Recognition: 2 theorem links
· Lean TheoremAnomalyClaw: A Universal Visual Anomaly Detection Agent via Tool-Grounded Refutation
Pith reviewed 2026-05-12 04:05 UTC · model grok-4.3
The pith
AnomalyClaw converts single-step VLM anomaly judgments into a multi-round refutation process that checks candidate anomalies against normal-sample references using a 13-tool library.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
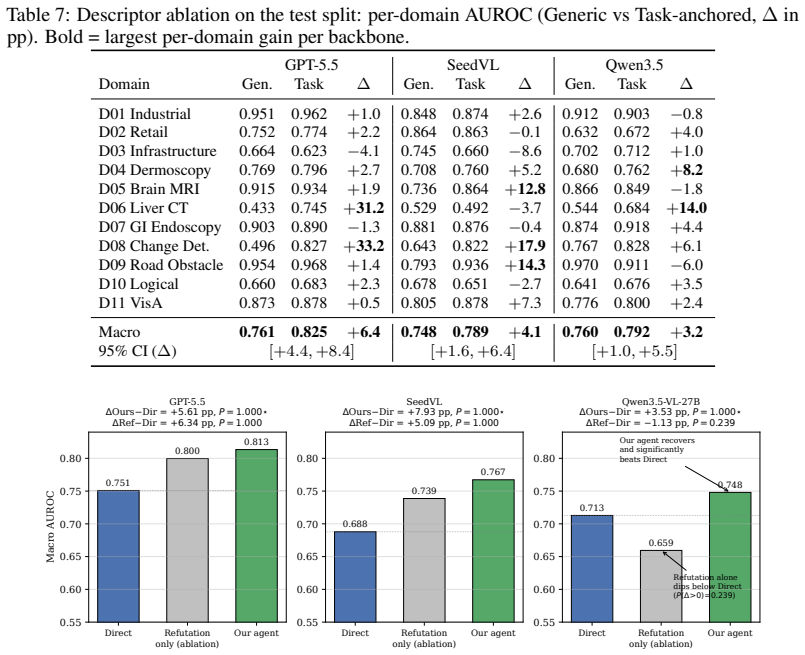
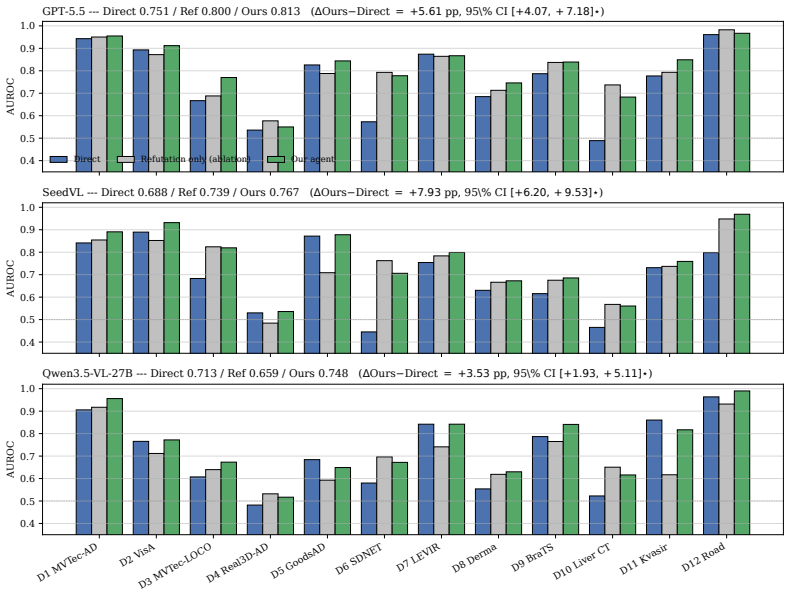
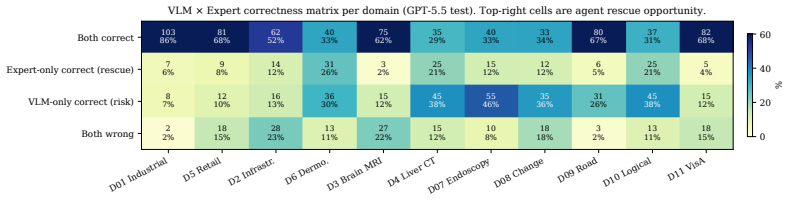
AnomalyClaw turns anomaly judgment into a multi-round refutation process in which candidate anomalies are proposed and then refuted against normal-sample references using a library of thirteen tools for visual verification, reference parsing, and frozen expert probing. On the CrossDomainVAD-12 benchmark the method raises macro-AUROC by 6.23 points with GPT-5.5, 7.93 points with Seed2.0-lite, and 3.52 points with Qwen3.5-VL-27B over direct single-step inference. An optional self-evolution extension builds an online rulebook from internal disagreements and adds a further 2.09 points on Qwen3.5-VL-27B without any oracle labels.
