Recognition: 2 theorem links
· Lean TheoremRotation-Preserving Supervised Fine-Tuning
Pith reviewed 2026-05-13 06:22 UTC · model grok-4.3
The pith
Rotation-Preserving Supervised Fine-Tuning limits changes to top singular subspaces during fine-tuning to improve out-of-domain generalization on math reasoning tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
RPSFT penalizes changes in the projected top-k singular-vector block of each pretrained weight matrix to limit unnecessary rotation of singular subspaces while still allowing task-specific adaptation. This serves as an efficient alternative to directly computing Fisher information or Hessian for identifying sensitive directions at large model scales.
What carries the argument
The penalty term on changes to the projected top-k singular-vector block of pretrained weight matrices, acting as a proxy for Fisher-sensitive directions to preserve dominant singular subspaces.
If this is right
- Improves the in-domain/OOD trade-off compared to standard SFT and other baselines on math reasoning tasks.
- Better preserves pretrained representations across model families and sizes.
- Provides stronger initializations for downstream reinforcement learning fine-tuning.
Where Pith is reading between the lines
- The subspace preservation idea could extend to other fine-tuning regimes such as instruction tuning or preference alignment.
- Dynamic adjustment of the top-k threshold per layer might further balance preservation and adaptation for specific tasks.
Load-bearing premise
Penalizing changes to the projected top-k singular-vector block of each pretrained weight matrix serves as an efficient and sufficient proxy for Fisher-sensitive directions without blocking necessary task adaptation.
What would settle it
An experiment where RPSFT shows no improvement or worse OOD performance than standard SFT on a diverse set of out-of-domain math reasoning benchmarks.
Figures




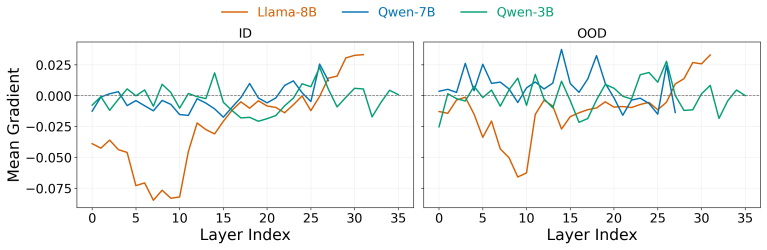


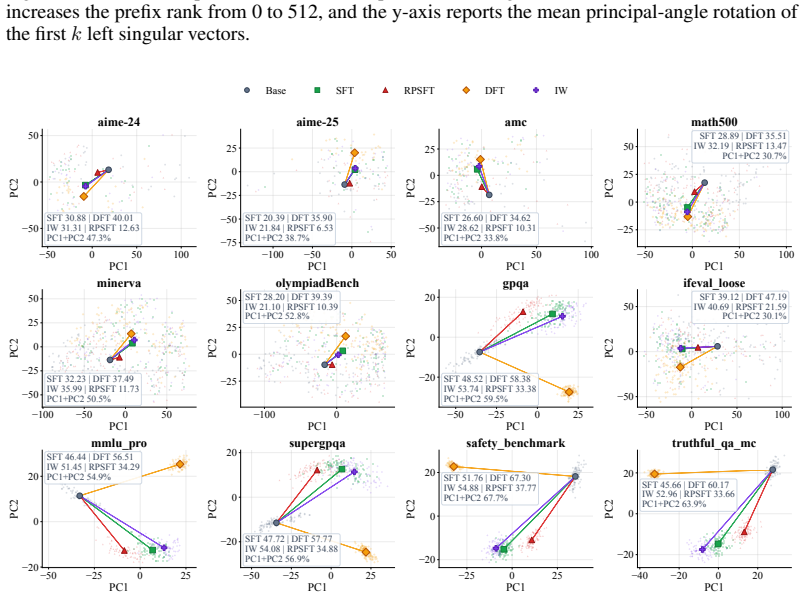

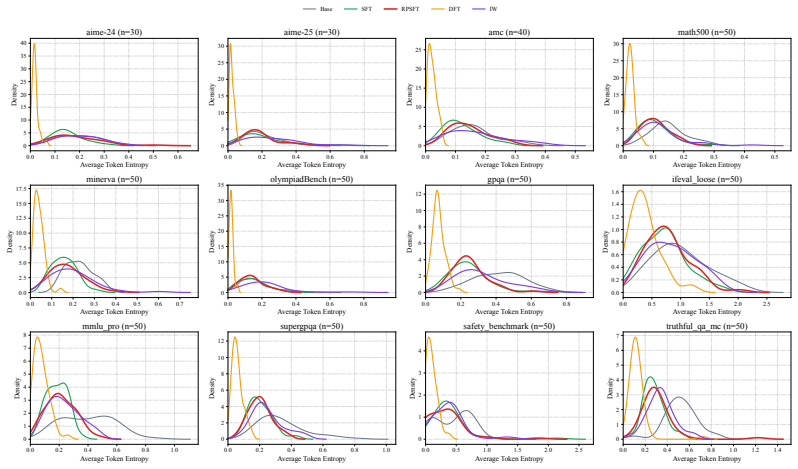



read the original abstract
Supervised fine-tuning (SFT) improves in-domain performance but can degrade out-of-domain (OOD) generalization. Prior work suggests that this degradation is related to changes in dominant singular subspaces of pretrained weight matrices. However, directly identifying loss-sensitive directions with Hessian or Fisher information is computationally expensive at LLM scale. In this work, we propose preserving projected rotations in pretrained singular subspaces as an efficient proxy for Fisher-sensitive directions, which we call Rotation-Preserving Supervised Fine-Tuning (RPSFT). RPSFT penalizes changes in the projected top-$k$ singular-vector block of each