Recognition: 2 theorem links
· Lean TheoremFactual recall in linear associative memories: sharp asymptotics and mechanistic insights
Pith reviewed 2026-05-12 04:09 UTC · model grok-4.3
The pith
Linear associative memories store up to p log p ≈ d²/2 associations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
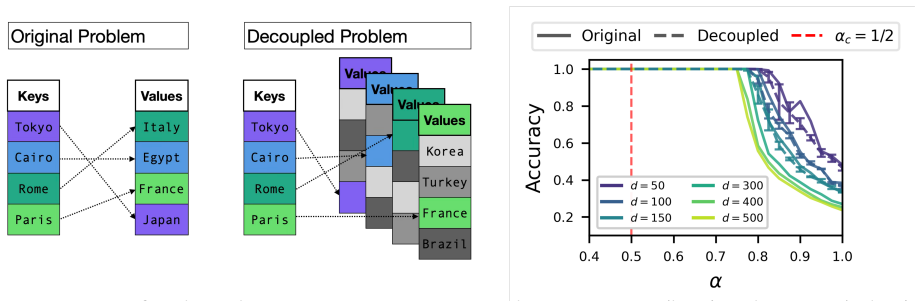
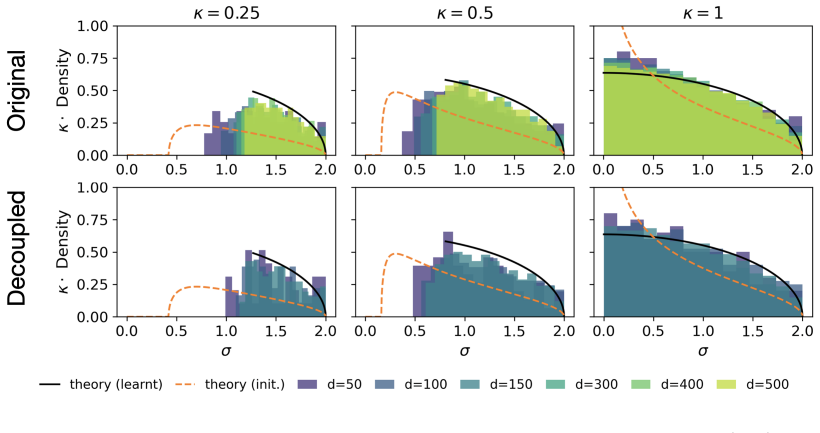
In the decoupled model each input has its own independent set of competing outputs. Statistical physics then shows that the maximum number of storable associations satisfies p log p / d² = 1/2. Numerical and analytical checks indicate this decoupled model reproduces the storage capacity, weight spectra, and learning mechanism of the original linear associative memory. The optimal solution raises the correct output score just above the extreme-value threshold of the competing outputs rather than using broad fluctuations as in Hebbian learning. The calculation of the constant p_c generalizes directly to linear two-layer architectures.
What carries the argument
The decoupled model, in which each input is paired with an independent set of competing targets, allowing separate treatment of the p constraints per association.
If this is right
- The storage capacity scales asymptotically as p ≈ d² / (2 log p).
- Optimal learning raises correct scores just above the extreme-value threshold of competitors rather than boosting alignments with broad fluctuations.
- The same capacity calculation applies to linear two-layer networks.
- The decoupled construction supplies a baseline for capacity in deeper or nonlinear networks.
Where Pith is reading between the lines
- The same extreme-value threshold mechanism may appear in the output layers of trained transformers when factual recall is examined.
- Decoupling competing outputs could simplify capacity bounds for nonlinear activation functions.
- Weight matrices of trained linear models can be checked for the predicted threshold-raising pattern rather than uniform Hebbian scaling.
Load-bearing premise
The decoupled model is equivalent to the original associative memory in capacity, weight spectra, and storage mechanism.
What would settle it
A simulation for large d in which the measured ratio p log p / d² in the original model deviates from 1/2 while the decoupled model stays at 1/2 would falsify the claimed equivalence.
