Recognition: 2 theorem links
· Lean TheoremCADBench: A Multimodal Benchmark for AI-Assisted CAD Program Generation
Pith reviewed 2026-05-12 04:27 UTC · model grok-4.3
The pith
Specialized mesh-to-CAD models recover editable programs more reliably than general vision-language models from clean 3D inputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
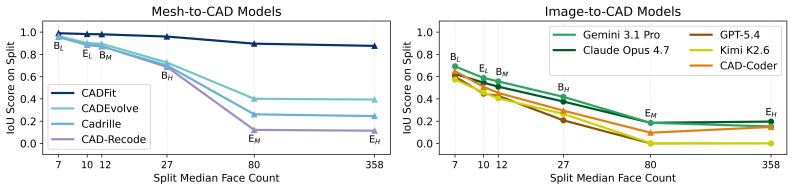
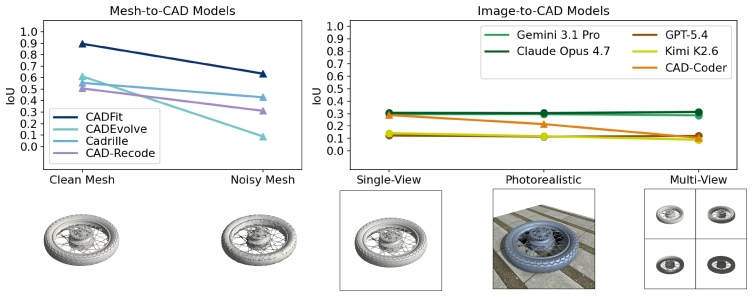
CADBench supplies 18,000 evaluation samples drawn from six dataset families, stratified by B-rep face count and diversity-sampled, across five input modalities and six metrics. Under idealized inputs, specialized mesh-to-CAD models substantially outperform code-generating VLMs, which remain far from reliable CAD program reconstruction. The benchmark also shows that reconstruction quality degrades with geometric complexity, that CAD-specialized models can be brittle under modality shift, and that model rankings change across metrics.
What carries the argument
CADBench, the unified collection of datasets, modalities, and metrics that enables controlled measurement of geometric fidelity, executability, and program compactness in CAD program generation.
If this is right
- Reconstruction quality falls as geometric complexity, measured by B-rep face count, rises.
- CAD-specialized models lose performance when inputs shift from clean meshes to photorealistic or multi-view renders.
- Which model appears strongest depends on the chosen metric among geometric fidelity, executability, and compactness.
- General vision-language models are currently far from reliable CAD program reconstruction even on idealized inputs.
- A shared benchmark allows consistent tracking of advances in multimodal CAD understanding and editable 3D reconstruction.
Where Pith is reading between the lines
- Future models might combine the precision of specialized CAD systems with the flexibility of vision-language models to handle modality shifts.
- Extending the benchmark with more noisy real-world captures could better test robustness needed for practical design tools.
- The observed failure modes point to a need for training objectives that explicitly reward compactness and editability.
- Adoption of CADBench as a standard test set could reduce fragmentation in evaluations of 3D-to-CAD methods.
Load-bearing premise
The chosen datasets, their stratification by B-rep face count, diversity sampling, and the six metrics together provide a representative and controlled measure of real-world CAD program generation performance across modalities.
What would settle it
A new model that scores high on all CADBench metrics and modalities yet produces non-executable or non-editable programs when loaded into standard CAD software would show the benchmark does not track practical utility.
