Recognition: 2 theorem links
· Lean TheoremStreaming of rendered content with adaptive frame rate and resolution
Pith reviewed 2026-05-13 01:41 UTC · model grok-4.3
The pith
A neural network predicts optimal frame rates and resolutions to improve perceptual quality of streamed rendered content under bandwidth limits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
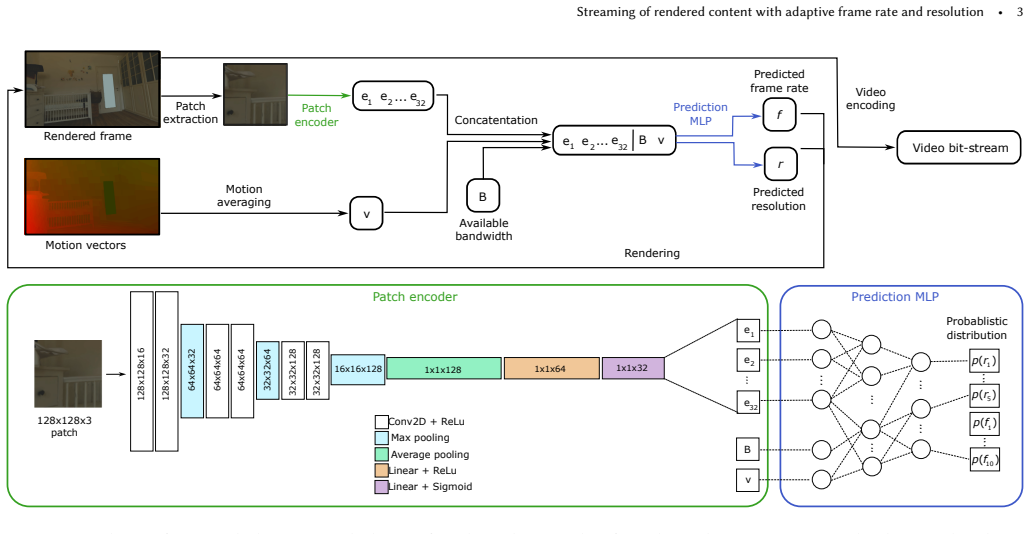
We exploit the spatio-temporal limits of the human visual system to improve perceived quality while reducing rendering costs by adaptively adjusting both frame rate and resolution based on scene content and motion. Our approach is codec-agnostic and requires only minimal modifications to existing rendering infrastructure. We propose a system in which a lightweight neural network predicts the optimal combination of frame rate and resolution for a given transmission bandwidth, content, and motion velocity. This prediction significantly enhances perceptual quality while minimizing computational cost under bandwidth constraints. The network is trained on a large dataset of rendered content.
What carries the argument
A lightweight neural network that predicts the best frame rate and resolution pair from scene content, motion velocity, and available transmission bandwidth.
If this is right
- Perceptual quality rises for rendered content streamed under bandwidth constraints compared to fixed-frame-rate baselines.
- Server rendering computation drops because high frame rates or resolutions are used only when motion and content require them.
- Integration requires only minor changes to existing rendering systems and works independently of the video codec.
- Quality gains apply across different scene contents and motion velocities.
Where Pith is reading between the lines
- The method could lower the server-side resources needed to deliver graphics to many simultaneous mobile users.
- Similar prediction logic might extend to other bandwidth-limited visual streams such as live video or 360 content.
- Real-time client feedback could further refine the network's choices beyond the current offline training.
Load-bearing premise
The perceptual video quality metric used to label the training data accurately captures human perception across varying frame rates, resolutions, and rendered content types.
What would settle it
A direct comparison study where viewers rate streams from the neural network's adaptive choices as equal or lower in quality than fixed 30 fps streams with reduced resolution at the same bandwidth would disprove the claimed perceptual improvement.
