Recognition: 2 theorem links
· Lean TheoremBeyond the Last Layer: Multi-Layer Representation Fusion for Visual Tokenization
Pith reviewed 2026-05-13 07:36 UTC · model grok-4.3
The pith
Fusing features from all layers of a vision encoder recovers attenuated low-level details and improves tokenization quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Representation autoencoders that reuse frozen pretrained vision encoders as visual tokenizers achieve strong results yet discard hierarchical information by extracting only from the last layer. Low-level visual details persist in that final layer only as attenuated residuals. Explicitly fusing multi-layer features through an adaptive module recovers this information and yields an enriched latent that a frozen decoder can exploit, producing better reconstruction and generation.
What carries the argument
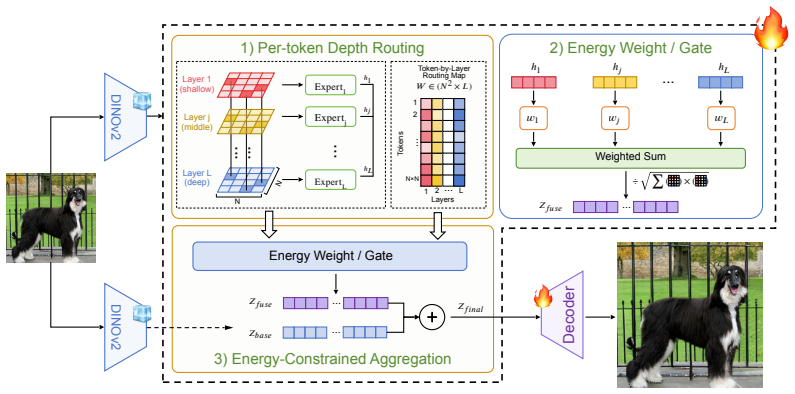
DRoRAE, a lightweight fusion module that adaptively aggregates all encoder layers via energy-constrained routing and incremental correction to produce an enriched latent.
If this is right
- rFID on ImageNet-256 falls from 0.57 to 0.29.
- Generation FID improves from 1.74 to 1.65 under AutoGuidance.
- Quality gains transfer to text-to-image synthesis.
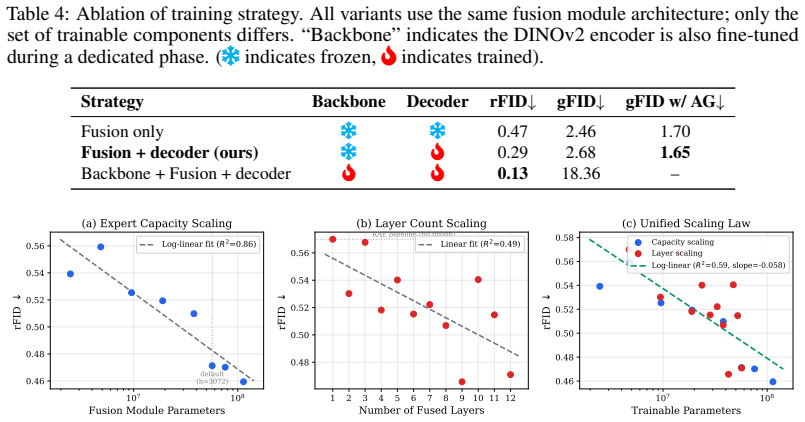
- Reconstruction quality follows a log-linear scaling law with fusion capacity at R² = 0.86.
Where Pith is reading between the lines
- Representation richness emerges as an independent scaling dimension that could be increased separately from model size or training data volume.
- The same layer-fusion pattern may apply to hierarchical encoders in other modalities such as audio or video.
- Decoupled training stages could become routine when adapting frozen components to richer intermediate representations.
Load-bearing premise
The enriched latent from the fusion module remains compatible with a frozen pretrained decoder and the three-phase decoupled training lets the decoder exploit the richer input without new distribution mismatches or instabilities.
