Recognition: no theorem link
MemReread: Enhancing Agentic Long-Context Reasoning via Memory-Guided Rereading
Pith reviewed 2026-05-12 05:18 UTC · model grok-4.3
The pith
MemReread recovers discarded facts by rereading only when final memory is insufficient, enabling linear-time long-context reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MemReread circumvents intermediate retrieval by triggering question decomposition and rereading when the final memory is insufficient. This enables the recovery of indirect facts prematurely discarded during streaming memory updates. The method supports non-linear reasoning paths while preserving the document's inherent logical flow and uses RL to control rereading based on task complexity for better length extrapolation.
What carries the argument
The memory insufficiency trigger for question decomposition and targeted rereading, integrated with a reinforcement learning framework for dynamic pass determination and length extrapolation.
Load-bearing premise
Rereading triggered only on final-memory insufficiency reliably recovers indirect facts that were discarded during initial memory formation without introducing new errors or requiring excessive passes.
What would settle it
Running MemReread on a long-context benchmark where it fails to improve accuracy over simple memory baselines or shows runtime scaling faster than linear.
Figures











read the original abstract
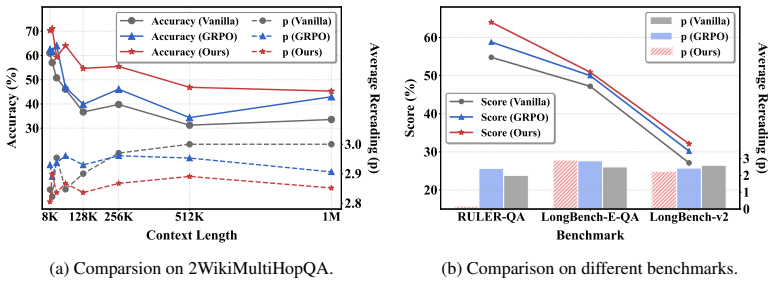
To tackle long-context reasoning tasks without the quadratic complexity of standard attention mechanisms, approaches based on agent memory have emerged, which typically maintain a dynamically updated memory when linearly processing document chunks. To mitigate the potential loss of latent evidence in this memorize-while-reading paradigm, recent works have integrated retrieval modules that allow agents to recall information previously discarded during memory overwriting. However, retrieval-based recall suffers from both evidence loss during memory formation and interference induced by invalid queries. To overcome these limitations, we propose MemReread. Built upon streaming reading, MemReread circumvents intermediate retrieval. It triggers question decomposition and rereading when the final memory is insufficient, enabling the recovery of indirect facts that were prematurely discarded. This design supports non-linear reasoning while preserving the inherent logical flow of document comprehension. To further enhance practicality, we introduce a reinforcement learning framework that enhances length extrapolation capability while dynamically determining the number of rereading passes based on task complexity, thereby flexibly controlling computational overhead. Extensive experiments demonstrate that MemReread consistently outperforms baseline frameworks on long-context reasoning tasks, while maintaining linear time complexity with respect to context length.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MemReread, a streaming-memory agent for long-context reasoning that avoids retrieval modules. It forms memory while linearly processing chunks and triggers question decomposition plus rereading only when the final memory is judged insufficient for the query. A reinforcement-learning controller is added to decide the number of rereading passes according to task complexity and to improve length extrapolation. The central claims are that this design recovers indirect facts more reliably than retrieval-based recall, consistently outperforms baselines on long-context reasoning tasks, and preserves linear time complexity in context length.
Significance. If validated, the shift from retrieval to memory-guided rereading could reduce evidence loss and invalid-query interference while preserving document logical flow. The RL-based dynamic control of rereading passes is a concrete strength for practical overhead management. These elements address a recognized limitation in current agent-memory systems and, if supported by rigorous experiments, would be a useful contribution to scalable long-context agent architectures.
major comments (2)
- [Abstract] Abstract: the central empirical claim ('extensive experiments demonstrate that MemReread consistently outperforms baseline frameworks') is load-bearing yet unsupported by any metrics, baselines, dataset sizes, or controls. Without these, the outperformance assertion cannot be evaluated.