Figures









read the original abstract
Streaming rendered content is an attractive way to bring high-quality graphics to billions of mobile devices that do not have sufficient rendering power. Existing solutions render content on a server at a fixed frame rate, typically 30 or 60 frames per second, and reduce resolution when bandwidth is restricted. However, this strategy leads to suboptimal rendering quality under the bandwidth constraints. In this work, we exploit the spatio-temporal limits of the human visual system to improve perceived quality while reducing rendering costs by adaptively adjusting both frame rate and resolution based on scene content and motion. Our approach is codec-agnostic and requires only minimal modifications to existing rendering infrastructure. We propose a system in which a lightweight neural network predicts the optimal combination of frame rate and resolution for a given transmission bandwidth, content, and motion velocity. This prediction significantly enhances perceptual quality while minimizing computational cost under bandwidth constraints. The network is trained on a large dataset of rendered content labeled with a perceptual video quality metric. The dataset and further information can be found at the project web page: https://www.cl.cam.ac.uk/research/rainbow/projects/adaptive_streaming/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a lightweight neural network to adaptively predict the optimal combination of frame rate and resolution for streaming rendered content, based on bandwidth constraints, scene content, and motion velocity. By exploiting spatio-temporal limits of the human visual system, the approach aims to improve perceived quality over fixed-rate/resolution baselines while reducing rendering computational costs. The network is trained on a large dataset of rendered content labeled by a perceptual video quality metric; the system is codec-agnostic and requires only minimal modifications to existing rendering pipelines. A project webpage link is provided for the dataset.
Significance. If substantiated with quantitative validation, the work could meaningfully advance remote rendering and cloud gaming for resource-constrained mobile devices by enabling content- and motion-aware adaptation that balances quality and cost. The codec-agnostic design and dataset release are strengths that support broader adoption and reproducibility in adaptive video streaming research.
major comments (3)
- [Abstract] Abstract: the central claim that the NN prediction 'significantly enhances perceptual quality while minimizing computational cost' is unsupported by any quantitative results, baseline comparisons (e.g., fixed 30/60 fps at reduced resolution), error bars, or statistical tests in the manuscript text.
- [Abstract] Abstract and training description: the perceptual video quality metric used to generate training labels is unnamed and unvalidated; no correlation analysis, subjective study, or ablation on metric choice is reported for the specific regime of adaptive frame rates and resolutions on rendered content, where temporal artifacts may be mis-scored by standard metrics.
- [Method] Method section: insufficient detail is given on network architecture, input representation of content and motion velocity, loss function, or training hyperparameters, preventing assessment of whether the model actually learns a generalizable mapping or simply memorizes the (unspecified) metric.
minor comments (1)
- [Abstract] The dataset webpage link is given but the manuscript lacks even a high-level summary of dataset size, diversity of rendered content, motion ranges, or label generation procedure.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the significance of our work and for their detailed and constructive comments. We address each major comment point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the NN prediction 'significantly enhances perceptual quality while minimizing computational cost' is unsupported by any quantitative results, baseline comparisons (e.g., fixed 30/60 fps at reduced resolution), error bars, or statistical tests in the manuscript text.
Authors: We agree that the abstract's claim requires clear support from the reported results. The experiments section presents quantitative comparisons of the adaptive predictions against fixed frame-rate and resolution baselines under varying bandwidth constraints, along with perceptual quality scores. To address the concern directly, we will revise the abstract to summarize these findings more precisely and avoid any unsupported phrasing. revision: yes
-
Referee: [Abstract] Abstract and training description: the perceptual video quality metric used to generate training labels is unnamed and unvalidated; no correlation analysis, subjective study, or ablation on metric choice is reported for the specific regime of adaptive frame rates and resolutions on rendered content, where temporal artifacts may be mis-scored by standard metrics.
Authors: We will revise the manuscript to explicitly name the perceptual video quality metric used to label the training data. While we did not perform a new subjective study or metric ablation specific to adaptive frame-rate/resolution rendering (which would be resource-intensive), we will add a discussion citing prior validation of the metric on video content and acknowledge its potential limitations with temporal artifacts in this regime. revision: partial
-
Referee: [Method] Method section: insufficient detail is given on network architecture, input representation of content and motion velocity, loss function, or training hyperparameters, preventing assessment of whether the model actually learns a generalizable mapping or simply memorizes the (unspecified) metric.
