Recognition: no theorem link
BenchCAD: A Comprehensive, Industry-Standard Benchmark for Programmatic CAD
Pith reviewed 2026-05-13 02:47 UTC · model grok-4.3
The pith
BenchCAD shows that current multimodal models recover only coarse outer shapes in industrial CAD parts and fail to generate accurate parametric code.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
BenchCAD demonstrates that while models can approximate the visible outer geometry of industrial parts from visual or textual inputs, they consistently fail to produce executable parametric CAD programs that capture the full 3D structure, correct engineering parameters, and the specific sequence of design operations such as sweeps, lofts, and twist-extrudes.
What carries the argument
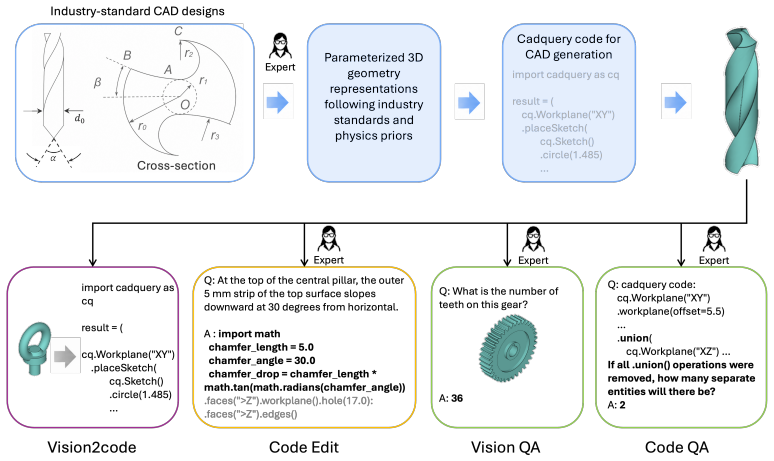
BenchCAD, a unified benchmark of 17,900 execution-verified CadQuery programs across 106 industrial part families, evaluated through visual question answering, code question answering, image-to-code generation, and instruction-guided code editing.
If this is right
- Models recover coarse outer geometry but miss fine 3D structure in industrial parts.
- Essential operations such as sweeps, lofts, and twist-extrudes are replaced by simpler sketch-and-extrude patterns.
- Industrial design parameters are frequently misinterpreted.
- Fine-tuning and reinforcement learning improve performance on seen part families.
- Generalization to unseen part families remains limited.
Where Pith is reading between the lines
- The benchmark could guide creation of models that better handle parametric reuse in manufacturing workflows.
- Observed gaps in operation selection point to a need for training that emphasizes engineering intent over surface appearance.
- Limited generalization suggests that expanding the set of part families with more parameter variations would be a direct next test.
Load-bearing premise
The 106 selected industrial part families and their programs are representative of the full diversity and complexity of real-world industrial CAD tasks.
What would settle it
A model that produces correct, executable parametric programs matching the ground-truth CadQuery code for a diverse set of previously unseen part families from the benchmark, without replacing complex operations with simpler ones.
Figures













read the original abstract
Industrial Computer-Aided Design (CAD) code generation requires models to produce executable parametric programs from visual or textual inputs. Beyond recognizing the outer shape of a part, this task involves understanding its 3D structure, inferring engineering parameters, and choosing CAD operations that reflect how the part would be designed and manufactured. Despite the promise of Multimodal large language models (MLLMs) for this task, they are rarely evaluated on whether these capabilities jointly hold in realistic industrial CAD settings. We present BenchCAD, a unified benchmark for industrial CAD reasoning. BenchCAD contains 17,900 execution-verified CadQuery programs across 106 industrial part families, including bevel gears, compression springs, twist drills, and other reusable engineering designs. It evaluates models through visual question answering, code question answering, image-to-code generation, and instruction-guided code editing, enabling fine-grained analysis across perception, parametric abstraction, and executable program synthesis. Across 10+ frontier models, BenchCAD shows that current systems often recover coarse outer geometry but fail to produce faithful parametric CAD programs. Common failures include missing fine 3D structure, misinterpreting industrial design parameters, and replacing essential operations such as sweeps, lofts, and twist-extrudes with simpler sketch-and-extrude patterns. Fine-tuning and reinforcement learning improve in-distribution performance, but generalization to unseen part families remains limited. These results position BenchCAD as a benchmark for measuring and improving the industrial readiness of multimodal CAD automation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
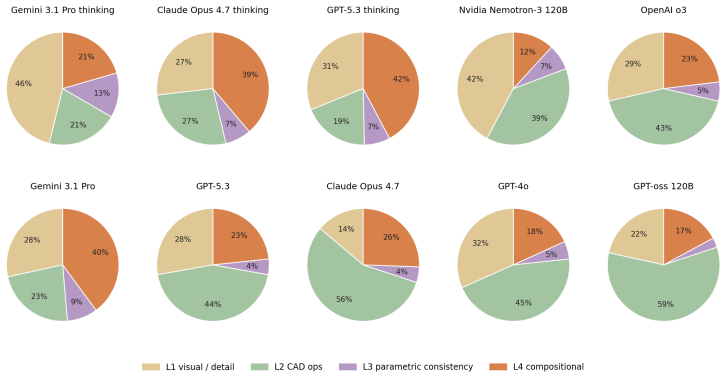
Summary. The paper introduces BenchCAD, a benchmark of 17,900 execution-verified CadQuery programs across 106 industrial part families (e.g., bevel gears, compression springs, twist drills). It supports four task types—visual question answering, code question answering, image-to-code generation, and instruction-guided editing—to assess multimodal models on perception, parametric abstraction, and executable program synthesis. Evaluation of 10+ frontier models shows they recover coarse outer geometry but fail to produce faithful parametric programs, with common errors including missing fine 3D structure, misinterpreting industrial parameters, and replacing sweeps/lofts/twist-extrudes by sketch-and-extrude patterns. Fine-tuning and RL improve in-distribution results, but generalization to unseen families is limited.
