Recognition: no theorem link
Agentic Performance at the Edge: Insights from Benchmarking
Pith reviewed 2026-05-12 05:19 UTC · model grok-4.3
The pith
Edge agent quality depends on pairing the right small model with the right tool workflow, not on parameter count alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Our core finding is that edge-agent quality is not a simple function of parameter count. Robust deployment depends on the joint design of model choice and tool workflow. Domain-conditioned analysis reveals Pareto fronts in the accuracy-latency space that can guide strategy selection based on operational priorities, while failure-mode analysis shows distinct semantic versus execution patterns across model families.
What carries the argument
Domain-conditioned evaluation methodology applied to model-tool interactions under a fixed protocol, used to compare general-purpose and coder-oriented models on edge-constrained agentic tasks.
If this is right
- Smaller models can reach competitive agent performance when paired with suitable tool workflows.
- Distinct semantic and execution failure patterns appear across different model families.
- Accuracy-latency Pareto fronts exist and can inform model selection based on whether speed or correctness is prioritized.
- Practical guidance emerges for choosing models under specific memory and latency constraints.
Where Pith is reading between the lines
- Edge system designers may benefit from treating tool integration as a first-class design variable alongside model selection.
- The observed failure patterns suggest targeted fine-tuning or prompt engineering could address semantic errors more effectively than execution errors.
- Extending the same joint-design approach to other resource-constrained settings, such as mobile or embedded robotics, could yield similar gains.
Load-bearing premise
The chosen benchmarks and fixed interaction protocol adequately represent real-world agent performance limits on edge hardware.
What would settle it
Repeating the experiments on a new set of agentic tasks drawn from actual deployed IoT applications and finding that larger-parameter models consistently outperform smaller ones under identical tool workflows would falsify the claim.
Figures



read the original abstract
Agentic artificial intelligence (AI) is a natural fit for Internet of Things (IoT) and edge systems, but edge deployments are often constrained to models around 8 billion parameters or smaller. An important question is: How much agentic-task quality is lost when model size is constrained by memory, power, and latency budgets? To address this question, in this paper, we provide an initial empirical study considering edge-focused model scaling, general-purpose versus coder-oriented model effects, and tool-enabled execution under a fixed protocol. We introduce a domain-conditioned evaluation methodology, an implementation-grounded analysis of model-tool interactions, practical guidance for model selection under constraints, and an analysis of failure modes that reveals distinct semantic versus execution failure patterns across model families. Our core finding is that edge-agent quality is not a simple function of parameter count. Robust deployment depends on the joint design of model choice and tool workflow. Domain-conditioned analysis reveals Pareto fronts in the accuracy-latency space that can guide strategy selection based on operational priorities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents an empirical study of agentic AI performance under edge constraints (models ≤8B parameters). It benchmarks general-purpose versus coder-oriented models using tool-enabled execution under a fixed protocol, introduces domain-conditioned evaluation, analyzes model-tool interactions and failure modes (semantic vs. execution), and concludes that agent quality is not a simple function of parameter count but depends on the joint design of model choice and tool workflow, with Pareto fronts in accuracy-latency space guiding selection.
Significance. If the empirical patterns hold, the work supplies timely, practical guidance for IoT/edge agent deployment by showing that workflow design can compensate for size limits and by distinguishing failure types across model families. The domain-conditioned methodology and implementation-grounded interaction analysis are strengths that could inform reproducible follow-on studies.
major comments (2)
- [§3] §3 (Experimental Protocol): The fixed protocol for tool-enabled execution and domain-conditioned evaluation is described at a high level, but the manuscript provides insufficient detail on benchmark selection criteria, data exclusion rules, statistical controls for latency/power/memory enforcement, and variation across tool workflows. This setup is load-bearing for the central claim that observed patterns reflect real edge constraints rather than task-specific artifacts.
