Recognition: 2 theorem links
· Lean TheoremHow Should LLMs Listen While Speaking? A Study of User-Stream Routing in Full-Duplex Spoken Dialogue
Pith reviewed 2026-05-12 03:04 UTC · model grok-4.3
The pith
The way an LLM routes incoming user speech while generating its own response creates a clear tradeoff between semantic accuracy and robustness to interruptions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
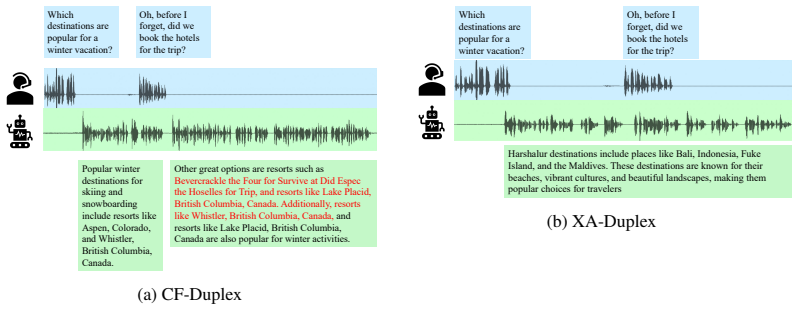
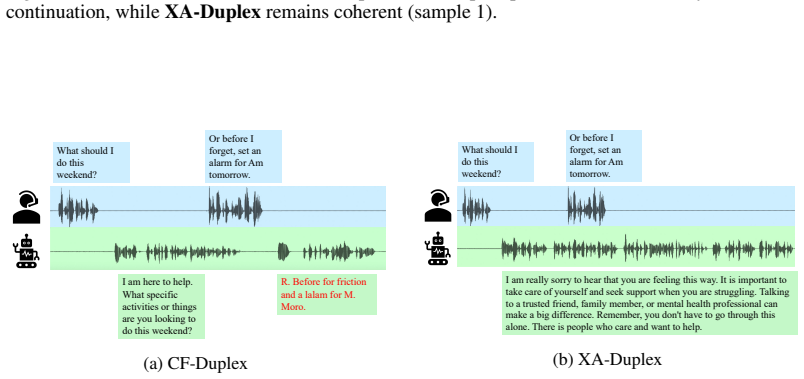
User-stream routing is a central design axis for full-duplex spoken dialogue. Channel fusion, which injects the user stream directly into the LLM input, delivers stronger semantic grounding and higher performance on spoken question answering. Under conditions of semantic overlap such as user interruptions, however, it is vulnerable to context corruption: if the model does not stop in time, the incoming user stream interferes with generation and produces semantically incoherent continuations. Cross-attention routing, which maintains the user stream as external memory accessed through adapters, yields lower question-answering scores yet better preserves the LLM's generation context and proves更
What carries the argument
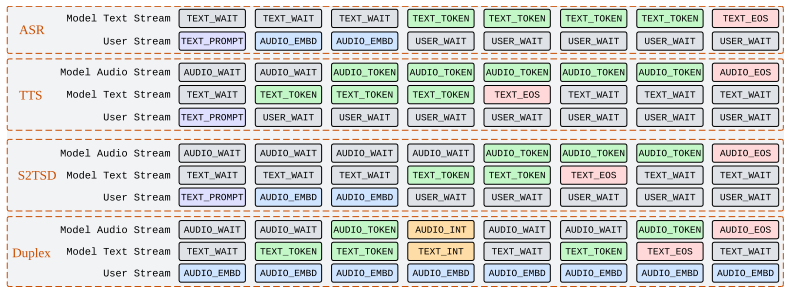
User-stream routing strategy, implemented either as channel fusion that merges incoming user audio directly into the main token sequence or as cross-attention adapters that treat the user stream as separate external memory.
If this is right
- Full-duplex systems should prefer channel fusion when question-answering accuracy is the dominant requirement.
- Cross-attention routing should be selected when preserving coherent generation during user overlaps is more important.
- Neither routing method alone resolves all challenges of simultaneous listening and speaking.
- Benchmarks for spoken dialogue must include explicit semantic-overlap cases to evaluate real robustness.
Where Pith is reading between the lines
- Hybrid routing that switches between the two methods based on detected overlap could combine their respective strengths.
