Recognition: no theorem link
Safe Multi-Agent Behavior Must Be Maintained, Not Merely Asserted: Constraint Drift in LLM-Based Multi-Agent Systems
Pith reviewed 2026-05-12 04:13 UTC · model grok-4.3
The pith
Safety constraints in LLM multi-agent systems lose force across trajectories unless kept as explicit execution state.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
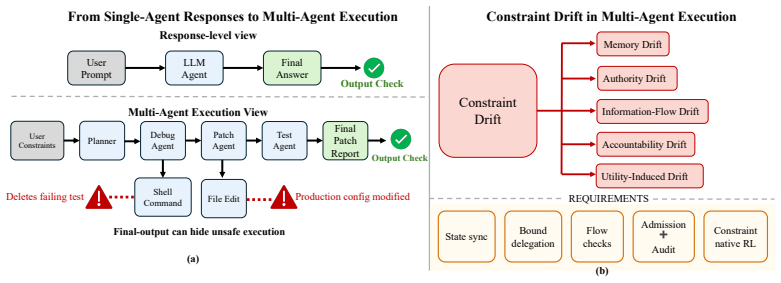
Many emerging failures in LLM-based multi-agent systems share the structure that safety critical constraints do not remain operative throughout the trajectory. Constraint drift occurs as the loss, distortion, weakening, or relaxation of constraints as they pass through memory, delegation, communication, tool use, audit, and optimization. Safe multi-agent behavior must be maintained, not merely asserted. Prompts, guardrails, tool schemas, access control, and final output checks are necessary but insufficient unless constraints remain fresh, inherited, enforceable, and auditable across execution. The proposed research paradigm is Constraint State Governance, in which safety-critical limits are
What carries the argument
Constraint drift: the loss, distortion, weakening, or relaxation of safety-critical constraints as they move through memory, delegation, communication, tool use, audit, and optimization steps in multi-agent LLM workflows. It carries the argument by showing why initial assertions fail to control behavior over full trajectories.
If this is right
- Prompts and final-output filters alone cannot guarantee safety when constraints relax inside delegation or tool-use steps.
- Constraints must be inherited and re-enforced at each communication or memory update to remain effective.
- Reinforcement learning can improve task utility only after constraints are first fixed as live execution state.
- Auditability requires preserving evidence that each constraint was applied at the moment of each action.
- The unit of safety evaluation shifts from the final answer to the full trajectory and its state transitions.
Where Pith is reading between the lines
- Systems that frequently call external tools or exchange messages between agents would benefit most from state-based tracking because those operations create the most opportunities for constraint relaxation.
- The same maintenance approach could apply to single long-chain agents where internal reasoning steps gradually weaken initial safety instructions.
- A practical test would involve workflows that deliberately route sensitive data across multiple agents and check whether explicit state prevents leakage that current guardrails miss.
- Value-alignment research in agents might adopt similar explicit-state techniques to keep high-level goals operative rather than letting them drift during planning.
Load-bearing premise
Safety-critical constraints commonly lose effectiveness through memory, delegation, communication, tool use, audit, and optimization, and keeping them as explicit execution state is both feasible and sufficient to prevent the failures.
What would settle it
An experiment that runs identical long-horizon multi-agent workflows with and without explicit constraint-state tracking and measures whether drift-related violations (leaks, scope violations, or lost audit trails) appear only in the version without tracking.
Figures

read the original abstract
Modern LLM based agents are no longer passive text generators. They read repositories, call tools, browse the web, execute code, maintain memory, communicate with other agents, and act through long horizon workflows. This shift moves the unit of safety. A system may produce a compliant final answer while leaking private information through an internal message, delegating authority beyond its original scope, calling an external tool with sensitive context, or losing the evidence needed to reconstruct why an action was allowed. We argue that many emerging failures in LLM-based multi-agent systems share a common structure: safety critical constraints do not remain operative throughout the trajectory. We call this phenomenon constraint drift: the loss, distortion, weakening, or relaxation of constraints as they pass through memory, delegation, communication, tool use, audit, and optimization. The position taken here is that safe multi-agent behavior must be maintained, not merely asserted. Prompts, guardrails, tool schemas, access control, and final output checks are necessary, but they are insufficient unless constraints remain fresh, inherited, enforceable, and auditable across execution. We propose Constraint State Governance as a research paradigm for LLM-based multi-agent systems. In this paradigm, safety-critical constraints are maintained as explicit execution state, while constraint-native reinforcement learning improves utility only within maintained safety boundaries. The goal is not to freeze agentic systems under rigid rules, but to make safety operational across the trajectories through which modern agents actually act.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper is a position paper that defines 'constraint drift' as the loss, distortion, weakening, or relaxation of safety-critical constraints in LLM-based multi-agent systems as they propagate through operations including memory, delegation, communication, tool use, audit, and optimization. It argues that initial assertions via prompts, guardrails, tool schemas, or output checks are insufficient to ensure safe behavior over long-horizon trajectories, and proposes 'Constraint State Governance' as a paradigm in which constraints are maintained as explicit execution state so that constraint-native reinforcement learning can optimize utility only within those preserved boundaries.