What carries the argument
The multi-round refutation process that proposes candidate anomalies and refutes each one against normal-sample references with a 13-tool library for visual verification, reference parsing, and frozen expert probing.
If this is right
- The same agentic loop produces measurable AUROC gains on three different VLMs without any task-specific training.
- An optional self-evolution step that derives rules from model disagreements adds further improvement comparable to a supervised baseline that uses ten labeled examples.
- The gains are attributed to better anomaly understanding rather than simple aggregation of tool outputs.
- The approach works across industrial, medical, infrastructure, and remote-sensing datasets despite differing anomaly definitions and modalities.
Where Pith is reading between the lines
- If the refutation loop succeeds mainly by forcing explicit comparison to normal samples, a smaller tool set focused only on reference comparison might achieve most of the benefit.
- The same pattern of proposing then refuting could be tested on other VLM tasks that currently suffer from over-reliance on priors, such as medical diagnosis or safety-critical scene understanding.
- The self-evolution rulebook could be made persistent across datasets, turning the agent into a growing knowledge base for cross-domain anomaly patterns.
Load-bearing premise
The multi-round refutation process with the 13-tool library reliably improves anomaly judgments by grounding them in normal-sample references and fine-grained feature evidence rather than from longer context or tool artifacts alone.
What would settle it
A controlled ablation that runs the same VLMs on the same twelve datasets once with the full multi-round refutation loop and once with an equivalent number of single-step inferences or random tool calls; if the AUROC gap disappears, the refutation mechanism is not the source of the gains.
Figures




read the original abstract
Visual anomaly detection (VAD) is crucial in many real-world fields, such as industrial inspection, medical imaging, infrastructure monitoring, and remote sensing. However, the specific anomaly definitions, data modalities, and annotation standards across different domains make it difficult to transfer single-domain trained VAD models. Vision-language models (VLMs), pre-trained on large-scale cross-domain data, can perform visual perception under task instructions, offering a promising solution for cross-domain VAD. However, single-inference VLM judgments are unreliable, since they rely more on prior knowledge than on normal-sample references or fine-grained feature evidence. We therefore present AnomalyClaw, a training-free VAD agent that turns anomaly judgment into a multi-round refutation process. In each round, the agent proposes candidate anomalies and refutes each against normal-sample references, drawing on a 13-tool library for visual verification, reference parsing, and frozen expert probing. On the CrossDomainVAD-12 benchmark (12 datasets), AnomalyClaw achieves consistent macro-AUROC improvements over single-step direct inference with +6.23 pp on GPT-5.5, +7.93 pp on Seed2.0-lite, and +3.52 pp on Qwen3.5-VL-27B. We further introduce an optional verbalized self-evolution extension. It builds an online rulebook from internal-branch disagreement without oracle labels. On Qwen3.5-VL-27B, it delivers a +2.09 pp mean gain, comparable to a K = 10 oracle-label supervised baseline (+1.99 pp). These results show that agentic refutation improve anomaly understanding and reasoning of VLMs, rather than merely aggregating tool outputs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AnomalyClaw, a training-free VLM-based agent for cross-domain visual anomaly detection that reformulates judgment as a multi-round refutation process grounded in a 13-tool library for verification, reference parsing, and expert probing. It reports consistent macro-AUROC gains over single-step direct inference on the CrossDomainVAD-12 benchmark (+6.23 pp on GPT-5.5, +7.93 pp on Seed2.0-lite, +3.52 pp on Qwen3.5-VL-27B) and shows that an optional verbalized self-evolution extension yields further gains comparable to a supervised K=10 baseline.
