Recognition: no theorem link
Cortico-cerebellar modularity as an architectural inductive bias for efficient temporal learning
Pith reviewed 2026-05-12 05:05 UTC · model grok-4.3
The pith
The cortico-cerebellar RNN learns temporal tasks faster and to higher performance than standard recurrent networks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
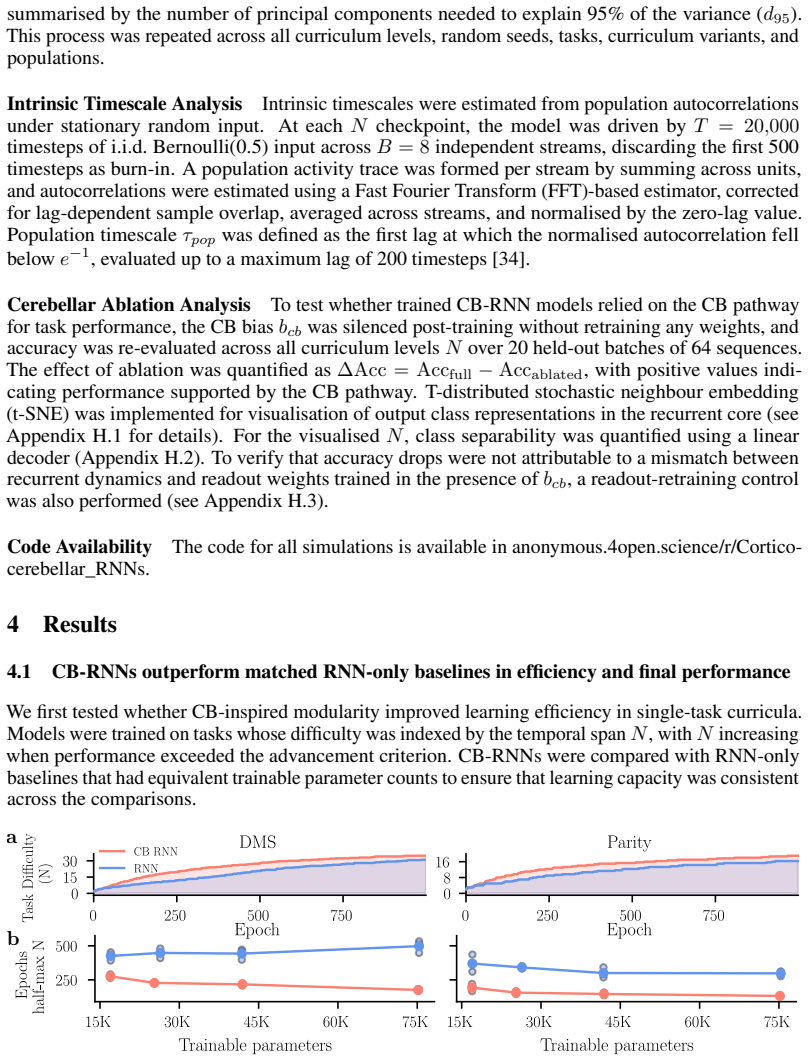
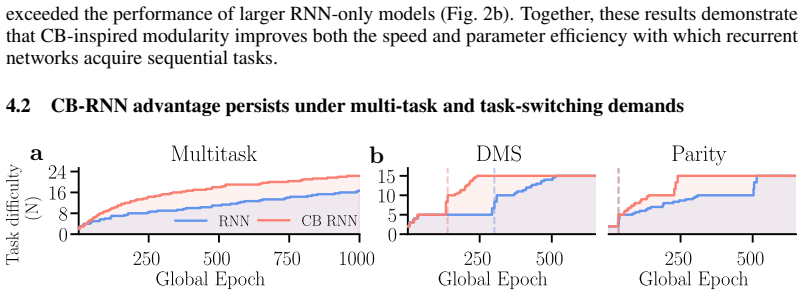
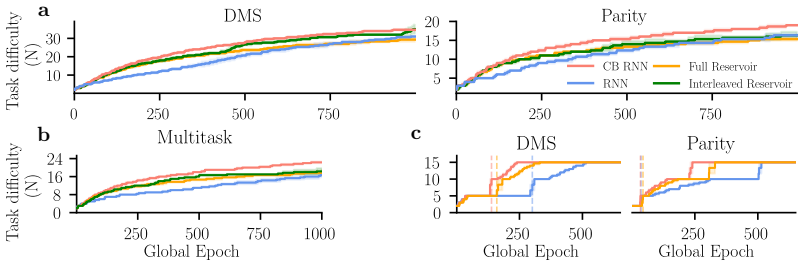
The cortico-cerebellar RNN augments a recurrent cortical module with a cerebellar-inspired feedforward module. This architecture produces faster learning and higher final performance on temporal tasks than parameter-matched fully recurrent baselines. The efficiency advantage survives when the recurrent core is frozen after minimal training and subsequent updates are restricted to the cerebellar module. The results indicate that the cerebellar module is the main source of the improvement and that the cortical recurrent network can largely serve as a fixed reservoir.
