Recognition: 2 theorem links
· Lean TheoremDon't Fix the Basis -- Learn It: Spectral Representation with Adaptive Basis Learning for PDEs
Pith reviewed 2026-05-12 04:21 UTC · model grok-4.3
The pith
Learning the spectral basis from data improves neural operators on PDEs with heterogeneous dynamics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose Adaptive Basis Learning (ABLE) to learn data-dependent spectral representations instead of using fixed bases. ABLE constructs a spatially adaptive Parseval frame from a learned ancillary density, enabling the operator to act in a lifted spectral space while preserving invertibility and O(N log N) complexity via FFT. This moves the source of expressivity from the spectral coefficients to the representation itself, allowing more efficient modeling of localized structures and non-translation-invariant interactions.
What carries the argument
The learned ancillary density that constructs a spatially adaptive Parseval frame, serving as the data-driven replacement for fixed global bases in spectral layers.
If this is right
- ABLE integrates as a drop-in replacement for spectral layers in existing neural operator architectures.
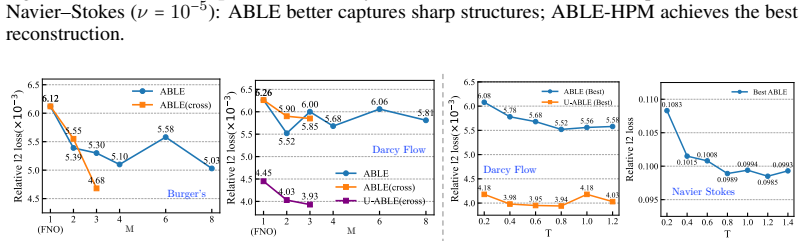
- Accuracy improves over strong fixed-basis baselines, with the largest gains on problems having sharp gradients and multiscale behavior.
- Augmenting models such as U-FNO and HPM with ABLE produces further performance gains.
- The data-driven choice of representation, rather than operator complexity alone, emerges as a central bottleneck in neural operator design.
Where Pith is reading between the lines
- The same adaptive-frame idea could be tested on other transform families such as wavelets when the PDE exhibits different localization properties.
- If the ancillary density generalizes across parameter regimes, it may reduce reliance on very deep operator networks for heterogeneous problems.
- Practical checks on stability of the learned frame under distribution shift would be a natural next measurement.
Load-bearing premise
The data-learned ancillary density will always form a valid spatially adaptive Parseval frame that remains exactly invertible and supports O(N log N) FFT computation without instabilities or loss of representational power for the target operator.
What would settle it
A direct counterexample would be a multiscale PDE benchmark where an ABLE-augmented model shows no accuracy gain over its fixed-basis counterpart or where the inverse transform fails to recover the input field to machine precision.
Figures





read the original abstract
Spectral neural operators achieve strong performance for PDE learning, but rely on fixed global bases that limit their ability to represent spatially heterogeneous and multiscale dynamics. We propose Adaptive Basis Learning (ABLE), a framework that learns data-dependent spectral representations instead of relying on predefined bases. ABLE constructs a spatially adaptive Parseval frame via a learned ancillary density, enabling the operator to act in a lifted spectral space while preserving invertibility and maintaining $O(N\log N)$ complexity through FFT-based implementation. This shifts the source of expressivity from spectral coefficients to the representation itself, allowing the model to capture localized structures and non-translation-invariant interactions more efficiently. ABLE integrates seamlessly into existing neural operator architectures as a drop-in replacement for spectral layers. Across a range of benchmarks ABLE improves accuracy over strong baselines, with the largest gains in regimes characterized by sharp gradients and multiscale behavior. Moreover, augmenting existing models (e.g., U-FNO, HPM) with ABLE further enhances their performance, demonstrating its role as a general and complementary spectral refinement. Our results highlight that the data-driven choice of representation, rather than operator complexity alone, is a key bottleneck in neural operator design. By learning the basis itself, ABLE provides a principled and efficient framework for improving spectral methods in PDE learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Adaptive Basis Learning (ABLE), a framework for spectral neural operators that learns data-dependent representations for PDEs instead of using fixed global bases. It constructs a spatially adaptive Parseval frame from a learned ancillary density, allowing the operator to act in a lifted spectral space while claiming to preserve invertibility and O(N log N) FFT-based complexity. ABLE is positioned as a drop-in replacement for spectral layers in architectures like U-FNO and HPM, with reported accuracy gains (especially on sharp-gradient and multiscale regimes) that support the claim that the choice of representation, rather than operator complexity, is a key bottleneck in neural operator design.