Figures







read the original abstract
Recovering editable CAD programs from images or 3D observations is central to AI-assisted design, but progress is difficult to measure because existing evaluations are fragmented across datasets, modalities, and metrics. We introduce CADBench, a unified benchmark for multimodal CAD program generation. CADBench contains 18,000 evaluation samples spanning six benchmark families derived from DeepCAD, Fusion 360, ABC, MCB, and Objaverse; five input modalities including clean meshes, noisy meshes, single-view renders, photorealistic renders, and multi-view renders; and six metrics covering geometric fidelity, executability, and program compactness. STEP-based families are stratified by B-rep face count and all families are diversity-sampled to support controlled analysis across complexity and object variation. We benchmark eleven CAD-specialized and general-purpose vision-language systems, generating more than 1.4 million CAD programs. Under idealized inputs, specialized mesh-to-CAD models substantially outperform code-generating VLMs, which remain far from reliable CAD program reconstruction. CADBench further reveals three recurring failure modes: reconstruction quality degrades with geometric complexity, CAD-specialized models can be brittle under modality shift, and model rankings change across metrics. Together, these results position CADBench as a diagnostic testbed for measuring progress in editable 3D reconstruction and multimodal CAD understanding. The benchmark is publicly available at https://huggingface.co/datasets/DeCoDELab/CADBench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CADBench, a unified multimodal benchmark for CAD program generation with 18,000 evaluation samples drawn from six families (DeepCAD, Fusion 360, ABC, MCB, Objaverse). It spans five input modalities (clean meshes, noisy meshes, single-view renders, photorealistic renders, multi-view renders) and six metrics (geometric fidelity, executability, program compactness). Eleven models are evaluated via 1.4 million generated programs, showing that specialized mesh-to-CAD models substantially outperform code-generating VLMs under idealized inputs, while revealing recurring failure modes: quality degrades with geometric complexity, CAD models are brittle to modality shift, and rankings vary by metric. The benchmark is released publicly.
Significance. If the evaluation controls hold, CADBench supplies a much-needed standardized, diagnostic testbed for editable 3D reconstruction and multimodal CAD understanding, directly addressing fragmentation in prior evaluations and enabling controlled analysis of complexity and modality effects.
major comments (2)
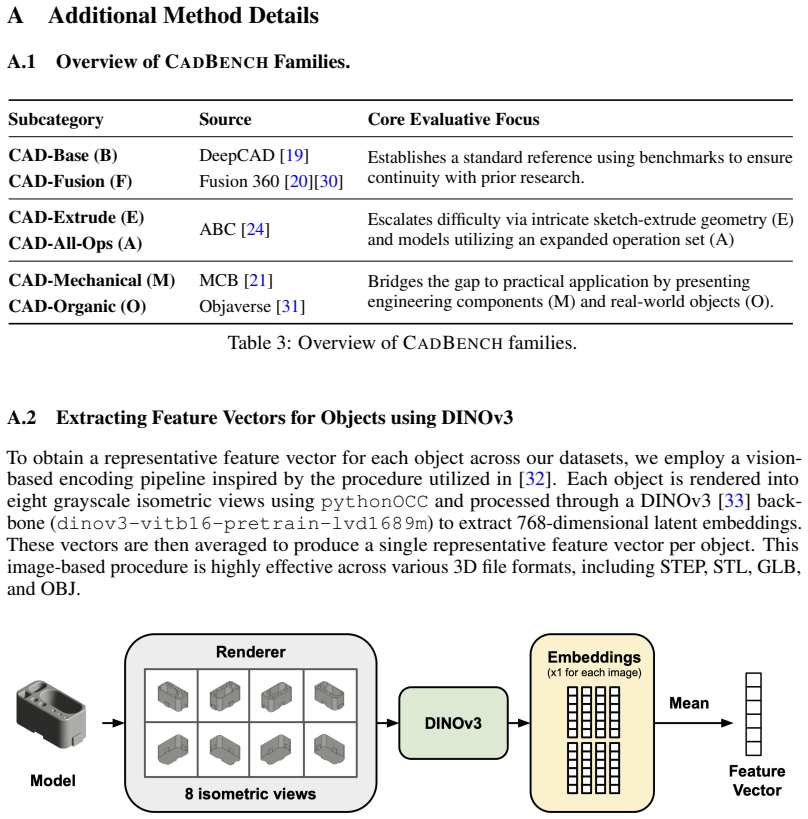
- [Abstract and §3] Abstract and §3 (dataset construction): B-rep face count stratification is applied only to STEP-based families, while mesh families (Objaverse, MCB) that supply the clean-mesh modality for the idealized-input comparisons receive only diversity sampling with no equivalent complexity proxy (face/edge count, curvature, or bounding-box statistics). This leaves open the possibility that reported performance gaps between specialized mesh-to-CAD models and VLMs are confounded by uncontrolled differences in geometric complexity distributions rather than modality or architecture.