What carries the argument
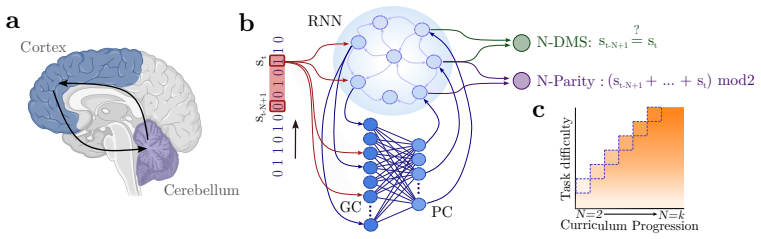
The heterogeneous modular architecture of the CB-RNN, formed by coupling a recurrent cortical core to a feedforward cerebellar module, which supplies a structural inductive bias for temporal learning.
If this is right
- The CB-RNN learns faster than fully recurrent baselines across temporal tasks of varying difficulty.
- It reaches higher maximum performance than the baselines.
- Freezing the recurrent core after minimal training and delegating learning to the cerebellar module preserves the efficiency gains.
- The cortical network can largely function as a fixed reservoir once initial training is complete.
- Heterogeneous modular architectures act as a structural inductive bias that improves learning in neural systems.
Where Pith is reading between the lines
- The same split could lower the cost of online adaptation in deployed recurrent models by limiting weight updates to the smaller module.
- The principle might generalize to other paired brain regions and corresponding artificial modules for non-temporal tasks.
- Testing the architecture on larger-scale sequence problems would reveal whether the efficiency benefit scales with network size.
- The results offer a concrete way to implement reservoir-style computation inside modern recurrent networks without hand-designing the reservoir.
Load-bearing premise
The performance gains arise specifically from the cerebellar-inspired modularity rather than from any unaccounted differences in effective capacity, initialization, or optimization dynamics.
What would settle it
An experiment that replaces the cerebellar module with a random feedforward network of identical size and connectivity statistics, then shows the performance gap disappears while all other factors remain matched, would falsify the claim.
