Recognition: 2 theorem links
· Lean TheoremRemember the Decision, Not the Description: A Rate-Distortion Framework for Agent Memory
Pith reviewed 2026-05-12 03:34 UTC · model grok-4.3
The pith
Agent memory should preserve distinctions between histories that lead to different decisions, not descriptive summaries of the past.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Memory quality is defined by the reduction in achievable decision quality caused by compression. This decision-centric rate-distortion formulation identifies a precise forgetting boundary for histories that can be merged without harming future choices and characterizes the optimal memory-distortion frontier. The resulting online learner, DeMem, refines its partition only on certified decision conflicts and carries near-minimax regret guarantees.
What carries the argument
The decision-centric rate-distortion problem whose distortion measure is the loss in decision quality induced by merging histories; the online partition refinement rule that updates only when data certify a decision conflict.
If this is right
- Memory systems can be equipped with an exact, computable boundary for what can be safely forgotten without reducing future decision quality.
- An optimal frontier exists that trades memory size directly against the highest attainable decision performance.
- Online refinement triggered only by observed decision conflicts suffices to achieve near-minimax regret in memory management.
- Under fixed runtime budgets, decision-centric memory yields measurable gains on both synthetic diagnostics and long-horizon conversational tasks.
Where Pith is reading between the lines
- The same decision-distinction principle could be applied to other resource-constrained sequential decision settings such as planning or control where histories must be distinguished only when they change optimal actions.
- If decision quality loss can be estimated from samples, the framework suggests a way to audit existing memory modules in deployed agents by measuring how much their compression raises decision error.
- Testing whether the forgetting boundary remains stable when the underlying decision model changes online would clarify how robust the approach is to non-stationary environments.
Load-bearing premise
The loss in decision quality caused by any given memory compression can be quantified, and the online rule that refines partitions only on certified decision conflicts yields near-minimax regret without prior knowledge of the environment or the decision model.
What would settle it
A controlled experiment in which a descriptive memory baseline matches or exceeds DeMem's decision quality under identical budget limits, or in which DeMem's observed regret exceeds the claimed near-minimax bound on a sequence of tasks where decision conflicts are fully observable.
Figures

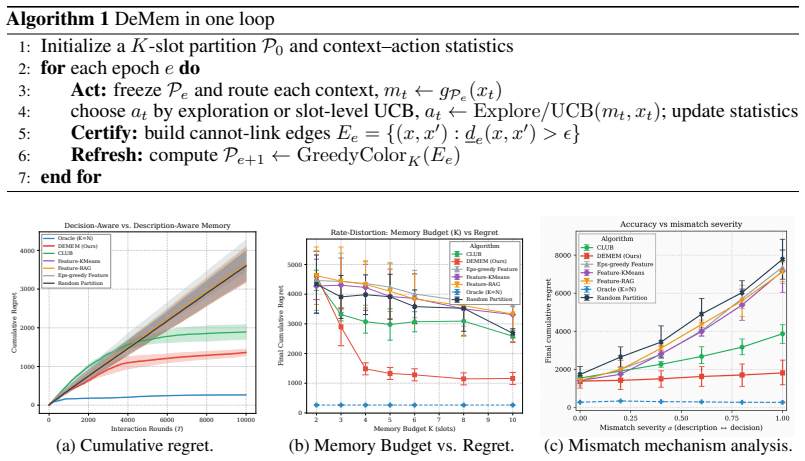
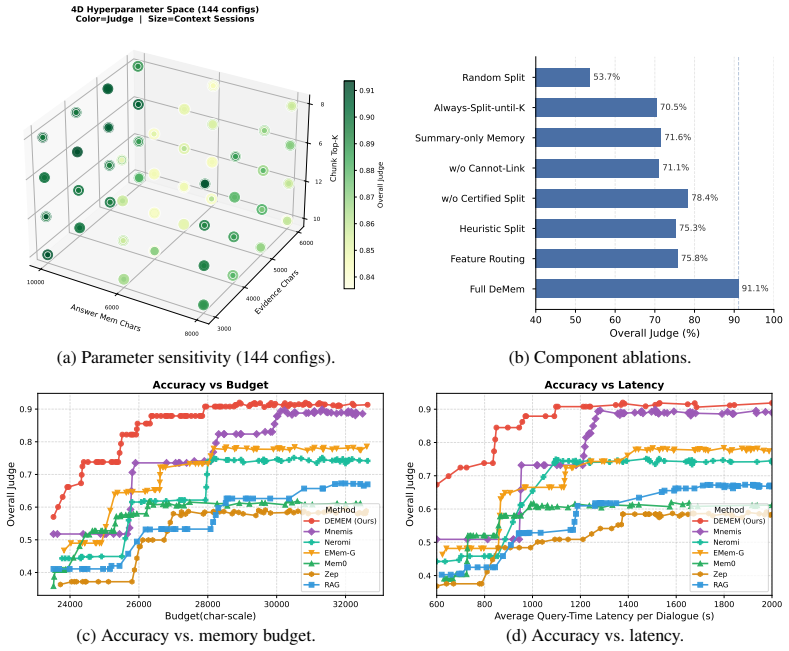

read the original abstract