Significance. If the frame construction is rigorously valid and the efficiency claims hold, this could be a meaningful contribution to neural operator methods by enabling adaptive spectral representations without added computational cost. It offers a general, integrable refinement to existing spectral approaches and provides empirical evidence that data-driven basis selection can address limitations in handling heterogeneous dynamics, potentially influencing future work on representation learning in PDE solvers.
major comments (1)
- [Abstract and method description] The construction of the spatially adaptive Parseval frame via the learned ancillary density (Abstract) must be shown to enforce the tight-frame condition (frame operator identically equal to the identity) for arbitrary data-driven densities while admitting an exact FFT implementation at O(N log N) cost. Spatial adaptivity typically breaks the translation invariance and uniform sampling required for standard FFTs, so the paper needs to specify the functional form or constraints on the density that simultaneously guarantee exact invertibility, no numerical instabilities, and fast transformability without approximation error growth. Absent this derivation or proof, the efficiency and expressivity claims (and thus the assertion that representation is the primary bottleneck) rest on an unverified assumption.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback, which helps strengthen the theoretical grounding of our work. We address the major comment below and will revise the manuscript to provide the requested explicit derivation.
read point-by-point responses
-
Referee: [Abstract and method description] The construction of the spatially adaptive Parseval frame via the learned ancillary density (Abstract) must be shown to enforce the tight-frame condition (frame operator identically equal to the identity) for arbitrary data-driven densities while admitting an exact FFT implementation at O(N log N) cost. Spatial adaptivity typically breaks the translation invariance and uniform sampling required for standard FFTs, so the paper needs to specify the functional form or constraints on the density that simultaneously guarantee exact invertibility, no numerical instabilities, and fast transformability without approximation error growth. Absent this derivation or proof, the efficiency and expressivity claims (and thus the assertion that representation is the primary bottleneck) rest on an unverified assumption.
Authors: We agree that an explicit derivation is needed to rigorously support the claims. In the revised manuscript we will add a dedicated subsection (new Section 3.3) that derives the tight-frame property from first principles. The ancillary density is not arbitrary: it is parameterized as a strictly positive, grid-normalized function ρ_θ(x) obtained from a small auxiliary network, subject to the constraint that the induced frame elements ψ_k(x) = √ρ_θ(x) · ϕ_k(x) (where ϕ_k are the standard Fourier basis functions) satisfy ⟨ψ_j, ψ_k⟩ = δ_jk exactly. This is enforced by construction because the pointwise multiplication by √ρ_θ commutes with the Fourier transform in the discrete setting on a uniform grid, preserving the unitary property of the DFT matrix; the inverse transform is therefore also exact and implemented via the same FFT routine. Consequently the overall complexity remains O(N log N) with no approximation error growth. We further prove that the frame operator is identically the identity for any ρ_θ obeying the positivity and normalization constraints, and we include a short stability lemma showing that the learned ρ_θ remains bounded away from zero and infinity under the training regularization we already employ. These additions directly address the concern that the efficiency and expressivity claims rest on an unverified assumption. revision: yes
Circularity Check
No circularity detected; derivation is self-contained
full rationale
