Recognition: no theorem link
Unveiling Fine-Grained Visual Traces: Evaluating Multimodal Interleaved Reasoning Chains in Multimodal STEM Tasks
Pith reviewed 2026-05-11 01:49 UTC · model grok-4.3
The pith
Multimodal models reach just 38% on new visual STEM benchmark
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that current MLLMs still rely heavily on textual reasoning in STEM tasks, achieving only 38.29% accuracy on StepSTEM even for top models, because the benchmark enforces strict complementarity between textual and visual inputs through its curation pipeline and measures interleaved reasoning at the step level via dynamic programming alignment.
What carries the argument
The StepSTEM benchmark, built via a rigorous curation pipeline that enforces strict textual-visual complementarity, together with the dynamic programming framework for aligning predicted reasoning steps against multiple references in both text-only and interleaved image-text chains.
If this is right
- Text-only chain-of-thought methods fall short when visual details are required for verification in STEM.
- Step-level metrics diagnose integration failures more precisely than final-answer accuracy alone.
- Existing benchmarks likely overestimate multimodal capabilities due to modality redundancy.
- StepSTEM provides a concrete testbed to track genuine progress in cross-modal STEM reasoning.
Where Pith is reading between the lines
- Training data for MLLMs may require more examples where visual information resolves textual ambiguities.
- The complementarity requirement could extend to other domains such as medical imaging or legal evidence analysis.
- Current scaling approaches may not close the gap without targeted curation of visually necessary problems.
Load-bearing premise
The assumption that the curation pipeline successfully creates problems where visual inputs are indispensable and no unimodal text-only shortcut is possible.
What would settle it
A model achieving markedly higher accuracy on StepSTEM by demonstrably incorporating essential visual information into its step-by-step reasoning would indicate that heavy textual reliance is not universal.
Figures



read the original abstract
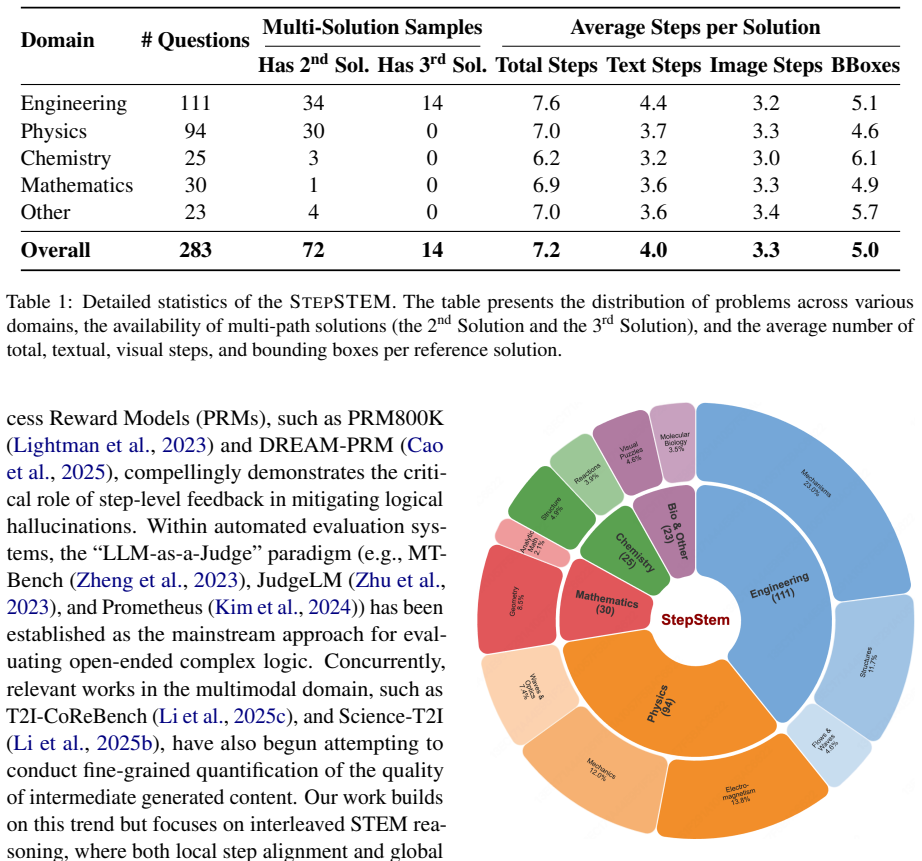
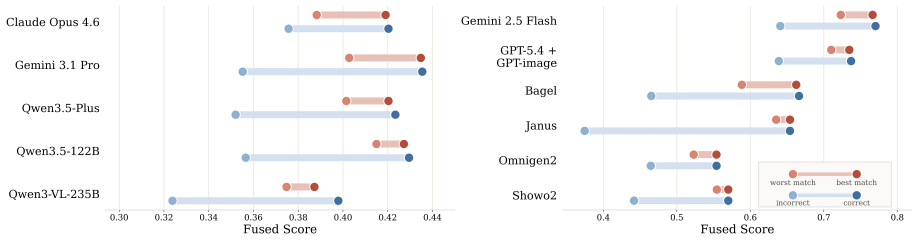
Multimodal large language models (MLLMs) have shown promising reasoning abilities, yet evaluating their performance in specialized domains remains challenging. STEM reasoning is a particularly valuable testbed because it provides highly verifiable feedback, but existing benchmarks often permit unimodal shortcuts due to modality redundancy and focus mainly on final-answer accuracy, overlooking the reasoning process itself. To address this challenge, we introduce StepSTEM: a graduate-level benchmark of 283 problems across mathematics, physics, chemistry, biology, and engineering for fine-grained evaluation of cross-modal reasoning in MLLMs. StepSTEM is constructed through a rigorous