Recognition: 2 theorem links
· Lean TheoremDeepRefine: Agent-Compiled Knowledge Refinement via Reinforcement Learning
Pith reviewed 2026-05-12 04:13 UTC · model grok-4.3
The pith
DeepRefine refines agent-compiled knowledge bases by diagnosing defects from multi-turn interactions and training refinements end-to-end with reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DeepRefine is a general LLM-based reasoning model for agent-compiled knowledge refinement that improves the quality of any pre-constructed knowledge bases with user queries to make it more suitable for the downstream tasks. DeepRefine performs multi-turn interactions with the knowledge base and conducts abductive diagnosis over interaction history, localizes likely defects, and executes targeted refinement actions for incremental knowledge base updates. To optimize refinement policies of DeepRefine without gold references, we introduce a Gain-Beyond-Draft (GBD) reward and train the reasoning process end-to-end via reinforcement learning.
What carries the argument
Abductive diagnosis over multi-turn interaction history to localize defects, paired with targeted refinement actions optimized end-to-end by reinforcement learning under the Gain-Beyond-Draft reward.
If this is right
- Refined bases produce higher retrieval fidelity and stronger results on knowledge-intensive downstream tasks.
- The method applies to any pre-existing knowledge base and requires no gold-standard answers for training.
- Incremental updates prevent defects from compounding during repeated agent operation.
- Consistent gains appear over strong baseline refinement methods in reported experiments.
Where Pith is reading between the lines
- Agents could maintain and improve their external knowledge autonomously across extended operation periods.
- The same diagnosis-plus-update loop might extend to other persistent memory structures used by LLM agents.
- Combining the approach with occasional human oversight could further increase refinement accuracy.
- Self-adapting knowledge systems become feasible that evolve in response to new query patterns without external intervention.
Load-bearing premise
An LLM can reliably diagnose defects from interaction histories and the Gain-Beyond-Draft reward supplies an adequate training signal for useful refinements without gold references.
What would settle it
A test in which DeepRefine is applied to a knowledge base and downstream task performance shows no gain or a clear drop, or in which the model's diagnosed defects fail to match verifiable issues in the base.
Figures







read the original abstract
Agent-compiled knowledge bases provide persistent external knowledge for large language model (LLM) agents in open-ended, knowledge-intensive downstream tasks. Yet their quality is systematically limited by \emph{incompleteness}, \emph{incorrectness}, and \emph{redundancy}, manifested as missing evidence or cross-document links, low-confidence or imprecise claims, and ambiguous or coreference resolution issues. Such defects compound under iterative use, degrading retrieval fidelity and downstream task performance. We present \textbf{DeepRefine}, a general LLM-based reasoning model for \emph{agent-compiled knowledge refinement} that improves the quality of any pre-constructed knowledge bases with user queries to make it more suitable for the downstream tasks. DeepRefine performs multi-turn interactions with the knowledge base and conducts abductive diagnosis over interaction history, localizes likely defects, and executes targeted refinement actions for incremental knowledge base updates. To optimize refinement policies of DeepRefine without gold references, we introduce a Gain-Beyond-Draft (GBD) reward and train the reasoning process end-to-end via reinforcement learning. Extensive experiments demonstrate consistent downstream gains over strong baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DeepRefine, an LLM-based reasoning model for refining agent-compiled knowledge bases. It performs multi-turn interactions with the KB, conducts abductive diagnosis over history to localize defects (incompleteness, incorrectness, redundancy), and executes targeted refinement actions for incremental updates. To train without gold references, it defines a Gain-Beyond-Draft (GBD) reward and optimizes the policy end-to-end with reinforcement learning, claiming consistent downstream task gains over strong baselines.
Significance. If the central claim holds, the work could meaningfully advance agentic LLM systems by providing an automated, reference-free method to improve persistent external KBs that suffer from systematic defects. The GBD reward plus RL formulation is a reasonable attempt to sidestep the lack of gold-standard refinements, and the multi-turn abductive diagnosis loop is a plausible architecture for incremental KB maintenance. No machine-checked proofs or reproducible artifacts are described.
major comments (3)
- [Abstract, §4] Abstract and §4 (Experiments): the claim of 'consistent downstream gains over strong baselines' is asserted without any quantitative metrics, specific baseline descriptions, ablation studies, or error analysis. This directly undermines verification of whether the multi-turn diagnosis + GBD-RL loop produces the claimed improvements.
- [§3.2] §3.2 (GBD reward definition): the training objective relies on GBD as a proxy for useful refinement, yet no validation is provided that GBD correlates with actual reductions in KB defects (incorrectness, incompleteness, or redundancy) rather than superficial or gameable signals. Without such correlation or gold-reference comparisons, the policy may maximize reward while leaving core defects intact.