- [Abstract] Abstract and method description: the linear-complexity guarantee rests on the assumption that the final-memory-insufficiency trigger plus RL controller produces a number of rereading passes that is O(1) on average and independent of context length. No analysis, bound, or ablation is supplied showing that pass count remains bounded when indirect facts are missed or when task difficulty increases with length; if passes grow with n the claimed O(n) complexity is violated.
minor comments (1)
- [Abstract] Abstract: the term 'non-linear reasoning' is introduced without definition; clarify whether it refers to the structure of reasoning steps or to computational complexity, as the latter would conflict with the linear-complexity claim.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and positive evaluation of the paper's potential contribution. We address each major comment below and plan to revise the manuscript to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim ('extensive experiments demonstrate that MemReread consistently outperforms baseline frameworks') is load-bearing yet unsupported by any metrics, baselines, dataset sizes, or controls. Without these, the outperformance assertion cannot be evaluated.
Authors: We agree that the abstract, being a concise summary, does not include specific numerical results. The full manuscript details the experimental setup, including the baselines (e.g., standard agent memory systems and retrieval-augmented variants), datasets used for long-context reasoning tasks, and quantitative metrics showing consistent outperformance. To address this, we will revise the abstract to include key performance highlights, such as average accuracy improvements and the specific tasks/datasets, while respecting length constraints. revision: yes
-
Referee: [Abstract] Abstract and method description: the linear-complexity guarantee rests on the assumption that the final-memory-insufficiency trigger plus RL controller produces a number of rereading passes that is O(1) on average and independent of context length. No analysis, bound, or ablation is supplied showing that pass count remains bounded when indirect facts are missed or when task difficulty increases with length; if passes grow with n the claimed O(n) complexity is violated.
Authors: We appreciate this point on the complexity analysis. While the RL controller is designed to adapt the number of rereading passes based on task complexity rather than context length, and our experiments demonstrate that the average number of passes remains small even for longer contexts, we acknowledge the lack of explicit ablation or theoretical bound in the current version. In the revision, we will add an analysis and ablation study showing the distribution of rereading passes across different context lengths to confirm that it does not scale with n, thereby supporting the linear complexity claim. revision: yes
Circularity Check
No circularity in derivation chain; proposal is architecturally independent
full rationale
The paper introduces MemReread as a new streaming-memory architecture with conditional rereading and an RL controller for pass count. No equations, first-principles derivations, or analytical predictions appear in the provided text. Claims of linear complexity and outperformance rest on the design description plus external experiments rather than any reduction of outputs to fitted inputs or self-citations by construction. The method is presented as an independent choice, not a tautological renaming or self-referential fit.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Rereading selected sections recovers indirect facts discarded during memory overwriting
Reference graph
Works this paper leans on
-
[1]
RULER: What's the Real Context Size of Your Long-Context Language Models?
Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shantanu Acharya, Dima Rekesh, Fei Jia, Yang Zhang, and Boris Ginsburg. Ruler: What’s the real context size of your long-context language models?arXiv preprint arXiv:2404.06654, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Yuri Kuratov, Aydar Bulatov, Petr Anokhin, Ivan Rodkin, Dmitry Sorokin, Artyom Sorokin, and Mikhail Burtsev. Babilong: Testing the limits of llms with long context reasoning-in-a-haystack.Advances in Neural Information Processing Systems, 37:106519–106554, 2024
work page 2024
-
[3]
Longbench v2: Towards deeper understanding and reasoning on realistic long-context multitasks
