Recognition: 2 theorem links
· Lean TheoremTraining-Free Cultural Alignment of Large Language Models via Persona Disagreement
Pith reviewed 2026-05-12 04:03 UTC · model grok-4.3
The pith
Disagreement among World Values Survey personas steers black-box LLMs toward country-specific cultural preferences at inference time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors establish that instantiating each country as a panel of persona agents grounded in World Values Survey responses, then converting their disagreement into a bounded logit correction, reduces cultural misalignment on the MultiTP benchmark by 10 to 24 percent across six model scales from 3.8B to 70B parameters, and by 2 to 7 percent in open-ended scenarios, all without modifying model parameters.
What carries the argument
DISCA, a disagreement-informed steering mechanism that instantiates countries via multiple World-Values-Survey-grounded persona agents and applies their disagreement as a loss-averse logit adjustment at inference.
If this is right
- Black-box LLMs can be aligned to diverse cultures using only public survey data and inference-time computation.
- The method scales across model sizes from 3.8 billion to 70 billion parameters without retraining.
- Within-country disagreement serves as a more effective steering signal than seeking cultural consensus.
- Open-ended generation scenarios show smaller but positive gains from the same correction.
- Alignment becomes feasible for the long tail of global moral preferences without per-country fine-tuning budgets.
Where Pith is reading between the lines
- Providers of API-based models could deploy this as a default layer to improve cultural sensitivity for users in different regions.
- The approach might extend to other forms of value alignment, such as political or ethical preferences, by sourcing appropriate disagreement data.
- Future work could test whether the same personas improve performance on related tasks like cross-cultural translation or bias detection.
- Since it requires no weight changes, it could be combined with other inference techniques like chain-of-thought without interference.
Load-bearing premise
That the disagreement among sociodemographic personas derived from the World Values Survey captures the primary and sufficient signal needed to correct a model's cultural misalignment.