Figures

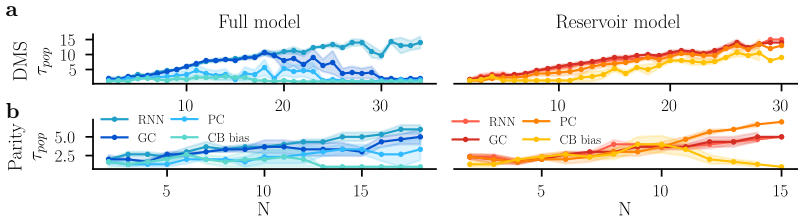
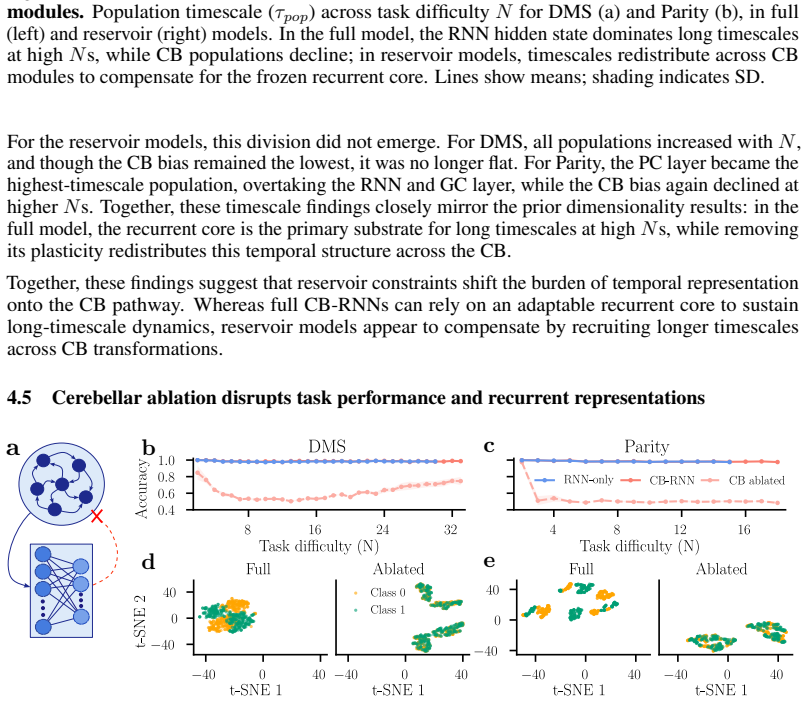
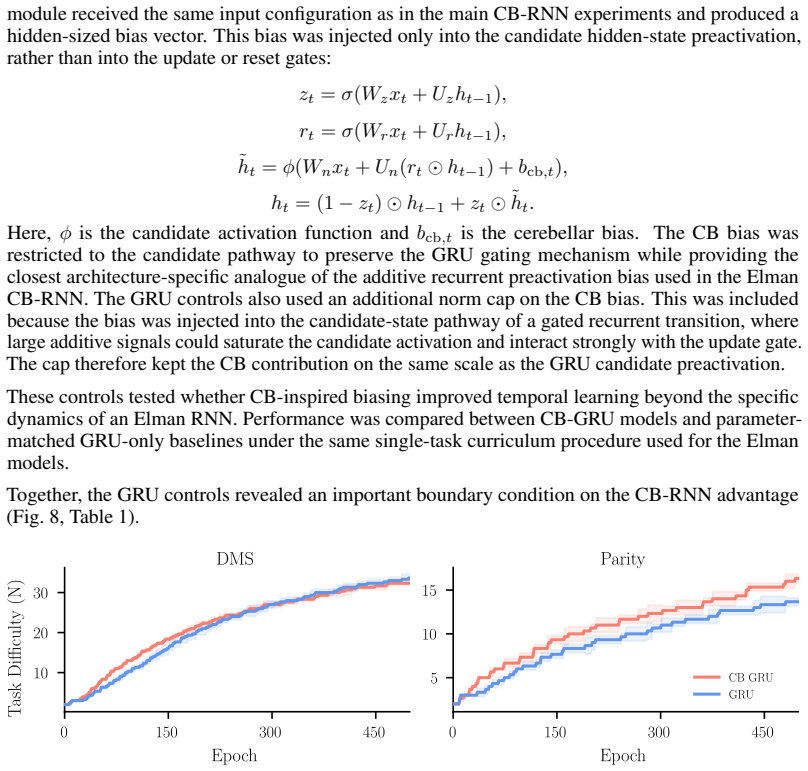


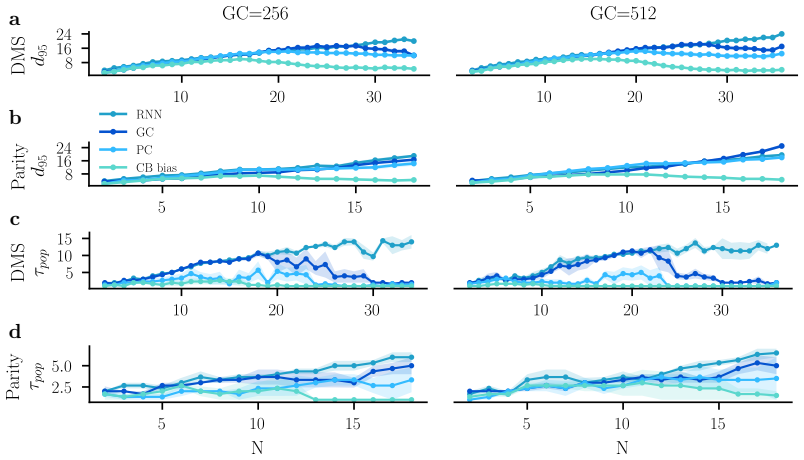


read the original abstract
The cerebellum and cerebral cortex form tightly coupled circuits thought to support flexible and efficient temporal processing. How this interaction shapes cortical learning dynamics, and whether such heterogeneous modularity can benefit artificial systems, remains unclear. Here, we augment a recurrent neural network (RNN) with a cerebellar-inspired feedforward module and evaluate the resulting architecture on temporal tasks of varying difficulty. The cortico-cerebellar RNN (CB-RNN) learns faster and reaches higher maximum performance than parameter-matched fully recurrent baselines across a variety of regimes. Crucially, freezing the recurrent core after minimal training and delegating subsequent learning to the cerebellar module preserves superior learning efficiency, suggesting the cerebellar module is a primary driver of efficiency and that the cortical network can largely function as a fixed reservoir. Our results suggest that heterogeneous modular architectures can act as a powerful structural inductive bias in neural systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a cortico-cerebellar RNN (CB-RNN) architecture that augments a recurrent cortical core with a cerebellar-inspired feedforward module. It claims that this hybrid model learns temporal tasks faster and achieves higher maximum performance than parameter-matched fully recurrent baselines. A key result is that freezing the recurrent core after minimal training and continuing learning only in the cerebellar module preserves the efficiency advantage, suggesting the cortical network can largely function as a fixed reservoir and that the cerebellar module is the primary driver of efficiency. The authors conclude that cortico-cerebellar modularity provides a structural inductive bias for efficient temporal learning.
Significance. If the empirical advantages are robust and specifically attributable to the proposed modularity rather than generic differences in recurrent size or optimization dynamics, the work would demonstrate that heterogeneous modular architectures inspired by biology can serve as effective inductive biases in artificial recurrent networks. The freezing protocol is a useful control for isolating the feedforward module's contribution and could inform more efficient RNN designs for temporal processing.