Figures


read the original abstract
Large language models demonstrate remarkable ability in factual recall, yet the fundamental limits of storing and retrieving input--output associations with neural networks remain unclear. We study these limits in a minimal setting: a linear associative memory that maps $p$ input embeddings in $\mathbb{R}^d$ to their corresponding~$d$-dimensional targets via a single layer, requiring each mapped input to be well separated from all other targets. Unlike in supervised classification, this strict separation induces~$p$ constraints per association and produces strong correlations between constraints that make a direct characterisation of the storage capacity difficult. Here, we provide a precise characterisation of this capacity in the following way. We first introduce a decoupled model in which each input has its own independent set of competing outputs, and provide numerical and analytical evidence that this decoupled model is equivalent to the original model in terms of storage capacity, spectra of the learnt weights, and storage mechanism. Using tools from statistical physics, we show that the decoupled model can store up to $p_c \log p_c / d^2 = 1 / 2$ associations, and generalise the computation of $p_c$ to linear two-layer architectures. Our analysis also gives mechanistic insight into how the optimal solution improves over a na\"ive Hebbian learning rule: rather than boosting input-output alignments with broad fluctuations, the optimal solution raises the correct scores just above the extreme-value threshold set by the competing outputs. These findings give a sharp statistical-physics characterisation of factual storage in linear networks and provide a baseline for understanding the memory capacity of more realistic neural architectures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that a decoupled model for linear associative memories (mapping p inputs in R^d to d-dimensional targets with strict separation) is equivalent to the original model in storage capacity, weight spectra, and mechanism, based on numerical and analytical evidence. It then applies statistical-physics tools to the decoupled model to derive the sharp capacity p_c log p_c / d^2 = 1/2 and generalizes the computation of p_c to linear two-layer architectures, while providing mechanistic insight that optimal solutions raise correct scores just above the extreme-value threshold of competitors (unlike naive Hebbian rules).
Significance. If the equivalence holds rigorously in the p, d → ∞ limit with p/d^2 fixed, the work supplies a precise statistical-physics characterization of factual-recall capacity in linear networks and a mechanistic baseline for more complex architectures. The derivation of sharp asymptotics via stat-phys methods and the explicit comparison to Hebbian learning are strengths that would be valuable if the central transfer of results is justified.
major comments (2)
- [Abstract] Abstract: The equivalence of the decoupled model to the original (in capacity, spectra, and mechanism) is supported only by 'numerical and analytical evidence.' The headline capacity p_c log p_c / d^2 = 1/2 is obtained exclusively on the decoupled model; without a rigorous demonstration that the constraint distributions or partition functions converge in the relevant scaling limit (e.g., via total-variation bounds or coupling), the exact constant 1/2 does not necessarily transfer to the original associative memory.
- [Section introducing the decoupled model] Section introducing the decoupled model and equivalence evidence: The paper asserts equivalence on the basis of evidence whose independence and scaling-regime validity are not detailed. If this evidence is only finite-size or approximate, the mechanistic claim that 'the optimal solution raises the correct scores just above the extreme-value threshold' and the generalization of p_c to two-layer nets cannot be taken as applying to the original model.
minor comments (1)
- [Abstract] Abstract: The escaped character in 'naïve' should be rendered as 'naive' for consistency with standard LaTeX.
Simulated Author's Rebuttal
We thank the referee for their thorough review and valuable feedback on our manuscript. We address the concerns regarding the rigor of the equivalence between the original and decoupled models in our point-by-point responses below. While we maintain that the numerical and analytical evidence strongly supports the equivalence in the relevant scaling limits, we agree that additional clarifications will improve the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: The equivalence of the decoupled model to the original (in capacity, spectra, and mechanism) is supported only by 'numerical and analytical evidence.' The headline capacity p_c log p_c / d^2 = 1/2 is obtained exclusively on the decoupled model; without a rigorous demonstration that the constraint distributions or partition functions converge in the relevant scaling limit (e.g., via total-variation bounds or coupling), the exact constant 1/2 does not necessarily transfer to the original associative memory.