pretrained weight matrix, limiting unnecessary rotation while preserving task adaptation. Across model families and sizes trained on math reasoning data, RPSFT improves the in-domain/OOD trade-off over standard SFT and strong SFT baselines, better preserves pretrained representations, and provides stronger initializations for downstream RL fine-tuning. Code is available at \href{https://github.com/jinhangzhan/RPSFT.git}{https://github.com/jinhangzhan/RPSFT}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Rotation-Preserving Supervised Fine-Tuning (RPSFT), which augments the standard SFT loss with a penalty term that discourages rotations within the projected top-k singular-vector blocks of each pretrained weight matrix. This is motivated as a computationally cheap proxy for preserving Fisher-sensitive directions. The authors claim that RPSFT yields a better in-domain/OOD trade-off than standard SFT and strong baselines on math-reasoning data across model families and sizes, better preserves pretrained representations, and supplies stronger initializations for downstream RL fine-tuning.
Significance. If the empirical gains are robust and the mechanistic link to Fisher directions can be substantiated, RPSFT would supply a practical, low-overhead regularizer that avoids the prohibitive cost of full Hessian or Fisher computations at LLM scale. The public code release supports reproducibility and further testing.
major comments (2)
- [§3 and §4] The central modeling assumption—that penalizing changes inside the top-k singular subspace acts as a faithful, low-cost surrogate for loss-sensitive (Fisher) directions—is load-bearing for the mechanistic explanation of the reported gains, yet no direct validation is supplied. No subspace-overlap metric (principal angles, average cosine similarity between top singular vectors and leading Fisher eigenvectors, or even a cheap gradient-based proxy) is reported on any model, including toy-scale ablations. Without this check, it remains possible that the observed in-domain/OOD improvements arise from generic weight decay rather than selective protection of the claimed directions.
- [§4] §4 (Experiments): the quantitative results are presented without error bars, statistical significance tests, or detailed ablation tables on the hyper-parameter k. In addition, the definitions of the “strong SFT baselines” and the precise train/test splits for the in-domain versus OOD math-reasoning evaluations are not fully specified, making it difficult to assess the magnitude and reliability of the claimed improvements.
minor comments (2)
- The abstract would be strengthened by including one or two key quantitative deltas (e.g., average OOD accuracy lift) rather than purely qualitative statements.