What would settle it
Measuring cultural misalignment on the MultiTP benchmark after applying the DISCA logit correction and finding that scores do not decrease compared to the uncorrected baseline, or decrease less than a control using random personas.
Figures

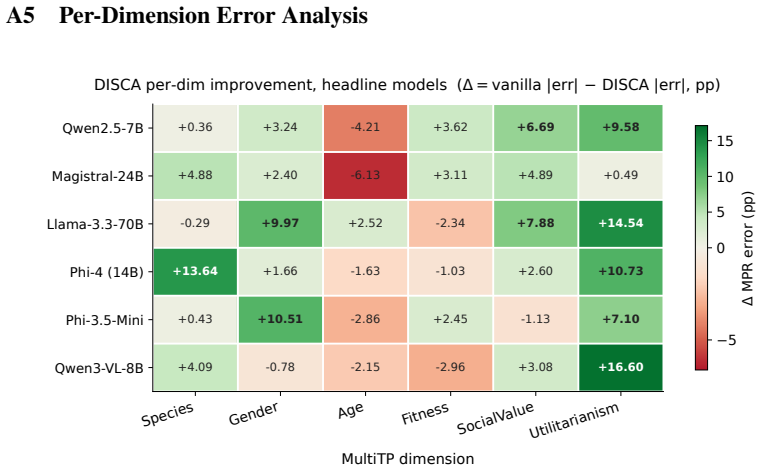
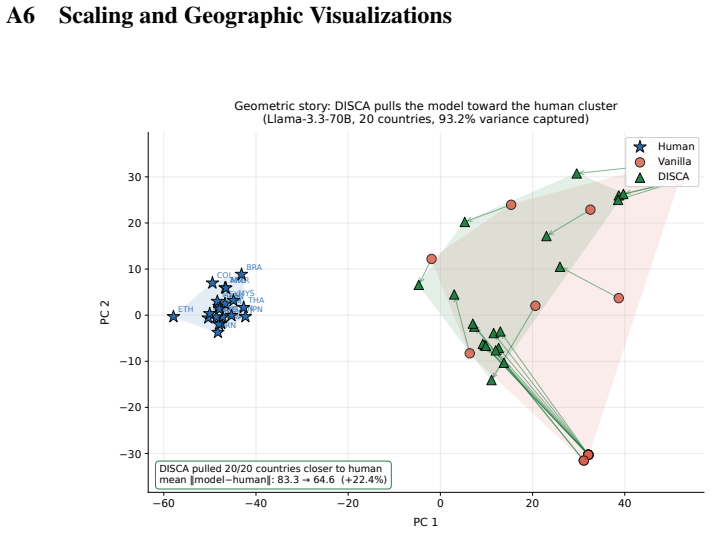
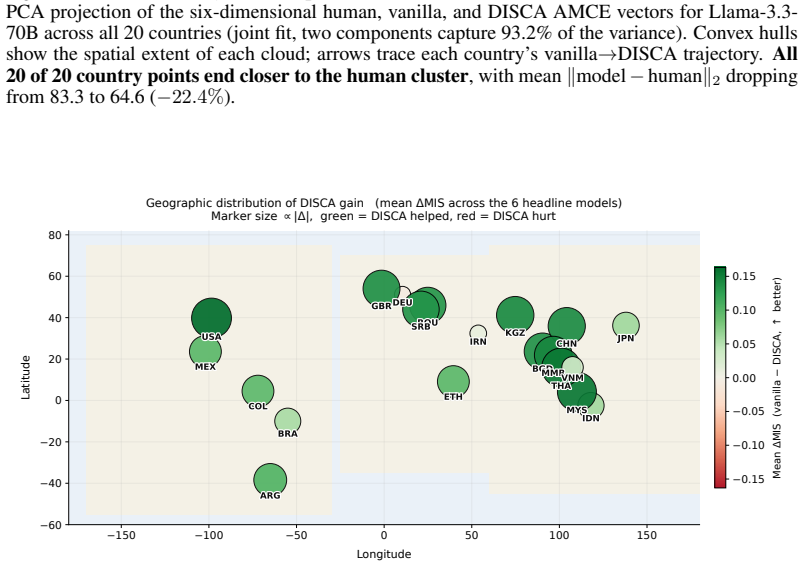
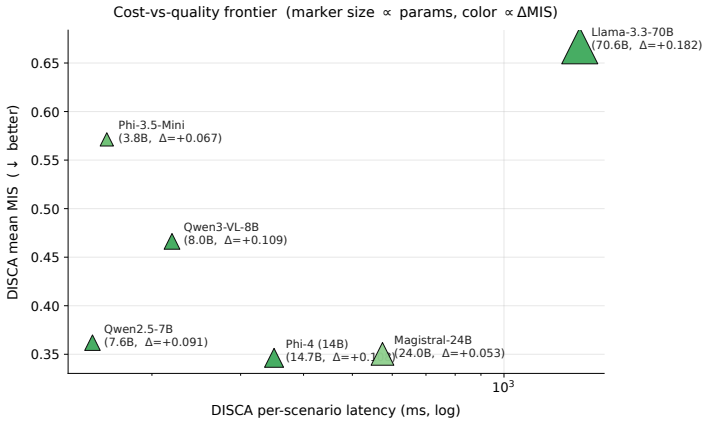
read the original abstract
Large language models increasingly mediate decisions that turn on moral judgement, yet a growing body of evidence shows that their implicit preferences are not culturally neutral. Existing cultural alignment methods either require per-country preference data and fine-tuning budgets or assume white-box access to model internals that commercial APIs do not expose. In this work, we focus on this realistic black-box, public-data-only regime and observe that within-country sociodemographic disagreement, not consensus, is the primary steering signal. We introduce DISCA (Disagreement-Informed Steering for Cultural Alignment), an inference-time method that instantiates each country as a panel of World-Values-Survey-grounded persona agents and converts their disagreement into a bounded, loss-averse logit correction. Across 20 countries and 7 open-weight backbones (2B--70B), DISCA reduces cultural misalignment on MultiTP by 10--24% on the six backbones >=3.8B, and 2--7% on open-ended scenarios, without changing any weights. Our results suggest that inference-time calibration is a scalable alternative to fine-tuning for serving the long tail of global moral preferences.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DISCA, an inference-time method for cultural alignment of LLMs. It instantiates each country as a panel of World Values Survey-grounded persona agents whose disagreement is converted into a bounded, loss-averse logit correction. Evaluated across 20 countries and 7 open-weight backbones (2B-70B), it claims 10-24% reduction in cultural misalignment on MultiTP for models >=3.8B and 2-7% on open-ended scenarios, without any weight changes, positioning it as a scalable alternative to fine-tuning in black-box, public-data-only settings.