- [§3.1] §3.1 (abductive diagnosis): the assumption that the LLM reliably localizes defects from interaction history is load-bearing for the entire refinement pipeline, but no failure-mode analysis, diagnostic accuracy metrics, or comparison against simpler baselines is reported.
minor comments (2)
- [§3.2] Notation for the GBD reward scaling factors is introduced but not clearly distinguished from other hyperparameters; a dedicated table or equation block would improve clarity.
- The manuscript would benefit from an explicit limitations section discussing when the multi-turn interaction budget or LLM diagnosis reliability may degrade.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and describe the revisions we will make to strengthen the presentation of results and validation of key components.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (Experiments): the claim of 'consistent downstream gains over strong baselines' is asserted without any quantitative metrics, specific baseline descriptions, ablation studies, or error analysis. This directly undermines verification of whether the multi-turn diagnosis + GBD-RL loop produces the claimed improvements.
Authors: We agree that the experimental claims would be more verifiable with explicit quantitative support. In the revised manuscript, we will expand the abstract and §4 to report specific downstream performance metrics, detailed descriptions of all baselines, ablation studies isolating the multi-turn diagnosis and GBD-RL components, and an error analysis highlighting where refinements succeed or fall short. revision: yes
-
Referee: [§3.2] §3.2 (GBD reward definition): the training objective relies on GBD as a proxy for useful refinement, yet no validation is provided that GBD correlates with actual reductions in KB defects (incorrectness, incompleteness, or redundancy) rather than superficial or gameable signals. Without such correlation or gold-reference comparisons, the policy may maximize reward while leaving core defects intact.
Authors: We acknowledge that direct validation of the GBD reward against defect reduction is necessary. We will add analysis in the revision, including controlled experiments with synthetically injected defects to measure correlation between GBD scores and reductions in incorrectness, incompleteness, and redundancy, along with any available gold-reference comparisons on a held-out set. revision: yes
-
Referee: [§3.1] §3.1 (abductive diagnosis): the assumption that the LLM reliably localizes defects from interaction history is load-bearing for the entire refinement pipeline, but no failure-mode analysis, diagnostic accuracy metrics, or comparison against simpler baselines is reported.
Authors: We recognize the importance of substantiating the abductive diagnosis step. In the revised version, we will include a dedicated analysis section reporting failure modes observed during development, diagnostic accuracy metrics on a manually annotated subset of cases, and comparisons of the full pipeline against simpler baseline diagnosis strategies such as single-turn prompting. revision: yes
Circularity Check
No circularity: GBD reward and RL training are independent of reported downstream gains
full rationale
The paper defines DeepRefine as an LLM-based agent that performs multi-turn KB interactions, abductive diagnosis, defect localization, and targeted refinement actions. It introduces the GBD reward explicitly to enable RL optimization in the absence of gold references, then reports separate experimental measurements of downstream task improvements over baselines. No equations or claims reduce the final performance numbers to quantities fitted from the same data used to define GBD or the policy; the reward is an external training signal whose alignment with true KB quality is an empirical question, not a definitional identity. No self-citations, uniqueness theorems, or ansatzes from prior author work are invoked as load-bearing premises. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- GBD reward scaling factors
axioms (1)
- domain assumption LLMs can perform effective abductive diagnosis from multi-turn interaction histories to localize knowledge-base defects
invented entities (1)
-
DeepRefine reasoning model
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearwe introduce a Gain-Beyond-Draft (GBD) reward and train the reasoning process end-to-end via reinforcement learning
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclearAnswerability Judgement Loop, Error Abduction, and Refinement Actions Generation
Reference graph
Works this paper leans on
-
[1]
Neuro- symbolic entity alignment via variational inference.arXiv preprint arXiv:2410.04153,
