluations show 64.98 percent higher token throughput and 47.47 percent lower energy use than state-of-the-art distributed SD architectures while preserving LLM decoding quality.
What carries the argument
The GELATO framework's combination of an outer drift-plus-penalty optimization loop for energy-throughput budgeting and a nested entropy-driven early-exit mechanism for per-token adaptation.
If this is right
- Establishes a rigorous performance bound on long-term throughput.
- Delivers 64.98 percent higher token throughput than prior distributed SD methods in constrained settings.
- Reduces energy consumption by 47.47 percent while keeping output quality intact.
- Adapts dynamically to per-token generative uncertainty through the nested entropy mechanism.
Where Pith is reading between the lines
- The control structure could transfer to other generative edge tasks such as image or audio synthesis where early-exit decisions matter.
- Deployment would need explicit handling of wireless channel fluctuations that the current analysis treats as external.
- Scaling to multiple edge nodes might multiply the gains if the budgeting loop coordinates across devices.
- Testing across LLM sizes beyond those evaluated would clarify whether the bound remains tight.
Load-bearing premise
The drift-plus-penalty decisions and per-token entropy calculations incur low enough overhead to deliver net gains in real dynamic wireless and hardware conditions.
What would settle it
A hardware testbed experiment in which the control-loop overhead exceeds the measured throughput gains or in which the stated long-term bound fails to hold under typical network variability would disprove the claims.
Figures


read the original abstract
The recent growth of on-device Large Language Model (LLM) inference has driven significant interest in device-edge collaborative LLM inference. As a promising architecture, Speculative Decoding (SD) is increasingly adopted where a lightweight draft model rapidly generates candidate tokens to be verified by a powerful target model. However, a fundamental challenge lies in achieving per-token resource scheduling to effectively adapt SD paradigm to resource-constrained edge environment. This paper proposes a Generative Entropy- and Lyapunov-based Adaptive Token Offloading framework, named GELATO, to maximize decoding throughput under energy constraints in a device-edge collaborative SD system. Specifically, an outer drift-plus-penalty loop makes online decisions to establish a reference drafting budget, managing long-term energy-throughput trade-off. Further, a nested entropy-driven generation mechanism executes early exiting to adapt to per-token dynamic generative uncertainty. Theoretical analysis establishes a rigorous performance bound on long-term throughput for GELATO. Extensive evaluations demonstrate that GELATO achieves a globally optimal tradeoff, outperforming state-of-the-art distributed SD architectures by 64.98% in token throughput and reducing energy consumption by 47.47% under resource-constrained environments, while preserving LLM decoding quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GELATO, a Generative Entropy- and Lyapunov-based Adaptive Token Offloading framework for device-edge collaborative speculative decoding in LLMs. It features an outer drift-plus-penalty loop for setting drafting budgets to balance long-term energy and throughput, and an inner entropy-driven mechanism for per-token early exits. Theoretical analysis provides a rigorous bound on long-term throughput, and experiments claim 64.98% improvement in token throughput and 47.47% reduction in energy consumption over state-of-the-art methods while maintaining decoding quality.
Significance. If the results hold, this work is significant for advancing efficient LLM inference on resource-constrained devices by adapting speculative decoding dynamically. The use of Lyapunov optimization for online decisions and entropy for adaptation offers a novel approach to handling uncertainty and constraints in edge environments. Credit is due for attempting a theoretical performance bound and reporting substantial quantitative gains. However, the significance is tempered by the need to confirm that computational overheads do not negate the benefits in practical settings.
major comments (3)
- [Theoretical Analysis] The rigorous performance bound on long-term throughput is load-bearing for the central claim. However, it appears to depend on the choice of the Lyapunov penalty parameter V and the drafting budget, which are tunable. The derivation should explicitly show whether the bound is parameter-free or reduces by construction to these choices, as this affects its generality.
- [Evaluation] The reported gains of 64.98% in token throughput and 47.47% in energy consumption are presented as outperforming SOTA distributed SD architectures. This is central, but the evaluation lacks sufficient details on baselines, specific resource constraints, model sizes, and any error analysis or statistical validation, undermining the ability to assess the claims' robustness.
- [Algorithm and System Model] The assumption that the overhead of drift-plus-penalty decisions and per-token entropy calculations is negligible compared to token generation latency is critical for the bound and empirical gains to hold in dynamic wireless and hardware conditions. No closed-form overhead analysis or micro-benchmarks are provided, which is a load-bearing issue for applicability.
minor comments (2)
- [Abstract] The abstract could include a brief mention of the key assumptions, such as the negligible overhead, to better contextualize the claims.
- Notation for the drafting budget and penalty parameter V should be consistently defined early in the paper for clarity.
Simulated Author's Rebuttal
We appreciate the referee's thorough review and constructive feedback on our manuscript. We address each of the major comments below and outline the revisions we plan to make.
read point-by-point responses
-
Referee: [Theoretical Analysis] The rigorous performance bound on long-term throughput is load-bearing for the central claim. However, it appears to depend on the choice of the Lyapunov penalty parameter V and the drafting budget, which are tunable. The derivation should explicitly show whether the bound is parameter-free or reduces by construction to these choices, as this affects its generality.