Significance. If the results hold, the work would be significant for showing that public survey data and inference-time steering via disagreement can mitigate cultural misalignment without training, offering a practical approach for the long tail of global preferences. It credits the use of external WVS data and open-weight model evaluations as strengths, though applicability beyond logit-accessible models remains untested.
major comments (3)
- [Abstract] Abstract: The paper frames DISCA as a solution for the 'realistic black-box, public-data-only regime' because prior methods require fine-tuning or white-box access. However, the method 'converts their disagreement into a bounded, loss-averse logit correction,' which presupposes direct access to output token probabilities. Experiments are reported only on 7 open-weight backbones; no prompt-only approximation or transfer to closed APIs (e.g., GPT-4) is tested. This makes the central black-box claim unsupported.
- [Experiments] Experiments section: The abstract states quantitative improvements of 10-24% on MultiTP and 2-7% on open-ended scenarios, but provides no details on experimental controls, baseline comparisons, statistical significance, variance across runs, or how the logit correction bound is enforced. This prevents assessment of whether the data support the claims.
- [Method] Method section: The claim that within-country sociodemographic disagreement (via WVS-grounded personas) is the primary steering signal is load-bearing but lacks ablations. No comparison is shown against consensus-based personas, random personas, or alternative disagreement measures to confirm sufficiency.
minor comments (2)
- [Abstract] Abstract: Clarify performance on the 2B model, as improvements are reported only for the six backbones >=3.8B.
- [Overall] Overall: Define MultiTP at first mention and provide a brief description of the benchmark and open-ended evaluation protocol.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important clarifications needed regarding the scope of our method and the robustness of our experimental claims. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The paper frames DISCA as a solution for the 'realistic black-box, public-data-only regime' because prior methods require fine-tuning or white-box access. However, the method 'converts their disagreement into a bounded, loss-averse logit correction,' which presupposes direct access to output token probabilities. Experiments are reported only on 7 open-weight backbones; no prompt-only approximation or transfer to closed APIs (e.g., GPT-4) is tested. This makes the central black-box claim unsupported.
Authors: We agree that the logit correction requires direct access to output probabilities, which is available for open-weight models but not for closed APIs. In the manuscript, 'black-box' denotes the absence of weight updates or private training data, contrasting with fine-tuning approaches. To resolve the ambiguity, we will revise the abstract, introduction, and related sections to explicitly limit the claim to open-weight models with logit access and note the untested status for proprietary APIs. No prompt-only approximation was developed, as the core mechanism depends on logit adjustments. revision: partial
-
Referee: [Experiments] Experiments section: The abstract states quantitative improvements of 10-24% on MultiTP and 2-7% on open-ended scenarios, but provides no details on experimental controls, baseline comparisons, statistical significance, variance across runs, or how the logit correction bound is enforced. This prevents assessment of whether the data support the claims.
Authors: We will expand the Experiments section with a dedicated subsection on setup and controls. This will include baseline comparisons (standard prompting, consensus personas, and prior alignment techniques), statistical significance tests (e.g., paired tests across countries), variance as standard deviations over repeated runs, and the precise enforcement of the loss-averse logit bound via the correction formula and hyperparameters. These details will substantiate the reported improvements. revision: yes
-
Referee: [Method] Method section: The claim that within-country sociodemographic disagreement (via WVS-grounded personas) is the primary steering signal is load-bearing but lacks ablations. No comparison is shown against consensus-based personas, random personas, or alternative disagreement measures to confirm sufficiency.