Shengyuan Chen, Zheng Yuan, Qinggang Zhang, Wen Hua, Jiannong Cao, and Xiao Huang. Neuro- symbolic entity alignment via variational inference.arXiv preprint arXiv:2410.04153,
-
[2]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building production-ready ai agents with scalable long-term memory.arXiv preprint arXiv:2504.19413,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Prafulla Kumar Choubey, Xin Su, Man Luo, Xiangyu Peng, Caiming Xiong, Tiep Le, Shachar Rosenman, Vasudev Lal, Phil Mui, Ricky Ho, et al. Distill-synthkg: Distilling knowledge graph synthesis workflow for improved coverage and efficiency.arXiv preprint arXiv:2410.16597,
-
[4]
ISSN 1570-0844. doi: 10.3233/SW-160218. URLhttps://doi.org/10.3233/SW-160218. Na Dong, Natthawut Kertkeidkachorn, Xin Liu, and Kiyoaki Shirai. Refining noisy knowledge graph with large language models. InProceedings of the Workshop on Generative AI and Knowledge Graphs (GenAIK), pages 78–86,
-
[5]
From Local to Global: A Graph RAG Approach to Query-Focused Summarization
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitansky, Robert Osazuwa Ness, and Jonathan Larson. From local to global: A graph rag approach to query-focused summarization.arXiv preprint arXiv:2404.16130,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Retrieval-Augmented Generation for Large Language Models: A Survey
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yixin Dai, Jiawei Sun, Haofen Wang, Haofen Wang, et al. Retrieval-augmented generation for large language models: A survey.arXiv preprint arXiv:2312.10997, 2(1):32,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
LightRAG: Simple and Fast Retrieval-Augmented Generation
Zirui Guo, Lianghao Xia, Yanhua Yu, Tian Ao, and Chao Huang. Lightrag: Simple and fast retrieval-augmented generation.arXiv preprint arXiv:2410.05779, 2(3),
work page internal anchor Pith review arXiv
-
[8]
From rag to memory: Non-parametric continual learning for large language models, 2025
Bernal Jiménez Gutiérrez, Yiheng Shu, Weijian Qi, Sizhe Zhou, and Yu Su. From rag to memory: Non-parametric continual learning for large language models.arXiv preprint arXiv:2502.14802,
-
[9]
Open-Reasoner-Zero: An Open Source Approach to Scaling Up Reinforcement Learning on the Base Model
10 Jingcheng Hu, Yinmin Zhang, Qi Han, Daxin Jiang, Xiangyu Zhang, and Heung-Yeung Shum. Open-reasoner-zero: An open source approach to scaling up reinforcement learning on the base model.arXiv preprint arXiv:2503.24290,
work page internal anchor Pith review arXiv
-
[10]
Retrieval-augmented generation with hierarchical knowledge.arXiv preprint arXiv:2503.10150,
Haoyu Huang, Yongfeng Huang, Junjie Yang, Zhenyu Pan, Yongqiang Chen, Kaili Ma, Hongzhi Chen, and James Cheng. Retrieval-augmented generation with hierarchical knowledge.arXiv preprint arXiv:2503.10150,
-
[11]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card.arXiv preprint arXiv:2412.16720,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
s3: You don’t need that much data to train a search agent via rl
Pengcheng Jiang, Xueqiang Xu, Jiacheng Lin, Jinfeng Xiao, Zifeng Wang, Jimeng Sun, and Jiawei Han. s3: You don’t need that much data to train a search agent via rl. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 21610–21628,
work page 2025
-
[13]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Zamani, and Jiawei Han. Search-r1: Training llms to reason and leverage search engines with reinforcement learning.arXiv preprint arXiv:2503.09516,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Understanding R1-Zero-Like Training: A Critical Perspective
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Understanding r1-zero-like training: A critical perspective.arXiv preprint arXiv:2503.20783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Haoran Luo, Guanting Chen, Qika Lin, Yikai Guo, Fangzhi Xu, Zemin Kuang, Meina Song, Xiaobao Wu, Yifan Zhu, Luu Anh Tuan, et al. Graph-r1: Towards agentic graphrag framework via end-to- end reinforcement learning.arXiv preprint arXiv:2507.21892,
-
[17]
A replication study of dense passage retriever.arXiv preprint arXiv:2104.05740,
Xueguang Ma, Kai Sun, Ronak Pradeep, and Jimmy Lin. A replication study of dense passage retriever.arXiv preprint arXiv:2104.05740,
-
[18]
Evaluating Very Long-Term Conversational Memory of LLM Agents
Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. Evaluating very long-term conversational memory of llm agents.arXiv preprint arXiv:2402.17753,
work page internal anchor Pith review arXiv
-
[19]
Zep: A Temporal Knowledge Graph Architecture for Agent Memory