Long-horizon language agents must operate under limited runtime memory, yet existing memory mechanisms often organize experience around descriptive criteria such as relevance, salience, or summary quality. For an agent, however, memory is valuable not because it faithfully describes the past, but because it preserves the distinctions between histories that must remain separated under a fixed budget to support good decisions. We cast this as a decision-centric rate-distortion problem, measuring memory quality by the loss in achievable decision quality induced by compression. This yields an exact forgetting boundary for what can be safely forgotten, and a memory-distortion frontier characterizing the optimal tradeoff between memory budget and decision quality. Motivated by this decision-centric view of memory, we propose DeMem, an online memory learner that refines its partition only when data certify that a shared state would induce decision conflict, and prove near-minimax regret guarantees. On both controlled synthetic diagnostics and long-horizon conversational benchmarks, DeMem yields consistent gains under the same runtime budget, supporting the principle that memory should preserve the distinctions that matter for decisions, not descriptions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper frames agent memory as a decision-centric rate-distortion problem, where compression quality is defined by the induced loss in achievable decision quality rather than descriptive fidelity. It derives an exact forgetting boundary and a memory-distortion frontier, then introduces DeMem—an online algorithm that refines its state partition only upon data-certified decision conflicts—and claims near-minimax regret guarantees for this procedure. Empirical results on synthetic diagnostics and long-horizon conversational tasks show improved decision performance under fixed memory budgets compared to relevance- or summary-based baselines.
Significance. If the regret bounds and boundary derivations hold under the stated conditions, the work offers a principled alternative to heuristic memory mechanisms in long-horizon agents, with potential to reduce unnecessary retention of descriptively salient but decision-irrelevant history. The explicit tradeoff frontier and online refinement rule could inform resource allocation in deployed systems; the empirical consistency across controlled and realistic settings strengthens the case for decision-quality as the relevant distortion measure.
major comments (2)
- [§4 (DeMem algorithm and regret analysis)] The near-minimax regret claim for DeMem (abstract and §4) rests on the online partition refinement rule triggering only on certified decision conflicts without prior knowledge of the decision model or environment. The manuscript does not provide the explicit certification procedure or the additional assumptions (e.g., finite state space, observable loss, or Lipschitz continuity) needed to ensure the bound holds for arbitrary environments; without these, the guarantee does not follow from the stated rule alone.
- [§3 (rate-distortion framework)] The exact forgetting boundary and memory-distortion frontier (abstract and §3) are presented as following directly from the decision-centric rate-distortion formulation, yet the derivation steps, assumption list, and mapping from compression to decision-quality loss are not shown in sufficient detail to verify that the boundary is parameter-free or that the frontier is tight for general decision models.
minor comments (2)
- [§4] Notation for the partition refinement and conflict certification (e.g., how 'data certify' is operationalized) should be defined more explicitly with pseudocode or a formal definition to aid reproducibility.