Authors: We will add an ablation subsection comparing the disagreement-based approach to consensus-based personas, random personas, and alternative metrics such as opinion variance or entropy. The results will show that sociodemographic disagreement yields stronger alignment gains, validating its role as the primary signal. This will be supported by quantitative tables and discussion of cultural nuance captured by disagreement. revision: yes
Circularity Check
No circularity: derivation grounded in external WVS data and explicit inference-time procedure
full rationale
The paper's central method (DISCA) instantiates personas from the external World Values Survey, computes disagreement among them, and applies a defined logit correction at inference time. No quoted equations, self-citations, or steps reduce the claimed misalignment reduction to a fitted parameter renamed as prediction, a self-definitional loop, or an ansatz imported only via the authors' prior work. The empirical results on open-weight models are presented as direct measurements rather than forced by construction from the inputs. The black-box framing mismatch noted in external commentary concerns applicability assumptions, not a circular derivation chain within the paper's own logic.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Proposition 1(Variance-aware shrinkage...): γ⋆ = Δ_h² / (Δ_h² + τ²/N), monotone-decreasing in τ².
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
loss-averse importance sampling... Kahneman–Tversky value function v(z) = z^α (z≥0), −κ(−z)^α (z<0)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Large-scale moral machine experiment on large language models , author =. PLOS ONE , year =. doi:10.1371/journal.pone.0322776 , url =
-
[2]
Kanai, Sekitoshi and Yoshida, Tsukasa and Takahashi, Hiroshi and Kuroki, Haru and Hashimoto, Kazumune , journal=. Test-Time Alignment of. 2025 , doi=
work page 2025
-
[3]
arXiv preprint arXiv:2601.10960 , year=
Steering Language Models Before They Speak: Logit-Level Interventions , author=. arXiv preprint arXiv:2601.10960 , year=. doi:10.48550/arXiv.2601.10960 , url=
-
[4]
Advances in Neural Information Processing Systems , volume=
Refusal in language models is mediated by a single direction , author=. Advances in Neural Information Processing Systems , volume=. 2025 , doi=
work page 2025
-
[5]
Which Humans? , author=. PsyArXiv preprint , year=. doi:10.31234/osf.io/5b26t , note=
-
[6]
The moral machine experiment , author=. Nature , volume=. 2018 , publisher=
work page 2018
-
[7]
Bobbili, Sarat Chandra and Dinesha, Ujwal and Narasimha, Dheeraj and Shakkottai, Srinivas , journal=. 2025 , doi=
work page 2025
-
[8]
No Free Lunch in Language Model Bias Mitigation?
Chand, Shireen and Baca, Faith and Ferrara, Emilio , journal=. No Free Lunch in Language Model Bias Mitigation?. 2026 , publisher=
work page 2026
-
[9]
Chen, Ruizhe and Chai, Wenhao and Yang, Zhifei and Zhang, Xiaotian and Wang, Ziyang and Quek, Tony and Zhou, Joey Tianyi and Poria, Soujanya and Liu, Zuozhu , booktitle=. 2025 , address=. doi:10.18653/v1/2025.acl-long.926 , url=
-
[10]
doi: 10.18653/v1/2023.findings-emnlp.88
Deshpande, Ameet and Murahari, Vishvak and Rajpurohit, Tanmay and Kalyan, Ashwin and Narasimhan, Karthik , booktitle=. Toxicity in. 2023 , address=. doi:10.18653/v1/2023.findings-emnlp.88 , url=
-
[11]
Proceedings of the 41st International Conference on Machine Learning , series=
Improving Factuality and Reasoning in Language Models through Multiagent Debate , author=. Proceedings of the 41st International Conference on Machine Learning , series=. 2024 , publisher=
work page 2024
-
[12]
arXiv preprint arXiv:2306.16388 , year =
Towards measuring the representation of subjective global opinions in language models , author=. arXiv preprint arXiv:2306.16388 , year=
-
[13]
The Annals of Statistics , volume=
Bootstrap methods: another look at the jackknife , author=. The Annals of Statistics , volume=. 1979 , note=. doi:10.1007/978-1-4612-4380-9_41 , url=