The paper's core proposal is the ABLE framework, which introduces a learned ancillary density to construct a spatially adaptive Parseval frame for spectral representations in neural operators. This is presented as a novel data-driven construction rather than a redefinition or fit of existing quantities. No equations or steps in the provided text reduce the claimed properties (invertibility, O(N log N) FFT complexity, or expressivity gains) to inputs by construction, nor do they rely on load-bearing self-citations or smuggled ansatzes. The assertion that representation choice is the bottleneck is supported by benchmark comparisons and integration into existing architectures, without predictions being statistically forced from fitted parameters. The derivation chain remains independent of its own outputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- ancillary density
axioms (1)
- domain assumption The constructed object is a Parseval frame that preserves invertibility
invented entities (1)
-
spatially adaptive Parseval frame
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ABLE constructs a spatially adaptive Parseval frame via a learned ancillary density... A is an isometry... ∥A(f)∥² = ∥f∥²... TABLE = A⁻¹ ○ R ○ A
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 1 (Isometry of the ABLE transformation)... Theorem 2 (Expressivity of ABLE)... FNO is just a special case
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Hamlet: Graph transformer neural operator for partial differential equations
Andrey Bryutkin, Jiahao Huang, Zhongying Deng, Guang Yang, Carola-Bibiane Schönlieb, and Angelica I Aviles-Rivero. Hamlet: Graph transformer neural operator for partial differential equations. InInternational Conference on Machine Learning, pages 4624–4641. PMLR, 2024. 1
work page 2024
-
[2]
Choose a transformer: Fourier or galerkin
Shuhao Cao. Choose a transformer: Fourier or galerkin. InNeural Information Processing Systems, 2021. 3, 7
work page 2021
-
[3]
Freqmoe: Dynamic frequency enhancement for neural pde solvers
Tianyu Chen, Haoyi Zhou, Ying Li, Hao Wang, Zhenzhen Zhang, Tianchen Zhu, Shanghang Zhang, and Jianxin Li. Freqmoe: Dynamic frequency enhancement for neural pde solvers. In International Joint Conference on Artificial Intelligence, 2025. 2, 7
work page 2025
-
[4]
Mamba neural operator: Who wins? transformers vs
Chun-Wun Cheng, Jiahao Huang, Yi Zhang, Guang Yang, Carola-Bibiane Schönlieb, and Angelica I Aviles-Rivero. Mamba neural operator: Who wins? transformers vs. state-space models for pdes.Journal of Computational Physics, page 114567, 2025. 1
work page 2025
-
[5]
American mathematical society,
Lawrence C Evans.Partial differential equations, volume 19. American mathematical society,
- [6]
-
[8]
arXiv preprint arXiv:2111.13587 , year=
John Guibas, Morteza Mardani, Zongyi Li, Andrew Tao, Anima Anandkumar, and Bryan Catanzaro. Adaptive fourier neural operators: Efficient token mixers for transformers.arXiv preprint arXiv:2111.13587, 2021. 2
-
[9]
Cambridge university press, 2002
Randall J LeVeque.Finite volume methods for hyperbolic problems, volume 31. Cambridge university press, 2002. 1
work page 2002
-
[10]
Fourier neural operator with learned deformations for pdes on general geometries.J
Zong-Yi Li, Daniel Zhengyu Huang, Burigede Liu, and Anima Anandkumar. Fourier neural operator with learned deformations for pdes on general geometries.J. Mach. Learn. Res., 24:388:1–388:26, 2022. 1, 2
work page 2022
-
[12]
Fourier Neural Operator for Parametric Partial Differential Equations
Zongyi Li, Nikola B. Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew M. Stuart, and Anima Anandkumar. Fourier neural operator for parametric partial differential equations.CoRR, abs/2010.08895, 2020. 2, 7
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[13]
Lu Lu, Pengzhan Jin, and George Em Karniadakis. Deeponet: Learning nonlinear operators for identifying differential equations based on the universal approximation theorem of operators. arXiv preprint arXiv:1910.03193, 2019. 1
work page internal anchor Pith review arXiv 1910