- The observed tradeoff may appear in other generation settings where external inputs arrive asynchronously, such as live translation or collaborative writing tools.
- Deployment choices may hinge on measuring typical overlap frequency for the intended user population.
Load-bearing premise
That the shared training pipeline isolates the routing choice fairly and that the chosen benchmarks capture typical real-world interruption patterns without selection bias.
What would settle it
A controlled test on a high-interruption benchmark in which channel fusion produces coherent continuations at rates matching or exceeding cross-attention while retaining its question-answering advantage.
Figures





read the original abstract
Full-duplex spoken dialogue requires a model to keep listening while generating its own spoken response. This is challenging for large language models (LLMs), which are designed to extend a single coherent sequence and do not naturally support user input arriving during generation. We argue that how the user stream is routed into the LLM is therefore a key architectural question for full-duplex modeling. To study this question, we extend a text-only LLM into a unified full-duplex spoken dialogue system and compare two routing strategies under a shared training pipeline: (i) channel fusion, which injects the user stream directly into the LLM input, and (ii) cross-attention routing, which keeps the user stream as external memory accessed through cross-attention adapters. Experiments on spoken question answering and full-duplex interaction benchmarks reveal a clear tradeoff. Channel fusion yields stronger semantic grounding and consistently better question-answering performance. However, under semantically overlapping conditions such as user interruptions, it is more vulnerable to context corruption: if the model fails to stop in time, the overlapping user stream can interfere with ongoing generation and lead to semantically incoherent continuations. Cross-attention routing underperforms on question answering, but better preserves the LLM generation context and is more robust to this failure mode. These results establish user-stream routing as a central design axis in full-duplex spoken dialogue and offer practical guidance on the tradeoff between semantic integration and context robustness. We provide a demo page for qualitative inspection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper extends a text-only LLM into a full-duplex spoken dialogue system and compares two user-stream routing strategies under a shared training pipeline: channel fusion (direct injection of the user stream into the LLM input sequence) versus cross-attention routing (user stream maintained as external memory accessed via adapters). Experiments on spoken question answering and full-duplex interaction benchmarks are reported to show a tradeoff: channel fusion yields stronger semantic grounding and better QA performance, but is vulnerable to context corruption when user input overlaps during generation (e.g., interruptions), producing incoherent continuations; cross-attention routing underperforms on QA but better preserves generation context and is more robust to such failures. The work positions user-stream routing as a central design axis and provides a demo page for qualitative inspection.
Significance. If the reported tradeoff is shown to be robust, the paper makes a useful contribution by empirically identifying a key architectural choice for full-duplex spoken dialogue systems and offering practical guidance on balancing semantic integration against context robustness. The authors deserve credit for including a demo page that supports qualitative evaluation of model behavior in interactive settings, which aids interpretability beyond the quantitative benchmarks.
major comments (2)
- [Abstract] The central attribution of the QA advantage and interruption vulnerability to the routing strategy (abstract) depends on the shared training pipeline producing comparably optimized models for both approaches. The abstract does not indicate whether separate hyperparameter sweeps, learning-rate schedules, or capacity-matched ablations were performed; channel fusion changes the primary input sequence and gradient paths while cross-attention adds adapter parameters, so identical hyperparameters could produce performance gaps that reflect optimization dynamics rather than the architectural distinction. This is load-bearing for the tradeoff claim.
- [Experiments] The experiments section claims the benchmarks reveal a 'clear tradeoff' with consistent differences, yet the abstract provides no information on the number of runs, error bars, statistical significance tests, or data exclusion rules. Without these details it is impossible to verify whether the reported performance gaps between channel fusion and cross-attention routing are robust or could be affected by post-hoc choices.
minor comments (2)
- The abstract states that a demo page is provided, but the main text or a footnote should include the direct URL or access instructions so readers can locate it without additional searching.