major comments (3)
- [Abstract] Abstract: the central claim that CB-RNN 'learns faster and reaches higher maximum performance' than parameter-matched fully recurrent baselines is presented without any quantitative metrics, effect sizes, learning-curve references, or statistical tests, preventing direct evaluation of the magnitude and reliability of the reported advantage.
- [Freezing experiment] Freezing experiment (described in abstract and results): while freezing the recurrent core after minimal training and training only the cerebellar module preserves superior efficiency, the design lacks a control condition using a randomly initialized fixed recurrent reservoir (not derived from the cortico-cerebellar architecture) paired with an equivalent feedforward module. This omission leaves open the possibility that any fixed recurrent core plus feedforward module would yield similar gains, undermining the attribution to cortico-cerebellar modularity specifically.
- [Architecture and experimental setup] Architecture and experimental setup: the claim of parameter-matched baselines requires explicit reporting of recurrent-unit counts (CB-RNN recurrent core must be smaller than the baseline to accommodate cerebellar parameters). Without this, differences in effective recurrent capacity, gradient propagation, or optimization landscape could explain the results independently of the modular inductive bias.
minor comments (2)
- [Results] All performance comparisons should report means and error bars across multiple random seeds together with appropriate statistical tests; this is especially important given the emphasis on 'faster learning' and 'higher maximum performance'.
- [Methods] A schematic diagram or explicit equations defining the cerebellar-inspired feedforward module (connectivity, activation, parameter count) would improve clarity and reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive and insightful comments on our manuscript. We address each major comment point by point below, outlining the revisions we will make to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that CB-RNN 'learns faster and reaches higher maximum performance' than parameter-matched fully recurrent baselines is presented without any quantitative metrics, effect sizes, learning-curve references, or statistical tests, preventing direct evaluation of the magnitude and reliability of the reported advantage.
