Recognition: no theorem link
Guaranteed Jailbreaking Defense via Disrupt-and-Rectify Smoothing
Pith reviewed 2026-05-12 04:45 UTC · model grok-4.3
The pith
Disrupt-and-rectify smoothing provides a provable defense against jailbreaking attacks on large language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors propose Disrupt-and-Rectify Smoothing (DR-Smoothing) as a guaranteed defense method for LLMs against jailbreaking attacks. By integrating a two-stage prompt processing scheme—disrupting the input prompt then rectifying it—into the conventional smoothing defense framework, the approach restores out-of-distribution disrupted prompts to an in-distribution form. This reduces the risk of unpredictable LLM behavior compared to disrupt-only methods. The paper provides a theoretical analysis for the generic smoothing framework, offering a tight bound for the defense success probability and requirements on the disruption strength. The method defends against both token-level and prompt-lev
What carries the argument
The two-stage disrupt-and-rectify scheme inside a smoothing framework, where disruption thwarts attacks and rectification returns the prompt to a form the LLM can handle predictably.
Load-bearing premise
The rectification stage reliably maps disrupted out-of-distribution prompts back to in-distribution forms without introducing unpredictable LLM behavior or new vulnerabilities.
What would settle it
Finding cases where the rectification step leaves the prompt vulnerable to jailbreaks or causes the LLM to produce unexpected harmful outputs would disprove the claimed defense guarantee.
Figures

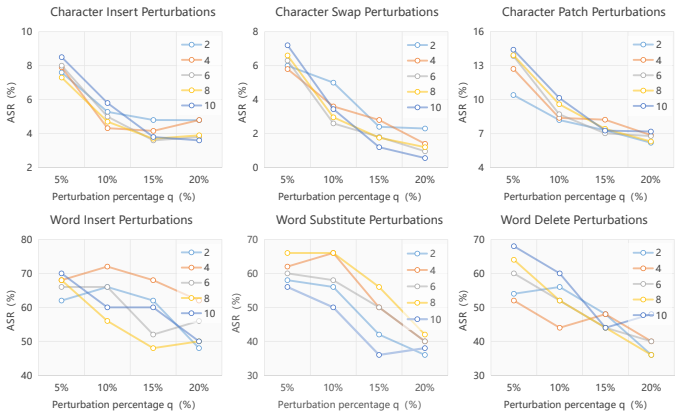
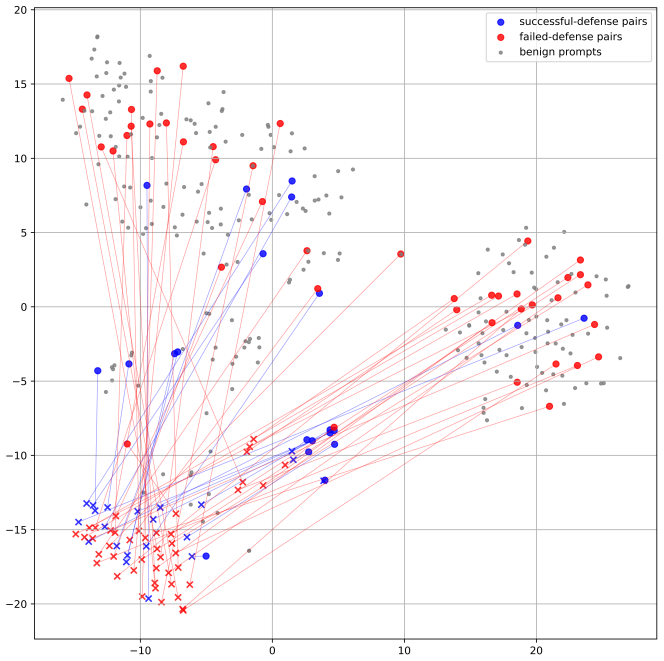
read the original abstract
This paper proposes a guaranteed defense method for large language models (LLMs) to safeguard against jailbreaking attacks. Drawing inspiration from the denoised-smoothing approach in the adversarial defense domain, we propose a novel smoothing-based defense method, termed Disrupt-and-Rectify Smoothing (DR-Smoothing). Specifically, we integrate a two-stage prompt processing scheme-first disrupting the input prompt, then rectifying it-into the conventional smoothing defense framework. This disrupt-and-rectify approach improves upon previous disrupt-only approaches by restoring out-of-distribution disrupted prompts to an in-distribution form, thereby reducing the risk of unpredictable LLM behavior. In addition, this two-stage scheme offers a distinct advantage in striking a balance between harmlessness and helpfulness in jailbreaking defense. Notably, we present a theoretical analysis for generic smoothing framework, offering a tight bound for the defense success probability and the requirements on the disruption strength. Our approach can defend against both token-level and prompt-level jailbreaking attacks, under both established and adaptive attacking scenarios. Extensive experiments demonstrate that our approach surpasses current state-of-the-art defense methods in terms of both harmlessness and helpfulness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Disrupt-and-Rectify Smoothing (DR-Smoothing) as a defense for LLMs against jailbreaking. It augments standard smoothing with a two-stage prompt process (disruption followed by rectification to restore in-distribution form), claims a theoretical analysis yielding a tight bound on defense success probability together with requirements on disruption strength, and reports that the method outperforms prior defenses on both token-level and prompt-level attacks under established and adaptive scenarios while balancing harmlessness and helpfulness.