Authors: We apologize for the insufficient detail in the original submission. The revised manuscript will include a full specification of the network architecture, the input encoding for scene content and motion velocity, the loss function, and all training hyperparameters. This will allow readers to evaluate the model's generalizability. revision: yes
Circularity Check
No significant circularity; derivation is self-contained via external labels
full rationale
The paper describes training a lightweight neural network on a dataset of rendered content labeled by an external perceptual video quality metric to predict frame-rate and resolution pairs. No equations, self-citations, or fitted parameters are shown to reduce the central prediction or quality claim to the inputs by construction. The approach is presented as learning from independent labels rather than renaming or tautologically re-deriving its own assumptions, satisfying the criteria for a non-circular derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human visual system has exploitable spatio-temporal limits for perceived quality in rendered video
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel uncleara lightweight neural network predicts the optimal combination of frame rate and resolution... trained on a large dataset of rendered content labeled with a perceptual video quality metric... extended the existing video quality metric, ColorVideoVDP
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclearexploit the spatio-temporal limits of the human visual system... JOD quality... pixels rendered per second
Reference graph
Works this paper leans on
-
[1]
ACM Transactions on Graphics , author =
Shading atlas streaming , volume =. ACM Transactions on Graphics , author =. 2018 , pages =. doi:10.1145/3272127.3275087 , abstract =
-
[2]
Computer Graphics Forum , volume =
Hladky, Jozef and Seidel, Hans-Peter and Steinberger, Markus , title =. Computer Graphics Forum , volume =. 2021 , doi =
work page 2021
-
[3]
and Steinberger, Markus and Schmalstieg, Dieter , title =
Neff, Thomas and Mueller, Joerg H. and Steinberger, Markus and Schmalstieg, Dieter , title =. Computer Graphics Forum , volume =. 2022 , doi =
work page 2022
-
[4]
ACM Transactions on Graphics , volume =
Hladky, Jozef and Stengel, Michael and Vining, Nicholas and Kerbl, Bernhard and Seidel, Hans-Peter and Steinberger, Markus , title =. ACM Transactions on Graphics , volume =. 2022 , doi =
work page 2022
-
[5]
ACM Transactions on Graphics , volume =
Lu, Edward and Rowe, Anthony , title =. ACM Transactions on Graphics , volume =. 2025 , doi =
work page 2025
-
[6]
ACM Transactions on Graphics , author =. 2022 , keywords =. doi:10.1145/3550454.3555524 , abstract =
-
[7]
Computer Graphics Forum , author =
Tessellated. Computer Graphics Forum , author =. 2019 , pages =. doi:10.1111/cgf.13780 , abstract =
-
[8]
Tumanov, Alexey and Allison, Robert and Stuerzlinger, Wolfgang , month = jan, year =. Variability-. doi:10.1109/VR.2007.352472 , abstract =
-
[9]
A Perceptual Model of Motion Quality for Rendering with Adaptive Refresh-rate and Resolution , volume=. ACM Transactions on Graphics , author=. 2020 , month=aug, language=. doi:10.1145/3386569.3392411 , number=
-
[10]
ColorVideoVDP: A visual difference predictor for image, video and display distortions , year =
Mantiuk, Rafa. ColorVideoVDP: A visual difference predictor for image, video and display distortions , year =. ACM Trans. Graph. , month = jul, articleno =. doi:10.1145/3658144 , abstract =