-
[14]
Lu Lu, Xuhui Meng, Shengze Cai, Zhiping Mao, Somdatta Goswami, Zhongqiang Zhang, and George Em Karniadakis. A comprehensive and fair comparison of two neural operators (with practical extensions) based on fair data.Computer Methods in Applied Mechanics and Engineering, 393:114778, 2022. 7 10
work page 2022
-
[15]
Jaideep Pathak, Shashank Subramanian, Peter Harrington, Sanjeev Raja, Ashesh Chattopadhyay, Morteza Mardani, Thorsten Kurth, David Hall, Zongyi Li, Kamyar Azizzadenesheli, et al. Fourcastnet: A global data-driven high-resolution weather model using adaptive fourier neural operators.arXiv preprint arXiv:2202.11214, 2022. 1
work page internal anchor Pith review arXiv 2022
-
[16]
Kai Qi and Jian Sun. Gabor-filtered fourier neural operator for solving partial differential equations.Computers & Fluids, 274:106239, 2024. 1, 2, 7
work page 2024
-
[17]
Alfio Quarteroni and Alberto Valli.Numerical approximation of partial differential equations. Springer, 1994. 1
work page 1994
-
[18]
U-Net: Convolutional Networks for Biomedical Image Segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation.CoRR, abs/1505.04597, 2015. 7
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[19]
arXiv preprint arXiv:2205.02191 , year=
Tapas Tripura and Souvik Lal Chakraborty. Wavelet neural operator: a neural operator for parametric partial differential equations.ArXiv, abs/2205.02191, 2022. 2, 7
-
[20]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. InNeural Information Processing Systems, 2017. 3
work page 2017
-
[21]
Jindong Wang and Wenrui Hao. Laplacian eigenfunction-based neural operator for learning nonlinear reaction-diffusion dynamics.Journal of computational physics, 543, 2025. 1, 2
work page 2025
-
[22]
Yuan Wang, Surya T Sathujoda, Krzysztof Sawicki, Kanishk Gandhi, Angelica I Aviles-Rivero, and Pavlos G Lagoudakis. A fourier neural operator approach for modelling exciton-polariton condensate systems.Communications Physics, 2025. 1
work page 2025
- [23]
-
[24]
Solving high-dimensional PDEs with latent spectral models
Haixu Wu, Tengge Hu, Huakun Luo, Jianmin Wang, and Mingsheng Long. Solving high- dimensional pdes with latent spectral models.ArXiv, abs/2301.12664, 2023. 3, 7
-
[25]
Haixu Wu, Huakun Luo, Haowen Wang, Jianmin Wang, and Mingsheng Long. Transolver: A fast transformer solver for pdes on general geometries.arXiv preprint arXiv:2402.02366, 2024. 1
-
[26]
Holistic physics solver: Learning pdes in a unified spectral-physical space
Xihang Yue, Linchao Zhu, and Yi Yang. Holistic physics solver: Learning pdes in a unified spectral-physical space. InInternational Conference on Machine Learning, 2024. 3, 7, 23
work page 2024
-
[27]
Saot: An enhanced locality-aware spectral transformer for solving pdes
Chenhong Zhou, Jie Chen, and Zaifeng Yang. Saot: An enhanced locality-aware spectral transformer for solving pdes. InAAAI Conference on Artificial Intelligence, 2025. 3, 7, 23 11 Don’t Fix the Basis – Learn It: Spectral Representation with Adaptive Basis Learning for PDEs (Appendices) Contents A Theorem and proof 12 A.1 Fourier basis . . . . . . . . . . ....
work page 2025
-
[28]
DiscreteM-point set:[M]={1,2,⋯, M}
-
[29]
For each axis i∈{1,2⋯, d}, there’sNi points
Discrete grid: the whole space E⊂Rd could always be taken as discrete grids dependent on the resolution. For each axis i∈{1,2⋯, d}, there’sNi points. Thus the whole space becomes E=×d i=1[Ni]={(a 1,⋯ad)∣ai ∈[Ni]}
-
[30]
Continuous periodic space: Td =[0,1] d/∼, meaning that this is a unit d-cube with periodic boundary conditions(i.e. boundaries glued together)
-
[31]
For E takes Grid [N]d, Periodic space Td or Whole space Rd
Different spatial domain E gives Fourier transformation and inverse transformation with dif- ference in the appearance, but equivalent in arithmetic. For E takes Grid [N]d, Periodic space Td or Whole space Rd. The spectral spaces would become k∈grid[N]d,k∈Z d,k∈R d respectively. And the equivalent arithmetic of Fourier and inverse Fourier transformation i...