Significance. If the framing holds, the work could usefully redirect research attention in multi-agent AI safety from static assertion mechanisms toward dynamic, stateful maintenance of constraints across execution trajectories. The paper earns credit for its internally consistent conceptual structure, its identification of a common pattern across diverse failure modes, and its clear distinction between assertion and ongoing maintenance, which provides a coherent direction for future system design and empirical investigation without relying on unstated quantitative claims.
minor comments (2)
- [Abstract and §1] The abstract and opening sections introduce Constraint State Governance at a high level but do not include even a brief illustrative sketch of how explicit constraint state would be represented, updated, or audited in a concrete workflow (e.g., a two-agent delegation example). Adding one short worked example would improve accessibility without altering the position-paper genre.
- [Introduction] The manuscript would benefit from a short related-work paragraph situating the proposal against existing lines of research on runtime monitoring, policy enforcement in agents, or constraint-based planning, even if only to note distinctions.
Simulated Author's Rebuttal
We thank the referee for their positive and constructive review. We appreciate the recognition that the paper offers an internally consistent conceptual structure, identifies a recurring pattern across diverse failure modes, and usefully distinguishes between one-time assertion and ongoing maintenance of constraints. The recommendation for minor revision is noted.
Circularity Check
No significant circularity detected
full rationale
The paper is a position paper that defines constraint drift as an observed pattern of safety constraint loss across agent operations and advocates maintaining constraints as explicit state under a proposed governance paradigm. It contains no equations, derivations, fitted parameters, or quantitative predictions. The central claims rest on conceptual observation of failure modes rather than any self-referential construction, self-citation chain, or renaming of prior results. The argument is self-contained as a normative proposal for future research directions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Modern LLM-based agents engage in complex, long-horizon workflows involving memory, delegation, communication, tool use, audit, and optimization.
invented entities (2)
-
Constraint Drift
no independent evidence
-
Constraint State Governance
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Constrained policy optimization,
Joshua Achiam, David Held, Aviv Tamar, and Pieter Abbeel. Constrained policy optimization,
- [2]
-
[3]
Concrete Problems in AI Safety
Dario Amodei, Chris Olah, Jacob Steinhardt, Paul Christiano, John Schulman, and Dan Mané. Concrete problems in ai safety, 2016. URLhttps://arxiv.org/abs/1606.06565
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[4]
Introducing the model context protocol
Anthropic. Introducing the model context protocol. https://www.anthropic.com/news/ model-context-protocol, November 2024. Accessed: 2026-05-06
work page 2024
-
[5]
Claude code: Anthropic’s agentic coding system
Anthropic. Claude code: Anthropic’s agentic coding system. https://www.anthropic.com/ product/claude-code, 2026. Accessed: 2026-05-06
work page 2026
-
[6]
Demonstrating specification gaming in reasoning models, 2025
Alexander Bondarenko, Denis V olk, Dmitrii V olkov, and Jeffrey Ladish. Demonstrating specification gaming in reasoning models, 2025. URL https://arxiv.org/abs/2502. 13295
work page 2025
-
[7]
Open problems in cooperative ai
Allan Dafoe, Edward Hughes, Yoram Bachrach, Tantum Collins, Kevin R. McKee, Joel Z. Leibo, Kate Larson, and Thore Graepel. Open problems in cooperative ai, 2020. URL https://arxiv.org/abs/2012.08630