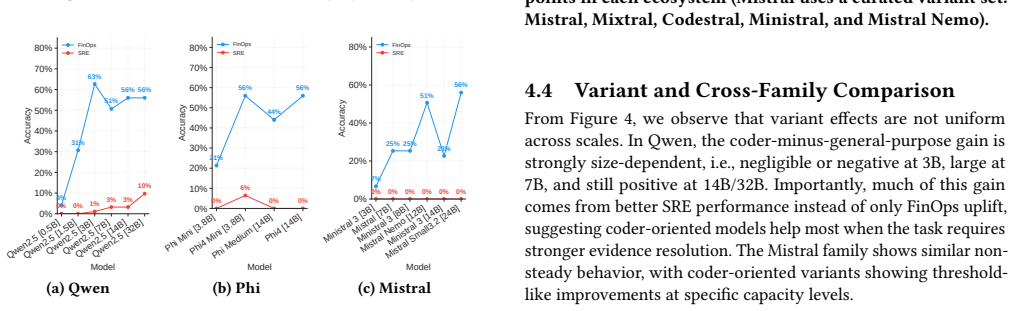
- [§4] §4 (Results): The claim that 'edge-agent quality is not a simple function of parameter count' requires explicit ablations or controls isolating the contribution of tool workflow from model size and family; without them, the joint-design conclusion risks post-hoc interpretation, especially given the observational nature of the study.
minor comments (2)
- [Abstract] The abstract and introduction use 'implementation-grounded analysis' without a clear pointer to the specific code, logs, or reproducibility artifacts that would allow readers to verify the model-tool interaction details.
- [Figures/Tables] Figure captions and table legends should explicitly state the number of runs, confidence intervals, and any multiple-comparison corrections applied to the accuracy-latency Pareto fronts.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We address the major comments point by point below, indicating the revisions we plan to make.
read point-by-point responses
-
Referee: [§3] §3 (Experimental Protocol): The fixed protocol for tool-enabled execution and domain-conditioned evaluation is described at a high level, but the manuscript provides insufficient detail on benchmark selection criteria, data exclusion rules, statistical controls for latency/power/memory enforcement, and variation across tool workflows. This setup is load-bearing for the central claim that observed patterns reflect real edge constraints rather than task-specific artifacts.
Authors: We concur that greater detail in the experimental protocol is necessary to support the reproducibility of our findings and to confirm that the results are driven by edge constraints. In the revised manuscript, we will augment §3 by providing: specific criteria used for benchmark selection and domain conditioning; explicit data exclusion rules applied during evaluation; comprehensive statistical controls, including the methodology for enforcing and measuring latency, power, and memory constraints with multiple runs and variance reporting; and an examination of performance variation across alternative tool workflows. These additions will mitigate concerns regarding potential task-specific artifacts. revision: yes
-
Referee: [§4] §4 (Results): The claim that 'edge-agent quality is not a simple function of parameter count' requires explicit ablations or controls isolating the contribution of tool workflow from model size and family; without them, the joint-design conclusion risks post-hoc interpretation, especially given the observational nature of the study.
Authors: Our manuscript presents evidence for this claim through systematic comparisons of general-purpose and coder-oriented models within a consistent tool-enabled framework, complemented by domain-specific Pareto front analyses and a breakdown of failure modes into semantic and execution categories that differ by model family. These elements demonstrate interactions between model choice and tool integration. Nevertheless, we recognize the value of more explicit ablations to isolate effects. We will incorporate additional ablation studies in the revision, such as controlled variations in tool availability across model sizes and families, to more rigorously separate the contributions and reduce the risk of post-hoc interpretations. revision: yes
Circularity Check
No circularity detected in empirical benchmarking study
full rationale
The paper is an observational empirical study that benchmarks edge-agent performance across model sizes, tool workflows, and failure modes under a fixed protocol. No derivation chain, equations, fitted parameters, or predictions are described that reduce by construction to the paper's own inputs. The core claim—that agent quality depends on joint model-tool design—arises directly from comparative experimental results rather than self-definitional normalizations, self-citation load-bearing premises, or renamed known results. The methodology is self-contained against external benchmarks and does not invoke uniqueness theorems or ansatzes from prior author work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The benchmarks and fixed protocol used are representative of real-world agentic tasks on edge devices