Yushi Bai, Shangqing Tu, Jiajie Zhang, Hao Peng, Xiaozhi Wang, Xin Lv, Shulin Cao, Jiazheng Xu, Lei Hou, Yuxiao Dong, et al. Longbench v2: Towards deeper understanding and reasoning on realistic long-context multitasks. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3639–3664, 2025
work page 2025
-
[4]
Found in the middle: Calibrating positional attention bias improves long context utilization
Cheng-Yu Hsieh, Yung-Sung Chuang, Chun-Liang Li, Zifeng Wang, Long Le, Abhishek Kumar, James Glass, Alexander Ratner, Chen-Yu Lee, Ranjay Krishna, et al. Found in the middle: Calibrating positional attention bias improves long context utilization. InFindings of the Association for Computational Linguistics: ACL 2024, pages 14982–14995, 2024
work page 2024
-
[5]
Revisiting long-context modeling from context denoising perspective
Zecheng Tang, Baibei Ji, Juntao Li, Lijun Wu, Haijia Gui, and Min Zhang. Revisiting long-context modeling from context denoising perspective. InThe Fourteenth International Conference on Learning Representations, 2026. URLhttps://openreview.net/forum?id=xvGyyh6MG7
work page 2026
-
[6]
Training long-context llms efficiently via chunk-wise optimization
Wenhao Li, Yuxin Zhang, Gen Luo, Daohai Yu, and Rongrong Ji. Training long-context llms efficiently via chunk-wise optimization. InFindings of the Association for Computational Linguistics: ACL 2025, pages 2691–2700, 2025
work page 2025
-
[7]
LongloRA: Efficient fine-tuning of long-context large language models
Yukang Chen, Shengju Qian, Haotian Tang, Xin Lai, Zhijian Liu, Song Han, and Jiaya Jia. LongloRA: Efficient fine-tuning of long-context large language models. InThe Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id=6PmJoRfdaK
work page 2024
-
[8]
Wenhao Li, Daohai Yu, Gen Luo, Yuxin Zhang, Yifan Wu, Jiaxin Liu, Ziyang Gong, Zimu Liao, Fei Chao, and Rongrong Ji. Out of the memory barrier: A highly memory-efficient training system for LLMs with million-token contexts. InThe Fourteenth International Conference on Learning Representations, 2026. URLhttps://openreview.net/forum?id=dSa3ImCQr7
work page 2026
-
[9]
Wenyu Tao, Xiaofen Xing, Zeliang Li, and Xiangmin Xu. Saki-rag: Mitigating context fragmentation in long-document rag via sentence-level attention knowledge integration. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 1195–1213, 2025
work page 2025
-
[10]
Memagent: Reshaping long-context LLM with multi- conv RL-based memory agent
Hongli Yu, Tinghong Chen, Jiangtao Feng, Jiangjie Chen, Weinan Dai, Qiying Yu, Ya-Qin Zhang, Wei-Ying Ma, Jingjing Liu, Mingxuan Wang, and Hao Zhou. Memagent: Reshaping long-context LLM with multi- conv RL-based memory agent. InThe Fourteenth International Conference on Learning Representations,
-
[11]
URLhttps://openreview.net/forum?id=k5nIOvYGCL
-
[12]
Look back to reason forward: Revisitable memory for long-context LLM agents
Yaorui Shi, Yuxin Chen, Siyuan Wang, Sihang Li, Hengxing Cai, Qi GU, Xiang Wang, and An Zhang. Look back to reason forward: Revisitable memory for long-context LLM agents. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum? id=1cymflI2Lh
work page 2026
-
[13]
Xinyu Wang, Mingze Li, Peng Lu, Xiao-Wen Chang, Lifeng Shang, Jinping Li, Fei Mi, Prasanna Parthasarathi, and Yufei Cui. Infmem: Learning system-2 memory control for long-context agent.arXiv preprint arXiv:2602.02704, 2026
-
[14]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Qwen2.5: A party of foundation models, September 2024
Qwen Team. Qwen2.5: A party of foundation models, September 2024. URL https://qwenlm.github. io/blog/qwen2.5/
work page 2024
-
[16]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
DRPO: Efficient reasoning via decoupled reward policy optimization
Gang Li, Yan Chen, Ming Lin, and Tianbao Yang. DRPO: Efficient reasoning via decoupled reward policy optimization. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=GP5RHZnEsw. 10
work page 2026
-
[18]
Hotpotqa: A dataset for diverse, explainable multi-hop question answering
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D Manning. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. InProceedings of the 2018 conference on empirical methods in natural language processing, pages 2369–2380, 2018
work page 2018
-
[19]
Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps
Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, and Akiko Aizawa. Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps. InProceedings of the 28th International Conference on Computational Linguistics, pages 6609–6625, 2020
work page 2020
-
[20]
The curious case of neural text degeneration
Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. The curious case of neural text degeneration. InInternational Conference on Learning Representations, 2020. URL https: //openreview.net/forum?id=rygGQyrFvH
work page 2020
-
[21]
Longbench: A bilingual, multitask benchmark for long context understanding
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, et al. Longbench: A bilingual, multitask benchmark for long context understanding. InProceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers), pages 3119–3137, 2024
work page 2024
-
[22]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces.arXiv preprint arXiv:2312.00752, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
Griffin: Mixing gated linear recurrences with local attention for e fficient language models
Soham De, Samuel L Smith, Anushan Fernando, Aleksandar Botev, George Cristian-Muraru, Albert Gu, Ruba Haroun, Leonard Berrada, Yutian Chen, Srivatsan Srinivasan, et al. Griffin: Mixing gated linear recurrences with local attention for efficient language models.arXiv preprint arXiv:2402.19427, 2024
-
[24]
Jamba: A Hybrid Transformer-Mamba Language Model
Opher Lieber, Barak Lenz, Hofit Bata, Gal Cohen, Jhonathan Osin, Itay Dalmedigos, Erez Safahi, Shaked Meirom, Yonatan Belinkov, Shai Shalev-Shwartz, et al. Jamba: A hybrid transformer-mamba language model.arXiv preprint arXiv:2403.19887, 2024
work page internal anchor Pith review arXiv 2024
-
[25]
Leave no context behind: Efficient infinite context transformers with infini-attention
Tsendsuren Munkhdalai, Manaal Faruqui, and Siddharth Gopal. Leave no context behind: Efficient infinite context transformers with infini-attention.arXiv preprint arXiv:2404.07143, 101:15, 2024
-
[26]
Ring Attention with Blockwise Transformers for Near-Infinite Context
Hao Liu, Matei Zaharia, and Pieter Abbeel. Ring attention with blockwise transformers for near-infinite context, 2023.URL https://arxiv. org/abs/2310.01889, 7, 1889
work page internal anchor Pith review arXiv 2023
-
[27]
Efficient Streaming Language Models with Attention Sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks.arXiv preprint arXiv:2309.17453, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
Extending Context Window of Large Language Models via Positional Interpolation
Shouyuan Chen, Sherman Wong, Liangjian Chen, and Yuandong Tian. Extending context window of large language models via positional interpolation.URL https://arxiv. org/abs/2306.15595, 2023
work page internal anchor Pith review arXiv 2023
-
[29]
YaRN: Efficient Context Window Extension of Large Language Models
Bowen Peng, Jeffrey Quesnelle, Honglu Fan, and Enrico Shippole. Yarn: Efficient context window extension of large language models.arXiv preprint arXiv:2309.00071, 2023
work page internal anchor Pith review arXiv 2023
-
[30]
LongRoPE: Extending LLM context window beyond 2 million tokens
Yiran Ding, Li Lyna Zhang, Chengruidong Zhang, Yuanyuan Xu, Ning Shang, Jiahang Xu, Fan Yang, and Mao Yang. Longrope: Extending llm context window beyond 2 million tokens.arXiv preprint arXiv:2402.13753, 2024
-
[31]
Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
work page 2024
-
[32]
Memory in the Age of AI Agents
Yuyang Hu, Shichun Liu, Yanwei Yue, Guibin Zhang, Boyang Liu, Fangyi Zhu, Jiahang Lin, Honglin Guo, Shihan Dou, Zhiheng Xi, et al. Memory in the age of ai agents.arXiv preprint arXiv:2512.13564, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building production-ready ai agents with scalable long-term memory.arXiv preprint arXiv:2504.19413, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
A-mem: Agentic memory for LLM agents
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. A-mem: Agentic memory for LLM agents. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URLhttps://openreview.net/forum?id=FiM0M8gcct
work page 2025
-
[35]
Memos: A memory os for ai system
Zhiyu Li, Chenyang Xi, Chunyu Li, Ding Chen, Boyu Chen, Shichao Song, Simin Niu, Hanyu Wang, Jiawei Yang, Chen Tang, et al. Memos: A memory os for ai system.arXiv preprint arXiv:2507.03724, 2025
-
[36]
Evo-Memory: Benchmarking LLM Agent Test-time Learning with Self-Evolving Memory
Tianxin Wei, Noveen Sachdeva, Benjamin Coleman, Zhankui He, Yuanchen Bei, Xuying Ning, Mengting Ai, Yunzhe Li, Jingrui He, Ed H Chi, et al. Evo-memory: Benchmarking llm agent test-time learning with self-evolving memory.arXiv preprint arXiv:2511.20857, 2025. 11
work page internal anchor Pith review arXiv 2025
-
[37]