- [Results and §4] Results and §4 (benchmarking): The headline claim that VLMs remain 'far from reliable' and the quantitative outperformance margins rest on the assumption that the six metrics and stratification together isolate model capability; without explicit per-family complexity statistics or ablation on complexity-matched subsets for non-STEP families, the support for these conclusions is weakened.
minor comments (3)
- [§3.2] §3.2: The precise algorithm and parameters used for diversity sampling across all families should be stated explicitly (e.g., embedding model, distance metric, target distribution) to allow exact reproduction of the 18,000-sample split.
- [Tables 2–4] Tables 2–4: Column headers and captions should clarify which families contribute to each modality column so that readers can immediately see the contribution of stratified vs. unstratified families to each reported score.
- [§5] §5: A short discussion of how the six metrics were chosen and whether any were post-hoc selected after seeing results would strengthen transparency.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on CADBench. The comments highlight important considerations for strengthening the controls on geometric complexity in our dataset construction and benchmarking analysis. We address each major comment below and have prepared revisions to incorporate additional statistics and ablations.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (dataset construction): B-rep face count stratification is applied only to STEP-based families, while mesh families (Objaverse, MCB) that supply the clean-mesh modality for the idealized-input comparisons receive only diversity sampling with no equivalent complexity proxy (face/edge count, curvature, or bounding-box statistics). This leaves open the possibility that reported performance gaps between specialized mesh-to-CAD models and VLMs are confounded by uncontrolled differences in geometric complexity distributions rather than modality or architecture.
Authors: We thank the referee for identifying this potential source of confounding. The manuscript applies B-rep face count stratification to STEP-based families because it is a direct and standard proxy for CAD complexity in those native representations. All families, including Objaverse and MCB, were diversity-sampled to ensure broad coverage of object variation. However, we agree that mesh families lack an equivalent explicit proxy in the current presentation, which could affect interpretation of the idealized-input comparisons. In the revised manuscript, we will add per-family statistics on mesh face counts, edge counts, and bounding-box volumes for Objaverse and MCB in §3, along with a description of how diversity sampling was tuned to balance these measures. This will allow direct comparison of complexity distributions across modalities. revision: yes
-
Referee: [Results and §4] Results and §4 (benchmarking): The headline claim that VLMs remain 'far from reliable' and the quantitative outperformance margins rest on the assumption that the six metrics and stratification together isolate model capability; without explicit per-family complexity statistics or ablation on complexity-matched subsets for non-STEP families, the support for these conclusions is weakened.
Authors: We acknowledge that stronger evidence for isolating model capability would benefit from explicit complexity controls on non-STEP families. Diversity sampling and the multi-metric evaluation were designed to support controlled analysis, but we agree that the absence of per-family statistics and matched-subset ablations for mesh families weakens the quantitative claims. In the revision, we will include the complexity statistics noted above in §3 and §4. We will also add an ablation on complexity-matched subsets (using mesh face count bins for Objaverse/MCB and B-rep face count bins for STEP families) to verify that performance gaps between specialized models and VLMs persist under matched conditions. These additions will be reported with updated figures and tables. revision: yes