Significance. If the gains are shown to arise specifically from the refutation structure rather than increased inference budget, the work would provide evidence that agentic tool-grounded reasoning can improve VLM reliability for cross-domain VAD without any training. The training-free design and the self-evolution mechanism that builds an online rulebook from internal disagreements are clear strengths.
major comments (2)
- [Experiments (CrossDomainVAD-12 benchmark results)] The headline results in the CrossDomainVAD-12 experiments compare AnomalyClaw only against single-step direct inference. No ablation is reported that holds fixed the total number of VLM calls, total context tokens, or number of reasoning steps while removing the refutation loop and tool calls; without this control the observed deltas could be explained by longer chains alone.
- [Method (tool library description)] The claim that the 13-tool library enables grounding in normal-sample references and fine-grained evidence is central to the causal story, yet no ablation or sensitivity analysis is provided that isolates the contribution of individual tool categories (visual verification vs. reference parsing vs. expert probing).
minor comments (2)
- [Abstract] The abstract states that the self-evolution extension delivers +2.09 pp on Qwen3.5-VL-27B, comparable to the K=10 oracle baseline (+1.99 pp), but does not specify whether the comparison uses identical base models, prompt templates, or evaluation protocols.
- [Method] Notation for the multi-round refutation process (e.g., how candidate anomalies are proposed and refuted across rounds) would benefit from a concise algorithm box or diagram.
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful comments. We address each major point below and commit to revisions that strengthen the empirical support for our claims.
read point-by-point responses
-
Referee: The headline results in the CrossDomainVAD-12 experiments compare AnomalyClaw only against single-step direct inference. No ablation is reported that holds fixed the total number of VLM calls, total context tokens, or number of reasoning steps while removing the refutation loop and tool calls; without this control the observed deltas could be explained by longer chains alone.
Authors: We agree that an explicit control for inference budget is necessary to isolate the contribution of the refutation structure. The current experiments focus on the end-to-end comparison to direct inference, but we will add a new ablation in the revised manuscript. This ablation will match the total number of VLM calls and approximate token budget of AnomalyClaw while replacing the structured refutation loop and tool calls with unstructured repeated direct queries or generic chain-of-thought prompting. The results will clarify whether the observed gains arise from the tool-grounded refutation mechanism rather than increased computation alone. revision: yes
-
Referee: The claim that the 13-tool library enables grounding in normal-sample references and fine-grained evidence is central to the causal story, yet no ablation or sensitivity analysis is provided that isolates the contribution of individual tool categories (visual verification vs. reference parsing vs. expert probing).
Authors: We concur that category-level ablations would provide stronger evidence for the role of each tool group. The manuscript presents the 13-tool library as an integrated system supporting the refutation process. In the revision we will add sensitivity analyses that remove or disable entire categories (visual verification tools, reference parsing tools, and expert probing tools) one at a time and report the resulting macro-AUROC changes across the CrossDomainVAD-12 benchmark. These results will quantify the marginal contribution of each category to the grounding effect. revision: yes
Circularity Check
No circularity: empirical gains measured on external benchmarks without reduction to fitted inputs or self-definitions
full rationale
The paper's central result is an empirical performance comparison of a training-free agent (multi-round tool-grounded refutation with a fixed 13-tool library) against single-step VLM inference on the public CrossDomainVAD-12 benchmark. No equations, parameter fitting, or self-referential definitions appear in the reported chain; the macro-AUROC deltas are direct measurements against external baselines. The method description and optional self-evolution extension do not reduce the observed improvements to the inputs by construction, and no load-bearing self-citations or uniqueness theorems are invoked. This is a standard empirical evaluation setup with no detectable circularity.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
multi-round refutation process... 13-tool library for visual verification, reference parsing, and frozen expert probing
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat.induction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
verbalized self-evolution extension... builds an online rulebook from internal-branch disagreement
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Mvtec AD - A comprehensive real-world dataset for unsupervised anomaly detection
Paul Bergmann, Michael Fauser, David Sattlegger, and Carsten Steger. Mvtec AD - A comprehensive real-world dataset for unsupervised anomaly detection. InIEEE Confer- ence on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, June 16-20, 2019, pages 9592–9600. Computer Vision Foundation / IEEE, 2019. doi: 10.1109/CVPR.2019.00982. URL ...