What would settle it
Measure reconstruction quality when feeding the enriched latents to the original frozen decoder with no decoder fine-tuning step; if quality fails to improve or degrades, the compatibility claim is false.
Figures







read the original abstract
Representation autoencoders that reuse frozen pretrained vision encoders as visual tokenizers have achieved strong reconstruction and generation quality. However, existing methods universally extract features from only the last encoder layer, discarding the rich hierarchical information distributed across intermediate layers. We show that low-level visual details survive in the last layer merely as attenuated residuals after multiple layers of semantic abstraction, and that explicitly fusing multi-layer features can substantially recover this lost information. We propose DRoRAE (Depth-Routed Representation AutoEncoder), a lightweight fusion module that adaptively aggregates all encoder layers via energy-constrained routing and incremental correction, producing an enriched latent compatible with a frozen pretrained decoder. A three-phase decoupled training strategy first learns the fusion under the implicit distributional constraint of the frozen decoder, then fine-tunes the decoder to fully exploit the enriched representation. On ImageNet-256, DRoRAE reduces rFID from 0.57 to 0.29 and improves generation FID from 1.74 to 1.65 (with AutoGuidance), with gains also transferring to text-to-image synthesis. Furthermore, we uncover a log-linear scaling law ($R^2{=}0.86$) between fusion capacity and reconstruction quality, identifying \textit{representation richness} as a new, predictably scalable dimension for visual tokenizers analogous to vocabulary size in NLP.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DRoRAE, a lightweight depth-routed fusion module that aggregates hierarchical features from all layers of a frozen pretrained vision encoder via energy-constrained routing and incremental correction. It introduces a three-phase decoupled training strategy (fusion learning under frozen decoder constraint, followed by decoder fine-tuning) and reports that this recovers low-level details lost in last-layer extraction, yielding rFID reduction from 0.57 to 0.29 and generation FID improvement from 1.74 to 1.65 on ImageNet-256, plus a log-linear scaling law (R²=0.86) between fusion capacity and reconstruction quality, with gains transferring to text-to-image synthesis.
Significance. If the central claim holds, the work establishes representation richness (via explicit multi-layer fusion) as a new, predictably scalable axis for visual tokenizers, analogous to vocabulary size in language models. The reported scaling law and quantitative gains on both reconstruction and generation metrics would strengthen the case for hierarchical feature exploitation in frozen-encoder autoencoders, provided the enriched latents remain decoder-compatible without requiring full decoder retraining.
major comments (2)
- [§3.2] §3.2 (three-phase training): the central claim that DRoRAE produces an enriched latent 'compatible with a frozen pretrained decoder' is load-bearing, yet all reported metrics (rFID=0.29, FID=1.65) are measured only after phase 3 decoder fine-tuning. No intermediate results (e.g., rFID or latent KL after phase 1 only) are provided to isolate whether gains arise from recovered information or from the decoder adapting to a shifted distribution.
- [§4.1] §4.1 (experimental setup): the abstract and results cite specific improvements over a baseline rFID of 0.57, but the manuscript provides no details on the exact baseline architecture, training hyperparameters, data splits, or whether the baseline also used multi-layer features; this makes the magnitude of the fusion contribution difficult to assess.
minor comments (2)
- [§4.3] The scaling law is presented with R²=0.86 but without the number of data points, confidence intervals, or the precise definition of 'fusion capacity' (e.g., number of parameters or routing dimensions), which should be clarified for reproducibility.
- [Figure 4] Figure captions and axis labels for the scaling plot should explicitly state the range of fusion capacities tested and whether error bars reflect multiple random seeds.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help strengthen the clarity of our training procedure and experimental details. We address each major point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§3.2] §3.2 (three-phase training): the central claim that DRoRAE produces an enriched latent 'compatible with a frozen pretrained decoder' is load-bearing, yet all reported metrics (rFID=0.29, FID=1.65) are measured only after phase 3 decoder fine-tuning. No intermediate results (e.g., rFID or latent KL after phase 1 only) are provided to isolate whether gains arise from recovered information or from the decoder adapting to a shifted distribution.