- [§5] The experimental section would benefit from reporting the precise memory budget values and quantitative regret or decision-quality metrics alongside the qualitative 'consistent gains' statement.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments on our manuscript. We address each major comment below with clarifications on the existing content and indicate planned revisions to enhance clarity without altering the core contributions.
read point-by-point responses
-
Referee: [§4 (DeMem algorithm and regret analysis)] The near-minimax regret claim for DeMem (abstract and §4) rests on the online partition refinement rule triggering only on certified decision conflicts without prior knowledge of the decision model or environment. The manuscript does not provide the explicit certification procedure or the additional assumptions (e.g., finite state space, observable loss, or Lipschitz continuity) needed to ensure the bound holds for arbitrary environments; without these, the guarantee does not follow from the stated rule alone.
Authors: We appreciate the referee highlighting the need for explicit details on the regret analysis. The certification procedure is defined in §4 (Algorithm 1) as testing whether merging histories would produce differing optimal actions via empirical value estimates computed from post-decision observed losses; this uses only online data and requires no prior environment knowledge. Theorem 4.1 states the near-minimax regret under the assumptions of finite partition cardinality, fully observable losses, and Lipschitz continuity of the decision model with respect to the state metric. The bound is not claimed to hold for completely arbitrary environments lacking these properties. To address the concern, we will add a dedicated paragraph in the revised §4 that enumerates all assumptions explicitly, includes the full certification pseudocode, and provides a brief proof sketch linking the refinement rule to the regret bound. This is a partial revision, as the elements exist in the current manuscript but will be made more self-contained. revision: partial
-
Referee: [§3 (rate-distortion framework)] The exact forgetting boundary and memory-distortion frontier (abstract and §3) are presented as following directly from the decision-centric rate-distortion formulation, yet the derivation steps, assumption list, and mapping from compression to decision-quality loss are not shown in sufficient detail to verify that the boundary is parameter-free or that the frontier is tight for general decision models.
Authors: We thank the referee for this observation on the framework derivations. In §3, the forgetting boundary is obtained by showing that two histories belong to the same equivalence class (and can thus be merged) precisely when they induce identical optimal action distributions under the decision-centric distortion measure; this yields a parameter-free boundary depending only on decision equivalence rather than descriptive features. The memory-distortion frontier is characterized as the lower convex envelope of achievable (rate, distortion) pairs, where distortion is the expected loss in decision value induced by the compressed representation. The mapping is formalized via the difference between the value function on the original and compressed state spaces. We acknowledge that intermediate steps and the assumption list could be expanded for easier verification. In the revision we will insert a step-by-step derivation in §3, an explicit assumption list (including bounded decision losses and ergodicity of the underlying process), and an argument establishing tightness for general decision models. This will be incorporated as a revision. revision: yes
Circularity Check
No significant circularity; derivation applies standard rate-distortion to an externally motivated distortion measure and invokes external RL regret analysis.
full rationale
The paper defines memory quality via loss in decision quality under compression, yielding a forgetting boundary and distortion frontier as direct consequences of the rate-distortion formulation with that measure. DeMem's partition-refinement rule and near-minimax regret claim are motivated by this view but rest on the online conflict-certification procedure plus standard minimax regret results from RL theory for unknown environments. No step reduces by construction to a fitted parameter, self-citation chain, or renamed input; the central claims retain independent content once the decision-loss distortion and external regret bounds are granted. The derivation is therefore self-contained against the paper's stated modeling assumptions.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 1 (Exact forgetting boundary). Fix a query q, ε≥0 and a nonempty C⊆Xq. The following are equivalent: 1. There exists a∈A with Δq(h,a)≤ε for all h∈C. 2. There exists a one-state encoder on C and a deterministic decision rule whose worst-case distortion over C is at most ε.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We cast this as a decision-centric rate-distortion problem, measuring memory quality by the loss in achievable decision quality induced by compression. This yields an exact forgetting boundary... and a memory-distortion frontier
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Ellis Hershkowitz, and Michael L
David Abel, D. Ellis Hershkowitz, and Michael L. Littman. Near optimal behavior via approxi- mate state abstraction, 2017. URLhttps://arxiv.org/abs/1701.04113
-
[2]
State abstractions for lifelong reinforcement learning
David Abel, Dilip Arumugam, Lucas Lehnert, and Michael Littman. State abstractions for lifelong reinforcement learning. InProceedings of the 35th International Conference on Machine Learning, 2018
work page 2018
-
[3]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building production-ready ai agents with scalable long-term memory, 2025. URL https: //arxiv.org/abs/2504.19413
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Pengfei Du. Memory for autonomous LLM agents:mechanisms, evaluation, and emerging frontiers, 2026. URLhttps://arxiv.org/abs/2603.07670
-
[5]
Pan, Yuxin Jiang, and Kam-Fai Wong
Yiming Du, Baojun Wang, Yifan Xiang, Zhaowei Wang, Wenyu Huang, Boyang XUE, Bin Liang, Xingshan Zeng, Fei Mi, Haoli Bai, Lifeng Shang, Jeff Z. Pan, Yuxin Jiang, and Kam-Fai Wong. Memory-t1: Reinforcement learning for temporal reasoning in multi-session agents. In The Fourteenth International Conference on Learning Representations, 2026. URL https: //openr...
