Recognition: 2 theorem links
· Lean TheoremDynamic Cross-Modal Prompt Generation for Multimodal Continual Instruction Tuning
Pith reviewed 2026-05-12 03:23 UTC · model grok-4.3
The pith
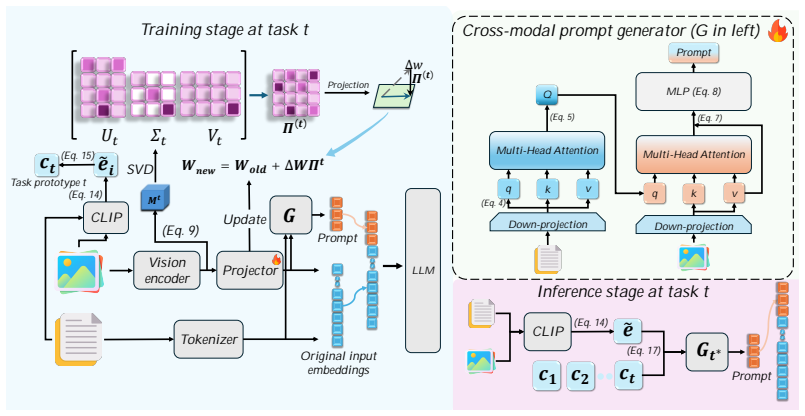
DRAPE generates instance-specific soft prompts for each query-image pair in multimodal models by deriving queries from text and cross-attending to visual patches, then prepends them to a frozen LLM while using null-space projection and CLIP
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DRAPE creates continuous instance-specific soft prompts by extracting query features from the textual instruction and cross-attending them to visual patch features from the image, then prepending the resulting prompts to the frozen LLM; forgetting is controlled by projecting gradients into the null space of the shared projector during updates and by selecting the appropriate generator at inference through CLIP-based prototype routing without task labels.
What carries the argument
Dynamic cross-modal prompt generation that produces query-image-conditioned soft prompts via text-derived queries cross-attended to visual patches, protected by null-space gradient projection and CLIP prototype routing.
If this is right
- Intra-task sample differences in visuals and reasoning are handled by per-instance prompts rather than task-level selection.
- No task identity is needed at inference because routing uses CLIP prototypes.
- The shared projector remains stable across updates through null-space projection.
- Performance exceeds representative prompt and LoRA continual baselines on MCIT benchmarks.
Where Pith is reading between the lines
- The approach could reduce the need for storing separate modules per task, lowering memory growth in long task sequences.
- Instance-level conditioning might improve robustness when test distributions shift within a known task.
- If the projection and routing generalize, similar dynamic generation could apply to other frozen-backbone continual setups.
Load-bearing premise
Null-space gradient projection on the shared projector together with CLIP-based prototype routing will keep forgetting low across any sequence of tasks even when no task labels are supplied at inference.
What would settle it
A sequential task stream in which accuracy on earlier tasks falls sharply below the best baseline after several updates despite applying the null-space projection and prototype routing.
Figures









read the original abstract
Multimodal Large Language Models (MLLMs) achieve strong performance through instruction tuning, yet real-world deployment often requires continual capability expansion across sequential tasks. In such scenarios, Multimodal Continual Instruction Tuning (MCIT) aims to acquire new capabilities while limiting catastrophic forgetting. Existing methods mainly follow a module-composition paradigm: they maintain task-level prompts or LoRA experts and dynamically route or aggregate a subset of them at inference. However, samples within the same task can still differ substantially in visual scenes, question intents, and reasoning demands. This motivates instance-level adaptation to individual query-image pairs rather than only selecting or combining task-level modules. To this end, we propose DRAPE (Dynamic Cross-Modal Prompt Generation), a prompt-learning framework that synthesizes continuous instance-specific soft prompts for MCIT. Instead of selecting prompts from a fixed pool, DRAPE derives prompt queries from the textual instruction and cross-attends to visual patch features, producing query-image conditioned prompts that are prepended to the frozen LLM. To mitigate forgetting during sequential updates, DRAPE applies null-space gradient projection to the shared projector and uses CLIP-based prototype routing for task-label-free generator selection at inference. Extensive experiments on MCIT benchmarks show that DRAPE achieves state-of-the-art performance among representative prompt-based and LoRA-based continual-learning baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DRAPE (Dynamic Cross-Modal Prompt Generation), a prompt-learning framework for Multimodal Continual Instruction Tuning (MCIT) in MLLMs. It generates instance-specific soft prompts by deriving queries from the textual instruction and cross-attending to visual patch features, prepending these to the frozen LLM. Forgetting is mitigated via null-space gradient projection on the shared projector during sequential updates, combined with CLIP-based prototype routing to enable task-label-free generator selection at inference. The central claim is that extensive experiments on MCIT benchmarks demonstrate state-of-the-art performance relative to representative prompt-based and LoRA-based continual-learning baselines.