-
[2]
Spot- the-difference self-supervised pre-training for anomaly detection and segmentation
Yang Zou, Jongheon Jeong, Latha Pemula, Dongqing Zhang, and Onkar Dabeer. Spot- the-difference self-supervised pre-training for anomaly detection and segmentation. In Computer Vision - ECCV 2022 - 17th European Conference, Tel Aviv, Israel, October 23- 27, 2022, Proceedings, Part XXX, Lecture Notes in Computer Science, pages 392–408. Springer, 2022. doi: ...
-
[3]
Ujjwal Baid, Satyam Ghodasara, Michel Bilello, Suyash Mohan, Evan Calabrese, Errol Colak, Keyvan Farahani, Jayashree Kalpathy-Cramer, Felipe C. Kitamura, Sarthak Pati, Luciano M. Prevedello, Jeffrey D. Rudie, Chiharu Sako, Russell T. Shinohara, Timothy Bergquist, Rong Chai, James A. Eddy, Julia Elliott, Walter Reade, Thomas Schaffter, Thomas Yu, Jiaxin Zh...
work page internal anchor Pith review arXiv 2021
-
[4]
Revisiting pre-trained remote sensing model benchmarks: Resizing and normalization matters
Jinan Bao, Hanshi Sun, Hanqiu Deng, Yinsheng He, Zhaoxiang Zhang, and Xingyu Li. BMAD: benchmarks for medical anomaly detection. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024 - Workshops, Seattle, WA, USA, June 17-18, 2024, pages 4042–4053. IEEE, 2024. doi: 10.1109/CVPRW63382.2024.00408. URL https://doi.org/ 10.1109/CVPRW6338...
-
[5]
Selvaraju, Michael Cogswell, Ab- hishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra
Krzysztof Lis, Krishna Kanth Nakka, Pascal Fua, and Mathieu Salzmann. Detecting the unexpected via image resynthesis. In2019 IEEE/CVF International Conference on Computer Vision, ICCV 2019, Seoul, Korea (South), October 27 - November 2, 2019, pages 2152–2161. IEEE, 2019. doi: 10.1109/ICCV .2019.00224. URLhttps://doi.org/10.1109/ICCV.2019. 00224
-
[6]
Sattar Dorafshan, Robert J. Thomas, and Marc Maguire. SDNET2018: An annotated image dataset for non-contact concrete crack detection using deep convolutional neural networks.Data in Brief, 21:1664–1668, 2018. doi: 10.1016/j.dib.2018.11.015. URL https://doi.org/10. 1016/j.dib.2018.11.015
-
[7]
Hao Chen and Zhenwei Shi. A spatial-temporal attention-based method and a new dataset for remote sensing image change detection.Remote Sensing, 12(10):1662, 2020. doi: 10.3390/ rs12101662. URLhttps://doi.org/10.3390/rs12101662
-
[8]
Jongheon Jeong, Yang Zou, Taewan Kim, Dongqing Zhang, Avinash Ravichandran, and Onkar Dabeer. Winclip: Zero-/few-shot anomaly classification and segmentation. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17-24, 2023, pages 19606–19616. IEEE, 2023. doi: 10.1109/CVPR52729.2023.01878. URLhttps://doi...
