Recognition: 1 theorem link
· Lean TheoremRethinking Agentic Search with Pi-Serini: Is Lexical Retrieval Sufficient?
Pith reviewed 2026-05-12 04:10 UTC · model grok-4.3
The pith
Lexical BM25 retrieval suffices for effective deep research when paired with capable LLMs in agentic search.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
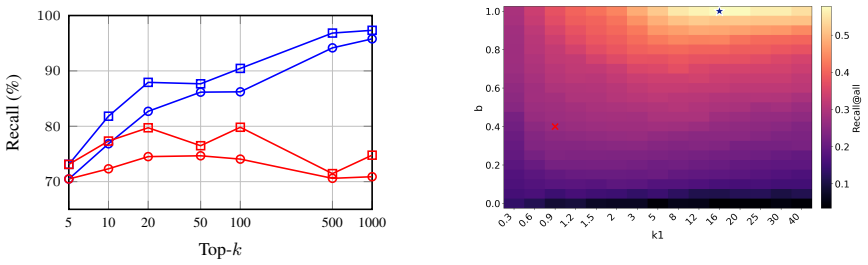
By equipping frontier LLMs with a lexical BM25 retriever in an agentic loop via Pi-Serini, the system achieves 83.1% answer accuracy and 94.7% surfaced evidence recall on BrowseComp-Plus, outperforming released search agents that use dense retrievers.
What carries the argument
Pi-Serini, an agent with three tools (BM25 retrieval, document browsing, and reading) that places lexical search inside the LLM agentic loop.
Load-bearing premise
That the BrowseComp-Plus benchmark and the specific LLM configurations produce results that generalize to other deep-research tasks and are not explained by differences in tool implementation or prompting.
What would settle it
A controlled comparison on BrowseComp-Plus showing that a dense-retriever agent with matched LLM and prompting details achieves higher accuracy and recall than the tuned BM25 version of Pi-Serini.
Figures


read the original abstract
Does a lexical retriever suffice as large language models (LLMs) become more capable in an agentic loop? This question naturally arises when building deep research systems. We revisit it by pairing BM25 with frontier LLMs that have better reasoning and tool-use abilities. To support researchers asking the same question, we introduce Pi-Serini, a search agent equipped with three tools for retrieving, browsing, and reading documents. Our results show that, on BrowseComp-Plus, a well-configured lexical retriever with sufficient retrieval depth can support effective deep research when paired with more capable LLMs. Specifically, Pi-Serini with gpt-5.5 achieves 83.1% answer accuracy and 94.7% surfaced evidence recall, outperforming released search agents that use dense retrievers. Controlled ablations further show that BM25 tuning improves answer accuracy by 18.0% and surfaced evidence recall by 11.1% over the default BM25 setting, while increasing retrieval depth further improves surfaced evidence recall by 25.3% over the shallow-retrieval setting. Source code is available at https://github.com/justram/pi-serini.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Pi-Serini, a three-tool agent (retrieve, browse, read) built on BM25 lexical retrieval, and reports that pairing it with frontier LLMs such as gpt-5.5 yields 83.1% answer accuracy and 94.7% surfaced evidence recall on BrowseComp-Plus, outperforming released dense-retriever agents. Controlled ablations within the system show that BM25 tuning improves accuracy by 18.0% and recall by 11.1%, while greater retrieval depth adds 25.3% to recall.
Significance. If the performance advantage can be shown to arise specifically from lexical retrieval rather than from the agent framework or prompting, the result would indicate that well-tuned BM25 remains competitive for deep research tasks when paired with capable LLMs, offering a simpler, tunable, and fully open-source alternative to dense pipelines. The public GitHub release strengthens the contribution by enabling direct replication and extension.
major comments (2)
- [Abstract] Abstract: The claim that Pi-Serini 'outperforms released search agents that use dense retrievers' is not supported by matched experiments. The baselines are described only as previously released systems; no evidence is given that they were re-run with the same LLM (gpt-5.5), the same three-tool interface, or the same agent loop, so the reported deltas (83.1% accuracy, 94.7% recall) cannot be unambiguously attributed to lexical retrieval.
- [Ablations] Ablation results (as summarized in the abstract): The reported gains from BM25 tuning (+18.0% accuracy) and increased retrieval depth (+25.3% recall) are measured only inside Pi-Serini. Without a parallel ablation that replaces BM25 with a dense retriever while holding the agent framework, tools, and prompting fixed, the experiments do not isolate retrieval type from other design choices.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important aspects of experimental design and attribution. We address each major comment below, agreeing where the manuscript requires clarification and proposing targeted revisions.
read point-by-point responses
-
Referee: [Abstract] The claim that Pi-Serini 'outperforms released search agents that use dense retrievers' is not supported by matched experiments. The baselines are described only as previously released systems; no evidence is given that they were re-run with the same LLM (gpt-5.5), the same three-tool interface, or the same agent loop, so the reported deltas (83.1% accuracy, 94.7% recall) cannot be unambiguously attributed to lexical retrieval.