Authors: We agree that the abstract would benefit from greater specificity to allow immediate assessment of the claims. In the revised manuscript, we will update the abstract to include quantitative details such as approximate effect sizes for learning speed and peak performance (drawn from the main results), along with explicit references to the relevant learning curves and statistical tests reported in the results section. revision: yes
-
Referee: [Freezing experiment] Freezing experiment (described in abstract and results): while freezing the recurrent core after minimal training and training only the cerebellar module preserves superior efficiency, the design lacks a control condition using a randomly initialized fixed recurrent reservoir (not derived from the cortico-cerebellar architecture) paired with an equivalent feedforward module. This omission leaves open the possibility that any fixed recurrent core plus feedforward module would yield similar gains, undermining the attribution to cortico-cerebellar modularity specifically.
Authors: This is a fair and important point. Our freezing protocol uses a minimally trained cortical core to show that the cerebellar module can sustain efficient learning, but we acknowledge that a random fixed-reservoir control would more cleanly isolate whether the advantage stems specifically from cortico-cerebellar modularity rather than any fixed recurrent component plus feedforward module. We will add this control condition in the revised manuscript. revision: yes
-
Referee: [Architecture and experimental setup] Architecture and experimental setup: the claim of parameter-matched baselines requires explicit reporting of recurrent-unit counts (CB-RNN recurrent core must be smaller than the baseline to accommodate cerebellar parameters). Without this, differences in effective recurrent capacity, gradient propagation, or optimization landscape could explain the results independently of the modular inductive bias.
Authors: We thank the referee for highlighting this need for transparency. Although the total parameter counts are matched between conditions, we will revise the methods and results sections to explicitly report the number of recurrent units in the CB-RNN cortical core (reduced to accommodate cerebellar parameters) versus the fully recurrent baseline. This will allow readers to directly evaluate any differences in recurrent capacity or dynamics. revision: yes
Circularity Check
No circularity: purely empirical architecture comparison with no derivations or self-referential fitting.
full rationale
The paper contains no equations, derivations, fitted parameters presented as predictions, or load-bearing self-citations. All claims rest on direct simulation results comparing the CB-RNN to parameter-matched fully recurrent baselines, including the freezing experiment. These are external benchmarks (task performance metrics) that do not reduce to the paper's own inputs by construction. The skeptic concern about unaccounted capacity differences is a question of experimental controls, not circularity in any claimed derivation chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Dhireesha Kudithipudi, Mario Aguilar-Simon, Jonathan Babb, Maxim Bazhenov, Douglas Blackiston, Josh Bongard, Andrew P. Brna, Suraj Chakravarthi Raja, Nick Cheney, Jeff Clune, Anurag Daram, Stefano Fusi, Peter Helfer, Leslie Kay, Nicholas Ketz, Zsolt Kira, Soheil Kolouri, Jeffrey L. Krichmar, Sam Kriegman, Michael Levin, Sandeep Madireddy, Santosh Manicka,...
work page 2022
-
[2]
Brenden M. Lake, Tomer D. Ullman, Joshua B. Tenenbaum, and Samuel J. Gershman. Building machines that learn and think like people.Behavioral and Brain Sciences, 40:e253, 2017
work page 2017
-
[3]
Anirudh Goyal and Yoshua Bengio. Inductive biases for deep learning of higher-level cogni- tion.Proceedings of the Royal Society A: Mathematical, Physical and Engineering Sciences, 478(2266):20210068, October 2022
work page 2022
-
[4]
Marblestone, Greg Wayne, and Konrad P