Reference graph
Works this paper leans on
-
[1]
Marah Abdin, Jyoti Aneja, et al. 2024. Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone.arXiv preprint arXiv:2404.14219(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Shuhao Chen, Weisen Jiang, et al. 2024. RouterDC: Query-Based Router by Dual Contrastive Learning for Assembling Large Language Models. InAdvances in Neural Information Processing Systems, Vol. 37. 66305–66328
work page 2024
-
[3]
Tim Dettmers, Artidoro Pagnoni, et al . 2023. QLoRA: Efficient Finetuning of Quantized LLMs. InAdvances in Neural Information Processing Systems, Vol. 36. 10088–10115
work page 2023
-
[4]
Saurabh Jha, Rohan R. Arora, et al. 2025. ITBench: Evaluating AI Agents across Diverse Real-World IT Automation Tasks. InProceedings of the 42nd Interna- tional Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 267). 27134–27197
work page 2025
-
[5]
Kaggle. 2026. ITBench Benchmark Leaderboard. https://www.kaggle.com/ benchmarks/ibm-research/itbench
work page 2026
-
[6]
Takeshi Kojima, Shixiang Shane Gu, et al. 2022. Large Language Models are Zero- Shot Reasoners. InAdvances in Neural Information Processing Systems, Vol. 35. 22199–22213
work page 2022
-
[7]
Xiao Liu, Hao Yu, et al. 2024. AgentBench: Evaluating LLMs as Agents. InThe Twelfth International Conference on Learning Representations. https://openreview. net/forum?id=zAdUB0aCTQ
work page 2024
-
[8]
Aman Madaan, Niket Tandon, et al. 2023. Self-Refine: Iterative Refinement with Self-Feedback. InAdvances in Neural Information Processing Systems, Vol. 36. 46534–46594
work page 2023
-
[9]
Grégoire Mialon, Clémentine Fourrier, et al. 2023. GAIA: a benchmark for General AI Assistants.arXiv preprint arXiv:2311.12983(2023)
work page internal anchor Pith review arXiv 2023
-
[10]
NVIDIA. 2024. Jetson Nano Developer Platform. https://developer.nvidia.com/ embedded/jetson-nano
work page 2024
-
[11]
Isaac Ong, Amjad Almahairi, et al. 2025. RouteLLM: Learning to Route LLMs from Preference Data. InThe Thirteenth International Conference on Learning Representations. https://openreview.net/forum?id=8sSqNntaMr
work page 2025
-
[12]
OpenAI. 2023. GPT-4 Technical Report.arXiv preprint arXiv:2303.08774(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [13]
-
[14]
Jason Wei, Xuezhi Wang, et al. 2022. Chain-of-Thought Prompting Elicits Rea- soning in Large Language Models. InAdvances in Neural Information Processing Systems, Vol. 35. 24824–24837
work page 2022
-
[15]
Herbert Woisetschläger, Ryan Zhang, et al. 2025. MESS+: Dynamically Learned Inference-Time LLM Routing in Model Zoos with Service Level Guarantees. In The Thirty-ninth Annual Conference on Neural Information Processing Systems. https://openreview.net/forum?id=wIM0y07NGX
work page 2025
-
[16]
Shunyu Yao, Jeffrey Zhao, et al. 2023. ReAct: Synergizing Reasoning and Act- ing in Language Models. InThe Eleventh International Conference on Learning Representations. https://openreview.net/forum?id=WE_vluYUL-X
work page 2023
-
[17]
Liangqi Yuan, Dong-Jun Han, et al. 2025. Local-Cloud Inference Offloading for LLMs in Multi-Modal, Multi-Task, Multi-Dialogue Settings. InProceedings of the Twenty-Sixth International Symposium on Theory, Algorithmic Foundations, and Protocol Design for Mobile Networks and Mobile Computing (MobiHoc ’25). 201–210
work page 2025
-
[18]
Peiyuan Zhang, Guangtao Zeng, et al. 2024. TinyLlama: An Open-Source Small Language Model.arXiv preprint arXiv:2401.02385(2024)
work page internal anchor Pith review arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.