Authors: We thank the referee for this observation. Our theoretical analysis, based on the drift-plus-penalty framework, derives a bound on the long-term average throughput that holds for any fixed V > 0, with the optimality gap scaling as O(1/V). The drafting budget is determined online by the algorithm and is not a fixed tunable parameter in the bound derivation. We will revise the manuscript to explicitly present the bound in terms of V and discuss its implications for different parameter choices, thereby clarifying its generality. revision: yes
-
Referee: [Evaluation] The reported gains of 64.98% in token throughput and 47.47% in energy consumption are presented as outperforming SOTA distributed SD architectures. This is central, but the evaluation lacks sufficient details on baselines, specific resource constraints, model sizes, and any error analysis or statistical validation, undermining the ability to assess the claims' robustness.
Authors: We agree that more details are necessary for reproducibility and robustness assessment. The revised version will include comprehensive descriptions of the baselines (including their hyperparameters), the specific hardware and network constraints used in experiments, the exact model sizes for draft and target models, and statistical measures such as mean and standard deviation over 10 independent runs with error bars on all performance plots. revision: yes
-
Referee: [Algorithm and System Model] The assumption that the overhead of drift-plus-penalty decisions and per-token entropy calculations is negligible compared to token generation latency is critical for the bound and empirical gains to hold in dynamic wireless and hardware conditions. No closed-form overhead analysis or micro-benchmarks are provided, which is a load-bearing issue for applicability.
Authors: This is a valid concern. We will incorporate a new subsection providing a closed-form analysis of the computational overhead, demonstrating that the per-epoch Lyapunov optimization and entropy calculations add only a fixed small cost (independent of token sequence length) compared to the model inference time. Additionally, we will include micro-benchmark results from our experimental setup quantifying the actual overhead percentages, which remain below 2% in our tests, and discuss conditions under which this assumption holds. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The abstract and description present GELATO as a combination of standard drift-plus-penalty Lyapunov optimization for long-term energy-throughput tradeoff and per-token entropy for early exiting. The claimed rigorous performance bound is stated to come from theoretical analysis of this framework, while the 64.98% throughput and 47.47% energy gains are reported from extensive evaluations. No equations, self-citations, or fitted parameters are shown reducing the bound or optimality claim to the inputs by construction. The derivation is self-contained; the bound and gains do not appear tautological or forced by renaming or ansatz smuggling.
Axiom & Free-Parameter Ledger
free parameters (1)
- Lyapunov penalty parameter V
axioms (2)
- standard math Lyapunov optimization yields rigorous long-term performance bounds for online stochastic control
- domain assumption Generative entropy reliably indicates per-token uncertainty suitable for early exiting decisions
Reference graph
Works this paper leans on
-
[1]
Mobile edge intelligence for large language models: A contemporary survey,
G. Qu, Q. Chen, W. Wei, Z. Lin, X. Chen, and K. Huang, “Mobile edge intelligence for large language models: A contemporary survey,”IEEE Commun. Surveys Tuts., vol. 27, no. 6, pp. 3820–3860, 2025
work page 2025
-
[2]
Mobile and edge evaluation of large language models,
S. Laskaridis, K. Katevas, L. Minto, and H. Haddadi, “Mobile and edge evaluation of large language models,” inWorkshop on Efficient Systems for Foundation Models, ICML, 2024
work page 2024
-
[3]
EdgeLLM: Fast on-device LLM inference with speculative decoding,
D. Xu, W. Yin, H. Zhang, X. Jin, Y . Zhang, S. Wei, M. Xu, and X. Liu, “EdgeLLM: Fast on-device LLM inference with speculative decoding,” IEEE Trans. Mobile Comput., vol. 24, no. 4, pp. 3256–3273, 2024
work page 2024
-
[4]
Unleashing the power of edge- cloud generative AI in mobile networks: A survey of AIGC services,
M. Xu, H. Du, D. Niyato, J. Kang, Z. Xiong, S. Mao, Z. Han, A. Jamalipour, D. I. Kim, X. Shenet al., “Unleashing the power of edge- cloud generative AI in mobile networks: A survey of AIGC services,” IEEE Commun. Surveys Tuts., vol. 26, no. 2, pp. 1127–1170, 2024
work page 2024
-
[5]
Task-oriented sensing, computation, and communication integration for multi-device edge AI,