Significance. If the empirical results hold, the work offers a meaningful advance by shifting from task-level module composition to instance-level prompt synthesis, better accommodating intra-task variability in visual scenes and reasoning demands. The combination of null-space projection with CLIP prototypes is a practical synthesis of established techniques that avoids circular fitting and supports label-free inference. This could inform more flexible continual adaptation strategies for large multimodal models in deployment scenarios.
major comments (2)
- Abstract and §4: The headline claim of SOTA performance is stated without accompanying quantitative tables, exact metric values, baseline implementation details, ablation studies, or error bars. This prevents direct verification of the magnitude and statistical reliability of the reported gains over prompt-based and LoRA baselines.
- §3.2: The null-space gradient projection is applied to the shared projector, but the manuscript does not specify how the null-space basis is maintained or updated across sequential tasks when new visual-textual distributions arrive; without this, it is unclear whether the projection remains effective at preventing interference in later tasks.
minor comments (2)
- The expansion of the DRAPE acronym is implicit from the title but should be stated explicitly on first use in the abstract and introduction for clarity.
- Notation for the cross-attention operation between prompt queries and visual patches could be formalized with an equation to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive overall assessment. We address each major comment below with clarifications and commitments to revisions that strengthen the presentation without altering the core contributions.
read point-by-point responses
-
Referee: Abstract and §4: The headline claim of SOTA performance is stated without accompanying quantitative tables, exact metric values, baseline implementation details, ablation studies, or error bars. This prevents direct verification of the magnitude and statistical reliability of the reported gains over prompt-based and LoRA baselines.
Authors: We appreciate this point. Section 4 already contains the full quantitative tables with exact metric values, baseline implementation details, and ablation studies. To address the concern about immediate verifiability in the abstract and opening of §4, we will revise the abstract to include a concise summary of key performance deltas and add error bars (computed over multiple random seeds) to all relevant tables and figures in the revised manuscript. This improves accessibility while preserving the existing experimental content. revision: partial
-
Referee: §3.2: The null-space gradient projection is applied to the shared projector, but the manuscript does not specify how the null-space basis is maintained or updated across sequential tasks when new visual-textual distributions arrive; without this, it is unclear whether the projection remains effective at preventing interference in later tasks.