Adam H. Marblestone, Greg Wayne, and Konrad P. Kording. Toward an Integration of Deep Learning and Neuroscience.Frontiers in Computational Neuroscience, 10, September 2016
work page 2016
-
[5]
Modularity is the Bedrock of Natural and Artificial Intelligence, February
Alessandro Salatiello. Modularity is the Bedrock of Natural and Artificial Intelligence, February
- [6]
-
[7]
A hierarchy of time-scales and the brain
Stefan J Kiebel, Jean Daunizeau, and Karl J Friston. A hierarchy of time-scales and the brain. PLoS computational biology, 4(11):e1000209, 2008
work page 2008
-
[8]
Earl K. Miller and Jonathan D. Cohen. An Integrative Theory of Prefrontal Cortex Function. Annual Review of Neuroscience, 24(1):167–202, March 2001
work page 2001
-
[9]
Valerio Mante, David Sussillo, Krishna V . Shenoy, and William T. Newsome. Context-dependent computation by recurrent dynamics in prefrontal cortex.Nature, 503(7474):78–84, November 2013
work page 2013
-
[10]
A theory of cerebellar cortex.The Journal of Physiology, 202(2):437–470, June 1969
David Marr. A theory of cerebellar cortex.The Journal of Physiology, 202(2):437–470, June 1969
work page 1969
-
[11]
N. Alex Cayco-Gajic and R. Angus Silver. Re-evaluating Circuit Mechanisms Underlying Pattern Separation.Neuron, 101(4):584–602, February 2019
work page 2019
-
[12]
Fredrik Johansson, Dan-Anders Jirenhed, Anders Rasmussen, Riccardo Zucca, and Germund Hesslow. Memory trace and timing mechanism localized to cerebellar Purkinje cells.Proceed- ings of the National Academy of Sciences of the United States of America, 111(41):14930–14934, October 2014
work page 2014
-
[13]
Frank A. Middleton and Peter L. Strick. Cerebellar Projections to the Prefrontal Cortex of the Primate.The Journal of Neuroscience, 21(2):700–712, January 2001
work page 2001
-
[14]
Zhenyu Gao, Courtney Davis, Alyse M. Thomas, Michael N. Economo, Amada M. Abrego, Karel Svoboda, Chris I. De Zeeuw, and Nuo Li. A cortico-cerebellar loop for motor planning. Nature, 563(7729):113–116, November 2018
work page 2018
-
[15]
Ben Deverett, Mikhail Kislin, David W. Tank, and Samuel S.-H. Wang. Cerebellar disruption impairs working memory during evidence accumulation.Nature Communications, 10(1):3128, July 2019
work page 2019
-
[16]
Verpeut, Silke Bergeler, Mikhail Kislin, F
Jessica L. Verpeut, Silke Bergeler, Mikhail Kislin, F. William Townes, Ugne Klibaite, Zahra M. Dhanerawala, Austin Hoag, Sanjeev Janarthanan, Caroline Jung, Junuk Lee, Thomas J. Pisano, Kelly M. Seagraves, Joshua W. Shaevitz, and Samuel S.-H. Wang. Cerebellar contributions to a brainwide network for flexible behavior in mice.Communications Biology, 6(1):6...
work page 2023
-
[17]
Jeffrey L. Elman. Finding Structure in Time.Cognitive Science, 14(2):179–211, March 1990
work page 1990
-
[18]
Nicolas Perez-Nieves, Vincent C. H. Leung, Pier Luigi Dragotti, and Dan F. M. Goodman. Neural heterogeneity promotes robust learning.Nature Communications, 12(1):5791, October 2021
work page 2021
-
[19]
Soo, Vishwa Goudar, and Xiao-Jing Wang
Wayne W.M. Soo, Vishwa Goudar, and Xiao-Jing Wang. Training biologically plausible recurrent neural networks on cognitive tasks with long-term dependencies, October 2023
work page 2023
-
[20]
Versatile Learning without Synaptic Plasticity in a Spiking Neural Network.bioRxiv, January 2026
Kai Mason, Navid Akbari, Aaron Gruber, and Wilten Nicola. Versatile Learning without Synaptic Plasticity in a Spiking Neural Network.bioRxiv, January 2026
work page 2026
-
[21]
Perich, Luca Mazzucato, and Guillaume Lajoie
Ezekiel Williams, Alexandre Payeur, Avery Hee-Woon Ryoo, Thomas Jiralerspong, Matthew G. Perich, Luca Mazzucato, and Guillaume Lajoie. Expressivity of Neural Networks with Random Weights and Learned Biases, 2024. Version Number: 3
work page 2024
-
[22]
Daniele Caligiore, Giovanni Pezzulo, Gianluca Baldassarre, Andreea C. Bostan, Peter L. Strick, Kenji Doya, Rick C. Helmich, Michiel Dirkx, James Houk, Henrik Jörntell, Angel Lago-Rodriguez, Joseph M. Galea, R. Chris Miall, Traian Popa, Asha Kishore, Paul F. M. J. Verschure, Riccardo Zucca, and Ivan Herreros. Consensus Paper: Towards a Systems-Level View o...