D. Wen, P. Liu, G. Zhu, Y . Shi, J. Xu, Y . C. Eldar, and S. Cui, “Task-oriented sensing, computation, and communication integration for multi-device edge AI,”IEEE Transactions on Wireless Communications, vol. 23, no. 3, pp. 2486–2502, 2024
work page 2024
-
[6]
Resource allocation for multiuser edge inference with batching and early exiting,
Z. Liu, Q. Lan, and K. Huang, “Resource allocation for multiuser edge inference with batching and early exiting,”IEEE Journal on Selected Areas in Communications, vol. 41, no. 4, pp. 1186–1200, 2023
work page 2023
-
[7]
Fast inference from transform- ers via speculative decoding,
Y . Leviathan, M. Kalman, and Y . Matias, “Fast inference from transform- ers via speculative decoding,” inProc. Int. Conf. Mach. Learn. (ICML), 2023
work page 2023
-
[8]
Accelerating Large Language Model Decoding with Speculative Sampling
C. Chen, S. Borgeaud, G. Irving, J.-B. Lespiau, L. Sifre, and J. Jumper, “Accelerating large language model decoding with speculative sam- pling,”arXiv preprint arXiv:2302.01318, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Y . He, J. Fang, F. R. Yu, and V . C. Leung, “Large language models (LLMs) inference offloading and resource allocation in cloud-edge computing: An active inference approach,”IEEE Transactions on Mobile Computing, vol. 23, no. 12, pp. 11 253–11 264, 2024
work page 2024
-
[10]
Edge and terminal cooperation enabled LLM deployment optimization in wireless network,
W. Zhao, W. Jing, Z. Lu, and X. Wen, “Edge and terminal cooperation enabled LLM deployment optimization in wireless network,” inProc. IEEE/CIC Int. Conf. Commun. China (ICCC Workshops). IEEE, 2024
work page 2024
-
[11]
Collaborative large language model infer- ence via resource-aware parallel speculative decoding,
J. Koh and H. J. Yang, “Collaborative large language model infer- ence via resource-aware parallel speculative decoding,”arXiv preprint arXiv:2511.01695, 2025
-
[12]
Edge intelligence optimization for large language model inference with batch- ing and quantization,
X. Zhang, J. Liu, Z. Xiong, Y . Huang, G. Xie, and R. Zhang, “Edge intelligence optimization for large language model inference with batch- ing and quantization,” in2024 IEEE Wireless Communications and Networking Conference (WCNC). IEEE, 2024, pp. 1–6
work page 2024
-
[13]
J. Ning, C. Zheng, and T. Yang, “DSSD: Efficient edge-device de- ployment and collaborative inference via distributed split speculative decoding,” inICML Workshop on Machine Learning for Wireless Communication and Networks (ML4Wireless), 2025
work page 2025
-
[14]
Uncertainty-aware hybrid inference with on-device small and remote large language models,
S. Oh, J. Kim, J. Park, S.-W. Ko, T. Q. S. Quek, and S.-L. Kim, “Uncertainty-aware hybrid inference with on-device small and remote large language models,” inProc. IEEE Int. Conf. on Mach. Learn. Commun. Netw. (ICMLCN), 2025
work page 2025
-
[15]
Fast and cost-effective speculative edge-cloud decoding with early exits,
Y . Venkatesha, S. Kundu, and P. Panda, “Fast and cost-effective speculative edge-cloud decoding with early exits,”arXiv preprint arXiv:2505.21594, 2025
-
[16]
arXiv preprint arXiv:2505.06371 (2025)
J.-W. Chung, J. J. Ma, R. Wu, J. Liu, O. J. Kweon, Y . Xia, Z. Wu, and M. Chowdhury, “The ML. ENERGY benchmark: Toward auto- mated inference energy measurement and optimization,”arXiv preprint arXiv:2505.06371, 2025
-
[17]
S. Oh, J. Kim, J. Park, S.-W. Ko, J. Choi, T. Q. Quek, and S.-L. Kim, “Communication-efficient hybrid language model via uncertainty- aware opportunistic and compressed transmission,”arXiv preprint arXiv:2505.11788, 2025
-
[18]
Neely,Stochastic network optimization with application to commu- nication and queueing systems
M. Neely,Stochastic network optimization with application to commu- nication and queueing systems. Morgan & Claypool Publishers, 2010
work page 2010
-
[19]
Stochastic network optimization with non-convex utilities and costs,
M. J. Neely, “Stochastic network optimization with non-convex utilities and costs,” in2010 Information Theory and Applications Workshop (ITA). IEEE, 2010, pp. 1–10
work page 2010
-
[20]
Qwen2.5: A party of foundation models,
Q. Team, “Qwen2.5: A party of foundation models,” September 2024. [Online]. Available: https://qwenlm.github.io/blog/qwen2.5/
work page 2024
-
[21]
Training Verifiers to Solve Math Word Problems
K. Cobbe, V . Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakano, C. Hesse, and J. Schul- man, “Training verifiers to solve math word problems,”arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[22]
Edgeshard: Efficient LLM inference via collaborative edge computing,
M. Zhang, X. Shen, J. Cao, Z. Cui, and S. Jiang, “Edgeshard: Efficient LLM inference via collaborative edge computing,”IEEE Internet of Things Journal, vol. 12, no. 10, pp. 13 119–13 131, 2024
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.