-
[9]
MMAD: A comprehensive benchmark for multimodal large language models in industrial anomaly detection
Xi Jiang, Jian Li, Hanqiu Deng, Yong Liu, Bin-Bin Gao, Yifeng Zhou, Jialin Li, Chengjie Wang, and Feng Zheng. MMAD: A comprehensive benchmark for multimodal large language models in industrial anomaly detection. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, 2025. URL https:/...
work page 2025
-
[10]
ViperGPT: Visual inference via python execution for reasoning
Dídac Surís, Sachit Menon, and Carl V ondrick. ViperGPT: Visual inference via python execution for reasoning. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 11888–11898, 2023
work page 2023
-
[11]
Visual programming: Compositional visual reasoning without training
Tanmay Gupta and Aniruddha Kembhavi. Visual programming: Compositional visual reasoning without training. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14953–14962, 2023
work page 2023
-
[12]
MM-REACT: Prompting ChatGPT for Multimodal Reasoning and Action
Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Ehsan Azarnasab, Faisal Ahmed, Zicheng Liu, Ce Liu, Michael Zeng, and Lijuan Wang. MM-ReAct: Prompting ChatGPT for multimodal reasoning and action.arXiv preprint arXiv:2303.11381, 2023
work page internal anchor Pith review arXiv 2023
-
[13]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R. Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models. InThe Eleventh International Conference on Learning Representations, ICLR 2023, 2023. URL https:// openreview.net/forum?id=WE_vluYUL-X
work page 2023
-
[14]
Toolformer: Language models can teach themselves to use tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools. InAdvances in Neural Information Processing Systems 36 (NeurIPS 2023), 2023. URL https://proceedings.neurips.cc/paper_files/paper/ 2023/hash/d842425e...
work page 2023
-
[16]
Dongwei Ji, Bingzhang Hu, and Yi Zhou. Autoiad: Manager-driven multi-agent collaboration for automated industrial anomaly detection.CoRR, abs/2508.05503, 2025. doi: 10.48550/ ARXIV .2508.05503. URLhttps://doi.org/10.48550/arXiv.2508.05503
-
[17]
Reflexion: Language agents with verbal reinforcement learning
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning. InAdvances in Neural Information Processing Systems 36 (NeurIPS 2023), 2023. URLhttps://openreview. net/forum?id=vAElhFcKW6
work page 2023
-
[18]
ExpeL: LLM agents are experiential learners
Andrew Zhao, Daniel Huang, Quentin Xu, Matthieu Lin, Yong-Jin Liu, and Gao Huang. ExpeL: LLM agents are experiential learners. InThirty-Eighth AAAI Conference on Artificial Intelligence, AAAI 2024, Vancouver, Canada, February 20-27, 2024, pages 19632–19642. AAAI Press, 2024. doi: 10.1609/AAAI.V38I17.29936. URL https://doi.org/10.1609/aaai. v38i17.29936
-
[19]
V oyager: An open-ended embodied agent with large language models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models. Trans. Mach. Learn. Res., 2024. URLhttps://openreview.net/forum?id=ehfRiF0R3a
work page 2024
-
[20]
A survey of visual sensory anomaly detection,
Xi Jiang, Guoyang Xie, Jinbao Wang, Yong Liu, Chengjie Wang, Feng Zheng, and Yaochu Jin. A survey of visual sensory anomaly detection.CoRR, abs/2202.07006, 2022. URL https://doi.org/10.48550/arXiv.2202.07006
-
[21]
Karsten Roth, Latha Pemula, Joaquin Zepeda, Bernhard Schölkopf, Thomas Brox, and Peter V . Gehler. Towards total recall in industrial anomaly detection. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18- 24, 2022, pages 14298–14308. IEEE, 2022. doi: 10.1109/CVPR52688.2022.01392. URL https://doi.org/...
-
[22]
SoftPatch: Unsupervised anomaly detection with noisy data
Xi Jiang, Ying Chen, Qiang Nie, Yong Liu, Jianlin Liu, Bin-Bin Gao, Jun Liu, Chengjie Wang, and Feng Zheng. SoftPatch: Unsupervised anomaly detection with noisy data. InAdvances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022, 2...