Circularity Check
No circularity: empirical benchmark with public data and external model evaluations
full rationale
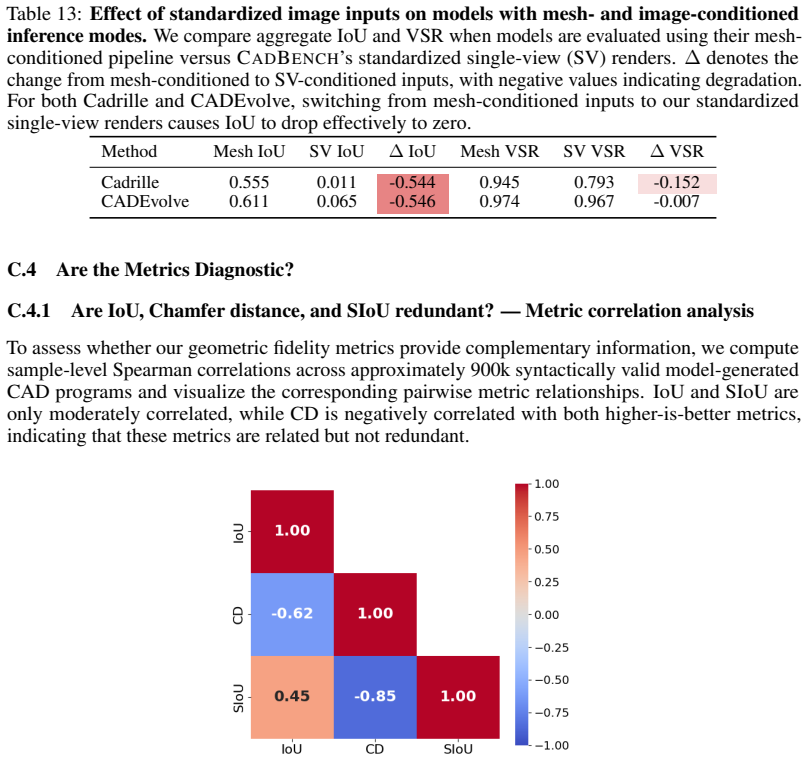
The paper introduces a new multimodal benchmark (CADBench) by aggregating and stratifying existing datasets (DeepCAD, Fusion 360, ABC, MCB, Objaverse) into 18,000 samples across modalities and metrics, then evaluates 11 external models on them. No mathematical derivation, parameter fitting, or first-principles prediction is present; all claims rest on direct empirical measurement against public data and third-party systems. Stratification by B-rep face count applies only to STEP families as stated, but this is an explicit design choice for controlled analysis rather than a self-referential reduction. No self-citation chains, ansatzes, or renamings of prior results occur. The work is self-contained as a diagnostic testbed release.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Existing datasets (DeepCAD, Fusion 360, ABC, MCB, Objaverse) contain sufficient variety and can be stratified by B-rep face count for controlled evaluation.
- domain assumption Geometric fidelity, executability, and program compactness are appropriate and sufficient metrics for assessing CAD program quality.
Lean theorems connected to this paper
-
IndisputableMonolith.Cost.FunctionalEquationwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We benchmark eleven CAD-specialized and general-purpose vision-language systems, generating more than 1.4 million CAD programs.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Rajkumar Roy, Sara Kelvesjo, Sara Forsberg, and Chris Rush. Quantitative and qualitative cost estimating for engineering design.Journal of Engineering Design, 12(2):147–162, 2001
work page 2001
-
[2]
Large language models for computer-aided design: A survey.ACM Computing Surveys, 58(9):1–39, 2026
Licheng Zhang, Bach Le, Naveed Akhtar, Siew-Kei Lam, and Duc Ngo. Large language models for computer-aided design: A survey.ACM Computing Surveys, 58(9):1–39, 2026
work page 2026
-
[3]
Yuhao Du, Shunian Chen, Wenbo Zan, Peizhao Li, Mingxuan Wang, Dingjie Song, Bo Li, Yan Hu, and Benyou Wang. Blenderllm: Training large language models for computer-aided design with self-improvement.arXiv preprint arXiv:2412.14203, 2024
-
[4]
Mohammad S Khan, Sankalp Sinha, Talha U Sheikh, Didier Stricker, Sk A Ali, and Muham- mad Z Afzal. Text2cad: Generating sequential cad designs from beginner-to-expert level text prompts.Advances in Neural Information Processing Systems, 37:7552–7579, 2024
work page 2024
-
[5]
Haoyang Xie and Feng Ju. Text-to-cadquery: A new paradigm for cad generation with scalable large model capabilities.arXiv preprint arXiv:2505.06507, 2025
-
[6]
Maksim Elistratov, Marina Barannikov, Gregory Ivanov, Valentin Khrulkov, Anton Konushin, Andrey Kuznetsov, and Dmitrii Zhemchuzhnikov. Cadevolve: Creating realistic cad via program evolution.arXiv preprint arXiv:2602.16317, 2026
-
[7]
Anna C Doris, Ferdous Alam, Amin Heyrani Nobari, and Faez Ahmed. Cad-coder: An open-source vision-language model for computer-aided design code generation.Journal of Mechanical Design, 148(7):071702, 2026
work page 2026
-
[8]
Nomi Yu, Md Ferdous Alam, A John Hart, and Faez Ahmed. Gencad-3d: Cad program genera- tion using multimodal latent space alignment and synthetic dataset balancing. InInternational Design Engineering Technical Conferences and Computers and Information in Engineering Conference, volume 89220, page V03AT03A015. American Society of Mechanical Engineers, 2025
work page 2025
-
[9]