Preston Rasmussen, Pavlo Paliychuk, Travis Beauvais, Jack Ryan, and Daniel Chalef. Zep: a temporal knowledge graph architecture for agent memory.arXiv preprint arXiv:2501.13956,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
GitHub repository. Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathemat- ical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
URL https://arxiv.org/abs/2108. 00573. Hong Ting Tsang, Jiaxin Bai, Haoyu Huang, Qiao Xiao, Tianshi Zheng, Baixuan Xu, Shujie Liu, and Yangqiu Song. Autograph-r1: End-to-end reinforcement learning for knowledge graph construction. arXiv preprint arXiv:2510.15339,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
URL https://openreview.net/forum?id=ehfRiF0R3a
Yu Wang, Ryuichi Takanobu, Zhiqi Liang, Yuzhen Mao, Yuanzhe Hu, Julian McAuley, and Xiaojian Wu. Mem-{\alpha}: Learning memory construction via reinforcement learning.arXiv preprint arXiv:2509.25911,
-
[24]
Benedict Wolff and Jacopo Bennati. Cost and accuracy of long-term graph memory in distributed llm-based multi-agent systems.arXiv preprint arXiv:2601.07978,
-
[25]
Yunjia Xi, Jianghao Lin, Yongzhao Xiao, Zheli Zhou, Rong Shan, Te Gao, Jiachen Zhu, Weiwen Liu, Yong Yu, and Weinan Zhang. A survey of llm-based deep search agents: Paradigm, optimization, evaluation, and challenges.arXiv preprint arXiv:2508.05668,
-
[26]
Sikuan Yan, Xiufeng Yang, Zuchao Huang, Ercong Nie, Zifeng Ding, Zonggen Li, Xiaowen Ma, Jinhe Bi, Kristian Kersting, Jeff Z Pan, et al. Memory-r1: Enhancing large language model agents to manage and utilize memories via reinforcement learning.arXiv preprint arXiv:2508.19828,
work page internal anchor Pith review arXiv
-
[27]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
arXiv preprint arXiv:2602.05665 , year=
Chang Yang, Chuang Zhou, Yilin Xiao, Su Dong, Luyao Zhuang, Yujing Zhang, Zhu Wang, Zijin Hong, Zheng Yuan, Zhishang Xiang, et al. Graph-based agent memory: Taxonomy, techniques, and applications.arXiv preprint arXiv:2602.05665,
-
[29]
Hotpotqa: A dataset for diverse, explainable multi-hop question answering
12 Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D Manning. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. InProceedings of the 2018 conference on empirical methods in natural language processing, pages 2369–2380,
work page 2018
-
[30]
KG-BERT: BERT for knowledge graph completion,
Liang Yao, Chengsheng Mao, and Yuan Luo. Kg-bert: Bert for knowledge graph completion.arXiv preprint arXiv:1909.03193,
-
[31]
Yaoze Zhang, Rong Wu, Pinlong Cai, Xiaoman Wang, Guohang Yan, Song Mao, Ding Wang, and Botian Shi. Leanrag: Knowledge-graph-based generation with semantic aggregation and hierarchical retrieval.arXiv preprint arXiv:2508.10391,
-
[32]
Xinkui Zhao, Haode Li, Yifan Zhang, Guanjie Cheng, and Yueshen Xu. Trail: Joint inference and refinement of knowledge graphs with large language models.arXiv preprint arXiv:2508.04474,
-
[33]
A Details for Metrics A.1 Metrics for Benchmark Evaluation Following existing works [Trivedi et al., 2022, Jimenez Gutierrez et al., 2024, Yan et al., 2025], we employ the token-level F1 score as the metric for benchmark evaluation. A.2 Metrics for GBD Reward Following the prior work [Jiang et al., 2025], we also use the Generation Accuracy (GenAcc) as th...
work page 2022
-
[34]
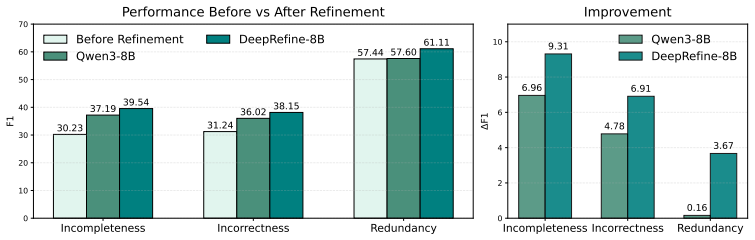
For LOCOMO dataset, m is set to 100 and ρ is set to 1.0. For other larger datasets,mis set to500andρis set to0.8. C Additional Experiments To further evaluate the effectiveness of DeepRefine on resolving incompleteness, incorrectness or redundancy issues, we provide a rigorous evaluation. We construct a high-quality benchmark characterized by explicit err...
work page 2018
-
[35]
Camdenton is a city in Camden County, Missouri, United States
The statistics in 2011 estimated the total population to be 8.11 million... Camdenton is a city in Camden County, Missouri, United States. The population was 3,718 at the 2010 census... ... What is the population in 2010 of the city popular with tourists? ... <‘Water tourism inside Strasbourg’,‘attracts’,‘hundreds of thousands of tourists yearly’>, <‘Okla...
work page 2011
-
[36]
He directed 159 films between 1926 and
was an American film director. He directed 159 films between 1926 and
work page 1926
-
[37]
His debut was the 1926 film serial ¨Fighting with Buffalo Bill¨. Ravina is an Indian actress who acted in Dhallywood movies. She acted in¨Praner Cheye Priyo ¨which film is considered as turning point of the career of Riaz. ... Which film has the director died later, Modern Husbands or The Fighting Vigilantes? ... <‘"Fighting with Buffalo Bill"’,‘was direc...
work page 1926
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.