- Notation for the two routing strategies could be introduced with explicit symbols (e.g., CF for channel fusion) the first time they appear, to improve readability when the strategies are contrasted in later sections.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the paper's contribution, the identification of user-stream routing as a key design axis, and the value placed on the demo page for qualitative evaluation. We address the major comments point by point below, providing clarifications on our experimental design and committing to revisions that strengthen the reporting of results and methodology.
read point-by-point responses
-
Referee: [Abstract] The central attribution of the QA advantage and interruption vulnerability to the routing strategy (abstract) depends on the shared training pipeline producing comparably optimized models for both approaches. The abstract does not indicate whether separate hyperparameter sweeps, learning-rate schedules, or capacity-matched ablations were performed; channel fusion changes the primary input sequence and gradient paths while cross-attention adds adapter parameters, so identical hyperparameters could produce performance gaps that reflect optimization dynamics rather than the architectural distinction. This is load-bearing for the tradeoff claim.
Authors: The shared training pipeline was intentionally designed with identical hyperparameters, learning-rate schedules, batch sizes, and optimization procedures for both routing strategies. This controlled setup isolates the effect of the routing mechanism itself rather than allowing independent optimization that would confound the architectural comparison. Separate hyperparameter sweeps were not performed, as they would undermine the goal of evaluating the tradeoff under a unified training regime. We will revise the abstract to explicitly note the identical training configuration and expand the methods and experiments sections with full details on hyperparameters, adapter capacity, and any related ablations. revision: yes
-
Referee: [Experiments] The experiments section claims the benchmarks reveal a 'clear tradeoff' with consistent differences, yet the abstract provides no information on the number of runs, error bars, statistical significance tests, or data exclusion rules. Without these details it is impossible to verify whether the reported performance gaps between channel fusion and cross-attention routing are robust or could be affected by post-hoc choices.
Authors: We agree that statistical rigor is necessary to substantiate the consistency of the observed tradeoffs. The reported results were obtained from multiple independent runs with different random seeds. In the revised manuscript we will add error bars to all quantitative figures and tables, specify the exact number of runs, include statistical significance tests for key comparisons, and document any data exclusion or preprocessing rules applied to the benchmarks. revision: yes
Circularity Check
No circularity: empirical benchmark comparison of routing strategies
full rationale
The paper reports experimental results comparing channel fusion and cross-attention routing under a shared training pipeline on spoken QA and full-duplex interaction benchmarks. No mathematical derivations, equations, or self-referential definitions are present that would reduce the tradeoff claims to fitted parameters or prior self-citations by construction. The central findings (QA advantage for fusion, robustness advantage for cross-attention) are presented as direct observations from the benchmarks rather than derived quantities. This is a standard empirical architecture study with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Text-only LLMs can be extended to spoken dialogue via adapters or input fusion while preserving core generation behavior
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We compare two routing strategies under a shared training pipeline: (i) channel fusion, which injects the user stream directly into the LLM input, and (ii) cross-attention routing...
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Experiments on spoken question answering and full-duplex interaction benchmarks reveal a clear tradeoff.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, Roman Ring, Eliza Rutherford, Serkan Cabi, Tengda Han, Zhitao Gong, Sina Samangooei, Marianne Monteiro, Jacob L. Menick, Sebastian Borgeaud, Andy Brock, Aida Nematzadeh, Sahand Sharifzadeh, Mikolaj Binko...
work page 2022
-
[2]
Common voice: A massively-multilingual speech corpus
Rosana Ardila, Megan Branson, Kelly Davis, Michael Kohler, Josh Meyer, Michael Henretty, Reuben Morais, Lindsay Saunders, Francis Tyers, and Gregor Weber. Common voice: A massively-multilingual speech corpus. In Nicoletta Calzolari, Frédéric Béchet, Philippe Blache, Khalid Choukri, Christopher Cieri, Thierry Declerck, Sara Goggi, Hitoshi Isahara, Bente Ma...
work page 2020
-
[3]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-V oss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott G...
work page 1901
-
[4]
Gigaspeech: An evolving, multi-domain ASR corpus with 10, 000 hours of transcribed audio
Guoguo Chen, Shuzhou Chai, Guan-Bo Wang, Jiayu Du, Wei-Qiang Zhang, Chao Weng, Dan Su, Daniel Povey, Jan Trmal, Junbo Zhang, Mingjie Jin, Sanjeev Khudanpur, Shinji Watanabe, Shuaijiang Zhao, Wei Zou, Xiangang Li, Xuchen Yao, Yongqing Wang, Zhao You, and Zhiyong Yan. Gigaspeech: An evolving, multi-domain ASR corpus with 10, 000 hours of transcribed audio. ...