work page 2026
-
[6]
Norm Ferns, Prakash Panangaden, and Doina Precup. Bisimulation metrics for continuous markov decision processes.SIAM Journal on Computing, 40(6):1662–1714, 2011. doi: 10. 1137/10080484X. URLhttps://doi.org/10.1137/10080484X
-
[7]
Online clustering of bandits, 2014
Claudio Gentile, Shuai Li, and Giovanni Zappella. Online clustering of bandits, 2014. URL https://arxiv.org/abs/1401.8257
-
[8]
Robert Givan, Thomas Dean, and Matthew Greig. Equivalence notions and model minimization in markov decision processes.Artificial Intelligence, 147(1):163–223, 2003. ISSN 0004-3702. doi: https://doi.org/10.1016/S0004-3702(02)00376-4. URL https://www.sciencedirect. com/science/article/pii/S0004370202003764. Planning with Uncertainty and Incom- plete Information
-
[9]
Hipporag: Neurobiologically inspired long-term memory for large language models,
Bernal Jiménez Gutiérrez, Yiheng Shu, Yu Gu, Michihiro Yasunaga, and Yu Su. Hipporag: Neurobiologically inspired long-term memory for large language models, 2025. URL https: //arxiv.org/abs/2405.14831
-
[10]
Memoryarena: Benchmarking agent memory in interdependent multi-session agentic tasks,
Zexue He, Yu Wang, Churan Zhi, Yuanzhe Hu, Tzu-Ping Chen, Lang Yin, Ze Chen, Tong Arthur Wu, Siru Ouyang, Zihan Wang, Jiaxin Pei, Julian McAuley, Yejin Choi, and Alex Pentland. Memoryarena: Benchmarking agent memory in interdependent multi-session agentic tasks,
- [11]
-
[12]
Evaluating memory in LLM agents via in- cremental multi-turn interactions
Yuanzhe Hu, Yu Wang, and Julian McAuley. Evaluating memory in LLM agents via in- cremental multi-turn interactions. InThe Fourteenth International Conference on Learning Representations, 2026. URLhttps://openreview.net/forum?id=DT7JyQC3MR
work page 2026
-
[13]
Memory in the age of ai agents,
Yuyang Hu, Shichun Liu, Yanwei Yue, Guibin Zhang, Boyang Liu, Fangyi Zhu, Jiahang Lin, Honglin Guo, Shihan Dou, Zhiheng Xi, Senjie Jin, Jiejun Tan, Yanbin Yin, Jiongnan Liu, Zeyu Zhang, Zhongxiang Sun, Yutao Zhu, Hao Sun, Boci Peng, Zhenrong Cheng, Xuanbo Fan, Jiaxin Guo, Xinlei Yu, Zhenhong Zhou, Zewen Hu, Jiahao Huo, Junhao Wang, Yuwei Niu, Yu Wang, Zhe...