work page 2017
-
[23]
Hirokazu Tanaka, Takahiro Ishikawa, Jongho Lee, and Shinji Kakei. The Cerebro-Cerebellum as a Locus of Forward Model: A Review.Frontiers in Systems Neuroscience, 14:19, April 2020
work page 2020
-
[24]
Abigail L. Person. Corollary Discharge Signals in the Cerebellum.Biological Psychiatry: Cognitive Neuroscience and Neuroimaging, 4(9):813–819, September 2019
work page 2019
-
[25]
Rancz, Taro Ishikawa, Ian Duguid, Paul Chadderton, Séverine Mahon, and Michael Häusser
Ede A. Rancz, Taro Ishikawa, Ian Duguid, Paul Chadderton, Séverine Mahon, and Michael Häusser. High-fidelity transmission of sensory information by single cerebellar mossy fibre boutons.Nature, 450(7173):1245–1248, December 2007
work page 2007
-
[26]
Catherine J. Stoodley and Peter T. Tsai. Adaptive Prediction for Social Contexts: The Cerebellar Contribution to Typical and Atypical Social Behaviors.Annual Review of Neuroscience, 44(V olume 44, 2021):475–493, July 2021
work page 2021
-
[27]
Ellen Boven, Joseph Pemberton, Paul Chadderton, Richard Apps, and Rui Ponte Costa. Cerebro- cerebellar networks facilitate learning through feedback decoupling.Nature Communications, 14(1):51, January 2023
work page 2023
-
[28]
Joseph Pemberton, Paul Chadderton, and Rui Ponte Costa. Cerebellar-driven cortical dynamics can enable task acquisition, switching and consolidation.Nature Communications, 15(1):10913, 2024
work page 2024
-
[29]
Leonardo Agueci and N. Alex Cayco-Gajic. Distributed learning across fast and slow neural systems supports efficient motor adaptation, June 2025. Pages: 2025.06.01.657238 Section: New Results
work page 2025
-
[30]
Rectifier nonlinearities improve neural network acoustic models
Andrew L Maas, Awni Y Hannun, and Andrew Y Ng. Rectifier nonlinearities improve neural network acoustic models. InProceedings of the 30th International Conference on Machine Learning, volume 30, Atlanta, Georgia, 2013
work page 2013
-
[31]
How to Construct Deep Recurrent Neural Networks, April 2014
Razvan Pascanu, Caglar Gulcehre, Kyunghyun Cho, and Yoshua Bengio. How to Construct Deep Recurrent Neural Networks, April 2014. arXiv:1312.6026 [cs]
-
[32]
Yu Sun, Xinhao Li, Karan Dalal, Jiarui Xu, Arjun Vikram, Genghan Zhang, Yann Dubois, Xinlei Chen, Xiaolong Wang, Sanmi Koyejo, et al. Learning to (learn at test time): Rnns with expressive hidden states.arXiv preprint arXiv:2407.04620, 2024
-
[33]
Sina Khajehabdollahi, Roxana Zeraati, Emmanouil Giannakakis, Tim Jakob Schäfer, Georg Martius, and Anna Levina. Emergent mechanisms for long timescales depend on training curriculum and affect performance in memory tasks. 2023. Version Number: 3. 11
work page 2023
-
[34]
Yoshua Bengio, Jérôme Louradour, Ronan Collobert, and Jason Weston. Curriculum learning. InProceedings of the 26th Annual International Conference on Machine Learning, ICML ’09, pages 41–48, New York, NY , USA, June 2009. Association for Computing Machinery
work page 2009
-
[35]
Roxana Zeraati, Tatiana A. Engel, and Anna Levina. A flexible Bayesian framework for unbiased estimation of timescales.Nature Computational Science, 2(3):193–204, March 2022
work page 2022
-
[36]
Müller, Fulvia Palesi, Kevin Y
Eli J. Müller, Fulvia Palesi, Kevin Y . Hou, Joshua Tan, Thomas Close, Claudia A. M. Gandini Wheeler-Kingschott, Egidio D’Angelo, Fernando Calamante, and James M. Shine. Parallel processing relies on a distributed, low-dimensional cortico-cerebellar architecture.Network Neuroscience, 7(2):844–863, June 2023
work page 2023
-
[37]
Jutta Peterburs, David Hofmann, Michael P. I. Becker, Alexander M. Nitsch, Wolfgang H. R. Miltner, and Thomas Straube. The role of the cerebellum for feedback processing and behavioral switching in a reversal-learning task.Brain and Cognition, 125:142–148, August 2018
work page 2018
-
[38]
Catherine J. Stoodley, Anila M. D’Mello, Jacob Ellegood, Vikram Jakkamsetti, Pei Liu, Mary Beth Nebel, Jennifer M. Gibson, Elyza Kelly, Fantao Meng, Christopher A. Cano, Juan M. Pascual, Stewart H. Mostofsky, Jason P. Lerch, and Peter T. Tsai. Altered cerebellar connectivity in autism and cerebellar-mediated rescue of autism-related behaviors in mice. Nat...