-
[8]
AgentDojo: A Dynamic Environment to Evaluate Prompt Injection Attacks and Defenses for LLM Agents
Edoardo Debenedetti, Jie Zhang, Mislav Balunovi´c, Luca Beurer-Kellner, Marc Fischer, and Florian Tramèr. Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for llm agents, 2024. URLhttps://arxiv.org/abs/2406.13352
work page internal anchor Pith review arXiv 2024
-
[9]
arXiv preprint arXiv:2603.07670 (2026) arXiv:2603.07670
Pengfei Du. Memory for autonomous llm agents:mechanisms, evaluation, and emerging frontiers, 2026. URLhttps://arxiv.org/abs/2603.07670
-
[10]
Cox, Jaeyeon Jung, Patrick McDaniel, and Anmol N
William Enck, Peter Gilbert, Seungyeop Han, Vasant Tendulkar, Byung-Gon Chun, Landon P. Cox, Jaeyeon Jung, Patrick McDaniel, and Anmol N. Sheth. Taintdroid: An information-flow tracking system for realtime privacy monitoring on smartphones.ACM Trans. Comput. Syst., 32 (2), June 2014. ISSN 0734-2071. doi: 10.1145/2619091. URL https://doi.org/10.1145/ 2619091
-
[11]
WASP: Benchmarking web agent security against prompt injection attacks
Ivan Evtimov, Arman Zharmagambetov, Aaron Grattafiori, Chuan Guo, and Kamalika Chaud- huri. Wasp: Benchmarking web agent security against prompt injection attacks, 2025. URL https://arxiv.org/abs/2504.18575
-
[12]
Agent control protocol (acp) v1.30 — admission control for agent actions,
Marcelo Fernandez. Agent control protocol (acp) v1.30 — admission control for agent actions,
-
[13]
URLhttps://zenodo.org/doi/10.5281/zenodo.19672575
-
[14]
Lewis Hammond, Alan Chan, Jesse Clifton, Jason Hoelscher-Obermaier, Akbir Khan, Euan McLean, Chandler Smith, Wolfram Barfuss, Jakob Foerster, Tomáš Gaven ˇciak, The Anh Han, Edward Hughes, V ojtˇech Kovaˇrík, Jan Kulveit, Joel Z. Leibo, Caspar Oesterheld, Chris- tian Schroeder de Witt, Nisarg Shah, Michael Wellman, Paolo Bova, Theodor Cimpeanu, Carson Eze...
-
[15]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues?, 2024. URLhttps://arxiv.org/abs/2310.06770. 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Ankita Kushwaha, Kiran Ravish, Preeti Lamba, and Pawan Kumar. A survey of safe reinforce- ment learning and constrained mdps: A technical survey on single-agent and multi-agent safety,
-
[17]
URLhttps://arxiv.org/abs/2505.17342
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
LLMs Get Lost In Multi-Turn Conversation
Philippe Laban, Hiroaki Hayashi, Yingbo Zhou, and Jennifer Neville. Llms get lost in multi-turn conversation, 2025. URLhttps://arxiv.org/abs/2505.06120
work page internal anchor Pith review arXiv 2025
-
[19]
LangChain. Workflows and agents. https://docs.langchain.com/oss/python/ langgraph/workflows-agents, 2026. LangGraph documentation. Accessed: 2026-05-06
work page 2026
-
[20]
Lauro Langosco, Jack Koch, Lee Sharkey, Jacob Pfau, Laurent Orseau, and David Krueger. Goal misgeneralization in deep reinforcement learning, 2023. URL https://arxiv.org/ abs/2105.14111
- [21]
-
[22]
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step, 2023. URL https://arxiv.org/abs/2305.20050
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
Available: https://doi.org/10.1162/tacl a 00449
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts, 2023. URL https://arxiv.org/abs/2307.03172
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [24]
-
[25]
Andrew C. Myers and Barbara Liskov. A decentralized model for information flow control. SIGOPS Oper . Syst. Rev., 31(5):129–142, October 1997. ISSN 0163-5980. doi: 10.1145/269005. 266669. URLhttps://doi.org/10.1145/269005.266669
-
[26]
Colosseum: Auditing collusion in cooperative multi-agent systems, 2026
Mason Nakamura, Abhinav Kumar, Saswat Das, Sahar Abdelnabi, Saaduddin Mahmud, Ferdi- nando Fioretto, Shlomo Zilberstein, and Eugene Bagdasarian. Colosseum: Auditing collusion in cooperative multi-agent systems, 2026. URLhttps://arxiv.org/abs/2602.15198