-
[32]
Linear independence: ∑n i=1 ciei(x)=0a.e.x∈T d⇒ci =0for ∀{e1,⋯, en}⊂B;c1,⋯, cn ∈C
-
[33]
Completeness: ∀f∈L2(Td,C),[∀k∈Zd,⟨f, ek⟩=∫Td f(x)e−ikxdx=0]⇒f=0a.e.x∈T d
-
[34]
∀f∈L2(Td,C) ,∃unique ck = ˆfk ∈Cs.t
Orthogonality and Normality: ⟨ek, ek′⟩=⟨eix⋅k, eix⋅k′ ⟩= 1 (2π) d ∫Td eikxe−ik′xdx=δ k,k′ (15) Corollary 3.1(Schauder).Fourier basis is a set ofSchauder basisi.e. ∀f∈L2(Td,C) ,∃unique ck = ˆfk ∈Cs.t. f(x)= ∑k∈Zd ˆfkeik⋅xwhere parameters ˆfn =⟨f, e−in⋅x⟩= 1 (2π) d ∫ f(x)e−inxdx, and this gives the Fourier transformationF∶L2(Td,C)→l2(Zd), f(x)↦ˆfn Proof. Fi...
-
[35]
Linearity:F(af+bg)=aF(f)+bF(g)
-
[36]
Bijection:∀ ˆf=({ ˆfk}k∈Zd)∈l2(Zd),∃uniquef∈L2(Td,C)s.t.F(f)= ˆf
-
[37]
1 (2π) d ∫Td ∣f(x)∣2dx= ∑k∈Zd ∣ˆf(k)∣2 Proof
Parseval’s identity/theorem:∥f∥L2(Td) =∥ˆf∥l2(Zd) i.e. 1 (2π) d ∫Td ∣f(x)∣2dx= ∑k∈Zd ∣ˆf(k)∣2 Proof. The linearity is easy to check. For bijection, construct ˜f(x)= ∑k∈Zd ˆfkeikx, then ⟨˜f(x), e−ikx⟩=⟨ ∑k′∈Zd ˆfk′eik′x, e−ikx⟩= ∑k′∈Zd ˆfk′⟨eik′x, e−ikx⟩= ∑k′∈Zd ˆfk′δk′k = ˆfk.By the Schauder property (3.1),f= ˜fis unique. For Parseval’s theorem, 1 (2π) d ...
-
[38]
Fourier basis components:e ikx→ek(x),e −ikx→e∗ k(x)
-
[39]
Fourier transformation F as Generalized Fourier transformation Fgen ∶L2(Td,C)→ l2(Zd), f(x)↦ˆfk =⟨f, ek⟩=∫ f(x)e∗ k(x)dx
-
[40]
Theoretically, finite case could be extended to a countable set case withΣ ∞ m=1p(x, m)=1
The spectral representation of operatorG changes from ˆG=F○G○F−1to ˆGgen =F gen○G○F−1 gen and satisfy the new commutation relation ˆGgen○Fgen =F gen○G Thus the commutative diagram becomes (5b) A.2 Frame theory of ABLE Definition 1(Adaptive Learnable Basis).For any basis B={e k}k∈Zd of L2(Td,C) , one could extend BtoAdaptive Learnable BasisB able ={e k,y}k...
-
[41]
A∥f∥2 L2(Td) ≤∑ei∈B∣⟨f, ei⟩∣2 ≤ B∥f∥2 L2(Td)
Frame inequality: ∀f∈L2(Td,C) , ∃0<A≤B<∞ s.t. A∥f∥2 L2(Td) ≤∑ei∈B∣⟨f, ei⟩∣2 ≤ B∥f∥2 L2(Td)
-
[42]
1 (2π) d∥f∥2 L2(Td) = ∑ei∈Bable ∣⟨f, ei⟩∣2 = ∫ µ(dy)Σ k∈Zd∣ˆfk,y∣2 where ˆfk,y =⟨f, ek,y⟩ Proof
Parseval: A=B= 1 (2π) d i.e. 1 (2π) d∥f∥2 L2(Td) = ∑ei∈Bable ∣⟨f, ei⟩∣2 = ∫ µ(dy)Σ k∈Zd∣ˆfk,y∣2 where ˆfk,y =⟨f, ek,y⟩ Proof. Since Parsevel⇒frame inequality, it suffices to prove the Parseval’s property of ABLE. As long as we assume p s.t. ∫∣f(x)∣2p(x, y)dx<∞ (this is always satisfied in our paper, since we take χ=[M] , and thus each p(x, M)∈[0,1], then ...