Authors: Thank you for identifying this gap in clarity. The current description in §3.2 focuses on the projection step but does not explicitly detail the cross-task maintenance procedure. In the revision we will expand §3.2 with the following specification: after each task t, the null-space basis is updated by computing the orthogonal complement (via SVD) to the accumulated gradient matrix formed from all prior tasks 1…t; the new basis is then used for projection in task t+1. This incremental orthogonalization ensures the protected subspace grows without circular fitting and remains effective against interference from future distributions. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper describes an empirical method DRAPE using cross-modal attention for instance-specific prompts, null-space projection on the projector, and CLIP prototype routing for inference. These build on prior established techniques without any equations or claims that reduce by construction to the method's own fitted parameters or self-citations. Performance claims rest on benchmark experiments rather than derivations, and no load-bearing step equates a prediction to its input definition.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearDRAPE applies null-space gradient projection to the shared projector... M(t) = ... SVD ... Π(t) = V⊥V⊤⊥ ... ∇W′ = ∇W Π(t)
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclearCLIP-based prototype routing for task-label-free generator selection
Reference graph
Works this paper leans on
-
[1]
Continual llava: Continual instruction tuning in large vision-language models
Meng Cao, Yuyang Liu, Yingfei Liu, Tiancai Wang, Jiahua Dong, Henghui Ding, Xiangyu Zhang, Ian Reid, and Xiaodan Liang. Continual llava: Continual instruction tuning in large vision-language models. arXiv preprint arXiv:2411.02564, 2024
-
[2]
Cheng Chen, Junchen Zhu, Xu Luo, Heng T Shen, Jingkuan Song, and Lianli Gao. Coin: A benchmark of continual instruction tuning for multimodel large language models.Advances in neural information processing systems, 37:57817–57840, 2024
work page 2024
-
[3]
Jinpeng Chen, Runmin Cong, Yuzhi Zhao, Hongzheng Yang, Guangneng Hu, Horace Ho Shing Ip, and Sam Kwong. Sefe: Superficial and essential forgetting eliminator for multimodal continual instruction tuning.arXiv preprint arXiv:2505.02486, 2025
-
[4]
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale N Fung, and Steven Hoi. Instructblip: Towards general-purpose vision-language models with instruction tuning.Advances in neural information processing systems, 36:49250–49267, 2023
work page 2023
-
[5]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009
work page 2009
-
[6]
Loramoe: Alleviate world knowledge for- getting in large language models via moe-style plugin,
Shihan Dou, Enyu Zhou, Yan Liu, Songyang Gao, Jun Zhao, Wei Shen, Yuhao Zhou, Zhiheng Xi, Xiao Wang, Xiaoran Fan, et al. Loramoe: Revolutionizing mixture of experts for maintaining world knowledge in language model alignment.arXiv preprint arXiv:2312.09979, 4(7), 2023
-
[7]
Catastrophic forgetting in connectionist networks.Trends in cognitive sciences, 3(4): 128–135, 1999
Robert M French. Catastrophic forgetting in connectionist networks.Trends in cognitive sciences, 3(4): 128–135, 1999
work page 1999
-
[8]
Chendi Ge, Xin Wang, Zeyang Zhang, Hong Chen, Jiapei Fan, Longtao Huang, Hui Xue, and Wenwu Zhu. Dynamic mixture of curriculum lora experts for continual multimodal instruction tuning.arXiv preprint arXiv:2506.11672, 2025
-
[9]
Making the v in vqa matter: Elevating the role of image understanding in visual question answering
Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Making the v in vqa matter: Elevating the role of image understanding in visual question answering. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 6904–6913, 2017
work page 2017
-
[10]
Haiyang Guo, Fanhu Zeng, Ziwei Xiang, Fei Zhu, Da-Han Wang, Xu-Yao Zhang, and Cheng-Lin Liu. Hide-llava: Hierarchical decoupling for continual instruction tuning of multimodal large language model. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 13572–13586, 2025
work page 2025
-
[11]
A comprehensive survey on continual learning in generative models