Authors: We appreciate this point and acknowledge that our demonstration of equivalence relies on numerical simulations across a range of system sizes and analytical arguments showing matching statistics in the large-d limit, rather than a fully rigorous proof of convergence (such as total-variation bounds on the constraint distributions). The analytical evidence includes showing that the partition functions and effective constraint distributions become equivalent under the scaling p ~ d^2 log d. However, a complete rigorous transfer is indeed not provided. In the revised manuscript, we will modify the abstract and relevant sections to more precisely state that the sharp asymptotic capacity is derived for the decoupled model, with the original model expected to share the same capacity based on the supporting evidence. We will also include a new paragraph discussing the limitations and the strength of the evidence for equivalence. revision: partial
-
Referee: [Section introducing the decoupled model] Section introducing the decoupled model and equivalence evidence: The paper asserts equivalence on the basis of evidence whose independence and scaling-regime validity are not detailed. If this evidence is only finite-size or approximate, the mechanistic claim that 'the optimal solution raises the correct scores just above the extreme-value threshold' and the generalization of p_c to two-layer nets cannot be taken as applying to the original model.
Authors: We agree that the section could benefit from more explicit details on the independence of the constraints in the decoupled model and the scaling regime. The evidence includes both finite-size numerics showing convergence as d increases (with p/d^2 fixed) and analytical calculations demonstrating that the weight spectra and optimization mechanisms match. The mechanistic insight is derived from the decoupled model but supported by matching behavior in the original. To address this, we will expand the section with additional details on the scaling validity, including plots of capacity convergence with system size, and clarify that while the claims are for the decoupled model, the equivalence evidence justifies applying the insights to the original. This revision will make the applicability clearer. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper derives the capacity result p_c log p_c / d^2 = 1/2 exclusively for the decoupled model via standard statistical-physics analysis. Equivalence to the original model (in capacity, spectra, and mechanism) is asserted separately on the basis of numerical simulations and analytical arguments, which are presented as independent supporting evidence rather than a definitional reduction or self-referential fit. No load-bearing step reduces by construction to its own inputs, no self-citation chain is invoked for uniqueness or ansatz, and no known result is merely renamed. The derivation remains self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Replica-symmetric or mean-field assumptions typical of statistical-physics analysis of high-dimensional systems
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe first introduce a decoupled model ... Using tools from statistical physics, we show that the decoupled model can store up to p_c log p_c / d² = 1/2 associations
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearreplica-symmetric assumption ... φ_d := d^{-2} E log V_DP(E,U)
Reference graph
Works this paper leans on
-
[1]
Petroni, F.et al. Language Models as Knowledge Bases?inProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP)(eds Inui, K., Jiang, J., Ng, V. & Wan, X.) (Association for Computational Linguistics, Hong Kong, China, Nov. 2019), 2463–2473...
work page 2019
-
[2]
Geva, M., Schuster, R., Berant, J. & Levy, O.Transformer feed-forward layers are key-value memories inProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing(2021), 5484–5495 (cit. on p. 1)