curation pipeline that enforces strict complementarity between textual and visual inputs. We further propose a general step-level evaluation framework for both text-only chain-of-thought and interleaved image-text reasoning, using dynamic programming to align predicted reasoning steps with multiple reference solutions. Experiments across a wide range of models show that current MLLMs still rely heavily on textual reasoning, with even Gemini 3.1 Pro and Claude Opus 4.6 achieving only 38.29% accuracy. These results highlight substantial headroom for genuine cross-modal STEM reasoning and position StepSTEM as a benchmark for fine-grained evaluation of multimodal reasoning. Source code is available at https://github.com/lll-hhh/STEPSTEM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces StepSTEM, a benchmark of 283 graduate-level problems in mathematics, physics, chemistry, biology, and engineering, constructed via a curation pipeline that enforces strict complementarity between text and images to prevent unimodal shortcuts. It proposes a step-level evaluation framework that uses dynamic programming to align predicted interleaved reasoning chains against multiple reference solutions, and reports experimental results showing that even top MLLMs (Gemini 3.1 Pro, Claude Opus 4.6) reach only 38.29% accuracy, interpreted as evidence that current models rely heavily on textual reasoning with substantial headroom for genuine cross-modal STEM reasoning.
Significance. If the curation successfully eliminates text-only solutions, the benchmark and its step-level DP alignment framework would provide a valuable, verifiable testbed for fine-grained multimodal reasoning evaluation beyond final-answer metrics. The public code release supports reproducibility and enables follow-up work on interleaved chains.
major comments (2)
- [§3 (Benchmark Construction)] §3 (Benchmark Construction / Curation Pipeline): The manuscript states that the pipeline 'enforces strict complementarity between textual and visual inputs' but provides no description of concrete mechanisms such as automated text-only solvability checks, redundancy detection procedures, or any reported text-only LLM baselines on the 283 problems. Without these, the headline accuracies cannot be unambiguously attributed to failure at cross-modal reasoning rather than overall problem difficulty.
- [§5 (Experiments)] §5 (Experiments): No ablation is presented that measures performance drop when images are removed from the inputs, nor is there a quantitative error analysis breaking down failures into visual-interpretation errors versus textual-reasoning errors. Such data are load-bearing for the claim that models 'still rely heavily on textual reasoning.'
minor comments (2)
- [Abstract and §5] Model names in the abstract and results ('Gemini 3.1 Pro', 'Claude Opus 4.6') appear non-standard; confirm exact versions and include parameter counts or release dates for reproducibility.