work page 2017
-
[39]
Sharon Israely, Hugo Ninou, Ori Rajchert, Lee Elmaleh, Ran Harel, Firas Mawase, Jonathan Kadmon, and Yifat Prut. Cerebellar output shapes cortical preparatory activity during motor adaptation.Nature Communications, 16(1):2574, March 2025
work page 2025
-
[40]
Matthew P. Kirschen, S. H. Annabel Chen, Pamela Schraedley-Desmond, and John E. Desmond. Load- and practice-dependent increases in cerebro-cerebellar activation in verbal working memory: an fMRI study.NeuroImage, 24(2):462–472, January 2005
work page 2005
-
[41]
Herzfeld, Damien Pastor, Adrian M
David J. Herzfeld, Damien Pastor, Adrian M. Haith, Yves Rossetti, Reza Shadmehr, and Jacinta O’Shea. Contributions of the cerebellum and the motor cortex to acquisition and retention of motor memories.NeuroImage, 98:147–158, September 2014
work page 2014
-
[42]
Hana Roš, Yizhou Xie, Sadra Sadeh, and R. Angus Silver. Population activity of mossy fibre axon input to the cerebellar cortex during behaviours, March 2025. Pages: 2025.03.23.644738 Section: New Results
work page 2025
-
[43]
Huu Hoang, Shinichiro Tsutsumi, Masanori Matsuzaki, Masanobu Kano, Mitsuo Kawato, Kazuo Kitamura, and Keisuke Toyama. Dynamic organization of cerebellar climbing fiber response and synchrony in multiple functional components reduces dimensions for reinforcement learning. eLife, 12:e86340, September 2023
work page 2023
-
[44]
The Cerebellar Thalamus.The Cerebel- lum, March 2019
Christophe Habas, Mario Manto, and Pierre Cabaraux. The Cerebellar Thalamus.The Cerebel- lum, March 2019
work page 2019
-
[45]
Masao Ito, Masaki Sakurai, and Pavich Tongroach. Climbing fibre induced depression of both mossy fibre responsiveness and glutamate sensitivity of cerebellar Purkinje cells.The Journal of Physiology, 324(1):113–134, March 1982
work page 1982
-
[46]
Lillicrap, Adam Santoro, Luke Marris, Colin J
Timothy P. Lillicrap, Adam Santoro, Luke Marris, Colin J. Akerman, and Geoffrey Hinton. Backpropagation and the brain.Nature Reviews Neuroscience, 21(6):335–346, June 2020
work page 2020
-
[47]
Local online learning in recurrent networks with random feedback.eLife, 8:e43299, May 2019
James M Murray. Local online learning in recurrent networks with random feedback.eLife, 8:e43299, May 2019
work page 2019
-
[48]
Guillaume Bellec, Franz Scherr, Anand Subramoney, Elias Hajek, Darjan Salaj, Robert Leg- enstein, and Wolfgang Maass. A solution to the learning dilemma for recurrent networks of spiking neurons.Nature Communications, 11(1):3625, July 2020. 12 A Compute resources. All experiments were run on a local workstation equipped with three NVIDIA GPUs: one GeForce...
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.