Significance. If the benchmark construction and evaluation protocols are validated, BenchCAD would constitute a substantial contribution by supplying the first large-scale, execution-verified industrial CAD benchmark that directly measures parametric program fidelity rather than surface geometry alone. The explicit cataloguing of failure modes (operation substitution, parameter misinterpretation) supplies concrete, falsifiable targets for future CAD automation work and the provision of reproducible CadQuery programs is a clear methodological strength.
major comments (3)
- [§3] §3 (Dataset Construction): the claim that the 106 part families constitute an 'industry-standard' benchmark rests on unstated selection criteria and lacks any quantitative comparison (operation-type histograms, parameter-complexity distributions, or coverage statistics) against external manufacturing corpora; without this, the reported systematic failures could be artifacts of the chosen subset rather than general industrial behavior.
- [§4] §4 (Evaluation Protocol): the abstract and results sections report performance gaps and failure-mode statistics but supply no information on train/test splits, inter-annotator or execution-verification procedures, statistical significance tests, or post-hoc derivation of the listed failure categories; these omissions make it impossible to assess whether the central claim of 'limited generalization' is robust.
- [§5] §5 (Generalization Experiments): the statement that 'generalization to unseen part families remains limited' is load-bearing for the paper's positioning of BenchCAD, yet no quantitative breakdown is given of how 'unseen' families differ in operation distribution or complexity from the training families, weakening the evidential basis for the generalization conclusion.
minor comments (2)
- [Abstract] The abstract and introduction repeatedly use 'industry-standard' without a supporting definition or external reference; a brief clarification of the term would improve precision.
- [Figures/Tables] Figure captions and table headers should explicitly state the number of samples per family and the exact CadQuery version used for verification to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for their thorough and constructive review of our manuscript on BenchCAD. The feedback highlights important areas for improving the clarity and rigor of our dataset construction, evaluation protocols, and generalization analysis. We address each major comment below and commit to making the necessary revisions to strengthen the paper.
read point-by-point responses
-
Referee: [§3] §3 (Dataset Construction): the claim that the 106 part families constitute an 'industry-standard' benchmark rests on unstated selection criteria and lacks any quantitative comparison (operation-type histograms, parameter-complexity distributions, or coverage statistics) against external manufacturing corpora; without this, the reported systematic failures could be artifacts of the chosen subset rather than general industrial behavior.
Authors: We agree that explicit selection criteria and quantitative comparisons would better support the 'industry-standard' positioning. The families were selected to represent a broad spectrum of industrial components drawn from engineering design handbooks and common manufacturing practices, ensuring coverage of diverse CAD operations and parametric variations. In the revised manuscript, we will expand §3 to include a clear statement of the selection criteria (e.g., inclusion of key operations like extrude, sweep, loft, revolve; range of part complexities; representation across industries such as mechanical, automotive). We will also add operation-type histograms, parameter-complexity distributions, and coverage statistics. While comprehensive external manufacturing corpora are not publicly available for direct comparison, we will reference and contrast with existing open CAD datasets to contextualize our benchmark. These changes will help demonstrate that the observed failures are not artifacts of our selection. revision: yes
-
Referee: [§4] §4 (Evaluation Protocol): the abstract and results sections report performance gaps and failure-mode statistics but supply no information on train/test splits, inter-annotator or execution-verification procedures, statistical significance tests, or post-hoc derivation of the listed failure categories; these omissions make it impossible to assess whether the central claim of 'limited generalization' is robust.