Xuechen Liang, Meiling Tao, Yinghui Xia, Jianhui Wang, Kun Li, Yijin Wang, Yangfan He, Jingsong Yang, Tianyu Shi, Yuantao Wang, et al. Sage: Self-evolving agents with reflective and memory-augmented abilities.Neurocomputing, 647:130470, 2025
work page 2025
-
[38]
A-MEM: Agentic Memory for LLM Agents
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. A-mem: Agentic memory for llm agents.arXiv preprint arXiv:2502.12110, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
arXiv preprint arXiv:2601.21468 , year=
Yaorui Shi, Shugui Liu, Yu Yang, Wenyu Mao, Yuxin Chen, Qi Gu, Hui Su, Xunliang Cai, Xiang Wang, and An Zhang. Memocr: Layout-aware visual memory for efficient long-horizon reasoning.arXiv preprint arXiv:2601.21468, 2026
-
[40]
Reinforcement learning: A survey
Leslie Pack Kaelbling, Michael L Littman, and Andrew W Moore. Reinforcement learning: A survey. Journal of artificial intelligence research, 4:237–285, 1996
work page 1996
-
[41]
Towards Reasoning Era: A Survey of Long Chain-of-Thought for Reasoning Large Language Models
Qiguang Chen, Libo Qin, Jinhao Liu, Dengyun Peng, Jiannan Guan, Peng Wang, Mengkang Hu, Yuhang Zhou, Te Gao, and Wanxiang Che. Towards reasoning era: A survey of long chain-of-thought for reasoning large language models.arXiv preprint arXiv:2503.09567, 2025
work page internal anchor Pith review arXiv 2025
-
[42]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Xumeng Wen, Zihan Liu, Shun Zheng, Shengyu Ye, Zhirong Wu, Yang Wang, Zhijian Xu, Xiao Liang, Junjie Li, Ziming Miao, Jiang Bian, and Mao Yang. Reinforcement learning with verifiable rewards implicitly incentivizes correct reasoning in base LLMs. InThe Fourteenth International Conference on Learning Representations, 2026. URLhttps://openreview.net/forum?i...
work page 2026
-
[44]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[45]
DAPO: An open-source LLM reinforcement learning system at scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, YuYue, Weinan Dai, Tiantian Fan, Gaohong Liu, Juncai Liu, LingJun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Ru Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Yuxuan Song, Xiangpeng Wei, Hao ...
work page 2026
-
[46]
GDPO: Group reward-Decoupled Normalization Policy Optimization for Multi-reward RL Optimization
Shih-Yang Liu, Xin Dong, Ximing Lu, Shizhe Diao, Peter Belcak, Mingjie Liu, Min-Hung Chen, Hongxu Yin, Yu-Chiang Frank Wang, Kwang-Ting Cheng, et al. Gdpo: Group reward-decoupled normalization policy optimization for multi-reward rl optimization.arXiv preprint arXiv:2601.05242, 2026
work page internal anchor Pith review arXiv 2026
-
[47]
Needle In A Haystack - Pressure Test for LLMs
Greg Kamradt. Needle In A Haystack - Pressure Test for LLMs. https://github.com/gkamradt/ LLMTest_NeedleInAHaystack, 2023. GitHub repository
work page 2023
-
[48]
Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts.Transactions of the association for computational linguistics, 12:157–173, 2024
work page 2024
-
[49]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe Eleventh International Conference on Learning Representations, 2023. URLhttps://openreview.net/forum?id=WE_vluYUL-X
work page 2023
-
[50]
On the impact of fine-tuning on chain-of- thought reasoning
Elita Lobo, Chirag Agarwal, and Himabindu Lakkaraju. On the impact of fine-tuning on chain-of- thought reasoning. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 11679–11698, 2025
work page 2025
-
[51]
Alibaba Cloud Model Studio Docs
Qwen Team. Alibaba Cloud Model Studio Docs. https://modelstudio.console.alibabacloud. com/, 2026
work page 2026
-
[52]
DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence
DeepSeek-AI. DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence. https: //huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf , 2026. Tech- nical Report
work page 2026
-
[53]
Doubao Large Model Series Documentation
ByteDance Seed. Doubao Large Model Series Documentation. https://www.volcengine.com/docs/ 82379/1099320, 2026
work page 2026
-
[54]
Gemini 2.5 Flash Model Overview
Google. Gemini 2.5 Flash Model Overview. https://cloud.google.com/vertex-ai/ generative-ai/docs/models/gemini/2-5-flash, 2025
work page 2025
-
[55]
Event X occurred at Location M
OpenAI. Introducing GPT-4.1 in the API.https://openai.com/index/gpt-4-1/, 2025. 12 A Related Work A.1 Memory-Augmented LLM Agents The quadratic computational complexity of self-attention has spurred extensive research into attention- efficient sequence modeling architectures [21–30]. While these variants establish viable foundations for extended-context r...