-
[14]
URLhttps://arxiv.org/abs/2512.13564. 10
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Atommem : Learnable dynamic agentic memory with atomic memory operation, 2026
Yupeng Huo, Yaxi Lu, Zhong Zhang, Haotian Chen, and Yankai Lin. Atommem : Learnable dynamic agentic memory with atomic memory operation, 2026. URL https://arxiv.org/ abs/2601.08323
-
[16]
Jiazheng Kang, Mingming Ji, Zhe Zhao, and Ting Bai. Memory OS of AI agent. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 25961– 25970, Suzhou, China, November 2025. Association for Computational Linguistics. ISBN 979- ...
-
[17]
Langmem: Long-term memory sdk for LLM agents, 2024
LangChain AI. Langmem: Long-term memory sdk for LLM agents, 2024. URL https: //github.com/langchain-ai/langmem
work page 2024
-
[18]
Chris Latimer, Nicoló Boschi, Andrew Neeser, Chris Bartholomew, Gaurav Srivastava, Xuan Wang, and Naren Ramakrishnan. Hindsight is 20/20: Building agent memory that retains, recalls, and reflects, 2025. URLhttps://arxiv.org/abs/2512.12818
-
[19]
Meta-Harness: End-to-End Optimization of Model Harnesses
Yoonho Lee, Roshen Nair, Qizheng Zhang, Kangwook Lee, Omar Khattab, and Chelsea Finn. Meta-harness: End-to-end optimization of model harnesses, 2026. URL https://arxiv.org/ abs/2603.28052
work page internal anchor Pith review arXiv 2026
-
[20]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive nlp tasks, 2021. URL https://arxiv.org/abs/2005.11401
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[21]
Lihong Li, Thomas J. Walsh, and Michael L. Littman. Towards a unified theory of state ab- straction for mdps. InAI&M, 2006. URL https://api.semanticscholar.org/CorpusID: 245037
work page 2006
-
[22]
arXiv preprint arXiv:2602.10715 , year=
Yifei Li, Weidong Guo, Lingling Zhang, Rongman Xu, Muye Huang, Hui Liu, Lijiao Xu, Yu Xu, and Jun Liu. Locomo-plus: Beyond-factual cognitive memory evaluation framework for LLM agents, 2026. URLhttps://arxiv.org/abs/2602.10715
-
[23]
Lost in the Middle: How Language Models Use Long Contexts
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts, 2023. URL https://arxiv.org/abs/2307.03172
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Evaluating Very Long-Term Conversational Memory of
Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. Evaluating very long-term conversational memory of LLM agents. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13851–13870. Associ...
-
[25]
David W. Matula and Leland L. Beck. Smallest-last ordering and clustering and graph coloring algorithms.J. ACM, 30(3):417–427, July 1983. ISSN 0004-5411. doi: 10.1145/2402.322385. URLhttps://doi.org/10.1145/2402.322385
-
[26]
What Deserves Memory: Adaptive Memory Distillation for LLM Agents
Jiayan Nan, Wenquan Ma, Wenlong Wu, and Yize Chen. Nemori: Self-organizing agent memory inspired by cognitive science, 2025. URLhttps://arxiv.org/abs/2508.03341
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [27]
-
[28]
Task-driven estimation and control via information bottlenecks
Vincent Pacelli and Anirudha Majumdar. Task-driven estimation and control via information bottlenecks. In2019 International Conference on Robotics and Automation (ICRA), pages 2061–2067, 2019. doi: 10.1109/ICRA.2019.8794213
-
[29]
MemGPT: Towards LLMs as Operating Systems
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. Memgpt: Towards LLMs as operating systems, 2024. URL https: //arxiv.org/abs/2310.08560. 11
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Natural-Language Agent Harnesses