- [§3] Notation for the projection operator onto the top-k singular block (presumably defined in Eq. (2) or (3)) should be introduced earlier and used consistently in the loss derivation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to incorporate the suggested improvements for greater rigor and clarity.
read point-by-point responses
-
Referee: [§3 and §4] The central modeling assumption—that penalizing changes inside the top-k singular subspace acts as a faithful, low-cost surrogate for loss-sensitive (Fisher) directions—is load-bearing for the mechanistic explanation of the reported gains, yet no direct validation is supplied. No subspace-overlap metric (principal angles, average cosine similarity between top singular vectors and leading Fisher eigenvectors, or even a cheap gradient-based proxy) is reported on any model, including toy-scale ablations. Without this check, it remains possible that the observed in-domain/OOD improvements arise from generic weight decay rather than selective protection of the claimed directions.
Authors: We agree that direct validation of the claimed surrogate relationship would strengthen the mechanistic argument. Full Fisher computations remain prohibitive at LLM scale, which is the core motivation for the singular-subspace proxy. In the revised manuscript we will add toy-scale experiments on smaller models that compute a gradient-based Fisher approximation and report quantitative overlap metrics (average cosine similarity and principal angles) between the top-k singular vectors and the leading eigenvectors of this approximation. These results will help rule out generic regularization as the sole source of the observed gains. revision: yes
-
Referee: [§4] §4 (Experiments): the quantitative results are presented without error bars, statistical significance tests, or detailed ablation tables on the hyper-parameter k. In addition, the definitions of the “strong SFT baselines” and the precise train/test splits for the in-domain versus OOD math-reasoning evaluations are not fully specified, making it difficult to assess the magnitude and reliability of the claimed improvements.
Authors: We accept that the current experimental presentation lacks sufficient statistical detail and specification. The revised version will include error bars from multiple random seeds, paired statistical significance tests on the reported improvements, comprehensive ablation tables for the hyper-parameter k, and explicit definitions of all strong SFT baselines together with the exact train/test splits used for the in-domain and OOD math-reasoning evaluations. revision: yes
Circularity Check
No significant circularity; RPSFT penalty defined independently from pretrained SVD
full rationale
The paper proposes RPSFT as a regularization that penalizes changes to the projected top-k singular-vector block of each pretrained weight matrix, computed directly via SVD on the initial weights. This construction is a design choice motivated by external prior observations on singular-subspace drift, not a quantity fitted to the target task data or derived from a self-citation chain. No equations reduce the claimed preservation effect to the inputs by construction, and the reported gains are presented as empirical outcomes across model families rather than tautological consequences of the definition. The central assumption that the top-k block serves as a proxy for Fisher-sensitive directions is stated as such and does not collapse into a self-referential loop.
Axiom & Free-Parameter Ledger
free parameters (1)
- k (top singular vectors)
axioms (2)
- domain assumption OOD degradation after SFT is related to changes in dominant singular subspaces of pretrained weight matrices
- domain assumption Projected rotations in these subspaces serve as an efficient proxy for Fisher-sensitive directions
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
RPSFT penalizes changes in the projected top-k singular-vector block of each pretrained weight matrix, limiting unnecessary rotation while preserving task adaptation.
-
IndisputableMonolith/Foundation/BranchSelection.leanRCLCombiner_isCoupling_iff echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