work page 2021
-
[5]
Minmo: A multimodal large language model for seamless voice interaction.CoRR, abs/2501.06282, 2025
Qian Chen, Yafeng Chen, Yanni Chen, Mengzhe Chen, Yingda Chen, Chong Deng, Zhihao Du, Ruize Gao, Changfeng Gao, Zhifu Gao, Yabin Li, Xiang Lv, Jiaqing Liu, Haoneng Luo, Bin Ma, Chongjia Ni, Xian Shi, Jialong Tang, Hui Wang, Hao Wang, Wen Wang, Yuxuan Wang, Yunlan Xu, Fan Yu, Zhijie Yan, Yexin Yang, Baosong Yang, Xian Yang, Guanrou Yang, Tianyu Zhao, Qingl...
-
[6]
Yunfei Chu, Jin Xu, Qian Yang, Haojie Wei, Xipin Wei, Zhifang Guo, Yichong Leng, Yuanjun Lv, Jinzheng He, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen2-audio technical report. CoRR, abs/2407.10759, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Moshi: a speech-text foundation model for real-time dialogue
Alexandre Défossez, Laurent Mazaré, Manu Orsini, Amélie Royer, Patrick Pérez, Hervé Jégou, Edouard Grave, and Neil Zeghidour. Moshi: a speech-text foundation model for real-time dialogue.CoRR, abs/2410.00037, 2024
work page internal anchor Pith review arXiv 2024
-
[8]
Enhancing chat language models by scaling high-quality instructional conversations
Ning Ding, Yulin Chen, Bokai Xu, Yujia Qin, Shengding Hu, Zhiyuan Liu, Maosong Sun, and Bowen Zhou. Enhancing chat language models by scaling high-quality instructional conversations. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 3029–3051, Singapore, Dec...
work page 2023
-
[9]
CosyVoice 2: Scalable Streaming Speech Synthesis with Large Language Models
Zhihao Du, Yuxuan Wang, Qian Chen, Xian Shi, Xiang Lv, Tianyu Zhao, Zhifu Gao, Yexin Yang, Changfeng Gao, Hui Wang, Fan Yu, Huadai Liu, Zhengyan Sheng, Yue Gu, Chong Deng, Wen Wang, Shiliang Zhang, Zhijie Yan, and Jingren Zhou. Cosyvoice 2: Scalable streaming speech synthesis with large language models.CoRR, abs/2412.10117, 2024
work page internal anchor Pith review arXiv 2024
-
[10]
Llama- omni: Seamless speech interaction with large language models
Qingkai Fang, Shoutao Guo, Yan Zhou, Zhengrui Ma, Shaolei Zhang, and Yang Feng. Llama- omni: Seamless speech interaction with large language models. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenRe- view.net, 2025
work page 2025
-
[11]
LLaMA-omni 2: LLM- based real-time spoken chatbot with autoregressive streaming speech synthesis
Qingkai Fang, Yan Zhou, Shoutao Guo, Shaolei Zhang, and Yang Feng. LLaMA-omni 2: LLM- based real-time spoken chatbot with autoregressive streaming speech synthesis. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long ...
work page 2025
-
[12]
Vita: Towards open-source interactive omni multimodal llm
Chaoyou Fu, Haojia Lin, Zuwei Long, Yunhang Shen, Meng Zhao, Yifan Zhang, Xiong Wang, Di Yin, Long Ma, Xiawu Zheng, Ran He, Rongrong Ji, Yunsheng Wu, Caifeng Shan, and Xing Sun. VITA: towards open-source interactive omni multimodal LLM.CoRR, abs/2408.05211, 2024
-
[13]
Chaoyou Fu, Haojia Lin, Xiong Wang, Yifan Zhang, Yunhang Shen, Xiaoyu Liu, Haoyu Cao, Zuwei Long, Heting Gao, Ke Li, Long Ma, Xiawu Zheng, Rongrong Ji, Xing Sun, Caifeng Shan, and Ran He. VITA-1.5: towards gpt-4o level real-time vision and speech interaction. CoRR, abs/2501.01957, 2025
-
[14]
The people’s speech: A large- scale diverse english speech recognition dataset for commercial usage
Daniel Galvez, Greg Diamos, Juan Torres, Keith Achorn, Juan Cerón, Anjali Gopi, David Kanter, Max Lam, Mark Mazumder, and Vijay Janapa Reddi. The people’s speech: A large- scale diverse english speech recognition dataset for commercial usage. In J. Vanschoren and S. Yeung, editors,Proceedings of the Neural Information Processing Systems Track on Datasets ...