Haiyang Guo, Fanhu Zeng, Fei Zhu, Jiayi Wang, Xukai Wang, Jingang Zhou, Hongbo Zhao, Wenzhuo Liu, Shijie Ma, Da-Han Wang, et al. A comprehensive survey on continual learning in generative models. arXiv preprint arXiv:2506.13045, 2025
-
[12]
Vizwiz grand challenge: Answering visual questions from blind people
Danna Gurari, Qing Li, Abigale J Stangl, Anhong Guo, Chi Lin, Kristen Grauman, Jiebo Luo, and Jeffrey P Bigham. Vizwiz grand challenge: Answering visual questions from blind people. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 3608–3617, 2018
work page 2018
-
[13]
The many faces of robustness: A critical analysis of out-of-distribution generalization
Dan Hendrycks, Steven Basart, Norman Mu, Saurav Kadavath, Frank Wang, Evan Dorundo, Rahul Desai, Tyler Zhu, Samyak Parajuli, Mike Guo, et al. The many faces of robustness: A critical analysis of out-of-distribution generalization. InProceedings of the IEEE/CVF international conference on computer vision, pages 8340–8349, 2021
work page 2021
-
[14]
Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
work page 2022
-
[15]
Tianyu Huai, Jie Zhou, Xingjiao Wu, Qin Chen, Qingchun Bai, Ze Zhou, and Liang He. Cl-moe: Enhancing multimodal large language model with dual momentum mixture-of-experts for continual visual question answering. InProceedings of the computer vision and pattern recognition conference, pages 19608–19617, 2025
work page 2025
-
[16]
Gqa: A new dataset for real-world visual reasoning and compositional question answering
Drew A Hudson and Christopher D Manning. Gqa: A new dataset for real-world visual reasoning and compositional question answering. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6700–6709, 2019. 10
work page 2019
-
[17]
Clevr: A diagnostic dataset for compositional language and elementary visual reasoning
Justin Johnson, Bharath Hariharan, Laurens Van Der Maaten, Li Fei-Fei, C Lawrence Zitnick, and Ross Girshick. Clevr: A diagnostic dataset for compositional language and elementary visual reasoning. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2901–2910, 2017
work page 2017
-
[18]
Generating instance-level prompts for rehearsal-free continual learning
Dahuin Jung, Dongyoon Han, Jihwan Bang, and Hwanjun Song. Generating instance-level prompts for rehearsal-free continual learning. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 11847–11857, 2023
work page 2023
-
[19]
Referitgame: Referring to objects in photographs of natural scenes
Sahar Kazemzadeh, Vicente Ordonez, Mark Matten, and Tamara Berg. Referitgame: Referring to objects in photographs of natural scenes. InProceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), pages 787–798, 2014
work page 2014
-
[20]
Revisit visual prompt tuning: The expressiveness of prompt experts
Minh Le, Anh Nguyen, Huy Nguyen, Chau Nguyen, Anh Tuan Tran, and Nhat Ho. Revisit visual prompt tuning: The expressiveness of prompt experts. InThe F ourteenth International Conference on Learning Representations
-
[21]
Multimodal arxiv: A dataset for improving scientific comprehension of large vision-language models
Lei Li, Yuqi Wang, Runxin Xu, Peiyi Wang, Xiachong Feng, Lingpeng Kong, and Qi Liu. Multimodal arxiv: A dataset for improving scientific comprehension of large vision-language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 14369–14387, 2024
work page 2024
-
[22]
Clevr-math: A dataset for compositional lan- guage, visual and mathematical reasoning
Adam Dahlgren Lindström and Savitha Sam Abraham. Clevr-math: A dataset for compositional language, visual and mathematical reasoning.arXiv preprint arXiv:2208.05358, 2022
-
[23]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
work page 2023
-
[24]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26296–26306, 2024
work page 2024
-
[25]
Visual instruction tuning.Advances in neural information processing systems, 36, 2024
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36, 2024
work page 2024
-
[26]
Yiyang Liu, James C Liang, Heng Fan, Wenhao Yang, Yiming Cui, Xiaotian Han, Lifu Huang, Dongfang Liu, Qifan Wang, and Cheng Han. All you need is one: Capsule prompt tuning with a single vector.arXiv preprint arXiv:2510.16670, 2025
-
[27]
The flan collection: Designing data and methods for effective instruction tuning