-
[11]
Bhat, Madhukar and Thiesse, Jean-Marc and Le Callet, Patrick , booktitle=. A Case Study of Machine Learning Classifiers for Real-Time Adaptive Resolution Prediction in Video Coding , year=
-
[12]
Bhat, Madhukar and Thiesse, Jean-Marc and Callet, Patrick Le , booktitle=. Combining Video Quality Metrics To Select Perceptually Accurate Resolution In A Wide Quality Range: A Case Study , year=
-
[13]
Adaptive Frameless Rendering , booktitle =
Dayal, Abhinav and Woolley, Cliff and Watson, Benjamin and Luebke, David , urldate =. Adaptive Frameless Rendering , booktitle =
-
[14]
The Journal of Physiology , volume=
The Mechanics of Human Saccadic Eye Movement , author=. The Journal of Physiology , volume=. 1964 , month=. doi:10.1113/jphysiol.1964.sp007485 , pmid=
-
[15]
Two-Frame Motion Estimation Based on Polynomial Expansion , isbn =
Farnebäck, Gunnar , urldate =. Two-Frame Motion Estimation Based on Polynomial Expansion , isbn =. Proceedings of the 13th Scandinavian conference on Image analysis , publisher =
-
[16]
Dynamic Frame-Rate Selection for Live LBR Video Encoders Using Trial Frames , year=
Thammineni, Arunoday and Raman, Arvind and Vadapalli, Sarat Chandra and Sethuraman, Sriram , booktitle=. Dynamic Frame-Rate Selection for Live LBR Video Encoders Using Trial Frames , year=
-
[17]
Sharma, Mohit K. and Liu, Chen-Feng and Farhat, Ibrahim and Sehad, Nassim and Hamidouche, Wassim and Debbah, Merouane , month = oct, year =
-
[18]
Huang, Chun-Ying and Hsu, Cheng-Hsin and Chang, Yu-Chun and Chen, Kuan-Ta , month = feb, year =. Proceedings of the 4th. doi:10.1145/2483977.2483981 , language =
-
[19]
Shea, Ryan and Liu, Jiangchuan and Cui, Yong , file =. Cloud
-
[20]
Duarte Jr, Elias and Pozo, Aurora and Beltrani, Pamela , month = mar, year =. Smart. doi:10.1016/j.entcom.2019.100336 , journal =
-
[21]
Kharitonov, Vasily Y. , month = dec, year =. Motion-aware adaptive dead reckoning algorithm for collaborative virtual environments , isbn =. Proceedings of the 11th. doi:10.1145/2407516.2407577 , language =
-
[22]
The Visual Computer , author =
On. The Visual Computer , author =. 2000 , pages =. doi:10.1007/s003710050198 , abstract =
-
[23]
Yahyavi, Amir and Huguenin, Kévin and Kemme, Bettina , month = oct, year =. Proceedings of the 10th
-
[24]
Training and Predicting Visual Error for Real-Time Applications , volume =
Cardoso, Joao Liborio and Kerbl, Bernhard and Yang, Lei and Uralsky, Yury and Wimmer, Michael , urldate =. Training and Predicting Visual Error for Real-Time Applications , volume =. doi:10.1145/3522625 , abstract =
-
[25]
Wiegand, T. and Sullivan, G.J. and Bjontegaard, G. and Luthra, A. , urldate =. Overview of the H.264/. doi:10.1109/TCSVT.2003.815165 , abstract =
-
[26]
Edge computing: current trends, research challenges and future directions , volume =
Carvalho, Gonçalo and Cabral, Bruno and Pereira, Vasco and Bernardino, Jorge , urldate =. Edge computing: current trends, research challenges and future directions , volume =. doi:10.1007/s00607-020-00896-5 , shorttitle =
-
[27]
An Overview of Coding Tools in
Chen, Yue and Mukherjee, Debargha and Han, Jingning and Grange, Adrian and Xu, Yaowu and Parker, Sarah and Chen, Cheng and Su, Hui and Joshi, Urvang and Chiang, Ching-Han and Wang, Yunqing and Wilkins, Paul and Bankoski, Jim and Trudeau, Luc and Egge, Nathan and Valin, Jean-Marc and Davies, Thomas and Midtskogen, Steinar and Norkin, Andrey and Liu, Zoe , ...