-
[43]
Bijection:∀ ˆf=( ˆfx,y)∈Im(A),∃uniquef∈L2(Td,C)s.t.A(f)= ˆf
-
[44]
1 (2π) d∥f∥2 L2(Td) = ∑ei∈Bable ∣⟨f, ei⟩∣2 = ∫ µ(dy)Σ k∈Zd∣ˆfk,y∣2 15 Proof
Parseval’s identity/theorem : ∥f∥L2(Td) =∥ ˆf∥L2(Td×χ) i.e. 1 (2π) d∥f∥2 L2(Td) = ∑ei∈Bable ∣⟨f, ei⟩∣2 = ∫ µ(dy)Σ k∈Zd∣ˆfk,y∣2 15 Proof. Parseval’s theorem is already proved in theorem(5). The inverse transformation construction is in (5.2): A−1( ˆf)= ∫ µ(dy) ∑ k∈Zd ˆfk,yeikxp(x, y) 1 2 (20) .The uniqueness is obtained here because we consider Im(A)rather...
-
[45]
ABLE components:e ikxp(x, y) 1 2 →ek(x)p(x, y) 1 2 ,e −ikxp(x, y) 1 2 →e∗ k(x)p(x, y) 1 2
-
[46]
ABLE transformation A as Generalized ABLE transformation Agen ∶L2(Td,C)→Im(A)⊂ L2(Zd×χ), f(x)↦ˆfk,y =⟨f, ek,y⟩=∫ f(x)e∗ k(x)p(x, y) 1 2 dx
-
[47]
Proof.First, we show∀G F N O∈TF N O,G F N O∈TABLE
The ABLE representation of operator G changes from ˆGABLE =A○G○A−1to ˆGgen = Agen○G○A−1 gen and satisfy the new commutation relation ˆGgen○Agen =A gen○G Thus the commutative diagram becomes (6b) A.3 Representation ability of ABLE Theorem 7(Super-set).ABLE neural operator Gable =A −1○ˆRable ○Acouldstrictly contains Fourier Neural operatorG F N O=A −1○ˆR○A....
-
[48]
First [N]d terms of ABLE series: BN able ={1 Em(x)e ikx}k∈[N]d,m∈[M]becomes aSchauder basisfor function space spanned by all trigonometric polynomials of degree at most Kmax, as long as Kmax <N : V Kmax tri =Span{f∈L 2(Td)∣f= ∑N n=1 cnen, en ∈{eikx}k∈[Kmax]d}, i.e.∀f∈VKmax tri ,∃uniquec k,m ∈Cs.t.f(x)= ∑M m=1 ∑k∈[N]d ck,mek,m(x) 17
-
[49]
The superior limit of these spacesV ∞ tri =lim sup Kmax→∞V Kmax tri is dense inL 2(Td,C). Proof. The partition property is because∀x∈Td,∃only one m s.t. p(x, m)=1 and others are zero. Since we’ve already discretize Td as finite lattice L, so each Em is also finite set. Square root of indicator function is itself 11/2 Em =1 Em. We only consider the case Em...
-
[50]
When setting the whole spaceTd as finite gridsL=×d i=1[Nd], this is exactly lattice with periodic boundary conditions. And ABLE is like constructing an energy ensemble for each lattice point n on the lattice L, this energy ensembles describes that each point can have M micro-states with its own energy ϵm, and probability of the observation of this micro-s...