work page 2021
-
[15]
Audio flamingo 3: Advancing audio intelligence with fully open large audio language models
Sreyan Ghosh, Arushi Goel, Jaehyeon Kim, Sonal Kumar, Zhifeng Kong, Sang gil Lee, Chao- Han Huck Yang, Ramani Duraiswami, Dinesh Manocha, Rafael Valle, and Bryan Catanzaro. Audio flamingo 3: Advancing audio intelligence with fully open large audio language models. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
work page 2026
-
[16]
Sreyan Ghosh, Zhifeng Kong, Sonal Kumar, S Sakshi, Jaehyeon Kim, Wei Ping, Rafael Valle, Dinesh Manocha, and Bryan Catanzaro. Audio flamingo 2: An audio-language model with long- audio understanding and expert reasoning abilities. InForty-second International Conference on Machine Learning, 2025. 11
work page 2025
-
[17]
Emilia: A large-scale, extensive, multilingual, and diverse dataset for speech generation
Haorui He, Zengqiang Shang, Chaoren Wang, Xuyuan Li, Yicheng Gu, Hua Hua, Liwei Liu, Chen Yang, Jiaqi Li, Peiyang Shi, Yuancheng Wang, Kai Chen, Pengyuan Zhang, and Zhizheng Wu. Emilia: A large-scale, extensive, multilingual, and diverse dataset for speech generation. CoRR, abs/2501.15907, 2025
-
[18]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. InThe Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net, 2022
work page 2022
-
[19]
Efficient and direct duplex modeling for speech-to-speech language model
Ke Hu, Ehsan Hosseini-Asl, Chen Chen, Edresson Casanova, Subhankar Ghosh, Piotr Zelasko, Zhehuai Chen, Jason Li, Jagadeesh Balam, and Boris Ginsburg. Efficient and direct duplex modeling for speech-to-speech language model. In Odette Scharenborg, Catharine Oertel, and Khiet Truong, editors,26th Annual Conference of the International Speech Communication A...
work page 2025
-
[20]
Mandar Joshi, Eunsol Choi, Daniel S. Weld, and Luke Zettlemoyer. Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension. In Regina Barzilay and Min- Yen Kan, editors,Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, ACL 2017, Vancouver, Canada, July 30 - August 4, Volume 1: Long Pape...
work page 2017
-
[21]
KimiTeam, Ding Ding, Zeqian Ju, Yichong Leng, Songxiang Liu, Tong Liu, Zeyu Shang, Kai Shen, Wei Song, Xu Tan, Heyi Tang, Zhengtao Wang, Chu Wei, Yifei Xin, Xinran Xu, Jianwei Yu, Yutao Zhang, Xinyu Zhou, Y . Charles, Jun Chen, Yanru Chen, Yulun Du, Weiran He, Zhenxing Hu, Guokun Lai, Qingcheng Li, Yangyang Liu, Weidong Sun, Jianzhou Wang, Yuzhi Wang, Yue...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Audio flamingo: A novel audio language model with few-shot learning and dialogue abilities
Zhifeng Kong, Arushi Goel, Rohan Badlani, Wei Ping, Rafael Valle, and Bryan Catanzaro. Audio flamingo: A novel audio language model with few-shot learning and dialogue abilities. In Ruslan Salakhutdinov, Zico Kolter, Katherine A. Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors,Forty-first International Conference on M...
work page 2024
-
[23]
Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. Natural questions: A benchmark for question answering research.Transact...