Authors: We agree that isolating the contribution of the fusion module is important. Phase 1 trains the fusion module with the decoder frozen, so the enriched latent is produced under the distributional constraint of the pretrained decoder by design; phase 3 then allows the decoder to better exploit the richer input. To address the concern directly, we will add phase-1-only metrics (rFID, latent KL divergence) in the revised §3.2 and §4, confirming that the majority of the reconstruction gain is already present before decoder fine-tuning. revision: yes
-
Referee: [§4.1] §4.1 (experimental setup): the abstract and results cite specific improvements over a baseline rFID of 0.57, but the manuscript provides no details on the exact baseline architecture, training hyperparameters, data splits, or whether the baseline also used multi-layer features; this makes the magnitude of the fusion contribution difficult to assess.
Authors: We apologize for the lack of detail. The baseline uses exactly the same pretrained vision encoder and extracts features only from its final layer, with identical data splits, optimizer settings, batch size, and training schedule as DRoRAE; no multi-layer fusion is applied. We will expand §4.1 with a full description of the baseline architecture, a hyperparameter table, and explicit confirmation that the baseline follows the standard last-layer protocol. revision: yes
Circularity Check
No circularity: empirical architecture and metrics
full rationale
The paper advances an architectural proposal (DRoRAE fusion module with energy-constrained routing) trained via a three-phase procedure and evaluates it with direct benchmark metrics (rFID, FID) plus an observed scaling relation (log-linear fit with R²=0.86). No equations or claims reduce the reported gains to fitted parameters or self-citations by construction; the scaling law is presented as an empirical discovery rather than a predictive input. The derivation chain consists of standard model design and decoupled optimization steps whose outputs are measured externally, leaving the central claims independent of any self-referential loop.
Axiom & Free-Parameter Ledger
free parameters (1)
- fusion capacity parameters
axioms (1)
- domain assumption Pretrained vision encoders distribute hierarchical visual information across layers with low-level details surviving as attenuated residuals in the final layer
invented entities (1)
-
DRoRAE fusion module
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearenergy-constrained routing ... zfuse = LN_bb (∑ wk·hk / √(∑ wk² + ϵ)) ... incremental correction zfinal = LN_bb(zbase + β·(zfuse − zbase)) ... log-linear scaling law (R²=0.86) between fusion capacity and reconstruction quality
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanalpha_pin_under_high_calibration unclearthree-phase decoupled training ... Phase 2 freezes both backbone and decoder, training only the fusion module
Reference graph
Works this paper leans on
-
[1]
Deep vit features as dense visual descriptors.arXiv preprint arXiv:2112.05814, 2(3):4, 2021
Shir Amir, Yossi Gandelsman, Shai Bagon, and Tali Dekel. Deep vit features as dense visual descriptors.arXiv preprint arXiv:2112.05814, 2(3):4, 2021
-
[2]
Mmfuser: Multimodal multi-layer feature fuser for fine-grained vision-language understanding
Yue Cao, Yangzhou Liu, Zhe Chen, Guangchen Shi, Wenhai Wang, Danhuai Zhao, and Tong Lu. Mmfuser: Multimodal multi-layer feature fuser for fine-grained vision-language understanding. arXiv preprint arXiv:2410.11829, 2024
-
[3]
Conceptual 12M: Pushing web-scale image-text pre-training to recognize long-tail visual concepts
Soravit Changpinyo, Piyush Sharma, Nan Ding, and Radu Soricut. Conceptual 12M: Pushing web-scale image-text pre-training to recognize long-tail visual concepts. InCVPR, 2021
work page 2021
-
[4]
Multimodal language models see better when they look shallower
Haoran Chen, Junyan Lin, Xinghao Chen, Yue Fan, Jianfeng Dong, Xin Jin, Hui Su, Jinlan Fu, and Xiaoyu Shen. Multimodal language models see better when they look shallower. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors, Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages...