-
[23]
SoftPatch+: Fully unsupervised anomaly classification and segmentation.Pattern Recognition,
Chengjie Wang, Xi Jiang, Bin-Bin Gao, Zhenye Gan, Yong Liu, Feng Zheng, and Lizhuang Ma. SoftPatch+: Fully unsupervised anomaly classification and segmentation.Pattern Recognition,
-
[24]
URLhttps://doi.org/10.48550/arXiv.2412.20870
-
[25]
AnomalyCLIP: Object- agnostic prompt learning for zero-shot anomaly detection
Qihang Zhou, Guansong Pang, Yu Tian, Shibo He, and Jiming Chen. AnomalyCLIP: Object- agnostic prompt learning for zero-shot anomaly detection. InThe Twelfth International Con- ference on Learning Representations, ICLR 2024, Vienna, Austria, May 7–11, 2024. OpenRe- view.net, 2024. URLhttps://openreview.net/forum?id=buC4E91xZE
work page 2024
-
[26]
Dn-splatter: Depth and normal priors for gaussian splatting and meshing
Simon Damm, Mike Laszkiewicz, Johannes Lederer, and Asja Fischer. AnomalyDINO: Boost- ing patch-based few-shot anomaly detection with DINOv2. InIEEE/CVF Winter Confer- ence on Applications of Computer Vision, WACV 2025, Tucson, AZ, USA, February 26 - March 6, 2025, pages 1319–1329. IEEE, 2025. doi: 10.1109/W ACV61041.2025.00136. URL https://doi.org/10.110...
work page doi:10.1109/w 2025
-
[31]
Anoma- lygpt: Detecting industrial anomalies using large vision-language models
Zhaopeng Gu, Bingke Zhu, Guibo Zhu, Yingying Chen, Ming Tang, and Jinqiao Wang. Anoma- lygpt: Detecting industrial anomalies using large vision-language models. InThirty-Eighth AAAI Conference on Artificial Intelligence, AAAI 2024, Vancouver, Canada, February 20- 27, 2024, pages 1932–1940. AAAI Press, 2024. doi: 10.1609/AAAI.V38I3.27963. URL https://doi.o...
-
[34]
Self- refine: Iterative refinement with self-feedback
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. Self- refine: Iterative refinement with self-feedback. InAdvances in Neural Information Processing Sy...
work page 2023
-
[35]
Yilun Du, Shuang Li, Antonio Torralba, Joshua B. Tenenbaum, and Igor Mordatch. Improving factuality and reasoning in language models through multiagent debate. InProceedings of the 41st International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21–27, 2024, volume 235 ofProceedings of Machine Learning Research, pages 11733–11763. PMLR,
work page 2024
-
[36]
URLhttps://proceedings.mlr.press/v235/du24e.html. 12
-
[37]
Geoffrey Irving, Paul Christiano, and Dario Amodei. AI safety via debate.CoRR, abs/1805.00899, 2018. URLhttps://arxiv.org/abs/1805.00899
work page internal anchor Pith review arXiv 2018
-
[38]
Beyond dents and scratches: Logical constraints in unsupervised anomaly detection and localization
Paul Bergmann, Kilian Batzner, Michael Fauser, David Sattlegger, and Carsten Steger. Beyond dents and scratches: Logical constraints in unsupervised anomaly detection and localization. Int. J. Comput. Vis., 130(4):947–969, 2022. doi: 10.1007/S11263-022-01578-9. URL https: //doi.org/10.1007/s11263-022-01578-9
-
[39]
Jian Zhang, Runwei Ding, Miaoju Ban, and Linhui Dai. Pku-goodsad: A supermarket goods dataset for unsupervised anomaly detection and segmentation.IEEE Robotics Autom. Lett., 9 (3):2008–2015, 2024. doi: 10.1109/LRA.2024.3352358. URL https://doi.org/10.1109/ LRA.2024.3352358
-
[40]
Scientific Data7(1), 283 (2020)
Hanna Borgli, Vajira Thambawita, Pia H. Smedsrud, Steven Hicks, Debesh Jha, Sigrun L. Eskeland, Kristin Ranheim Randel, Konstantin Pogorelov, Mathias Lux, Duc Tien Dang Nguyen, Dag Johansen, Carsten Griwodz, Håkon K. Stensland, Enrique Garcia-Ceja, Peter T. Schmidt, Hugo L. Hammer, Michael A. Riegler, Pål Halvorsen, and Thomas de Lange. Hyperkvasir, a com...