work page 2021
-
[3]
Meng, K., Bau, D., Andonian, A. & Belinkov, Y. Locating and editing factual associations in gpt. Advances in neural information processing systems35,17359–17372 (2022) (cit. on p. 1)
work page 2022
-
[4]
Roberts, A., Raffel, C. & Shazeer, N.How Much Knowledge Can You Pack Into the Parameters of a Language Model?inProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)(eds Webber, B., Cohn, T., He, Y. & Liu, Y.) (Association for Computational Linguistics, Online, Nov. 2020), 5418–5426 (cit. on p. 1)
work page 2020
-
[5]
Allen-Zhu, Z. & Li, Y.Physics of Language Models: Part 3.3, Knowledge Capacity Scaling Lawsin International Conference on Learning Representations(eds Yue, Y., Garg, A., Peng, N., Sha, F. & Yu, R.) 2025(2025), 14937–14946 (cit. on p. 1)
work page 2025
-
[6]
Cabannes, V., Dohmatob, E. & Bietti, A.Scaling Laws for Associative MemoriesinInternational Conference on Learning Representations(eds Kim, B.et al.)2024(2024), 9718–9747 (cit. on pp. 2, 4)
work page 2024
-
[7]
Cabannes, V., Simsek, B. & Bietti, A.Learning Associative Memories with Gradient Descentin Proceedings of the 41st International Conference on Machine Learning(eds Salakhutdinov, R.et al.) 235(PMLR, 2024), 5114–5134 (cit. on p. 2)
work page 2024
-
[8]
Nichani, E., Lee, J. & Bietti, A.Understanding Factual Recall in Transformers via Associative Memories inInternational Conference on Learning Representations(eds Yue, Y., Garg, A., Peng, N., Sha, F. & Yu, R.)2025(2025), 4166–4207 (cit. on pp. 2, 4)
work page 2025
-
[9]
M., Bietti, A., Soltanolkotabi, M
Vural, N. M., Bietti, A., Soltanolkotabi, M. & Wu, D.Learning to Recall with Transformers Beyond Orthogonal EmbeddingsinThe Fourteenth International Conference on Learning Representations (2026) (cit. on p. 2)
work page 2026
-
[10]
Sharp Capacity Scaling of Spectral Optimizers in Learning Associative Memory
Kim, J., Nichani, E., Wu, D., Bietti, A. & Lee, J. D.Sharp Capacity Scaling of Spectral Optimizers in Learning Associative Memory2026. arXiv:2603.26554 [cs.LG](cit. on pp. 2, 10)
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Gardner, E. & Derrida, B. Optimal storage properties of neural network models.Journal of Physics A: Mathematical and Theoretical21,271–284 (1988) (cit. on pp. 2–4, 9). 11
work page 1988
-
[12]
Cover, T. M. Geometrical and Statistical Properties of Systems of Linear Inequalities with Appli- cations in Pattern Recognition.IEEE Transactions on Electronic ComputersEC-14,326–334 (1965) (cit. on p. 3)
work page 1965
-
[13]
Krauth, W. & Mézard, M. Storage capacity of memory networks with binary couplings.Journal de Physique50,3057–3066 (1989) (cit. on p. 3)
work page 1989
-
[14]
Franz, S., Parisi, G., Sevelev, M., Urbani, P. & Zamponi, F. Universality of the SAT-UNSAT (jamming) threshold in non-convex continuous constraint satisfaction problems.SciPost Physics2,019 (2017) (cit. on p. 3)
work page 2017
- [15]
-
[16]
Huang, B.Capacity threshold for the Ising perceptronin2024 IEEE 65th Annual Symposium on Foundations of Computer Science (FOCS)(2024), 1126–1136 (cit. on p. 3)
work page 2024
-
[17]
Hopfield, J. J. Neural networks and physical systems with emergent collective computational abilities.Proceedings of the National Academy of Sciences79,2554–2558. eprint: https://www. pnas.org/doi/pdf/10.1073/pnas.79.8.2554(1982) (cit. on p. 3)
-
[18]
Amit, D. J., Gutfreund, H. & Sompolinsky, H. Spin-glass models of neural networks.Physical Review A32,1007 (1985) (cit. on p. 3)
work page 1985
-
[19]
Krotov, D. & Hopfield, J. J. Dense associative memory for pattern recognition.Advances in neural information processing systems29(2016) (cit. on p. 3)
work page 2016
-
[20]
Demircigil, M., Heusel, J., Löwe, M., Upgang, S. & Vermet, F. On a Model of Associative Memory with Huge Storage Capacity.Journal of Statistical Physics168,288–299 (May 2017) (cit. on p. 3)
work page 2017
-
[21]