work page 2025
-
[5]
Emerging Properties in Unified Multimodal Pretraining
Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu Wang, Shu Zhong, Weihao Yu, Xiaonan Nie, Ziang Song, et al. Emerging properties in unified multimodal pretraining.arXiv preprint arXiv:2505.14683, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, K. Li, and Li Fei-Fei. Imagenet: A large- scale hierarchical image database.2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 248–255, 2009
work page 2009
-
[7]
Diffusion models beat gans on image synthesis
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis. Advances in neural information processing systems, 34:8780–8794, 2021
work page 2021
-
[8]
Taming transformers for high-resolution image synthesis
Patrick Esser, Robin Rombach, and Bjorn Ommer. Taming transformers for high-resolution image synthesis. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12873–12883, 2021. 11
work page 2021
-
[9]
Dhruba Ghosh, Hannaneh Hajishirzi, and Ludwig Schmidt. Geneval: An object-focused framework for evaluating text-to-image alignment.Advances in Neural Information Processing Systems, 36:52132–52152, 2023
work page 2023
-
[10]
Yue Gong, Hongyu Li, Shanyuan Liu, Bo Cheng, Yuhang Ma, Liebucha Wu, Xiaoyu Wu, Manyuan Zhang, Dawei Leng, Yuhui Yin, et al. Rpiae: A representation-pivoted autoencoder enhancing both image generation and editing.arXiv preprint arXiv:2603.19206, 2026
-
[11]
Hypercolumns for object segmentation and fine-grained localization
Bharath Hariharan, Pablo Arbeláez, Ross Girshick, and Jitendra Malik. Hypercolumns for object segmentation and fine-grained localization. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 447–456, 2015
work page 2015
-
[12]
Hongzhi Huang, Defa Zhu, Banggu Wu, Yutao Zeng, Ya Wang, Qiyang Min, and Xun Zhou. Over-tokenized transformer: V ocabulary is generally worth scaling.arXiv preprint arXiv:2501.16975, 2025
-
[13]
Jing Jin, Hao Liu, Yan Bai, Yihang Lou, Zhenke Wang, Tianrun Yuan, Juntong Chen, Yongkang Zhu, Fanhu Zeng, Xuanyu Zhu, et al. Unveiling fine-grained visual traces: Evaluating multi- modal interleaved reasoning chains in multimodal stem tasks.arXiv preprint arXiv:2604.19697, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[14]
Xu Li, Yi Zheng, Haotian Chen, Xiaolei Chen, Yuxuan Liang, Chenghang Lai, Bin Li, and Xiangyang Xue. Instruction-guided fusion of multi-layer visual features in large vision-language models.Pattern Recognition, 170:111932, 2026
work page 2026
-
[15]
Feature pyramid networks for object detection
Tsung-Yi Lin, Piotr Dollár, Ross Girshick, Kaiming He, Bharath Hariharan, and Serge Belongie. Feature pyramid networks for object detection. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2117–2125, 2017
work page 2017
-
[16]
Sit: Exploring flow and diffusion-based generative models with scalable interpolant transformers
Nanye Ma, Mark Goldstein, Michael S Albergo, Nicholas M Boffi, Eric Vanden-Eijnden, and Saining Xie. Sit: Exploring flow and diffusion-based generative models with scalable interpolant transformers. InEuropean Conference on Computer Vision, pages 23–40. Springer, 2024
work page 2024
-
[17]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
work page 2023
-
[19]
Maithra Raghu, Thomas Unterthiner, Simon Kornblith, Chiyuan Zhang, and Alexey Dosovitskiy. Do vision transformers see like convolutional neural networks?Advances in neural information processing systems, 34:12116–12128, 2021
work page 2021
-
[20]
Vision transformers for dense prediction
René Ranftl, Alexey Bochkovskiy, and Vladlen Koltun. Vision transformers for dense prediction. InProceedings of the IEEE/CVF international conference on computer vision, pages 12179– 12188, 2021