Linyue Pan, Lexiao Zou, Shuo Guo, Jingchen Ni, and Hai-Tao Zheng. Natural-language agent harnesses, 2026. URLhttps://arxiv.org/abs/2603.25723
-
[31]
Clawvm: Harness-managed virtual memory for stateful tool-using LLM agents
Mofasshara Rafique and Laurent Bindschaedler. Clawvm: Harness-managed virtual memory for stateful tool-using LLM agents. 2026. URL https://api.semanticscholar.org/ CorpusID:287432731
work page 2026
-
[32]
Zep: A Temporal Knowledge Graph Architecture for Agent Memory
Preston Rasmussen, Pavlo Paliychuk, Travis Beauvais, Jack Ryan, and Daniel Chalef. Zep: A temporal knowledge graph architecture for agent memory, 2025. URL https://arxiv.org/ abs/2501.13956
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Approximate homomorphisms: A framework for non-exact minimization in markov decision processes
Balaraman Ravindran and Andrew G Barto. Approximate homomorphisms: A framework for non-exact minimization in markov decision processes. 2004
work page 2004
-
[34]
Continuous mdp homomorphisms and homomorphic policy gradient, 2022
Sahand Rezaei-Shoshtari, Rosie Zhao, Prakash Panangaden, David Meger, and Doina Precup. Continuous mdp homomorphisms and homomorphic policy gradient, 2022. URL https: //arxiv.org/abs/2209.07364
-
[35]
Yiting Shen, Kun Li, Wei Zhou, and Songlin Hu. Mem2actbench: A benchmark for evaluating long-term memory utilization in task-oriented autonomous agents, 2026. URL https:// arxiv.org/abs/2601.19935
-
[36]
Reflexion: Language Agents with Verbal Reinforcement Learning
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning, 2023. URL https://arxiv.org/abs/2303.11366
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
REMem: Reasoning with episodic memory in language agent
Yiheng Shu, Saisri Padmaja Jonnalagedda, Xiang Gao, Bernal Jiménez Gutiérrez, Weijian Qi, Kamalika Das, Huan Sun, and Yu Su. REMem: Reasoning with episodic memory in language agent. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=fugnQxbvMm
work page 2026
-
[38]
Simão, Marnix Suilen, and Nils Jansen
Thiago D. Simão, Marnix Suilen, and Nils Jansen. Safe policy improvement for pomdps via finite-state controllers, 2023. URLhttps://arxiv.org/abs/2301.04939
-
[39]
Decision-centric design for LLM systems
Wei Sun. Decision-centric design for LLM systems. 2026. URL https://api. semanticscholar.org/CorpusID:287021773
work page 2026
-
[40]
Membench: Towards more comprehensive evaluation on the memory of llm-based agents, 2025
Haoran Tan, Zeyu Zhang, Chen Ma, Xu Chen, Quanyu Dai, and Zhenhua Dong. Membench: Towards more comprehensive evaluation on the memory of LLM-based agents, 2025. URL https://arxiv.org/abs/2506.21605
-
[41]
Mnemis: Dual-Route Retrieval on Hierarchical Graphs for Long-Term LLM Memory
Zihao Tang, Xin Yu, Ziyu Xiao, Zengxuan Wen, Zelin Li, Jiaxi Zhou, Hualei Wang, Haohua Wang, Haizhen Huang, Weiwei Deng, Feng Sun, and Qi Zhang. Mnemis: Dual-route retrieval on hierarchical graphs for long-term LLM memory, 2026. URL https://arxiv.org/abs/ 2602.15313
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[42]
Augmenting language models with long-term memory
Weizhi Wang, Li Dong, Hao Cheng, Xiaodong Liu, Xifeng Yan, Jianfeng Gao, and Furu Wei. Augmenting language models with long-term memory. In A. Oh, T. Nau- mann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neu- ral Information Processing Systems, volume 36, pages 74530–74543. Curran Associates, Inc., 2023. URL https://proceedings....