Significance. If the claimed tight bound holds and rectification preserves the necessary distributional invariance without semantic drift or new attack surfaces, the result would strengthen certified robustness techniques for LLMs by overcoming the unpredictability of pure disruption methods and offering a practical trade-off between safety and utility.
major comments (2)
- [Abstract / Theoretical Analysis] Abstract and theoretical analysis: the derivation of the tight bound on defense success probability assumes that the rectification stage maps disrupted OOD prompts back to ID forms without semantic drift or altering the LLM response distribution used in the bound. No separate proof or invariance argument is supplied for this step, which is load-bearing for the bound's validity under both token-level and adaptive prompt-level attacks.
- [Abstract] Abstract: the claim that the bound is 'generic' and independent of LLM-specific assumptions is not accompanied by the derivation details or error analysis needed to confirm it remains tight when rectification is performed by an auxiliary model or heuristic that could itself introduce distributional shifts.
minor comments (2)
- [Experiments] The experimental section would benefit from explicit reporting of the exact disruption operator, rectification procedure, and any ablation on rectification failure modes to allow verification of the claimed balance between harmlessness and helpfulness.
- [Theoretical Analysis] Notation for the smoothing parameters and the disruption strength threshold should be introduced with a clear table or equation reference to improve readability of the theoretical requirements.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major comment point by point below, indicating planned revisions where the manuscript requires strengthening.
read point-by-point responses
-
Referee: [Abstract / Theoretical Analysis] Abstract and theoretical analysis: the derivation of the tight bound on defense success probability assumes that the rectification stage maps disrupted OOD prompts back to ID forms without semantic drift or altering the LLM response distribution used in the bound. No separate proof or invariance argument is supplied for this step, which is load-bearing for the bound's validity under both token-level and adaptive prompt-level attacks.
Authors: The referee is correct that the manuscript derives the tight bound under the assumption that rectification restores in-distribution prompts without semantic drift or change to the LLM response distribution, but does not supply a dedicated invariance argument. The bound is obtained by composing the standard smoothing probability with the probability that rectification succeeds in mapping to ID; we will revise the theoretical analysis section to include an explicit invariance lemma showing that, conditional on successful rectification to ID (as controlled by the disruption strength), the response distribution matches that of the original ID prompts. This will be supported by a short discussion of rectifier design choices that limit semantic drift, plus additional empirical checks of response consistency. revision: yes
-
Referee: [Abstract] Abstract: the claim that the bound is 'generic' and independent of LLM-specific assumptions is not accompanied by the derivation details or error analysis needed to confirm it remains tight when rectification is performed by an auxiliary model or heuristic that could itself introduce distributional shifts.