-
[14]
Wiley StatsRef: Statistics Reference Online , pages=
Advances in importance sampling , author=. Wiley StatsRef: Statistics Reference Online , pages=. 2021 , publisher=. doi:10.1002/9781118445112.stat08284 , url=
-
[15]
Ethayarajh, Kawin and Xu, Winnie and Muennighoff, Niklas and Jurafsky, Dan and Kiela, Douwe , booktitle=. 2024 , note=
work page 2024
-
[16]
Gal, Yarin and Ghahramani, Zoubin , booktitle=. Dropout as a. 2016 , url=
work page 2016
-
[17]
arXiv preprint arXiv:2601.22396 , year=
Culturally Grounded Personas in Large Language Models: Characterization and Alignment with Socio-Psychological Value Frameworks , author=. arXiv preprint arXiv:2601.22396 , year=
-
[18]
Proceedings of the 34th International Conference on Machine Learning , series=
On Calibration of Modern Neural Networks , author=. Proceedings of the 34th International Conference on Machine Learning , series=. 2017 , note=
work page 2017
-
[19]
Haerpfer, Christian and Inglehart, Ronald and Moreno, Alejandro and Welzel, Christian and Kizilova, Kseniya and Diez-Medrano, Jaime and Lagos, Marta and Norris, Pippa and Ponarin, Eduard and Puranen, Bi , howpublished=. 2020 , note=
work page 2020
- [20]
-
[21]
The weirdest people in the world? , author=. Behavioral and Brain Sciences , volume=. 2010 , publisher=. doi:10.1017/S0140525X0999152X , url=
-
[22]
Modernization, Cultural Change, and Democracy: The Human Development Sequence , author=. 2005 , publisher=
work page 2005
-
[23]
Estimation with Quadratic Loss , author =. Proceedings of the Fourth Berkeley Symposium on Mathematical Statistics and Probability, Volume 1: Contributions to the Theory of Statistics , year =
-
[24]
Advances in Neural Information Processing Systems , volume=
When to make exceptions: Exploring language models as accounts of human moral judgment , author=. Advances in Neural Information Processing Systems , volume=. 2022 , url=
work page 2022
-
[25]
International Conference on Learning Representations , year=
Jin, Zhijing and Kleiman-Weiner, Max and Piatti, Giorgio and Levine, Sydney and Liu, Jiarui and Adauto, Fernando Gonzalez and Ortu, Francesco and Strausz, Andr. International Conference on Learning Representations , year=
-
[26]
Prospect theory: An analysis of decision under risk , author=. Econometrica , volume=. 1979 , publisher=
work page 1979
-
[27]
Randomness, Not Representation: The Unreliability of Evaluating Cultural Alignment in
Khan, Ariba and Casper, Stephen and Hadfield-Menell, Dylan , booktitle=. Randomness, Not Representation: The Unreliability of Evaluating Cultural Alignment in. 2025 , pages=. doi:10.1145/3715275.3732147 , url=
-
[28]
Khanov, Maxim and Burapacheep, Jirayu and Li, Yixuan , booktitle=. 2024 , url=
work page 2024
- [29]
-
[30]
arXiv preprint arXiv:2504.10886 , year =
Exploring Persona-dependent LLM Alignment for the Moral Machine Experiment , author =. arXiv preprint arXiv:2504.10886 , year =. doi:10.48550/arXiv.2504.10886 , url =
- [31]
- [32]
- [33]
-
[34]
Dropouts in Confidence: Moral Uncertainty in Human-
Kwon, Jea and Vecchietti, Luiz Felipe and Park, Sungwon and Cha, Meeyoung , booktitle=. Dropouts in Confidence: Moral Uncertainty in Human-. 2026 , note=
work page 2026
-
[35]
Reinforcement learning and control as probabilistic inference:
Levine, Sergey , journal=. Reinforcement learning and control as probabilistic inference:. 2018 , doi=
work page 2018
-
[36]
Encouraging Divergent Thinking in Large Language Models through Multi-Agent Debate , author =. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , year =. doi:10.18653/v1/2024.emnlp-main.992 , url =
-
[37]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Lost in the middle: How language models use long contexts , author=. Transactions of the Association for Computational Linguistics , volume=. 2024 , publisher=. doi:10.1162/tacl_a_00638 , url=
-
[38]