Shayne Longpre, Le Hou, Tu Vu, Albert Webson, Hyung Won Chung, Yi Tay, Denny Zhou, Quoc V Le, Barret Zoph, Jason Wei, et al. The flan collection: Designing data and methods for effective instruction tuning. InInternational conference on machine learning, pages 22631–22648. PMLR, 2023
work page 2023
-
[28]
Iconqa: A new benchmark for abstract diagram under- standing and visual language reasoning
Pan Lu, Liang Qiu, Jiaqi Chen, Tony Xia, Yizhou Zhao, Wei Zhang, Zhou Yu, Xiaodan Liang, and Song-Chun Zhu. Iconqa: A new benchmark for abstract diagram understanding and visual language reasoning.arXiv preprint arXiv:2110.13214, 2021
-
[29]
Pan Lu, Swaroop Mishra, Tanglin Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. Learn to explain: Multimodal reasoning via thought chains for science question answering.Advances in Neural Information Processing Systems, 35:2507–2521, 2022
work page 2022
-
[30]
Generation and comprehension of unambiguous object descriptions
Junhua Mao, Jonathan Huang, Alexander Toshev, Oana Camburu, Alan L Yuille, and Kevin Murphy. Generation and comprehension of unambiguous object descriptions. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 11–20, 2016
work page 2016
-
[31]
Ocr-vqa: Visual question answering by reading text in images
Anand Mishra, Shashank Shekhar, Ajeet Kumar Singh, and Anirban Chakraborty. Ocr-vqa: Visual question answering by reading text in images. In2019 international conference on document analysis and recognition (ICDAR), pages 947–952. IEEE, 2019
work page 2019
-
[32]
Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models
Bryan A Plummer, Liwei Wang, Chris M Cervantes, Juan C Caicedo, Julia Hockenmaier, and Svetlana Lazebnik. Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models. InProceedings of the IEEE international conference on computer vision, pages 2641–2649, 2015
work page 2015
-
[33]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PMLR, 2021. 11
work page 2021
-
[34]
Guangyuan Shi, Jiaxin Chen, Wenlong Zhang, Li-Ming Zhan, and Xiao-Ming Wu. Overcoming catastrophic forgetting in incremental few-shot learning by finding flat minima.Advances in neural information processing systems, 34:6747–6761, 2021
work page 2021
-
[35]
Towards vqa models that can read
Amanpreet Singh, Vivek Natarajan, Meet Shah, Yu Jiang, Xinlei Chen, Dhruv Batra, Devi Parikh, and Marcus Rohrbach. Towards vqa models that can read. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8317–8326, 2019
work page 2019
-
[36]
Coda-prompt: Continual decomposed attention- based prompting for rehearsal-free continual learning
James Seale Smith, Leonid Karlinsky, Vyshnavi Gutta, Paola Cascante-Bonilla, Donghyun Kim, Assaf Arbelle, Rameswar Panda, Rogerio Feris, and Zsolt Kira. Coda-prompt: Continual decomposed attention- based prompting for rehearsal-free continual learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11909–11919, 2023
work page 2023
-
[37]
Metamorph: Multimodal understanding and generation via instruction tuning
Shengbang Tong, David Fan, Jiachen Li, Yunyang Xiong, Xinlei Chen, Koustuv Sinha, Michael Rabbat, Yann LeCun, Saining Xie, and Zhuang Liu. Metamorph: Multimodal understanding and generation via instruction tuning. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 17001–17012, 2025
work page 2025
-
[38]
Rehearsal-free modular and compositional continual learning for language models
Mingyang Wang, Heike Adel, Lukas Lange, Jannik Strötgen, and Hinrich Schütze. Rehearsal-free modular and compositional continual learning for language models. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (V olume 2: Short Papers), pages 469–480, 2024
work page 2024
-
[39]
Orthogonal subspace learning for language model continual learning
Xiao Wang, Tianze Chen, Qiming Ge, Han Xia, Rong Bao, Rui Zheng, Qi Zhang, Tao Gui, and Xuan-Jing Huang. Orthogonal subspace learning for language model continual learning. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 10658–10671, 2023
work page 2023
-
[40]
Yifan Wang, Yafei Liu, Chufan Shi, Haoling Li, Chen Chen, Haonan Lu, and Yujiu Yang. Inscl: A data-efficient continual learning paradigm for fine-tuning large language models with instructions. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (V olume 1: Long ...