Authors: The analysis is framed for a generic smoothing framework whose bound depends only on disruption strength and rectification success probability, not on LLM internals. We agree that the current text lacks sufficient derivation steps and error analysis for auxiliary rectifiers. In revision we will expand the theoretical section (and appendix) with the full derivation outline, including an additive error term that bounds any distributional shift introduced by a fixed auxiliary rectifier, thereby confirming that the bound remains tight whenever the rectification success probability exceeds the stated threshold. revision: yes
Circularity Check
No circularity in claimed theoretical bound or method derivation
full rationale
The paper presents a theoretical analysis for a generic smoothing framework that yields a claimed tight bound on defense success probability and disruption strength requirements. This bound is positioned as derived from the framework itself rather than fitted to LLM-specific data or reduced to the rectification step by construction. The disrupt-and-rectify extension is described as an improvement over prior disrupt-only methods to restore in-distribution prompts, but the bound is stated for the generic case and does not appear to depend on self-referential definitions, fitted parameters renamed as predictions, or load-bearing self-citations. No equations or steps in the abstract reduce the result to its inputs; the analysis is presented as independent first-principles work on the smoothing framework, with experiments serving as separate validation. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Smoothing framework provides probabilistic guarantees when disruption strength meets a derived threshold
- domain assumption Rectification maps disrupted prompts back to the original input distribution
Reference graph
Works this paper leans on
-
[1]
Structure and Interpretation of Computer Programs
Harold Abelson and Gerald Jay Sussman and Julie Sussman. Structure and Interpretation of Computer Programs. 1985
work page 1985
-
[2]
Visual Information Extraction with Lixto
Robert Baumgartner and Georg Gottlob and Sergio Flesca. Visual Information Extraction with Lixto. Proceedings of the 27th International Conference on Very Large Databases. 2001
work page 2001
-
[3]
Ronald J. Brachman and James G. Schmolze. An overview of the KL-ONE knowledge representation system. Cognitive Science. 1985
work page 1985
-
[4]
Complexity results for nonmonotonic logics
Georg Gottlob. Complexity results for nonmonotonic logics. Journal of Logic and Computation. 1992
work page 1992
-
[5]
Hypertree Decompositions and Tractable Queries
Georg Gottlob and Nicola Leone and Francesco Scarcello. Hypertree Decompositions and Tractable Queries. Journal of Computer and System Sciences. 2002
work page 2002
- [6]
- [7]
-
[8]
On the compilability and expressive power of propositional planning formalisms
Bernhard Nebel. On the compilability and expressive power of propositional planning formalisms. Journal of Artificial Intelligence Research. 2000
work page 2000
-
[9]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[10]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Training a helpful and harmless assistant with reinforcement learning from human feedback , author=. arXiv preprint arXiv:2204.05862 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
LaMDA: Language Models for Dialog Applications
Lamda: Language models for dialog applications , author=. arXiv preprint arXiv:2201.08239 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Realtoxicityprompts: Evaluating neural toxic degenera- tion in language models
Realtoxicityprompts: Evaluating neural toxic degeneration in language models , author=. arXiv preprint arXiv:2009.11462 , year=
-
[13]
Red Teaming Language Models with Language Models
Red teaming language models with language models , author=. arXiv preprint arXiv:2202.03286 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
The woman worked as a babysitter: On biases in language generation
The woman worked as a babysitter: On biases in language generation , author=. arXiv preprint arXiv:1909.01326 , year=
-
[15]
Proceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society , pages=
Persistent anti-muslim bias in large language models , author=. Proceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society , pages=
work page 2021
-
[16]
30th USENIX Security Symposium (USENIX Security 21) , pages=
Extracting training data from large language models , author=. 30th USENIX Security Symposium (USENIX Security 21) , pages=
-
[17]
Fine-Tuning Language Models from Human Preferences
Fine-tuning language models from human preferences , author=. arXiv preprint arXiv:1909.08593 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[18]
Advances in Neural Information Processing Systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in Neural Information Processing Systems , volume=
-
[19]
International Conference on Machine Learning , pages=
Pretraining language models with human preferences , author=. International Conference on Machine Learning , pages=. 2023 , organization=
work page 2023
-
[20]
Jailbroken: How Does LLM Safety Training Fail?