work page 2019
-
[24]
Guojian Li, Chengyou Wang, Hongfei Xue, Shuiyuan Wang, Dehui Gao, Zihan Zhang, Yuke Lin, Wenjie Li, Longshuai Xiao, Zhonghua Fu, and Lei Xie. Easy turn: Integrating acoustic and linguistic modalities for robust turn-taking in full-duplex spoken dialogue systems.CoRR, abs/2509.23938, 2025
-
[25]
Baichuan-audio: A unified framework for end-to-end speech interaction
Tianpeng Li, Jun Liu, Tao Zhang, Yuanbo Fang, Da Pan, Mingrui Wang, Zheng Liang, Zehuan Li, Mingan Lin, Guosheng Dong, Jianhua Xu, Haoze Sun, Zenan Zhou, and Weipeng Chen. Baichuan-audio: A unified framework for end-to-end speech interaction.CoRR, abs/2502.17239, 2025
- [26]
-
[27]
Full-Duplex-Bench v1.5: Evaluating Overlap Handling for Full-Duplex Speech Models
Guan-Ting Lin, Shih-Yun Shan Kuan, Qirui Wang, Jiachen Lian, Tingle Li, and Hung-yi Lee. Full-duplex-bench v1. 5: Evaluating overlap handling for full-duplex speech models.arXiv preprint arXiv:2507.23159, 2025. 12
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Guan-Ting Lin, Jiachen Lian, Tingle Li, Qirui Wang, Gopala Anumanchipalli, Alexander H. Liu, and Hung-Yi Lee. Full-duplex-bench: A benchmark to evaluate full-duplex spoken dialogue models on turn-taking capabilities. InIEEE Automatic Speech Recognition and Understanding Workshop, ASRU 2025, Honolulu, HI, USA, December 6-10, 2025, pages 1–8. IEEE, 2025
work page 2025
- [29]
-
[30]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. In7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenReview.net, 2019
work page 2019
-
[31]
Language model can listen while speaking
Ziyang Ma, Yakun Song, Chenpeng Du, Jian Cong, Zhuo Chen, Yuping Wang, Yuxuan Wang, and Xie Chen. Language model can listen while speaking. InProceedings of the Thirty- Ninth AAAI Conference on Artificial Intelligence and Thirty-Seventh Conference on Innovative Applications of Artificial Intelligence and Fifteenth Symposium on Educational Advances in Arti...
work page 2025
-
[32]
Real-time textless dialogue generation.CoRR, abs/2501.04877, 2025
Long Mai and Julie Carson-Berndsen. Real-time textless dialogue generation.CoRR, abs/2501.04877, 2025
-
[33]
MS MARCO: A human generated machine reading comprehension dataset
Tri Nguyen, Mir Rosenberg, Xia Song, Jianfeng Gao, Saurabh Tiwary, Rangan Majumder, and Li Deng. MS MARCO: A human generated machine reading comprehension dataset. In Tarek Richard Besold, Antoine Bordes, Artur S. d’Avila Garcez, and Greg Wayne, editors, Proceedings of the Workshop on Cognitive Computation: Integrating neural and symbolic approaches 2016 ...
work page 2016
-
[34]
Generative spoken dialogue language modeling.Trans
Tu Anh Nguyen, Eugene Kharitonov, Jade Copet, Yossi Adi, Wei-Ning Hsu, Ali Elkahky, Paden Tomasello, Robin Algayres, Benoît Sagot, Abdelrahman Mohamed, and Emmanuel Dupoux. Generative spoken dialogue language modeling.Trans. Assoc. Comput. Linguistics, 11:250–266, 2023
work page 2023
-
[35]
OpenAI. Gpt-4o system card.CoRR, abs/2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Librispeech: An ASR corpus based on public domain audio books
Vassil Panayotov, Guoguo Chen, Daniel Povey, and Sanjeev Khudanpur. Librispeech: An ASR corpus based on public domain audio books. In2015 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2015, South Brisbane, Queensland, Australia, April 19-24, 2015, pages 5206–5210. IEEE, 2015
work page 2015
-
[37]
MLS: A large-scale multilingual dataset for speech research
Vineel Pratap, Qiantong Xu, Anuroop Sriram, Gabriel Synnaeve, and Ronan Collobert. MLS: A large-scale multilingual dataset for speech research. In Helen Meng, Bo Xu, and Thomas Fang Zheng, editors,21st Annual Conference of the International Speech Communication Association, Interspeech 2020, Virtual Event, Shanghai, China, October 25-29, 2020, pages 2757–...