Krotov, D. & Hopfield, J. J.Large Associative Memory Problem in Neurobiology and Machine Learning inInternational Conference on Learning Representations(2021) (cit. on p. 3)
work page 2021
-
[22]
Hopfield Networks is All You NeedinInternational Conference on Learning Representations(2021) (cit
Ramsauer, H.et al. Hopfield Networks is All You NeedinInternational Conference on Learning Representations(2021) (cit. on p. 3)
work page 2021
-
[23]
Lucibello, C. & Mézard, M. Exponential capacity of dense associative memories.Physical Review Letters132,077301 (2024) (cit. on p. 3)
work page 2024
-
[24]
Anderson, J. A. A simple neural network generating an interactive memory.Mathematical Bio- sciences14,197–220 (1972) (cit. on p. 3)
work page 1972
-
[25]
Correlation Matrix Memories.IEEE Transactions on Computers21,353–359 (Apr
Kohonen, T. Correlation Matrix Memories.IEEE Transactions on Computers21,353–359 (Apr. 1972) (cit. on p. 3)
work page 1972
-
[26]
Kosko, B. Bidirectional associative memories.IEEE Transactions on Systems, Man, and Cybernetics 18,49–60 (1988) (cit. on p. 3)
work page 1988
-
[27]
Weston, J., Chopra, S. & Bordes, A.Memory Networksin3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings(eds Bengio, Y. & LeCun, Y.) (2015) (cit. on p. 3)
work page 2015
-
[28]
Barnfield, N., Kim, J., Nichani, E., Lee, J. D. & Lu, Y. M.Sharp Capacity Thresholds in Linear Associative Memory: From Winner-Take-All to Listwise Retrieval2026. arXiv: 2605.05189 [stat.ML] (cit. on pp. 4, 7)
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Hu, H. & Lu, Y. M. Universality Laws for High-Dimensional Learning With Random Features.IEEE Transactions on Information Theory69,1932–1964 (2023) (cit. on pp. 5, 20)
work page 1932
-
[30]
Bandeira, A. S. & Maillard, A. Exact threshold for approximate ellipsoid fitting of random points. Electronic Journal of Probability30,1–46 (2025) (cit. on pp. 5, 10, 20)
work page 2025
-
[31]
Goldt, S.et al. The Gaussian equivalence of generative models for learning with shallow neural networksinProceedings of the 2nd Mathematical and Scientific Machine Learning Conference(eds Bruna, J., Hesthaven, J. & Zdeborova, L.)145(PMLR, 2022), 426–471 (cit. on pp. 5, 20). 12
work page 2022
-
[32]
Montanari, A. & Saeed, B. N.Universality of empirical risk minimizationinConference on Learning Theory(2022), 4310–4312 (cit. on pp. 5, 10, 20)
work page 2022
-
[33]
Mézard, M., Parisi, G. & Virasoro, M. A.Spin glass theory and beyond: An Introduction to the Replica Method and Its Applications(World Scientific Publishing Company, 1987) (cit. on pp. 9, 18, 21)
work page 1987
-
[34]
Gabrié, M. Mean-field inference methods for neural networks.Journal of Physics A: Mathematical and Theoretical53,223002 (2020) (cit. on p. 9)
work page 2020
-
[35]
Charbonneau, P.et al. Spin Glass Theory and Far Beyond: Replica Symmetry Breaking after 40 Years (World Scientific, 2023) (cit. on pp. 9, 18)
work page 2023
-
[36]
Maillard, A., Troiani, E., Martin, S., Krzakala, F. & Zdeborová, L. Bayes-optimal learning of an extensive-width neural network from quadratically many samples.Advances in Neural Information Processing Systems37,82085–82132 (2024) (cit. on pp. 9, 10, 20)
work page 2024
-
[37]
Barbier, J., Camilli, F., Nguyen, M.-T., Pastore, M. & Skerk, R. Statistical physics of deep learning: Optimal learning of a multi-layer perceptron near interpolation.Phys. Rev. X(2026) (cit. on pp. 9, 10)
work page 2026
-
[38]
Guerra, F. & Toninelli, F. L. The thermodynamic limit in mean field spin glass models.Communica- tions in Mathematical Physics230,71–79 (2002) (cit. on p. 9)
work page 2002
-
[39]
The Parisi formula.Annals of mathematics,221–263 (2006) (cit
Talagrand, M. The Parisi formula.Annals of mathematics,221–263 (2006) (cit. on p. 9)
work page 2006
-
[40]
The Parisi ultrametricity conjecture.Annals of Mathematics,383–393 (2013) (cit
Panchenko, D. The Parisi ultrametricity conjecture.Annals of Mathematics,383–393 (2013) (cit. on p. 9)
work page 2013