Jailbroken: How does llm safety training fail? , author=. arXiv preprint arXiv:2307.02483 , year=
work page internal anchor Pith review arXiv
-
[21]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Universal and transferable adversarial attacks on aligned language models , author=. arXiv preprint arXiv:2307.15043 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
Llama guard: Llm-based input-output safeguard for human-ai conversations , author=. arXiv preprint arXiv:2312.06674 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Visual instruction tuning , author=. arXiv preprint arXiv:2304.08485 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Minigpt-v2: large language model as a unified interface for vision-language multi-task learning
Minigpt-v2: large language model as a unified interface for vision-language multi-task learning , author=. arXiv preprint arXiv:2310.09478 , year=
-
[25]
Advances in Neural Information Processing Systems , volume=
Flamingo: a visual language model for few-shot learning , author=. Advances in Neural Information Processing Systems , volume=
-
[26]
mplug-owl2: Revolutionizing multi-modal large language model with modality collaboration
mplug-owl2: Revolutionizing multi-modal large language model with modality collaboration , author=. arXiv preprint arXiv:2311.04257 , year=
-
[27]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond , author=. arXiv preprint arXiv:2308.12966 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning , author=. 2023 , eprint=
work page 2023
- [29]
-
[30]
https://blog.google/technology/ai/bard-google-ai-search-updates/
Google. 2023 , url = "https://blog.google/technology/ai/bard-google-ai-search-updates/", urldate =
work page 2023
-
[31]
arXiv preprint arXiv:2106.04169 , year=
On improving adversarial transferability of vision transformers , author=. arXiv preprint arXiv:2106.04169 , year=
-
[32]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
On the robustness of vision transformers to adversarial examples , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[33]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Towards transferable adversarial attacks on vision transformers , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[34]
arXiv preprint arXiv:2203.08392 , year=
Patch-fool: Are vision transformers always robust against adversarial perturbations? , author=. arXiv preprint arXiv:2203.08392 , year=
-
[35]
Autoprompt: Eliciting knowledge from language models wit h automatically generated prompts,
Autoprompt: Eliciting knowledge from language models with automatically generated prompts , author=. arXiv preprint arXiv:2010.15980 , year=
-
[36]
Hard prompts made easy: Gradient-based discrete optimization for prompt tuning and discovery, 2023
Hard prompts made easy: Gradient-based discrete optimization for prompt tuning and discovery , author=. arXiv preprint arXiv:2302.03668 , year=
-
[37]
Gradient-based Adversarial Attacks against Text Transformers
Gradient-based adversarial attacks against text transformers , author=. arXiv preprint arXiv:2104.13733 , year=
-
[38]
Are aligned neural networks adversarially aligned? arXiv preprint arXiv:2306.15447, 2023
Are aligned neural networks adversarially aligned? , author=. arXiv preprint arXiv:2306.15447 , year=
-
[39]
Explaining and Harnessing Adversarial Examples
Explaining and harnessing adversarial examples , author=. arXiv preprint arXiv:1412.6572 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
Towards Deep Learning Models Resistant to Adversarial Attacks
Towards deep learning models resistant to adversarial attacks , author=. arXiv preprint arXiv:1706.06083 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
2017 ieee symposium on security and privacy (sp) , pages=
Towards evaluating the robustness of neural networks , author=. 2017 ieee symposium on security and privacy (sp) , pages=. 2017 , organization=
work page 2017
-
[42]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Llama 2: Open foundation and fine-tuned chat models , author=. arXiv preprint arXiv:2307.09288 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
Minigpt-4: Enhancing vision-language understanding with advanced large language models , author=. arXiv preprint arXiv:2304.10592 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
Judging LLM-as-a-judge with MT-Bench and Chatbot Arena , author=. 2023 , eprint=
work page 2023
-
[45]
arXiv preprint arXiv:2309.00236 , year=
Image Hijacks: Adversarial Images can Control Generative Models at Runtime , author=. arXiv preprint arXiv:2309.00236 , year=
-
[46]
arXiv preprint arXiv:2309.11751 , year=
How Robust is Google's Bard to Adversarial Image Attacks? , author=. arXiv preprint arXiv:2309.11751 , year=
-
[47]
Visual Adversarial Examples Jailbreak Aligned Large Language Models , author=. 2023 , eprint=