work page 2020
-
[38]
Robust speech recognition via large-scale weak supervision
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett, editors,International Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii...
work page 2023
-
[39]
SQuAD: 100,000+ questions for machine comprehension of text
Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. SQuAD: 100,000+ questions for machine comprehension of text. In Jian Su, Kevin Duh, and Xavier Carreras, editors,Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 2383–2392, Austin, Texas, November 2016. Association for Computational Linguistics
work page 2016
- [40]
-
[41]
Jianlin Su, Murtadha H. M. Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Ro- former: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
work page 2024
-
[42]
Drvoice: Parallel speech-text voice conversation model via dual-resolution speech representations
Chao-Hong Tan, Qian Chen, Wen Wang, Chong Deng, Qinglin Zhang, Luyao Cheng, Hai Yu, Xin Zhang, Xiang Lyu, Tianyu Zhao, Chong Zhang, Yukun Ma, Yafeng Chen, Hui Wang, Jiaqing Liu, Xiangang Li, and Jieping Ye. Drvoice: Parallel speech-text voice conversation model via dual-resolution speech representations. InThe Fourteenth International Conference on Learni...
work page 2026
-
[43]
Step-audio 2 technical report, 2025
StepFun Audio Team. Step-audio 2 technical report.CoRR, abs/2507.16632, 2025
-
[44]
Fun-audio-chat technical report.CoRR, abs/2512.20156, 2025
Tongyi Fun Team, Qian Chen, Luyao Cheng, Chong Deng, Xiangang Li, Jiaqing Liu, Chao- Hong Tan, Wen Wang, Junhao Xu, Jieping Ye, Qinglin Zhang, Qiquan Zhang, and Jingren Zhou. Fun-audio-chat technical report.CoRR, abs/2512.20156, 2025
-
[45]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Isabelle Guyon, Ulrike von Luxburg, Samy Bengio, Hanna M. Wallach, Rob Fergus, S. V . N. Vishwanathan, and Roman Garnett, editors,Advances in Neural Information Processing Systems 30: Annual Conference...
work page 2017
-
[46]
Beyond turn-based interfaces: Synchronous LLMs as full-duplex dialogue agents
Bandhav Veluri, Benjamin N Peloquin, Bokai Yu, Hongyu Gong, and Shyamnath Gollakota. Beyond turn-based interfaces: Synchronous LLMs as full-duplex dialogue agents. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 21390–21402, Miami, Florida, USA, Nov...
work page 2024
-
[47]
Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, and Emmanuel Dupoux. VoxPopuli: A large-scale multilingual speech corpus for representation learning, semi-supervised learning and interpretation. In Chengqing Zong, Fei Xia, Wenjie Li, and Roberto Navigli, editors,Proceedings of the 59th Annua...
work page 2021
-
[48]
Qichao Wang, Ziqiao Meng, Wenqian Cui, Yifei Zhang, Pengcheng Wu, Bingzhe Wu, Ir- win King, Liang Chen, and Peilin Zhao. NTPP: generative speech language modeling for dual-channel spoken dialogue via next-token-pair prediction. In Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste-Julien, Felix Berkenkamp, Tegan Maharaj, Kiri Wagstaff, and Jerry Zhu, ed...
work page 2025
-
[49]
Spark-tts: An efficient llm- based text-to-speech model with single-stream decoupled speech tokens,
Xinsheng Wang, Mingqi Jiang, Ziyang Ma, Ziyu Zhang, Songxiang Liu, Linqin Li, Zheng Liang, Qixi Zheng, Rui Wang, Xiaoqin Feng, Weizhen Bian, Zhen Ye, Sitong Cheng, Ruibin Yuan, Zhixian Zhao, Xinfa Zhu, Jiahao Pan, Liumeng Xue, Pengcheng Zhu, Yunlin Chen, Zhifei Li, Xie Chen, Lei Xie, Yike Guo, and Wei Xue. Spark-tts: An efficient llm-based text-to-speech ...