work page 2024
-
[41]
Dualprompt: Complementary prompting for rehearsal-free continual learning
Zifeng Wang, Zizhao Zhang, Sayna Ebrahimi, Ruoxi Sun, Han Zhang, Chen-Yu Lee, Xiaoqi Ren, Guolong Su, Vincent Perot, Jennifer Dy, et al. Dualprompt: Complementary prompting for rehearsal-free continual learning. InEuropean Conference on Computer Vision, pages 631–648. Springer, 2022
work page 2022
-
[42]
Finetuned Language Models Are Zero-Shot Learners
Jason Wei, Maarten Bosma, Vincent Y Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M Dai, and Quoc V Le. Finetuned language models are zero-shot learners.arXiv preprint arXiv:2109.01652, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[43]
Continual learning for large language models: A survey.arXiv preprint arXiv:2402.01364, 2024
Tongtong Wu, Linhao Luo, Yuan-Fang Li, Shirui Pan, Thuy-Trang Vu, and Gholamreza Haffari. Continual learning for large language models: A survey.arXiv preprint arXiv:2402.01364, 2024
-
[44]
Idpg: An instance-dependent prompt generation method
Zhuofeng Wu, Sinong Wang, Jiatao Gu, Rui Hou, Yuxiao Dong, VG Vinod Vydiswaran, and Hao Ma. Idpg: An instance-dependent prompt generation method. InProceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 5507–5521, 2022
work page 2022
-
[45]
Visual instance-aware prompt tuning
Xi Xiao, Yunbei Zhang, Xingjian Li, Tianyang Wang, Xiao Wang, Yuxiang Wei, Jihun Hamm, and Min Xu. Visual instance-aware prompt tuning. InProceedings of the 33rd ACM International Conference on Multimedia, pages 2880–2889, 2025
work page 2025
-
[46]
Zhen-Hao Xie, Jun-Tao Tang, Yu-Cheng Shi, Han-Jia Ye, De-Chuan Zhan, and Da-Wei Zhou. Same: Stabilized mixture-of-experts for multimodal continual instruction tuning.arXiv preprint arXiv:2602.01990, 2026
-
[47]
Progressive lora for multimodal continual instruction tuning
Yahan Yu, Duzhen Zhang, Yong Ren, Xuanle Zhao, Xiuyi Chen, and Chenhui Chu. Progressive lora for multimodal continual instruction tuning. InFindings of the Association for Computational Linguistics: ACL 2025, pages 2779–2796, 2025
work page 2025
-
[48]
Fanhu Zeng, Fei Zhu, Haiyang Guo, Xu-Yao Zhang, and Cheng-Lin Liu. Modalprompt: Towards efficient multimodal continual instruction tuning with dual-modality guided prompt. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 12137–12152, 2025
work page 2025
-
[49]
Aimen Zerroug, Mohit Vaishnav, Julien Colin, Sebastian Musslick, and Thomas Serre. A benchmark for compositional visual reasoning.Advances in neural information processing systems, 35:29776–29788, 2022. 12
work page 2022
-
[50]
Investigating the catastrophic forgetting in multimodal large language models
Yuexiang Zhai, Shengbang Tong, Xiao Li, Mu Cai, Qing Qu, Yong Jae Lee, and Yi Ma. Investigating the catastrophic forgetting in multimodal large language models. InNeurIPS 2023 Workshop on Instruction Tuning and Instruction F ollowing, 2023
work page 2023
-
[51]
Mm-llms: Recent advances in multimodal large language models.arXiv preprint arXiv:2401.13601, 2024
Duzhen Zhang, Yahan Yu, Chenxing Li, Jiahua Dong, Dan Su, Chenhui Chu, and Dong Yu. Mm-llms: Recent advances in multimodal large language models.arXiv preprint arXiv:2401.13601, 2024
-
[52]
Instruction tuning for large language models: A survey.ACM Computing Surveys, 58(7):1–36, 2026
Shengyu Zhang, Linfeng Dong, Xiaoya Li, Sen Zhang, Xiaofei Sun, Shuhe Wang, Jiwei Li, Runyi Hu, Tianwei Zhang, Guoyin Wang, et al. Instruction tuning for large language models: A survey.ACM Computing Surveys, 58(7):1–36, 2026
work page 2026
-
[53]
Instruction-Following Evaluation for Large Language Models
Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. Instruction-following evaluation for large language models.arXiv preprint arXiv:2311.07911, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[54]
Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. Learning to prompt for vision-language models.International Journal of Computer Vision, 130(9):2337–2348, 2022. 13 Appendix In this appendix, we provide additional details and supplementary analyses for DRAPE, including evaluation metrics, null-space projection analysis, additional benchmark res...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.