Authors: We acknowledge that the evaluation protocol details were insufficiently described. The train/test splits were designed at the part-family level, with 80% of families for training/fine-tuning and 20% held out for testing generalization, ensuring no family overlap. All programs were execution-verified by running them in the CadQuery environment and confirming successful 3D model generation without runtime errors. Failure categories were identified through systematic manual review of model-generated programs by the research team, focusing on discrepancies in operations, parameters, and structure. In the revision, we will add a new subsection in §4 detailing the splits, verification procedures, any inter-annotator processes (for failure categorization), statistical tests (e.g., paired t-tests or bootstrap confidence intervals for performance differences), and the post-hoc analysis method for deriving failure modes. This will allow readers to better evaluate the robustness of our findings on limited generalization. revision: yes
-
Referee: [§5] §5 (Generalization Experiments): the statement that 'generalization to unseen part families remains limited' is load-bearing for the paper's positioning of BenchCAD, yet no quantitative breakdown is given of how 'unseen' families differ in operation distribution or complexity from the training families, weakening the evidential basis for the generalization conclusion.
Authors: We agree that providing a quantitative comparison between seen and unseen families is essential to substantiate the generalization results. Currently, the unseen families were chosen to include variations in operation types and complexities not fully represented in the training set. In the revised §5, we will include a quantitative breakdown, such as tables showing the distribution of CAD operations (e.g., percentage of programs using sweeps vs. extrudes), average parameter counts, program lengths, and other complexity metrics for both training and unseen families. This analysis will highlight the distributional shift and support our conclusion that generalization remains limited despite in-distribution improvements from fine-tuning and RL. revision: yes
Circularity Check
No circularity: benchmark and empirical evaluations are self-contained
full rationale
The paper introduces a new dataset of 17,900 execution-verified CadQuery programs across 106 part families and reports direct model evaluations on VQA, code QA, image-to-code, and editing tasks. No equations, fitted parameters, predictions, or derivations are present; results are empirical observations on the newly constructed benchmark rather than reductions to prior inputs or self-citations. The central claims about model failure modes follow straightforwardly from running the models on the provided data.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption CAD programs written in CadQuery can be executed to confirm they produce valid geometry
- domain assumption The 106 part families are representative of industrial CAD usage
Reference graph
Works this paper leans on
-
[1]
Wu, Rundi and Xiao, Chang and Zheng, Changxi , journal =
-
[2]
Willis, Karl D. D. and Pu, Yewen and Luo, Jieliang and Chu, Hang and Du, Tao and Lambourne, Joseph G. and Solar-Lezama, Armando and Matusik, Wojciech , booktitle =
-
[3]
Khan, Mohammad Sadil and Sinha, Sankalp and Uddin, Talha A. M. and Stricker, Didier and Ali, Sk Aziz and Afzal, Muhammad Zeshan , booktitle =
-
[4]
Guan, Yandong and Ge, Xilin and Yang, Shihao and Yang, Wenhao and Wei, Zhipeng and Cui, Can and Tang, Cheng and Zhang, Liang and Zhuang, Yueting , booktitle =. 2025 , eprint =
work page 2025
-
[5]
Rukhovich, Danila and Kolodiazhnyi, Kyrylo and Aouada, Djamila , booktitle =
-
[6]
Kolodiazhnyi, Kyrylo and Rukhovich, Danila and Aouada, Djamila , booktitle =
-
[7]
Elistratov, Maksim and Barannikov, Marina and Ivanov, Gregory and Khrulkov, Valentin and Konushin, Anton and Kuznetsov, Andrey and Zhemchuzhnikov, Dmitrii , year =. 2602.16317 , archivePrefix =
-
[8]
Alrashedy, Khaled and others , booktitle =
-
[9]
Yang, Sihan and Xu, Runsen and Xie, Yiman and Yang, Sizhe and Li, Mo and Lin, Jingli and Zhu, Chenming and Chen, Xiaochen and Duan, Haodong and Yue, Xiangyu and Lin, Dahua and Wang, Tai and Pang, Jiangmiao , booktitle =. 2026 , eprint =
work page 2026
-
[10]
Chou, Jason and Liu, Ao and Deng, Yuchi and Zeng, Zhiying and Zhang, Tao and Zhu, Haotian and Cai, Jianwei and Mao, Yue and Zhang, Chenchen and Tan, Lingyun and Xu, Ziyan and Zhai, Bohui and Liu, Hengyi and Zhu, Speed and Zhou, Wiggin and Lian, Fengzong , year =. 2508.09101 , archivePrefix =
-
[11]
Yuan, Yu and Sun, Shizhao and Liu, Qi and Bian, Jiang , booktitle =. 2025 , eprint =
work page 2025
-
[12]
and Company, Pedro , journal =
Zhou, Jiwei and Camba, Jorge D. and Company, Pedro , journal =. 2025 , doi =
work page 2025
-
[13]
Dong, Xintong and others , year =. 2602.19171 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Croissant: A Metadata Format for
Akhtar, Mubashara and others , booktitle =. Croissant: A Metadata Format for
-
[15]
2024 , howpublished =
work page 2024
-
[16]
Bai, Shuai and others , year =. 2511.21631 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Chen, Zhe and others , year =. 2504.10479 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Chandiramani, Abhishek and others , year =. 2604.12374 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.