Authors: We agree that the reported outperformance is based on comparisons to the published results of released dense-retriever agents rather than re-executions under identical conditions (same LLM, tool set, and agent loop). The manuscript's intent is to demonstrate that a well-tuned lexical retriever can achieve strong results on BrowseComp-Plus when paired with frontier LLMs, exceeding the figures reported for existing dense systems. To prevent misinterpretation, we will revise the abstract and introduction to explicitly note that these are comparisons to published baseline results and add a brief discussion of potential confounding factors in the limitations section. revision: yes
-
Referee: [Ablations] The reported gains from BM25 tuning (+18.0% accuracy) and increased retrieval depth (+25.3% recall) are measured only inside Pi-Serini. Without a parallel ablation that replaces BM25 with a dense retriever while holding the agent framework, tools, and prompting fixed, the experiments do not isolate retrieval type from other design choices.
Authors: The ablations were conducted internally to quantify the benefits of BM25 parameter tuning and retrieval depth within the fixed Pi-Serini agent framework. We concur that this design does not isolate the effect of lexical versus dense retrieval while holding the agent, tools, and prompting constant. Performing the complementary dense-retriever ablation would require substantial additional implementation effort to integrate a dense index into the same three-tool loop. We will add text in the discussion and limitations sections to clarify the scope of the current ablations and identify a full cross-retrieval ablation as valuable future work. revision: partial
Circularity Check
No circularity: direct empirical measurements on fixed benchmark
full rationale
The paper reports measured answer accuracy (83.1%) and evidence recall (94.7%) for Pi-Serini (BM25 + gpt-5.5) on BrowseComp-Plus, plus internal ablations quantifying gains from BM25 tuning (+18.0% accuracy) and retrieval depth (+25.3% recall). These are observed experimental outcomes under controlled conditions, not quantities derived from equations, fitted parameters renamed as predictions, or self-citation chains. No load-bearing derivations, uniqueness theorems, or ansatzes appear in the provided text; the results stand as independent benchmark data.
Axiom & Free-Parameter Ledger
free parameters (2)
- BM25 tuning parameters =
tuned
- retrieval depth =
increased
invented entities (1)
-
Pi-Serini
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquationwashburn_uniqueness_aczel unclearControlled ablations further show that BM25 tuning improves answer accuracy by 18.0% and surfaced evidence recall by 11.1% over the default BM25 setting, while increasing retrieval depth further improves surfaced evidence recall by 25.3% over the shallow-retrieval setting.
Reference graph
Works this paper leans on
-
[1]
Deep research: A systematic survey.Preprint arXiv:2512.02038. Tongyi DeepResearch Team, Baixuan Li, Bo Zhang, Dingchu Zhang, Fei Huang, Guangyu Li, Guoxin Chen, Huifeng Yin, Jialong Wu, Jingren Zhou, Kuan Li, Liangcai Su, Litu Ou, Liwen Zhang, Pengjun Xie, Rui Ye, Wenbiao Yin, Xinmiao Yu, Xinyu Wang, and 38 others. 2025. Tongyi DeepResearch technical repo...
-
[2]
Use search with a concise raw query string based on the original question
-
[3]
Prefer short lexical searches over long natural-language rewrites
-
[4]
Browse the current ranking with read_search_results before repeatedly rewriting the query
-
[5]
If a promising candidate document appears in the ranking, inspect it with read_document
-
[6]
If it is truncated and still relevant, continue reading the same document
When reading a document, start with offset=1 and a moderate limit. If it is truncated and still relevant, continue reading the same document
-
[7]
Use search refinements only when they add a genuinely new clue from what you already saw
-
[8]
Keep it specific, under 100 words, and focused on the clue, gap, candidate, or ranking issue
Every call to search, read_search_results, and read_document must include reason as the first argument. Keep it specific, under 100 words, and focused on the clue, gap, candidate, or ranking issue
-
[9]
As soon as you have enough evidence, stop using tools and answer in plain assistant text
-
[10]
Your final response must use exactly this format: Explanation: {your explanation for your final answer. Cite supporting docids inline in square brackets [] at the end of sentences when possible, for example [123].} Exact Answer: {your succinct, final answer} Confidence: {your confidence score between 0% and 100%}
-
[11]
Do not do more research after that steer
If you later receive a user steer telling you to submit now, stop using tools immediately and answer right away with the exact final response format below. Do not do more research after that steer
-
[12]
Keep Exact Answer concise and directly responsive to the question. Question: {Question} 2The setup documented in this appendix corresponds to PI-SERINI’s codebase at commit68c5e0f. 11 A.2 Retrieval Tool Interface Tool: search Purpose: Send a raw lexical query to the configured retrieval backend. Arguments: reason: brief rationale, supplied first, at most ...
-
[13]
Send a user steer saying the time budget is nearly exhausted
-
[14]
Instruct the agent to stop using tools and submit its best answer immediately
-
[15]
Block later calls to search, read_search_results, and read_document. Final response format after the steer remains: Explanation: ... Exact Answer: ... Confidence: ... A.5 Gold-Answer LLM Judge We evaluate final-answer correctness with a gold-answer LLM judge. The judge receives the question, the agent’s final response, and the benchmark-provided correct a...
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.