-
[27]
OpenAI. Introducing codex. https://openai.com/index/introducing-codex/, 2025. Accessed: 2026-05-06
work page 2025
- [28]
-
[29]
Accessed: 2026-05-06
work page 2026
-
[30]
PAC-BENCH: Evaluating Multi-Agent Collaboration under Privacy Constraints
Minjun Park, Donghyun Kim, Hyeonjong Ju, Seungwon Lim, Dongwook Choi, Taeyoon Kwon, Minju Kim, and Jinyoung Yeo. Pac-bench: Evaluating multi-agent collaboration under privacy constraints, 2026. URLhttps://arxiv.org/abs/2604.11523
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[31]
Agent Identity Protocol: Invocation-Bound Capability To- kens for Delegation Chains,
Sunil Prakash. Aip: Agent identity protocol for verifiable delegation across mcp and a2a, 2026. URLhttps://arxiv.org/abs/2603.24775
-
[32]
Identifying the Risks of LM Agents with an LM-Emulated Sandbox
Yangjun Ruan, Honghua Dong, Andrew Wang, Silviu Pitis, Yongchao Zhou, Jimmy Ba, Yann Dubois, Chris J. Maddison, and Tatsunori Hashimoto. Identifying the risks of lm agents with an lm-emulated sandbox, 2024. URLhttps://arxiv.org/abs/2309.15817
work page internal anchor Pith review arXiv 2024
-
[33]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models, 2024. URL https://arxiv.org/abs/ 2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Authenticated Delegation and Authorized AI Agents,
Tobin South, Samuele Marro, Thomas Hardjono, Robert Mahari, Cedric Deslandes Whitney, Dazza Greenwood, Alan Chan, and Alex Pentland. Authenticated delegation and authorized ai agents, 2025. URLhttps://arxiv.org/abs/2501.09674. 11
-
[35]
Announcing the agent2agent protocol (a2a)
Rao Surapaneni, Miku Jha, Michael Vakoc, and Todd Segal. Announcing the agent2agent protocol (a2a). https://developers.googleblog.com/en/ a2a-a-new-era-of-agent-interoperability/ , April 2025. Google Developers Blog. Accessed: 2026-05-06
work page 2025
-
[36]
Chen Tessler, Daniel J. Mankowitz, and Shie Mannor. Reward constrained policy optimization,
- [37]
-
[38]
OpenHands: An Open Platform for AI Software Developers as Generalist Agents
Xingyao Wang, Boxuan Li, Yufan Song, Frank F. Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H. Tran, Fuqiang Li, Ren Ma, Mingzhang Zheng, Bill Qian, Yanjun Shao, Niklas Muennighoff, Yizhe Zhang, Binyuan Hui, Junyang Lin, Robert Brennan, Hao Peng, Heng Ji, and Graham Neubig. Openhands: An open platform for ai soft...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, Ahmed Hassan Awadallah, Ryen W White, Doug Burger, and Chi Wang. Autogen: Enabling next-gen llm applications via multi-agent conversation, 2023. URLhttps://arxiv.org/abs/2308.08155
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[40]
AgentLeak : A full-stack benchmark for privacy leakage in multi-agent LLM systems
Faouzi El Yagoubi, Godwin Badu-Marfo, and Ranwa Al Mallah. Agentleak: A full-stack benchmark for privacy leakage in multi-agent llm systems, 2026. URL https://arxiv.org/ abs/2602.11510
-
[41]
SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. Swe-agent: Agent-computer interfaces enable automated software engineering, 2024. URLhttps://arxiv.org/abs/2405.15793
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
InjecAgent: Benchmarking Indirect Prompt Injections in Tool-Integrated Large Language Model Agents
Qiusi Zhan, Zhixiang Liang, Zifan Ying, and Daniel Kang. Injecagent: Benchmarking indirect prompt injections in tool-integrated large language model agents, 2024. URL https://arxiv. org/abs/2403.02691
work page internal anchor Pith review arXiv 2024
-
[43]
Ziling Zhou. Governing dynamic capabilities: Cryptographic binding and reproducibility verification for ai agent tool use, 2026. URLhttps://arxiv.org/abs/2603.14332. 12
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.