- [§4 (Evaluation Framework)] The dynamic-programming alignment procedure is described at a high level; adding pseudocode, alignment cost function, and handling of multiple reference solutions would improve clarity of the evaluation framework.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We have revised the manuscript to address the concerns about benchmark construction details and experimental analyses. Our point-by-point responses follow.
read point-by-point responses
-
Referee: [§3 (Benchmark Construction)] The manuscript states that the pipeline 'enforces strict complementarity between textual and visual inputs' but provides no description of concrete mechanisms such as automated text-only solvability checks, redundancy detection procedures, or any reported text-only LLM baselines on the 283 problems. Without these, the headline accuracies cannot be unambiguously attributed to failure at cross-modal reasoning rather than overall problem difficulty.
Authors: We agree that more explicit details on the curation mechanisms are needed to substantiate the complementarity claim. In the revised manuscript, we have substantially expanded Section 3 to describe the concrete procedures: automated text-only solvability checks (using LLMs to attempt solving each problem from text alone and retaining only those with low text-only success), redundancy detection via embedding-based overlap analysis between text and image content, and text-only LLM baselines now reported for the full 283 problems. These additions demonstrate that the benchmark requires cross-modal reasoning and allow the headline results to be interpreted accordingly. revision: yes
-
Referee: [§5 (Experiments)] No ablation is presented that measures performance drop when images are removed from the inputs, nor is there a quantitative error analysis breaking down failures into visual-interpretation errors versus textual-reasoning errors. Such data are load-bearing for the claim that models 'still rely heavily on textual reasoning.'
Authors: We acknowledge that these analyses are important for supporting the interpretation of model behavior. In the revised Section 5, we have added an ablation evaluating all models on text-only inputs (images removed), which shows a clear performance drop relative to the full multimodal setting. We have also added a quantitative error analysis on a sampled set of failures, with manual categorization into visual-interpretation errors versus textual-reasoning errors (including inter-annotator agreement). These revisions provide direct evidence for the claim that current models rely heavily on textual reasoning while still facing multimodal integration challenges. revision: yes
Circularity Check
Empirical benchmark construction with no derivational circularity
full rationale
The paper introduces the StepSTEM benchmark of 283 problems and evaluates MLLMs on interleaved reasoning using a step-level alignment framework based on dynamic programming. No mathematical derivations, equations, or predictions are claimed that reduce to the paper's own inputs by construction. The curation pipeline is presented as a methodological process to enforce complementarity, but this is an empirical construction step rather than a self-referential derivation. Model accuracy results (e.g., 38.29%) are direct measurements on the benchmark, not outputs forced by fitted parameters or self-citations. This is self-contained empirical work with no load-bearing steps matching the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The curation pipeline enforces strict complementarity between textual and visual inputs.
Forward citations
Cited by 2 Pith papers
-
Beyond the Last Layer: Multi-Layer Representation Fusion for Visual Tokenization
DRoRAE fuses multi-layer features from pretrained vision encoders to recover lost low-level details, reducing rFID from 0.57 to 0.29 and generation FID from 1.74 to 1.65 on ImageNet-256.
-
Beyond the Last Layer: Multi-Layer Representation Fusion for Visual Tokenization
DRoRAE adaptively fuses multi-layer features from vision encoders via energy-constrained routing to enrich visual tokens, cutting rFID from 0.57 to 0.29 and generation FID from 1.74 to 1.65 on ImageNet-256 while revea...
Reference graph
Works this paper leans on
-
[1]
Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
Janus-pro: Unified multimodal understanding and generation with data and model scaling.arXiv preprint arXiv:2501.17811. Ethan Chern, Zhulin Hu, Steffi Chern, Siqi Kou, Jiadi Su, Yan Ma, Zhijie Deng, and Pengfei Liu. 2025. Thinking with generated images.arXiv preprint arXiv:2505.22525. Yufeng Cui, Honghao Chen, Haoge Deng, Xu Huang, Xinghang Li, Jirong Liu...
work page internal anchor Pith review arXiv 2025
-
[2]
InThe twelfth inter- national conference on learning representations
Let’s verify step by step. InThe twelfth inter- national conference on learning representations. Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harri- son Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe
-
[3]
MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts
Let’s verify step by step. InThe Twelfth In- ternational Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. Open- Review.net. Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chun- yuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai- Wei Chang, Michel Galley, and Jianfeng Gao. 2023. Mathvista: Evaluating mathematical reasoning of f...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Show-o2: Improved Native Unified Multimodal Models
Show-o2: Improved native unified multimodal models.arXiv preprint arXiv:2506.15564. Guanyu Yao, Qiucheng Wu, Yang Zhang, Zhaowen Wang, Handong Zhao, and Shiyu Chang. 2025. Rethinking the text-vision reasoning imbalance in mllms through the lens of training recipes.arXiv preprint arXiv:2510.22836. Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu...