work page 2023
-
[43]
LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory
Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, Kai-Wei Chang, and Dong Yu. Long- memeval: Benchmarking chat assistants on long-term interactive memory, 2025. URL https://arxiv.org/abs/2410.10813
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
A-MEM: Agentic Memory for LLM Agents
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. A-mem: Agentic memory for LLM agents, 2025. URLhttps://arxiv.org/abs/2502.12110
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models, 2023. URL https: //arxiv.org/abs/2210.03629. 12
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[46]
Yi Yu, Liuyi Yao, Yuexiang Xie, Qingquan Tan, Jiaqi Feng, Yaliang Li, and Libing Wu. Agentic memory: Learning unified long-term and short-term memory management for large language model agents, 2026. URLhttps://arxiv.org/abs/2601.01885
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[47]
URLhttps://arxiv.org/abs/2512.18746
Guibin Zhang, Haotian Ren, Chong Zhan, Zhenhong Zhou, Junhao Wang, He Zhu, Wangchun- shu Zhou, and Shuicheng Yan. Memevolve: Meta-evolution of agent memory systems, 2025. URLhttps://arxiv.org/abs/2512.18746
-
[48]
Memgen: Weaving generative latent memory for self-evolving agents
Guibin Zhang, Muxin Fu, and Shuicheng Y AN. Memgen: Weaving generative latent memory for self-evolving agents. InThe Fourteenth International Conference on Learning Representations,
-
[49]
URLhttps://openreview.net/forum?id=vI56m4Iu4e
-
[50]
MemSkill: Learning and Evolving Memory Skills for Self-Evolving Agents
Haozhen Zhang, Quanyu Long, Jianzhu Bao, Tao Feng, Weizhi Zhang, Haodong Yue, and Wenya Wang. Memskill: Learning and evolving memory skills for self-evolving agents, 2026. URLhttps://arxiv.org/abs/2602.02474
work page internal anchor Pith review arXiv 2026
-
[51]
Min Zhang, Hongyao Tang, Jianye Hao, and Yan Zheng. Towards a unified policy abstraction theory and representation learning approach in markov decision processes, 2022. URL https: //arxiv.org/abs/2209.07696
-
[52]
Memory as Action: Autonomous Context Curation for Long-Horizon Agentic Tasks
Yuxiang Zhang, Jiangming Shu, Ye Ma, Xueyuan Lin, Shangxi Wu, and Jitao Sang. Memory as action: Autonomous context curation for long-horizon agentic tasks, 2026. URL https: //arxiv.org/abs/2510.12635
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[53]
A survey on the memory mechanism of large language model based agents,
Zeyu Zhang, Xiaohe Bo, Chen Ma, Rui Li, Xu Chen, Quanyu Dai, Jieming Zhu, Zhenhua Dong, and Ji-Rong Wen. A survey on the memory mechanism of large language model based agents,
-
[54]
URLhttps://arxiv.org/abs/2404.13501
work page internal anchor Pith review arXiv
-
[55]
Externalization in LLM Agents: A Unified Review of Memory, Skills, Protocols and Harness Engineering
Chenyu Zhou, Huacan Chai, Wenteng Chen, Zihan Guo, Rong Shan, Yuanyi Song, Tianyi Xu, Yingxuan Yang, Aofan Yu, Weiming Zhang, Congming Zheng, Jiachen Zhu, Zeyu Zheng, Zhu- osheng Zhang, Xingyu Lou, Changwang Zhang, Zhihui Fu, Jun Wang, Weiwen Liu, Jianghao Lin, and Weinan Zhang. Externalization in LLM agents: A unified review of memory, skills, protocols ...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[56]
A simple yet strong baseline for long-term conversational memory of LLM agents, 2025
Sizhe Zhou and Jiawei Han. A simple yet strong baseline for long-term conversational memory of LLM agents, 2025. URLhttps://arxiv.org/abs/2511.17208
-
[57]
MEM1: Learning to synergize memory and reasoning for efficient long-horizon agents
Zijian Zhou, Ao Qu, Zhaoxuan Wu, Sunghwan Kim, Alok Prakash, Daniela Rus, Bryan Kian Hsiang Low, and Paul Pu Liang. MEM1: Learning to synergize memory and reasoning for efficient long-horizon agents. InThe Fourteenth International Conference on Learning Representations, 2026. URLhttps://openreview.net/forum?id=XY8AaxDSLb. 13 A Additional Preliminaries and...
work page 2026
-
[58]
Policy πϕ, whose downstream behavior is conditioned on the selected slot and its maintained state realization. Memory control versus downstream decision.It is important to separate memory control from task decision. Routing, slot reading, slot updating, and certified splitting are memory operations that implement the encoder and state-maintenance mechanis...
work page 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.