Caddreamer: Cad object generation from single-view images
Yuan Li, Cheng Lin, Yuan Liu, Xiaoxiao Long, Chenxu Zhang, Ningna Wang, Xin Li, Wenping Wang, and Xiaohu Guo. Caddreamer: Cad object generation from single-view images. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 21448–21457, 2025
work page 2025
-
[10]
cadrille: Multi-modal cad reconstruction with reinforcement learning
Maksim Kolodiazhnyi, Denis Tarasov, Dmitrii Zhemchuzhnikov, Alexander Nikulin, Ilya Zisman, Anna V orontsova, Anton Konushin, Vladislav Kurenkov, and Danila Rukhovich. cadrille: Multi-modal cad reconstruction with reinforcement learning. InThe Fourteenth International Conference on Learning Representations, 2025
work page 2025
-
[11]
Cad-recode: Reverse engineering cad code from point clouds
Danila Rukhovich, Elona Dupont, Dimitrios Mallis, Kseniya Cherenkova, Anis Kacem, and Djamila Aouada. Cad-recode: Reverse engineering cad code from point clouds. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9801–9811, 2025
work page 2025
-
[12]
Md Ferdous Alam and Faez Ahmed. Gencad: Image-conditioned computer-aided design generation with transformer-based contrastive representation and diffusion priors.arXiv preprint arXiv:2409.16294, 2024
-
[13]
Jingwei Xu, Chenyu Wang, Zibo Zhao, Wen Liu, Yi Ma, and Shenghua Gao. Cad-mllm: Unify- ing multimodality-conditioned cad generation with mllm.arXiv preprint arXiv:2411.04954, 2024
-
[14]
Ahmet Serdar Karadeniz, Dimitrios Mallis, Danila Rukhovich, Kseniya Cherenkova, Anis Kacem, and Djamila Aouada. Micadangelo: Fine-grained reconstruction of constrained cad models from 3d scans.arXiv preprint arXiv:2510.23429, 2025
-
[15]
Mohammad Sadil Khan, Elona Dupont, Sk Aziz Ali, Kseniya Cherenkova, Anis Kacem, and Djamila Aouada. Cad-signet: Cad language inference from point clouds using layer-wise sketch instance guided attention. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4713–4722, 2024. 10
work page 2024
-
[16]
Liane Makatura, Michael Foshey, Bohan Wang, Felix HähnLein, Pingchuan Ma, Bolei Deng, Megan Tjandrasuwita, Andrew Spielberg, Crystal Elaine Owens, Peter Yichen Chen, et al. How can large language models help humans in design and manufacturing?arXiv preprint arXiv:2307.14377, 2023
-
[17]
Cyril Picard, Kristen M Edwards, Anna C Doris, Brandon Man, Giorgio Giannone, Md Ferdous Alam, and Faez Ahmed. From concept to manufacturing: Evaluating vision-language models for engineering design.Artificial Intelligence Review, 58(9):288, 2025
work page 2025
-
[18]
Wamiq Para, Shariq Bhat, Paul Guerrero, Tom Kelly, Niloy Mitra, Leonidas J Guibas, and Peter Wonka. Sketchgen: Generating constrained cad sketches.Advances in Neural Information Processing Systems, 34:5077–5088, 2021
work page 2021
-
[19]
Deepcad: A deep generative network for computer- aided design models
Rundi Wu, Chang Xiao, and Changxi Zheng. Deepcad: A deep generative network for computer- aided design models. InProceedings of the IEEE/CVF international conference on computer vision, pages 6772–6782, 2021
work page 2021
-
[20]
Karl DD Willis, Yewen Pu, Jieliang Luo, Hang Chu, Tao Du, Joseph G Lambourne, Armando Solar-Lezama, and Wojciech Matusik. Fusion 360 gallery: A dataset and environment for programmatic cad construction from human design sequences.ACM Transactions on Graphics (TOG), 40(4):1–24, 2021
work page 2021
-
[21]
Sangpil Kim, Hyung-gun Chi, Xiao Hu, Qixing Huang, and Karthik Ramani. A large-scale annotated mechanical components benchmark for classification and retrieval tasks with deep neural networks. InEuropean conference on computer vision, pages 175–191. Springer, 2020
work page 2020
-
[22]
Gen- erating cad code with vision-language models for 3d designs
Kamel Alrashedy, Pradyumna Tambwekar, Zulfiqar Zaidi, Megan Langwasser, Wei Xu, and Matthew Gombolay. Generating cad code with vision-language models for 3d designs.arXiv preprint arXiv:2410.05340, 2024