the pretrained singular basis is not identical to the Fisher eigenspace, its strong overlap with Fisher-projected gradient energy indicates that dominant singular directions provide a useful low-rank structural proxy for loss-sensitive curvature directions.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng X...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Parseval regularization for continual reinforcement learning, 2024
Wesley Chung, Lynn Cherif, David Meger, and Doina Precup. Parseval regularization for continual reinforcement learning, 2024. URL https://arxiv.org/abs/2412.07224
-
[4]
Mohamed Elsayed, Qingfeng Lan, Clare Lyle, and A. Rupam Mahmood. Weight clipping for deep continual and reinforcement learning, 2024. URL https://arxiv.org/abs/2407.01704
-
[5]
Franke, Michael Hefenbrock, and Frank Hutter
J \"o rg K.H. Franke, Michael Hefenbrock, and Frank Hutter. Preserving principal subspaces to reduce catastrophic forgetting in fine-tuning. In ICLR 2024 Workshop on Mathematical and Empirical Understanding of Foundation Models, 2024. URL https://openreview.net/forum?id=XoWtroECJU
work page 2024
-
[7]
Hessian eigenvectors and principal component analysis of neural network weight matrices, 2023
David Haink. Hessian eigenvectors and principal component analysis of neural network weight matrices, 2023. URL https://arxiv.org/abs/2311.00452
-
[8]
Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Leng Thai, Junhao Shen, Jinyi Hu, Xu Han, Yujie Huang, Yuxiang Zhang, Jie Liu, Lei Qi, Zhiyuan Liu, and Maosong Sun. Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems, 2024. URL https://arxiv.org/abs/2402.14008
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset, 2021. URL https://arxiv.org/abs/2103.03874
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[10]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models, 2021. URL https://arxiv.org/abs/2106.09685
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[11]
Maggie Huan, Yuetai Li, Tuney Zheng, Xiaoyu Xu, Seungone Kim, Minxin Du, Radha Poovendran, Graham Neubig, and Xiang Yue. Does math reasoning improve general llm capabilities? understanding transferability of llm reasoning, 2025. URL https://arxiv.org/abs/2507.00432
-
[12]
Open r1: A fully open reproduction of deepseek-r1, January 2025
Hugging Face . Open r1: A fully open reproduction of deepseek-r1, January 2025. URL https://github.com/huggingface/open-r1
work page 2025
-
[13]
RL Fine-Tuning Heals OOD Forgetting in SFT
Hangzhan Jin, Sitao Luan, Sicheng Lyu, Guillaume Rabusseau, Reihaneh Rabbany, Doina Precup, and Mohammad Hamdaqa. Rl fine-tuning heals ood forgetting in sft, 2025. URL https://arxiv.org/abs/2509.12235
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Maintaining plasticity in continual learning via regenerative regularization, 2024
Saurabh Kumar, Henrik Marklund, and Benjamin Van Roy. Maintaining plasticity in continual learning via regenerative regularization, 2024. URL https://arxiv.org/abs/2308.11958
-
[16]
Limitations of the empirical fisher approximation for natural gradient descent
Frederik Kunstner, Philipp Hennig, and Lukas Balles. Limitations of the empirical fisher approximation for natural gradient descent. In Advances in Neural Information Processing Systems 32, pages 4158--4169, 2019
work page 2019
-
[17]
Reinforcement fine-tuning naturally mitigates forgetting in continual post-training, 2025
Song Lai, Haohan Zhao, Rong Feng, Changyi Ma, Wenzhuo Liu, Hongbo Zhao, Xi Lin, Dong Yi, Min Xie, Qingfu Zhang, Hongbin Liu, Gaofeng Meng, and Fei Zhu. Reinforcement fine-tuning naturally mitigates forgetting in continual post-training, 2025. URL https://arxiv.org/abs/2507.05386
- [18]
-
[19]
Solving Quantitative Reasoning Problems with Language Models
Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, Yuhuai Wu, Behnam Neyshabur, Guy Gur-Ari, and Vedant Misra. Solving quantitative reasoning problems with language models, 2022. URL https://arxiv.org/abs/2206.14858
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[20]
arXiv preprint arXiv:2509.20758 , year=
Jiacheng Lin, Zhongruo Wang, Kun Qian, Tian Wang, Arvind Srinivasan, Hansi Zeng, Ruochen Jiao, Xie Zhou, Jiri Gesi, Dakuo Wang, Yufan Guo, Kai Zhong, Weiqi Zhang, Sujay Sanghavi, Changyou Chen, Hyokun Yun, and Lihong Li. Sft doesn't always hurt general capabilities: Revisiting domain-specific fine-tuning in llms, 2025. URL https://arxiv.org/abs/2509.20758