-
[41]
Barbier, J., Krzakala, F., Macris, N., Miolane, L. & Zdeborová, L. Optimal errors and phase transitions in high-dimensional generalized linear models.Proceedings of the National Academy of Sciences 116,5451–5460 (2019) (cit. on p. 9)
work page 2019
-
[42]
Gerbelot, C., Abbara, A. & Krzakala, F. Asymptotic Errors for Teacher-Student Convex Generalized Linear Models (Or: How to Prove Kabashima’s Replica Formula).IEEE Transactions on Information Theory69,1824–1852 (2023) (cit. on p. 9)
work page 2023
-
[43]
Vilucchio, M., Dandi, Y., Rossignol, M. P., Gerbelot, C. & Krzakala, F. Asymptotics of non-convex generalized linear models in high-dimensions: A proof of the replica formula.arXiv preprint arXiv:2502.20003(2025) (cit. on p. 9)
-
[44]
Talagrand, M.Mean field models for spin glasses: Volume I: Basic examples(Springer Science & Business Media, 2010) (cit. on pp. 9, 21)
work page 2010
-
[45]
Barbier, J., Panchenko, D. & Sáenz, M. Strong replica symmetry for high-dimensional disordered log-concave Gibbs measures.Information and Inference: A Journal of the IMA11,1079–1108 (2022) (cit. on pp. 9, 21)
work page 2022
-
[46]
Maillard, A., Bandeira, A. S., Belius, D., Dokmanić, I. & Nakajima, S. Injectivity of relu networks: perspectives from statistical physics.Applied and Computational Harmonic Analysis76,101736 (2025) (cit. on pp. 10, 19, 22, 27)
work page 2025
-
[47]
Xu, Y., Maillard, A., Krzakala, F. & Zdeborová, L.Fundamental Limits of Matrix Sensing: Exact Asymptotics, Universality, and Applicationsin38th Annual Conference on Learning Theory(2025) (cit. on pp. 10, 20)
work page 2025
-
[48]
Erba, V., Troiani, E., Zdeborova, L. & Krzakala, F.The Nuclear Route: Sharp Asymptotics of ERM in Overparameterized Quadratic NetworksinThe Thirty-ninth Annual Conference on Neural Information Processing Systems(2026) (cit. on p. 10)
work page 2026
- [49]
-
[50]
& Van den Broeck, C.Statistical Mechanics of Learning(Cambridge University Press, 2001) (cit
Engel, A. & Van den Broeck, C.Statistical Mechanics of Learning(Cambridge University Press, 2001) (cit. on p. 19). 13
work page 2001
- [51]
-
[52]
Gerace, F., Krzakala, F., Loureiro, B., Stephan, L. & Zdeborová, L. Gaussian universality of percep- trons with random labels.Physical Review E109,034305 (2024) (cit. on p. 20)
work page 2024
-
[53]
Wen, G. G., Hu, H., Lu, Y. M., Fan, Z. & Misiakiewicz, T. When does Gaussian equivalence fail and how to fix it: Non-universal behavior of random features with quadratic scaling.arXiv preprint arXiv:2512.03325(2025) (cit. on p. 20)
-
[54]
Maillard, A. & Kunisky, D. Fitting an ellipsoid to random points: predictions using the replica method.IEEE Transactions on Information Theory(2024) (cit. on pp. 20, 28–30)
work page 2024
-
[55]
Anderson, G. W., Guionnet, A. & Zeitouni, O.An Introduction to Random Matrices(Cambridge University Press, 2009) (cit. on pp. 20, 27–29)
work page 2009
-
[56]
Vershynin, R.High-dimensional probability: An introduction with applications in data science(Cam- bridge university press, 2018) (cit. on p. 20)
work page 2018
-
[57]
Potters, M. & Bouchaud, J.-P.A First Course in Random Matrix Theory: for Physicists, Engineers and Data Scientists(Cambridge University Press, 2020) (cit. on pp. 27, 33)
work page 2020
-
[58]
Erba, V., Troiani, E., Biggio, L., Maillard, A. & Zdeborová, L. Bilinear sequence regression: A model for learning from long sequences of high-dimensional tokens.Physical Review X15,021092 (2025) (cit. on pp. 28, 30)
work page 2025
- [59]
-
[60]
Bun, J., Bouchaud, J.-P., Majumdar, S. N. & Potters, M. Instanton Approach to Large N Harish- Chandra-Itzykson-Zuber Integrals.Physical Review Letters113,070201 (2014) (cit. on p. 31). 14 A Numerical Experiments Common training strategy.All experiments reported in this manuscript follow the same training protocol. Inputs and outputs (in both the original ...
work page 2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.