work page internal anchor Pith review arXiv 2025
-
[5]
Looking beyond text: Reducing language bias in large vision-language models via multimodal dual- attention and soft-image guidance. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, EMNLP 2025, Suzhou, China, November 4-9, 2025, pages 19666–19690. Association for Computational Linguistics. Lianmin Zheng, Wei-Lin Chi...
work page 2025
-
[6]
Judgelm: Fine-tuned large language models are scalable judges,
Judgelm: Fine-tuned large language models are scalable judges.arXiv preprint arXiv:2310.17631. Xuanyu Zhu, Yuhao Dong, Rundong Wang, Yang Shi, Zhipeng Wu, Yinlun Peng, YiFan Zhang, Yihang Lou, Yuanxing Zhang, Ziwei Liu, et al. 2026. Vtc- bench: Evaluating agentic multimodal models via compositional visual tool chaining.arXiv preprint arXiv:2603.15030. Kai...
-
[7]
The diversity penalty hyperparame- terλis set to0.2
encoder. The diversity penalty hyperparame- terλis set to0.2. A.3 Global Judge and Metric Fusion The LLM-based global judge for assessing whole- trace coverage is also powered by Qwen3.5-9B. To ensure stable and deterministic judgments, we con- figure it with a temperature of 0.0, a top-p of 1.0, and a maximum token length of 512. In the calcu- lation of ...
work page 2026
-
[8]
A leading commercial multimodal model from Google designed with native capabilities to seamlessly process and generate both textual and visual outputs within a unified inference process. B.2 Open-Source Unified / Interleaved Generation Models Janus-Pro(Chen et al., 2025) An advanced open-source model designed for unified multi- modal understanding and gen...
work page 2025
-
[9]
A powerful series of models developed by the Qwen team. While possessing strong foun- dational language and vision-language understand- ing, they are fundamentally constrained to text-only generation and rely purely on textual or symbolic reasoning. C Detailed Experimental Results on Each Specific Domain Tables 4 – 8 present the detailed results on the En...
-
[10]
Please answer by strictly following these instructions: [Task Requirements]
INTERLEA VED_QUERY_PREFIX You will be given a problem. Please answer by strictly following these instructions: [Task Requirements]
-
[11]
Carefully understand the problem first, then provide a complete step-by-step solution
-
[12]
The solution process must use an "interleaved text-and-visual"format: - For each key step, first explain the reasoning in text. - Then provide a "visual illustration" block to support that step. - Each "Visual Illustration" must be an actual image output generated by the model. It must not be replaced by ASCII art, tables, plain text diagrams, flowcharts ...
-
[13]
At the end, provide the final answer separately, and it must be strictly wrapped in: <final_answer>final answer</final_answer>
-
[14]
Do not put any extra explanation inside the`<final_answer>`tag other than the final answer itself
-
[15]
Any requirement in the problem statement about the form of the final submitted answer applies only to the final answer itself, not to the reasoning process before it
-
[16]
Any answer-format requirement in the problem statement constrains only the content inside`< final_answer>...</final_answer>'. It does not constrain the length, level of detail, or structure of the reasoning before it. [Required Output Format] - Use the following structure: Problem Understanding Textual Reasoning Visual Illustration Textual Reasoning Visua...