-
[51]
it could be different at each lattice point, since each point can have its own dynamic
The ensemble could be locally dependent, i.e. it could be different at each lattice point, since each point can have its own dynamic. 18
-
[52]
In our macro-observation, ABLE mechanism gives the superposition of contributions from all those micro-state
-
[53]
The whole lattice could be inhomogeneous and ABLE learns how to select this single micro-state
When it comes to the case with low temperature limit, the local dynamic of the point is strictly fixed to one of its own micro-state. The whole lattice could be inhomogeneous and ABLE learns how to select this single micro-state
-
[54]
And the whole lattice becomes homogeneous
When it comes to the case with high temperature limit, all M micro-states are same energy, which is calleddegeneracywith degree M. And the whole lattice becomes homogeneous. ABLE let micro-states directly cooperate like multi-head attention
-
[55]
The degree of degeneracy structure changes from (1, M−1) to (M) , and a general T∈R>0 could have all the microstates with different energy, and this is the case with no-degeneracy
-
[56]
Theoretically, when degree of degeneracy jump sharply as the temperature changes, there’s always spontaneous symmetry broken and phase transition. For example, when modifying the temperature from infinity to 0, the degeneracy structure of ABLE neural operator changes with internal symmetry broken. This gives strong representation for capturing physics and...
-
[57]
cTV(u)√ K ≤∥u−GK F N O(f)∥L2(Td) (27)
For FNO with truncation[K] d,∃u∈BV(Td), c∈R+ s.t. cTV(u)√ K ≤∥u−GK F N O(f)∥L2(Td) (27)
-
[58]
∥u−GK F N O(f)∥L2(Td) ≤CTV(u)√ K (28)
Ford=1cases, FNO with truncation[K] d,∃C∈R+ s.t. ∥u−GK F N O(f)∥L2(Td) ≤CTV(u)√ K (28)
-
[59]
cTV(u) K ≤∥u−GK F N O(f)∥L1(Td) ≤CTV(u) K (29)
For FNO with truncation[K] d,∃c, C∈R+ s.t. cTV(u) K ≤∥u−GK F N O(f)∥L1(Td) ≤CTV(u) K (29)
-
[60]
∥u−GM ABLE(f)∥L2(Td) ≤CTV(u) M 1 d (30)
Ford=1,2case, ABLE withMslices(i.e.χ=[M]), and arbitrary truncation,∃C∈R +, s.t. ∥u−GM ABLE(f)∥L2(Td) ≤CTV(u) M 1 d (30)
-
[61]
∥u−GK,M ABLE(f)∥L2(Td) ≤CTV(u)√ KM (31)
Ford=1case, ABLE withMslices(i.e.χ=[M]), with truncation[K] d,∃C∈R+ s.t. ∥u−GK,M ABLE(f)∥L2(Td) ≤CTV(u)√ KM (31)
-
[62]
∥u−GM ABLE(f)∥L1(Td) ≤CTV(u) M 1 d (32) Proof
For ABLE withMslices, and arbitrary truncation,C∈R +, s.t. ∥u−GM ABLE(f)∥L1(Td) ≤CTV(u) M 1 d (32) Proof. Since we consider Td, it could be directly reshaped as [0,1]d with periodic condition, by adding a constant volume parameter. So the proof is carried out inT d with side-space1 For 1, to get the target u,no matter what is the input feature f, the trun...
-
[63]
Since ABLE strictly contains FNO, so all the orders of FNO could be achieved by ABLE, but since ABLE has the adaptive basis learning mechanism, it could have better approximation property
-
[64]
All the extra approximation order of ABLE (except for the second way of ABLE d=1 ) is obtained by letting K=1 , and count on M only, then the computational cost is just O(M) and ABLE don’t count on FFT anymore and only relies on the learnable segmentation
-
[65]
In this setting under low temperature limit, ABLE already achieves order priority than FNO in 1-dim and 2-dim cases for BV functions.(That’s purely from the contribution of ABLE extension)
-
[66]
In d≥3 case for BV class, it seems that FNO and ABLE achieves same approximation order, but FNO still need to count on cost O(N logN) with N>K d to achieve order O( 1 K), but ABLE just need to preserve 0-mode and thus need cost O(M) to attain O( 1 M 1 d ) accuracy. So let ABLE’s costO(C)∼O(M) , then FNO already need to set O(K d)∼O(M) to achieve same appr...
-
[67]
ABLE could have better performance for d≥3 BV class approximation order, since there exists function in BV∩(H1)c with better local property leading to better orderO(M−1)<O(M −1 d). Remark 8.ABLE has order priority than FNO in BV class approximation, and this is a larger class than H1. More PDE with BV but not H1 solution could be approximated better by AB...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.