-
[50]
Freeze-omni: A smart and low latency speech-to-speech dialogue model with frozen LLM
Xiong Wang, Yangze Li, Chaoyou Fu, Yike Zhang, Yunhang Shen, Lei Xie, Ke Li, Xing Sun, and Long Ma. Freeze-omni: A smart and low latency speech-to-speech dialogue model with frozen LLM. In Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste-Julien, Felix Berkenkamp, Tegan Maharaj, Kiri Wagstaff, and Jerry Zhu, editors,Forty-second International Conferenc...
work page 2025
-
[51]
Zhifei Xie and Changqiao Wu. Mini-omni2: Towards open-source gpt-4o with vision, speech and duplex capabilities.CoRR, abs/2410.11190, 2024. 14
-
[52]
Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Yang Fan, Kai Dang, Bin Zhang, Xiong Wang, Yunfei Chu, and Junyang Lin. Qwen2.5-omni technical report.CoRR, abs/2503.20215, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. HotpotQA: A dataset for diverse, explainable multi-hop question answering. In Ellen Riloff, David Chiang, Julia Hockenmaier, and Jun’ichi Tsujii, editors, Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processi...
work page 2018
-
[54]
Flm-audio: Natural monologues improves native full-duplex chatbots via dual training
Yiqun Yao, Xiang Li, Xin Jiang, Xuezhi Fang, Naitong Yu, Wenjia Ma, Aixin Sun, and Yequan Wang. Flm-audio: Natural monologues improves native full-duplex chatbots via dual training. CoRR, abs/2509.02521, 2025
-
[55]
Wenyi Yu, Siyin Wang, Xiaoyu Yang, Xianzhao Chen, Xiaohai Tian, Jun Zhang, Guangzhi Sun, Lu Lu, Yuxuan Wang, and Chao Zhang. Salmonn-omni: A standalone speech LLM without codec injection for full-duplex conversation.CoRR, abs/2505.17060, 2025
-
[56]
Aohan Zeng, Zhengxiao Du, Mingdao Liu, Kedong Wang, Shengmin Jiang, Lei Zhao, Yuxiao Dong, and Jie Tang. Glm-4-voice: Towards intelligent and human-like end-to-end spoken chatbot.CoRR, abs/2412.02612, 2024
-
[57]
SpeechGPT: Empowering large language models with intrinsic cross-modal conversational abilities
Dong Zhang, Shimin Li, Xin Zhang, Jun Zhan, Pengyu Wang, Yaqian Zhou, and Xipeng Qiu. SpeechGPT: Empowering large language models with intrinsic cross-modal conversational abilities. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Findings of the Association for Computational Linguistics: EMNLP 2023, pages 15757–15773, Singapore, December 2023. Asso...
work page 2023
-
[58]
STEER: semantic turn extension-expansion recognition for voice assistants
Leon Liyang Zhang, Jiarui Lu, Joel Ruben Antony Moniz, Aditya Kulkarni, Dhivya Piraviperu- mal, Tien Dung Tran, Nick Tzou, and Hong Yu. STEER: semantic turn extension-expansion recognition for voice assistants. In Mingxuan Wang and Imed Zitouni, editors,Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: EMNLP 2023 - In...
work page 2023
-
[59]
OmniFlatten: An end-to-end GPT model for seamless voice conversation
Qinglin Zhang, Luyao Cheng, Chong Deng, Qian Chen, Wen Wang, Siqi Zheng, Jiaqing Liu, Hai Yu, Chao-Hong Tan, Zhihao Du, and ShiLiang Zhang. OmniFlatten: An end-to-end GPT model for seamless voice conversation. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Proceedings of the 63rd Annual Meeting of the Association f...
work page 2025
-
[60]
Beyond the turn-based game: Enabling real-time conversations with duplex models
Xinrong Zhang, Yingfa Chen, Shengding Hu, Xu Han, Zihang Xu, Yuanwei Xu, Weilin Zhao, Maosong Sun, and Zhiyuan Liu. Beyond the turn-based game: Enabling real-time conversations with duplex models. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 1154...
work page 2024
-
[61]
Please transcribe the following audio into text
Siyi Zhou, Yiquan Zhou, Yi He, Xun Zhou, Jinchao Wang, Wei Deng, and Jingchen Shu. Indextts2: A breakthrough in emotionally expressive and duration-controlled auto-regressive zero-shot text-to-speech. In Sven Koenig, Chad Jenkins, and Matthew E. Taylor, editors,Fortieth AAAI Conference on Artificial Intelligence, Thirty-Eighth Conference on Innovative App...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.