work page 2021
-
[21]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
work page 2022
-
[22]
Yang Shi, Yuhao Dong, Yue Ding, Yuran Wang, Xuanyu Zhu, Sheng Zhou, Wenting Liu, Haochen Tian, Rundong Wang, Huanqian Wang, et al. Realunify: Do unified models truly benefit from unification? a comprehensive benchmark.arXiv preprint arXiv:2509.24897, 2025
-
[23]
Mavors: Multi-granularity video representation for multimodal large language model
Yang Shi, Jiaheng Liu, Yushuo Guan, Zhenhua Wu, Yuanxing Zhang, Zihao Wang, Weihong Lin, Jingyun Hua, Zekun Wang, Xinlong Chen, et al. Mavors: Multi-granularity video representation for multimodal large language model. InProceedings of the 33rd ACM International Conference on Multimedia, pages 10994–11003, 2025
work page 2025
-
[24]
Yang Shi, Huanqian Wang, Xie Xie, Huanyao Zhang, Lijie Zhao, Xinfeng Li, Chaoyou Fu, Zhuoer Wen, Wenting Liu, Zhuoran Zhang, et al. Mme-videoocr: Evaluating ocr-based capabilities of multimodal llms in video scenarios.Advances in Neural Information Processing Systems, 38, 2026. 12
work page 2026
-
[25]
Longcat-next: Lexicalizing modalities as discrete tokens.arXiv preprint arXiv:2603.27538, 2026
Meituan LongCat Team, Bin Xiao, Chao Wang, Chengjiang Li, Chi Zhang, Chong Peng, Hang Yu, Hao Yang, Haonan Yan, Haoze Sun, et al. Longcat-next: Lexicalizing modalities as discrete tokens.arXiv preprint arXiv:2603.27538, 2026
-
[26]
Qixun Wang, Yang Shi, Yifei Wang, Yuanxing Zhang, Pengfei Wan, Kun Gai, Xianghua Ying, and Yisen Wang. Monet: Reasoning in latent visual space beyond images and language.arXiv preprint arXiv:2511.21395, 2025
-
[27]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Huanjin Yao, Wenhao Wu, Taojiannan Yang, YuXin Song, Mengxi Zhang, Haocheng Feng, Yifan Sun, Zhiheng Li, Wanli Ouyang, and Jingdong Wang. Dense connector for mllms. Advances in Neural Information Processing Systems, 37:33108–33140, 2024
work page 2024
-
[29]
Jingfeng Yao, Bin Yang, and Xinggang Wang. Reconstruction vs. generation: Taming opti- mization dilemma in latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
work page 2025
-
[30]
Representation alignment for generation: Training diffusion transformers is easier than you think
Sihyun Yu, Sangkyung Kwak, Huiwon Jang, Jongheon Jeong, Jonathan Huang, Jinwoo Shin, and Saining Xie. Representation alignment for generation: Training diffusion transformers is easier than you think. InInternational Conference on Learning Representations, 2025
work page 2025
-
[31]
The unrea- sonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unrea- sonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595, 2018
work page 2018
-
[32]
Debiasing multimodal large language models via penalization of language priors
YiFan Zhang, Yang Shi, Weichen Yu, Qingsong Wen, Xue Wang, Wenjing Yang, Zhang Zhang, Liang Wang, and Rong Jin. Debiasing multimodal large language models via penalization of language priors. InProceedings of the 33rd ACM International Conference on Multimedia, pages 4232–4241, 2025
work page 2025
-
[33]
Diffusion Transformers with Representation Autoencoders
Boyang Zheng, Nanye Ma, Shengbang Tong, and Saining Xie. Diffusion transformers with representation autoencoders.arXiv preprint arXiv:2510.11690, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Xuanyu Zhu, Yuhao Dong, Rundong Wang, Yang Shi, Zhipeng Wu, Yinlun Peng, YiFan Zhang, Yihang Lou, Yuanxing Zhang, Ziwei Liu, et al. Vtc-bench: Evaluating agentic multimodal models via compositional visual tool chaining.arXiv preprint arXiv:2603.15030, 2026. 13 A Training Details This section provides full implementation details for the DRoRAE tokenizer an...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.