-
[23]
Pvdeconv: Point-voxel deconvolution for autoencoding cad construction in 3d
Kseniya Cherenkova, Djamila Aouada, and Gleb Gusev. Pvdeconv: Point-voxel deconvolution for autoencoding cad construction in 3d. In2020 IEEE International Conference on Image Processing (ICIP), pages 2741–2745. IEEE, 2020
work page 2020
-
[24]
Abc: A big cad model dataset for geometric deep learning
Sebastian Koch, Albert Matveev, Zhongshi Jiang, Francis Williams, Alexey Artemov, Evgeny Burnaev, Marc Alexa, Denis Zorin, and Daniele Panozzo. Abc: A big cad model dataset for geometric deep learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9601–9611, 2019
work page 2019
-
[25]
Cad-gpt: Synthesising cad construction sequence with spatial reasoning-enhanced multimodal llms
Siyu Wang, Cailian Chen, Xinyi Le, Qimin Xu, Lei Xu, Yanzhou Zhang, and Jie Yang. Cad-gpt: Synthesising cad construction sequence with spatial reasoning-enhanced multimodal llms. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 7880–7888, 2025
work page 2025
-
[26]
Point2cyl: Reverse engineering 3d objects from point clouds to extrusion cylinders
Mikaela Angelina Uy, Yen-Yu Chang, Minhyuk Sung, Purvi Goel, Joseph G Lambourne, Tolga Birdal, and Leonidas J Guibas. Point2cyl: Reverse engineering 3d objects from point clouds to extrusion cylinders. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11850–11860, 2022
work page 2022
-
[27]
Transcad: A hierarchical transformer for cad sequence inference from point clouds
Elona Dupont, Kseniya Cherenkova, Dimitrios Mallis, Gleb Gusev, Anis Kacem, and Djamila Aouada. Transcad: A hierarchical transformer for cad sequence inference from point clouds. In European Conference on Computer Vision, pages 19–36. Springer, 2024
work page 2024
-
[28]
Manuel Contero, David Pérez-López, Pedro Company, and Jorge D Camba. A quantitative anal- ysis of parametric cad model complexity and its relationship to perceived modeling complexity. Advanced Engineering Informatics, 56:101970, 2023
work page 2023
-
[29]
CADFit: Precise Mesh-to-CAD Program Generation with Hybrid Optimization
Ghadi Nehme, Eamon Whalen, and Faez Ahmed. Cadfit: Precise mesh-to-cad program genera- tion with hybrid optimization, 2026. URLhttps://arxiv.org/abs/2605.01171
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[30]
Brepnet: A topological message passing system for solid models
Joseph G Lambourne, Karl DD Willis, Pradeep Kumar Jayaraman, Aditya Sanghi, Peter Meltzer, and Hooman Shayani. Brepnet: A topological message passing system for solid models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12773–12782, 2021. 11
work page 2021
-
[31]
Objaverse: A universe of annotated 3d objects
Matt Deitke, Dustin Schwenk, Jordi Salvador, Luca Weihs, Oscar Michel, Eli VanderBilt, Ludwig Schmidt, Kiana Ehsani, Aniruddha Kembhavi, and Ali Farhadi. Objaverse: A universe of annotated 3d objects. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 13142–13153, 2023
work page 2023
-
[32]
Zero-to-CAD: Agentic Synthesis of Interpretable CAD Programs at Million-Scale Without Real Data
Mohammadmehdi Ataei, Farzaneh Askari, Kamal Rahimi Malekshan, and Pradeep Kumar Jayaraman. Zero-to-cad: Agentic synthesis of interpretable cad programs at million-scale without real data.arXiv preprint arXiv:2604.24479, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[33]
Oriane Siméoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, et al. Dinov3. arXiv preprint arXiv:2508.10104, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large- scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009. 12 Table of Contents for Appendices A Additional Method Details 14 A.1 Overview of CADBENCHFamilies.. . . . . . . . . . . . . . . . . . . ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.