Proceedings of the 41st International Conference on Machine Learning , series=
Controlled Decoding from Language Models , author=. Proceedings of the 41st International Conference on Machine Learning , series=. 2024 , publisher=
work page 2024
-
[39]
Myung, Junho and Lee, Nayeon and Zhou, Yi and Jin, Jiho and Putri, Rifki Afina and Antypas, Dimosthenis and Borkakoty, Hsuvas and Kim, Eunsu and Perez-Almendros, Carla and Ayele, Abinew Ali and others , booktitle=. 2024 , doi=
work page 2024
-
[40]
Nie, Allen and Zhang, Yuhui and Amdekar, Atharva and Piech, Chris and Hashimoto, Tatsunori B and Gerstenberg, Tobias , booktitle=. 2023 , doi=
work page 2023
- [41]
-
[42]
Multimodal Cultural Safety: Evaluation Framework and Alignment Strategies , author=. 2025 , eprint=. doi:10.48550/arXiv.2505.14972 , url=
-
[43]
Ryan, Michael J and Held, William and Yang, Diyi , booktitle=. Unintended Impacts of. 2024 , address=. doi:10.18653/v1/2024.acl-long.853 , url=
-
[44]
arXiv preprint arXiv:2303.17548 , year =
Whose opinions do language models reflect? , author=. arXiv preprint arXiv:2303.17548 , year=
-
[45]
Journal of Personality and Social Psychology , volume=
Refining the theory of basic individual values , author=. Journal of Personality and Social Psychology , volume=. 2012 , publisher=
work page 2012
-
[46]
arXiv preprint arXiv:2402.05070 , year =
A roadmap to pluralistic alignment , author=. arXiv preprint arXiv:2402.05070 , year=. doi:10.48550/arXiv.2402.05070 , url=
-
[47]
Royal Society Open Science , volume=
The moral machine experiment on large language models , author=. Royal Society Open Science , volume=. 2024 , doi=
work page 2024
-
[48]
Proceedings of the National Academy of Sciences , volume=
Efficient computation of optimal actions , author=. Proceedings of the National Academy of Sciences , volume=. 2009 , publisher=. doi:10.1073/pnas.0710743106 , url=
-
[49]
Steering Language Models With Activation Engineering
Activation Addition: Steering Language Models Without Optimization , author=. arXiv preprint arXiv:2308.10248 , year=. doi:10.48550/arXiv.2308.10248 , url=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2308.10248
-
[50]
Journal of Risk and Uncertainty , volume=
Advances in prospect theory: Cumulative representation of uncertainty , author=. Journal of Risk and Uncertainty , volume=. 1992 , publisher=. doi:10.1007/BF00122574 , url=
-
[51]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author =. International Conference on Learning Representations (ICLR) , year =. doi:10.48550/arXiv.2203.11171 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2203.11171
-
[52]
IEEE Transactions on Robotics , volume=
Information-theoretic model predictive control: Theory and applications to autonomous driving , author=. IEEE Transactions on Robotics , volume=. 2018 , publisher=. doi:10.1109/TRO.2018.2865891 , url=
-
[53]
Yao, Jing and Yi, Xiaoyuan and Wang, Jindong and Dou, Zhicheng and Xie, Xing , journal=. 2025 , doi=
work page 2025
-
[54]
Proceedings of the National Academy of Sciences , volume=
Moral stereotyping in large language models , author=. Proceedings of the National Academy of Sciences , volume=. 2026 , doi=
work page 2026
-
[55]
arXiv preprint arXiv:2602.22475 , year=
Mind the Gap in Cultural Alignment: Task-Aware Culture Management for Large Language Models , author=. arXiv preprint arXiv:2602.22475 , year=
-
[56]
Representation engineering: A top-down approach to
Zou, Andy and Phan, Long and Chen, Sarah and Campbell, James and Guo, Phillip and others , journal=. Representation engineering: A top-down approach to
- [57]
-
[58]
Kalai, Ehud and Smorodinsky, Meir , title =. Econometrica , volume =. 1975 , doi =
work page 1975
-
[59]
Mahalanobis, P. C. , title =. Journal of the Royal Statistical Society , volume =
- [60]
- [61]
-
[62]
Annals of Mathematical Statistics , volume =
Hoeffding, Wassily , title =. Annals of Mathematical Statistics , volume =
- [63]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.