-
[17]
Please solve it through a genuinely interleaved text-and-image reasoning process
TOOL_INTERLEA VED_PROMPT You are solving a multimodal problem. Please solve it through a genuinely interleaved text-and-image reasoning process. Your goal is not to finish as quickly as possible, but to use generated images as part of the reasoning itself. Follow these principles:
-
[18]
Produce at least one text reasoning segment
-
[19]
Generate multiple genuinely helpful images and distribute them throughout the reasoning process
-
[20]
Text and images must be interleaved: - do not write a long stretch of text first and then dump several images at the end; - do not generate multiple images in a row without new reasoning progress between them
-
[21]
The process should look like: reasoning -> helpful image -> further reasoning from that image -> another helpful image -> further reasoning
-
[22]
Every image must directly support reasoning rather than decoration. It may help with: - understanding the setup - marking key objects - highlighting relevant regions - clarifying structural relations - redrawing a schematic more clearly - showing an intermediate analytical result
-
[23]
Each image must advance the later reasoning, rather than merely repeat earlier content or serve as a presentation illustration
-
[24]
Before generating an image, explain what is still uncertain, what the image is meant to clarify, and why it is useful
-
[25]
After an image is generated, read it carefully and continue reasoning from what it clarifies
-
[26]
Do not give only a one-line conclusion
The reasoning must be sufficiently detailed and clear. Do not give only a one-line conclusion
-
[27]
Do not generate images that merely paste large amounts of text on the canvas. Images must provide genuinely useful visual information such as schematics, structural relations, arrows, axes, regions, force directions, connections, or key labels
-
[28]
It does not constrain the length, level of detail, or structure of the reasoning before it
Any answer-format requirement in the problem statement constrains only the final answer itself. It does not constrain the length, level of detail, or structure of the reasoning before it
- [29]
-
[30]
Before the final answer, provide at least one substantive reasoning block even for easy problems
A bare short answer string by itself is not a valid reasoning process. Before the final answer, provide at least one substantive reasoning block even for easy problems
-
[31]
If the problem includes an image, do not end immediately with only a short final answer unless the reasoning has already been explained in a substantive text block
-
[32]
Only give the final answer when you believe the conclusion is stable
-
[33]
For text-answer problems, the final answer must appear in the final text portion and must end with exactly one <final_answer>...</final_answer> block
-
[34]
Do not output any text after the final answer tag
-
[35]
If the required final answer is itself an image, structure, diagram, conformation, or drawing, then the last generated image should be the answer image itself rather than merely an auxiliary illustration
-
[36]
Even when the final answer is an image, provide at least one substantive text block before the answer image explaining what is being drawn, what key structure or relation it must show, and why it is the correct final answer
-
[37]
The final answer should be realized as the last generated image itself
For such drawing problems, do not replace the answer image with markdown image syntax, SVG code, a data URI, an attachment placeholder, or any other text surrogate. The final answer should be realized as the last generated image itself
-
[38]
Unless the problem is truly trivial, do not finish before using multiple helpful generated images to advance the reasoning
-
[39]
Final-answer Judge Prompts You are a strict and careful judge for final-answer equivalence. Your only job is to decide whether the predicted final answer is truly semantically identical to one acceptable ground -truth answer. Be conservative: when a difference may change the meaning, treat it as not equivalent. You are judging final-answer equivalence. Ta...
-
[40]
Focus on final-answer equivalence only
-
[41]
Ignore harmless formatting differences only: punctuation, whitespace, LaTeX wrappers, capitalization, surrounding filler words, and standard algebraic rewrites
-
[42]
Give credit for mathematically equivalent expressions only when they are fully equivalent, with the same variables, same constraints, same set of solutions, same sign, same units, and same boundaries
-
[43]
Do not give credit when any meaningful content changes, including: - different numeric value or approximation that is not clearly intended as the same value - different sign, inequality direction, interval boundary, ordering, or logical relation - different variable, symbol, label, object identity, or named entity - different chemical structure, substitue...
-
[44]
For structured answers with multiple items, all items must align correctly. A reordering is acceptable only if the answer is explicitly unordered and every item still matches exactly. If labels or item-to-item correspondences change, return 0
-
[45]
Two answers in the same domain are still wrong if any key term or component differs
Do not infer correctness from topic similarity. Two answers in the same domain are still wrong if any key term or component differs
-
[46]
Do not use it to invent a better final answer than the extracted one
Use the candidate response tail only as supporting context when the extracted predicted final answer is awkwardly formatted. Do not use it to invent a better final answer than the extracted one
-
[47]
If the predicted answer is empty, image-only, placeholder-like, or lacks enough information to verify exact equivalence, return 0
-
[48]
Output exactly one block between <judge_result> and </judge_result>
-
[49]
Inside the block output a single JSON object with fields: "verdict": 0 or 1 "matched_gt_index": integer index starting from 1, or 0 if none "reason": short string Checklist before returning 1: - Same objects or entities? - Same mapping between labels and items? - Same mathematical meaning, not just similar form? - No missing or extra components? If any an...