-
[21]
TruthfulQA: Measuring How Models Mimic Human Falsehoods
Stephanie Lin, Jacob Hilton, and Owain Evans. Truthfulqa: Measuring how models mimic human falsehoods, 2022. URL https://arxiv.org/abs/2109.07958
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[22]
Aojun Lu, Hangjie Yuan, Tao Feng, and Yanan Sun. Rethinking the stability-plasticity trade-off in continual learning from an architectural perspective, 2025. URL https://arxiv.org/abs/2506.03951
-
[23]
Understanding plasticity in neural networks, 2023
Clare Lyle, Zeyu Zheng, Evgenii Nikishin, Bernardo Avila Pires, Razvan Pascanu, and Will Dabney. Understanding plasticity in neural networks, 2023. URL https://arxiv.org/abs/2303.01486
-
[24]
Deep learning via hessian-free optimization
James Martens. Deep learning via hessian-free optimization. In Proceedings of the 27th International Conference on Machine Learning, pages 735--742, 2010
work page 2010
-
[25]
New insights and perspectives on the natural gradient method, 2020
James Martens. New insights and perspectives on the natural gradient method, 2020. URL https://arxiv.org/abs/1412.1193
-
[26]
Pissa: Principal singular values and singular vectors adaptation of large language models, 2025
Fanxu Meng, Zhaohui Wang, and Muhan Zhang. Pissa: Principal singular values and singular vectors adaptation of large language models, 2025. URL https://arxiv.org/abs/2404.02948
-
[27]
Reinforcement learning finetunes small subnetworks in large language models, 2025
Sagnik Mukherjee, Lifan Yuan, Dilek Hakkani-Tur, and Hao Peng. Reinforcement learning finetunes small subnetworks in large language models, 2025. URL https://arxiv.org/abs/2505.11711
-
[28]
Sculpting subspaces: Constrained full fine-tuning in llms for continual learning, 2025
Nikhil Shivakumar Nayak, Krishnateja Killamsetty, Ligong Han, Abhishek Bhandwaldar, Prateek Chanda, Kai Xu, Hao Wang, Aldo Pareja, Oleg Silkin, Mustafa Eyceoz, and Akash Srivastava. Sculpting subspaces: Constrained full fine-tuning in llms for continual learning, 2025. URL https://arxiv.org/abs/2504.07097
-
[29]
Offline learning and forgetting for reasoning with large language models, 2025
Tianwei Ni, Allen Nie, Sapana Chaudhary, Yao Liu, Huzefa Rangwala, and Rasool Fakoor. Offline learning and forgetting for reasoning with large language models, 2025. URL https://arxiv.org/abs/2504.11364
-
[30]
OpenAI, :, Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, Alex Iftimie, Alex Karpenko, Alex Tachard Passos, Alexander Neitz, Alexander Prokofiev, Alexander Wei, Allison Tam, Ally Bennett, Ananya Kumar, Andre Saraiva, Andrea Vallone, Andrew Duberstein, Andrew Kondri...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Supervised fine tuning on curated data is reinforcement learning (and can be improved), 2025
Chongli Qin and Jost Tobias Springenberg. Supervised fine tuning on curated data is reinforcement learning (and can be improved), 2025. URL https://arxiv.org/abs/2507.12856
-
[32]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. Gpqa: A graduate-level google-proof q&a benchmark, 2023. URL https://arxiv.org/abs/2311.12022
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms, 2017. URL https://arxiv.org/abs/1707.06347
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[35]
Rl’s razor: Why online reinforcement learning forgets less, 2025
Idan Shenfeld, Jyothish Pari, and Pulkit Agrawal. Rl's razor: Why online reinforcement learning forgets less, 2025. URL https://arxiv.org/abs/2509.04259
-
[36]
Understanding layer significance in llm alignment, 2025
Guangyuan Shi, Zexin Lu, Xiaoyu Dong, Wenlong Zhang, Xuanyu Zhang, Yujie Feng, and Xiao-Ming Wu. Understanding layer significance in llm alignment, 2025. URL https://arxiv.org/abs/2410.17875
-
[37]
P Team, Xinrun Du, Yifan Yao, Kaijing Ma, Bingli Wang, Tianyu Zheng, King Zhu, Minghao Liu, Yiming Liang, Xiaolong Jin, Zhenlin Wei, Chujie Zheng, Kaixin Deng, Shawn Gavin, Shian Jia, Sichao Jiang, Yiyan Liao, Rui Li, Qinrui Li, Sirun Li, Yizhi Li, Yunwen Li, David Ma, Yuansheng Ni, Haoran Que, Qiyao Wang, Zhoufutu Wen, Siwei Wu, Tyshawn Hsing, Ming Xu, Z...