-
[41]
Jiancheng Yang, Rui Shi, Donglai Wei, Zequan Liu, Lin Zhao, Bilian Ke, Hanspeter Pfister, and Bingbing Ni. Medmnist v2: A large-scale lightweight benchmark for 2d and 3d biomedical image classification.Scientific Data, 10(1):41, 2023. doi: 10.1038/s41597-022-01721-8. URL https://doi.org/10.1038/s41597-022-01721-8
-
[42]
Fisher Yu, Haofeng Chen, Xin Wang, Wenqi Xian, Yingying Chen, Fangchen Liu, Vashisht Madhavan, and Trevor Darrell. BDD100K: A diverse driving dataset for heterogeneous multitask learning. In2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, June 13-19, 2020, pages 2633–2642. Computer Vision Foundation / IEEE,...
-
[43]
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mido Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Hervé Jégou, Julien Mairal, Patrick L...
work page 2024
-
[44]
Real3D-AD: A dataset of point cloud anomaly detection
Jiaqi Liu, Guoyang Xie, Ruitao Chen, Xinpeng Li, Jinbao Wang, Yong Liu, Chengjie Wang, and Feng Zheng. Real3D-AD: A dataset of point cloud anomaly detection. InAdvances in Neural Information Processing Systems, 2023
work page 2023
-
[45]
SegmentMeIfYouCan: A benchmark for anomaly segmentation
Robin Chan, Krzysztof Lis, Svenja Uhlemeyer, Hermann Blum, Sina Honari, Roland Siegwart, Pascal Fua, Mathieu Salzmann, and Matthias Rottmann. SegmentMeIfYouCan: A benchmark for anomaly segmentation. InNeurIPS Datasets and Benchmarks Track, 2021
work page 2021
-
[46]
In: Proceedings of the 29th Symposium on Operating Systems Principles
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with PagedAttention. InProceedings of the 29th ACM Symposium on Operating Systems Principles (SOSP), pages 611–626, 2023. doi: 10.1145/3600006.3613165
-
[47]
Iad-r1: Reinforcing consistent reasoning in industrial anomaly detection,
Yanhui Li, Yunkang Cao, Chengliang Liu, Yuan Xiong, Xinghui Dong, and Chao Huang. IAD- R1: Reinforcing consistent reasoning in industrial anomaly detection.CoRR, abs/2508.09178,
-
[48]
Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks
doi: 10.48550/ARXIV .2508.09178. URL https://doi.org/10.48550/arXiv.2508. 09178
work page internal anchor Pith review doi:10.48550/arxiv
-
[49]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-VL technical report. a...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhangwei Gao, Erfei Cui, Jinguo Zhu, Shenglong Ye, Hao Tian, Zhaoyang Liu, Lixin Gu, Xuehui Wang, Qingyun Li, Yimin Ren, Zixuan Chen, Jiapeng Luo, Jiahao Wang, Tan Jiang, Bo Wang, Conghui He, Botian Shi, Xingcheng Zhang, Han Lv, Yi Wang, Wenqi Shao, Pei Chu, Zhongying Tu, Tong He, Zhiyong Wu, Huipeng Deng, Jia...
work page internal anchor Pith review Pith/arXiv arXiv
-
[51]
InternVL2-Llama3-76B) cited here
InternVL 2.5 technical report; covers the InternVL2 family (incl. InternVL2-Llama3-76B) cited here
-
[52]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini Team, Google. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context.arXiv preprint arXiv:2403.05530, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[53]
Doubao Team and ByteDance. Seed1.5-VL technical report.arXiv preprint arXiv:2505.07062, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[54]
Eiad: Explainable industrial anomaly detection via multi-modal large language models,
Zongyun Zhang, Jiacheng Ruan, Xian Gao, Ting Liu, and Yuzhuo Fu. EIAD: Explainable industrial anomaly detection via multi-modal large language models. InIEEE International Conference on Multimedia and Expo (ICME), 2025. arXiv:2503.14162. 14 Table 4: CrossDomainV AD-12 per-domain specification. ID Domain Source Anomaly definition Refs/item License D1 Indus...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.