-
[50]
Whole-trace Judge Prompts You are a generous, evidence-based judge for reasoning-process coverage. Task: Given the original problem, a candidate model's whole reply, and a list of reference contents, determine for each reference content whether the candidate reply semantically covers it. Core principle: Your goal is to judge semantic entailment and covera...
-
[51]
Match against the entire candidate reply, not only the final answer
-
[52]
Mark 1 if the candidate reply explicitly states the reference content, clearly paraphrases it, or provides enough mathematical or semantic evidence that entails it
-
[53]
Mark 1 if the candidate reply gives an algebraically equivalent formula, an equivalent constraint, an equivalent domain statement, or a stronger statement that clearly subsumes the reference
-
[54]
Mark 1 if the evidence is distributed across multiple nearby or logically connected sentences or equations, as long as together they support the reference content
-
[55]
Mark 1 if a later derivation, equation, or final expression clearly implies the reference content, even if the intermediate wording is omitted
-
[56]
Mark 1 if the candidate reply reaches the same local conclusion or a directly equivalent stronger conclusion by a different but valid derivation path
-
[57]
Do not require the same wording, the same notation, the same variable names, the same derivation order, or the same decomposition granularity as the reference
-
[58]
Ignore harmless differences in formatting, equation rearrangement, symbol renaming, simplification, factorization, unit style, and equivalent notation
-
[59]
If the candidate reply states a more concrete result that logically contains the reference idea, count the reference as covered
-
[60]
Use a generous semantic matching standard for correct or near-correct reasoning traces; do not demand verbatim intermediate steps
-
[61]
If the candidate reply provides the correct equation, invariant, constraint, ranking, or final symbolic result from which the reference naturally follows, count it as covered even when the explicit wording differs
-
[62]
Mark 0 only if the reference content is truly missing, too vague to verify, merely topically related, or contradicted by the candidate reply
-
[63]
Do not give 1 for generic topic overlap without concrete supporting evidence
-
[64]
Output format: - Output exactly one block between <judge_result> and </judge_result>
When uncertain between 0 and 1, prefer 1 if there is plausible mathematical or semantic evidence in the candidate reply. Output format: - Output exactly one block between <judge_result> and </judge_result>. - Inside the block, output one line per reference in the format step_id=0 or step_id=1. - Do not output explanations. Problem: {question_text} Candida...
-
[65]
Consider both the reference text and the important GT image regions
-
[66]
Mark 1 only if at least one candidate generated image semantically matches the GT visual evidence
-
[67]
If the candidate has no relevant generated image evidence, mark 0
Pure text alone is not sufficient for image coverage. If the candidate has no relevant generated image evidence, mark 0
-
[68]
Mark 1 if the candidate image evidence plus the candidate reply together capture the same visual idea, relation, geometry, highlight, or conclusion as the GT reference
-
[69]
Mark 0 if the relevant visual evidence is missing from the candidate image panels, contradicted, or too vague to verify
-
[70]
Do not count it as candidate evidence
The question image, if provided, is context only. Do not count it as candidate evidence
-
[71]
Output format: - Output exactly one block between <judge_result> and </judge_result>
When uncertain between 0 and 1, prefer 0 unless there is visible evidence in the candidate image panels. Output format: - Output exactly one block between <judge_result> and </judge_result>. - Inside the block, output exactly one line in the format {step_id}=0 or {step_id}=1. - Do not output explanations. Problem: {question_text} Candidate whole reply: {r...
-
[72]
Score Text-Matching Prompt You are a strict grader. Your goal is to determine whether the Predicted reasoning step between <predicted> and </ predicted> semantically contains the Reference key point between <reference> and </ reference>. Judging procedure:
-
[73]
Identify the essential propositions in the Reference key point
-
[74]
Check whether each essential proposition is present in the Predicted reasoning step, allowing paraphrase
-
[75]
If all essential propositions are covered and there is no contradiction, output 1
-
[76]
Rules: - Paraphrase counts as match
Otherwise output 0. Rules: - Paraphrase counts as match. - Missing any essential proposition => 0. - Contradiction => 0. - Mere topic similarity => 0. - Extra correct information is acceptable. - Exactly same => 1. - Same information => 1. Reference key point: <reference>{ref}</reference> Predicted reasoning step: <predicted>
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.