work page 2023
-
[48]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Universal adversarial perturbations , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[49]
arXiv preprint arXiv:1705.07204 , year=
Ensemble adversarial training: Attacks and defenses , author=. arXiv preprint arXiv:1705.07204 , year=
-
[50]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Improving transferability of adversarial examples with input diversity , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[51]
Advances in Neural Information Processing Systems , volume=
On evaluating adversarial robustness of large vision-language models , author=. Advances in Neural Information Processing Systems , volume=
-
[52]
The Twelfth International Conference on Learning Representations , year=
An Image Is Worth 1000 Lies: Transferability of Adversarial Images across Prompts on Vision-Language Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[53]
arXiv preprint arXiv:2402.00357 , year=
Safety of Multimodal Large Language Models on Images and Text , author=. arXiv preprint arXiv:2402.00357 , year=
-
[54]
arXiv preprint arXiv:2403.09792 , year=
Images are Achilles' Heel of Alignment: Exploiting Visual Vulnerabilities for Jailbreaking Multimodal Large Language Models , author=. arXiv preprint arXiv:2403.09792 , year=
-
[55]
FigStep: Jailbreaking Large Vision- language Models via Typographic Visual Prompts
Figstep: Jailbreaking large vision-language models via typographic visual prompts , author=. arXiv preprint arXiv:2311.05608 , year=
-
[56]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Set-level guidance attack: Boosting adversarial transferability of vision-language pre-training models , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[57]
Llama Team , title =
-
[58]
Baseline Defenses for Adversarial Attacks Against Aligned Language Models , author=. 2023 , eprint=
work page 2023
-
[59]
Query-Relevant Images Jailbreak Large Multi-Modal Models , author =. 2023 , eprint =
work page 2023
-
[60]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Visual adversarial examples jailbreak aligned large language models , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[61]
Jailbreak in pieces: Compositional Adversarial Attacks on Multi-Modal Language Models , author=. 2023 , eprint=
work page 2023
-
[62]
SmoothLLM: Defending Large Language Models Against Jailbreaking Attacks , author=. 2024 , eprint=
work page 2024
-
[63]
Certified Adversarial Robustness via Randomized Smoothing , author=. 2019 , eprint=
work page 2019
-
[64]
Denoised Smoothing: A Provable Defense for Pretrained Classifiers , author=. 2020 , eprint=
work page 2020
-
[65]
Detecting Language Model Attacks with Perplexity , author=. 2023 , eprint=
work page 2023
-
[66]
On the Reliability of Watermarks for Large Language Models , author=. 2024 , eprint=
work page 2024
-
[67]
BPE-Dropout: Simple and Effective Subword Regularization , author=. 2020 , eprint=
work page 2020
-
[68]
HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal , author=. 2024 , eprint=
work page 2024
-
[69]
Fundamental Limitations of Alignment in Large Language Models , author=. 2024 , eprint=
work page 2024
-
[70]
Mission Impossible: A Statistical Perspective on Jailbreaking LLMs , author=. 2024 , eprint=
work page 2024
-
[71]
Build it Break it Fix it for Dialogue Safety: Robustness from Adversarial Human Attack , author=. 2019 , eprint=
work page 2019
-
[72]
Beyond Accuracy: Behavioral Testing of NLP models with CheckList , author=. 2020 , eprint=
work page 2020
-
[73]
Automatically Auditing Large Language Models via Discrete Optimization , author=. 2023 , eprint=
work page 2023
-
[74]
Black Box Adversarial Prompting for Foundation Models , author=. 2023 , eprint=
work page 2023
-
[75]
Defending Large Language Models against Jailbreak Attacks via Semantic Smoothing , author=. 2024 , eprint=
work page 2024
-
[76]
Jailbreaking Black Box Large Language Models in Twenty Queries , author=. 2024 , eprint=
work page 2024
-
[77]
Towards Deep Learning Models Resistant to Adversarial Attacks , author=. 2019 , eprint=
work page 2019
-
[78]
N eu S pell: A Neural Spelling Correction Toolkit
Jayanthi, Sai Muralidhar and Pruthi, Danish and Neubig, Graham. N eu S pell: A Neural Spelling Correction Toolkit. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. 2020. doi:10.18653/v1/2020.emnlp-demos.21
-
[79]
Grammatical Error Correction: A Survey of the State of the Art , ISSN=
Bryant, Christopher and Yuan, Zheng and Qorib, Muhammad Reza and Cao, Hannan and Ng, Hwee Tou and Briscoe, Ted , year=. Grammatical Error Correction: A Survey of the State of the Art , ISSN=. doi:10.1162/coli_a_00478 , journal=
-
[80]
Certifying LLM Safety against Adversarial Prompting , author=. 2025 , eprint=
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.