-
[38]
Qwen2.5: A party of foundation models, September 2024
Qwen Team. Qwen2.5: A party of foundation models, September 2024. URL https://qwenlm.github.io/blog/qwen2.5/
work page 2024
-
[39]
Continual gradient low-rank projection fine-tuning for llms, 2025 a
Chenxu Wang, Yilin Lyu, Zicheng Sun, and Liping Jing. Continual gradient low-rank projection fine-tuning for llms, 2025 a . URL https://arxiv.org/abs/2507.02503
-
[40]
Milora: Harnessing minor singular components for parameter-efficient llm finetuning, 2025 b
Hanqing Wang, Yixia Li, Shuo Wang, Guanhua Chen, and Yun Chen. Milora: Harnessing minor singular components for parameter-efficient llm finetuning, 2025 b . URL https://arxiv.org/abs/2406.09044
-
[41]
A comprehensive survey of continual learning: Theory, method and application, 2024 a
Liyuan Wang, Xingxing Zhang, Hang Su, and Jun Zhu. A comprehensive survey of continual learning: Theory, method and application, 2024 a . URL https://arxiv.org/abs/2302.00487
-
[42]
Orthogonal subspace learning for language model continual learning,
Xiao Wang, Tianze Chen, Qiming Ge, Han Xia, Rong Bao, Rui Zheng, Qi Zhang, Tao Gui, and Xuanjing Huang. Orthogonal subspace learning for language model continual learning, 2023. URL https://arxiv.org/abs/2310.14152
-
[43]
MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, Tianle Li, Max Ku, Kai Wang, Alex Zhuang, Rongqi Fan, Xiang Yue, and Wenhu Chen. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark, 2024 b . URL https://arxiv.org/abs/2406.01574
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
On the generalization of sft: A reinforcement learning perspective with reward rectification, 2026
Yongliang Wu, Yizhou Zhou, Zhou Ziheng, Yingzhe Peng, Xinyu Ye, Xinting Hu, Wenbo Zhu, Lu Qi, Ming-Hsuan Yang, and Xu Yang. On the generalization of sft: A reinforcement learning perspective with reward rectification, 2025. URL https://arxiv.org/abs/2508.05629
-
[45]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Yuxuan Song, Xiangpeng Wei, Hao Zhou, Jingjing Liu, W...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
A Layer-wise Analysis of Supervised Fine-Tuning
Qinghua Zhao, Xueling Gong, Xinyu Chen, Zhongfeng Kang, and Xinlu Li. A layer-wise analysis of supervised fine-tuning, 2026. URL https://arxiv.org/abs/2604.11838
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[47]
Instruction-Following Evaluation for Large Language Models
Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. Instruction-following evaluation for large language models, 2023. URL https://arxiv.org/abs/2311.07911
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[48]
Pan, Zhangyang Wang, Yuandong Tian, and Kai Sheng Tai
Hanqing Zhu, Zhenyu Zhang, Hanxian Huang, DiJia Su, Zechun Liu, Jiawei Zhao, Igor Fedorov, Hamed Pirsiavash, Jinwon Lee, David Z. Pan, Zhangyang Wang, Yuandong Tian, and Kai Sheng Tai. Why rl updates look sparse: An implicit compass drives optimization bias, 2025 a . URL https://openreview.net/forum?id=Q4mF4tLGbf. Submitted to ICLR 2026
work page 2025
-
[49]
arXiv preprint arXiv:2511.08567 , year=
Hanqing Zhu, Zhenyu Zhang, Hanxian Huang, DiJia Su, Zechun Liu, Jiawei Zhao, Igor Fedorov, Hamed Pirsiavash, Zhizhou Sha, Jinwon Lee, David Z. Pan, Zhangyang Wang, Yuandong Tian, and Kai Sheng Tai. The path not taken: Rlvr provably learns off the principals, 2025 b . URL https://arxiv.org/abs/2511.08567
-
[50]
Proximal Supervised Fine-Tuning
Wenhong Zhu, Ruobing Xie, Rui Wang, Xingwu Sun, Di Wang, and Pengfei Liu. Proximal supervised fine-tuning, 2025 c . URL https://arxiv.org/abs/2508.17784
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-R1: Incentivizing Reasoning Capability in Large Language Models via Reinforcement Learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[52]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Group Relative Policy Optimization for Large Language Models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