work page 2025
-
[56]
Do not attempt to answer or re-query any other questions
Focus on QUESTION: Evaluate only whether MEMORY can answer the current QUESTION. Do not attempt to answer or re-query any other questions
-
[57]
Identify if any crucial facts are still missing, uncertain, or incomplete
Compare needs with MEMORY: Break the QUESTION down into specific information needs and compare them with what the MEMORY already contains. Identify if any crucial facts are still missing, uncertain, or incomplete
-
[58]
Review QUERY_HISTORY: Avoid repeating any query already asked and recorded in QUERY_HISTORY
-
[59]
Your output must strictly follow the decision logic below
You MUST NOT answer the QUESTION directly. Your output must strictly follow the decision logic below. Decision Logic & Actions: - IF SUFFICIENT: If the MEMORY already contains all necessary information to fully address the QUESTION, you must stop immediately. Do not generate any query and do not generate any further text. - IF INSUFFICIENT: If the MEMORY ...
-
[60]
Review the history carefully and ensure your proposed query is novel and represents genuine progress
No Repetition: The query must NOT duplicate any query already present in the QUERY_HISTORY . Review the history carefully and ensure your proposed query is novel and represents genuine progress
-
[61]
Independence: The query must be answerable in isolation without requiring answers to other queries
-
[62]
Sufficiency: Resolving this query, combined with the existing MEMORY , must meaningfully progress toward fully resolving the QUESTION
-
[63]
Self-Contained Expression: The query must be fully self-contained and free of any references to the original QUESTION, MEMORY , or external context. Never use pronouns, option labels, or context-dependent phrases like "the entity mentioned above", "option A", or "this event". Instead, explicitly state all relevant entities, values, and content
-
[64]
Output exactly one query; never submit multiple queries
Output Format: Submit exclusively this single highest-priority query by wrapping it in <query> tags. Output exactly one query; never submit multiple queries
-
[65]
Confirmed Information Exclusion: Do NOT generate a query targeting any information enclosed within <confirmed>...</confirmed> tags in the MEMORY . These tags denote facts, evidence, or confirmed absences that have already been explicitly verified and resolved. Only generate queries for information whose existence, value, or status remains uncertain, ambig...
-
[66]
Do not answer the original QUESTION directly; your sole output is the integrated MEMORY
-
[67]
When information in the reference conflicts with existing MEMORY content, prioritize the reference information as it represents fresh research
-
[68]
Eliminate redundant information; if a fact already exists in MEMORY , do not add it again
-
[69]
Filter out any information irrelevant to the original QUESTION; retain only content that contributes to answering it
-
[70]
Express all integrated information in fluent, coherent natural language. Do not copy the reference verbatim; instead, extract key facts and synthesize them into descriptive prose
-
[71]
This cross-source consistency indicates higher reliability
Cross-Source Evidence Tagging: Wrap a statement in <confirmed>...</confirmed> tags if the exact same factual claim (regarding existence, occurrence, or verified absence of evidence) appears in BOTH the current <memory> input AND the <subanswer> section of the reference. This cross-source consistency indicates higher reliability. Do NOT tag information tha...
-
[72]
Preserve Existing Confirmed Tags: If the current <memory> already contains information enclosed in <con- firmed>...</confirmed> tags, and this information is not contradicted by the reference, retain these tagged segments verbatim in the updated MEMORY . Integrate them naturally into the surrounding prose without removing the tags. Your final output shoul...
work page 2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.