American Invitational Mathematics Examination , author=
-
[54]
Finetuned Language Models Are Zero-Shot Learners
Finetuned Language Models Are Zero-Shot Learners , author=. arXiv preprint arXiv:2109.01652 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[55]
LoRA: Low-Rank Adaptation of Large Language Models , author=. 2021 , eprint=
work page 2021
-
[56]
Training language models to follow instructions with human feedback
Training Language Models to Follow Instructions with Human Feedback , author=. arXiv preprint arXiv:2203.02155 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[57]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author=. 2024 , eprint=
work page 2024
-
[58]
Improved Supervised Fine-Tuning for Large Language Models to Mitigate Catastrophic Forgetting , author=. 2025 , eprint=
work page 2025
-
[59]
Reinforcement Fine-Tuning Naturally Mitigates Forgetting in Continual Post-Training , author=. 2025 , eprint=
work page 2025
-
[60]
Revisiting Catastrophic Forgetting in Large Language Model Tuning , author=. 2024 , eprint=
work page 2024
-
[61]
arXiv preprint arXiv:2403.08741 , year=
Sculpting Subspaces: Constrained Full Fine-Tuning in Large Language Models for Continual Learning , author=. arXiv preprint arXiv:2403.08741 , year=
-
[62]
Training Networks in Null Space of Feature Covariance for Continual Learning , author=. 2021 , eprint=
work page 2021
-
[63]
Continual Gradient Low-Rank Projection Fine-Tuning for LLMs , author=. 2025 , eprint=
work page 2025
- [64]
-
[65]
Hessian Eigenvectors and Principal Component Analysis of Neural Network Weight Matrices , author=. 2023 , eprint=
work page 2023
- [66]
-
[67]
Open R1: A fully open reproduction of DeepSeek-R1 , url =
-
[68]
arXiv preprint arXiv:2505.21908 , year=
Reinforcement Learning for Out-of-Distribution Reasoning in LLMs: An Empirical Study on Diagnosis-Related Group Coding , author=. arXiv preprint arXiv:2505.21908 , year=
- [69]
-
[70]
Logic-RL: Unleashing LLM Reasoning with Rule-Based Reinforcement Learning , author=. 2025 , eprint=
work page 2025
-
[71]
RL's Razor: Why Online Reinforcement Learning Forgets Less , author=. 2025 , eprint=
work page 2025
-
[72]
The Path Not Taken: RLVR Provably Learns Off the Principals , author=. 2025 , eprint=
work page 2025
-
[73]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[74]
Qwen2.5: A Party of Foundation Models , url =
Qwen Team , month =. Qwen2.5: A Party of Foundation Models , url =
-
[75]
Orthogonal Subspace Learning for Language Model Continual Learning , author=. 2023 , eprint=
work page 2023
-
[76]
and Soures, Nicholas and Kudithipudi, Dhireesha , year=
van de Ven, Gido M. and Soures, Nicholas and Kudithipudi, Dhireesha , year=. Continual learning and catastrophic forgetting , ISBN=. doi:10.1016/b978-0-443-15754-7.00073-0 , booktitle=
- [77]
-
[78]
Continual Learning with Deep Generative Replay , author=. 2017 , eprint=
work page 2017
-
[79]
TRACE: A Comprehensive Benchmark for Continual Learning in Large Language Models , author=. 2023 , eprint=
work page 2023
-
[80]
Progressive Prompts: Continual Learning for Language Models , author=. 2023 , eprint=
work page 2023
-
[81]
Fine-tuned Language Models are Continual Learners , author=. 2022 , eprint=
work page 2022
-
[82]
Character-level Convolutional Networks for Text Classification , author=. 2016 , eprint=
work page 2016
-
[83]
Kirkpatrick, James and Pascanu, Razvan and Rabinowitz, Neil and Veness, Joel and Desjardins, Guillaume and Rusu, Andrei A. and Milan, Kieran and Quan, John and Ramalho, Tiago and Grabska-Barwinska, Agnieszka and Hassabis, Demis and Clopath, Claudia and Kumaran, Dharshan and Hadsell, Raia , year=. Overcoming catastrophic forgetting in neural networks , vol...
-
[84]
Language Models Meet World Models: Embodied Experiences Enhance Language Models , author=. 2023 , eprint=
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.