-
[28]
doi:10.1109/VCIP.2017.8305033 , shorttitle =
Chen, Tong and Liu, Haojie and Shen, Qiu and Yue, Tao and Cao, Xun and Ma, Zhan , date =. doi:10.1109/VCIP.2017.8305033 , shorttitle =
-
[29]
doi:10.1109/TIP.2016.2601264 , abstract =
Liu, Zhenyu and Yu, Xianyu and Gao, Yuan and Chen, Shaolin and Ji, Xiangyang and Wang, Dongsheng , date =. doi:10.1109/TIP.2016.2601264 , abstract =
-
[30]
doi:10.48550/arXiv.1812.00101 , shorttitle =
Lu, Guo and Ouyang, Wanli and Xu, Dong and Zhang, Xiaoyun and Cai, Chunlei and Gao, Zhiyong , urldate =. doi:10.48550/arXiv.1812.00101 , shorttitle =. 1812.00101 [cs, eess] , keywords =
-
[31]
doi:10.48550/arXiv.2109.10849 , shorttitle =
Zhang, Saiping and Mrak, Marta and Herranz, Luis and Górriz, Marc and Wan, Shuai and Yang, Fuzheng , urldate =. doi:10.48550/arXiv.2109.10849 , shorttitle =. 2109.10849 [cs, eess] , keywords =
-
[32]
Rate-Perception Optimized Preprocessing for Video Coding , url =
Ma, Chengqian and Wu, Zhiqiang and Cai, Chunlei and Zhang, Pengwei and Wang, Yi and Zheng, Long and Chen, Chao and Zhou, Quan , urldate =. Rate-Perception Optimized Preprocessing for Video Coding , url =. doi:10.48550/arXiv.2301.10455 , abstract =. 2301.10455 [cs, eess] , keywords =
-
[33]
Wang, Zhou and Bovik, Alan C. , urldate =. Mean squared error: Love it or leave it? A new look at Signal Fidelity Measures , volume =. doi:10.1109/MSP.2008.930649 , shorttitle =
-
[34]
doi:10.5555/197765.197784 , note =
What's wrong with mean-squared error?. doi:10.5555/197765.197784 , note =
-
[35]
and Ohm, Jens-Rainer and Han, Woo-Jin and Wiegand, Thomas , urldate =
Sullivan, Gary J. and Ohm, Jens-Rainer and Han, Woo-Jin and Wiegand, Thomas , urldate =. Overview of the High Efficiency Video Coding (. doi:10.1109/TCSVT.2012.2221191 , abstract =
-
[36]
Kalman, R. E. , urldate =. A New Approach to Linear Filtering and Prediction Problems , volume =. doi:10.1115/1.3662552 , abstract =
-
[37]
Cisco Annual Internet Report - Cisco Annual Internet Report (2018–2023) White Paper , url =
work page 2018
-
[38]
Evangelakos, Daniel and Mara, Michael , urldate =. Extended. Proceedings of the 20th. doi:10.1145/2856400.2876015 , eventtitle =
-
[39]
Post-Render Warp with Late Input Sampling Improves Aiming Under High Latency Conditions , volume =
Kim, Joohwan and Knowles, Pyarelal and Spjut, Josef and Boudaoud, Ben and Mcguire, Morgan , date =. Post-Render Warp with Late Input Sampling Improves Aiming Under High Latency Conditions , volume =. doi:10.1145/3406187 , abstract =
-
[40]
Revealing the realities of collaborative virtual reality , isbn =
Fraser, Mike and Glover, Tony and Vaghi, Ivan and Benford, Steve and Greenhalgh, Chris and Hindmarsh, Jon and Heath, Christian , urldate =. Revealing the realities of collaborative virtual reality , isbn =. Proceedings of the third international conference on Collaborative virtual environments , publisher =. doi:10.1145/351006.351010 , series =
-
[41]
Revealing delay in collaborative environments , isbn =
Gutwin, Carl and Benford, Steve and Dyck, Jeff and Fraser, Mike and Vaghi, Ivan and Greenhalgh, Chris , urldate =. Revealing delay in collaborative environments , isbn =. Proceedings of the. doi:10.1145/985692.985756 , series =
-
[42]
High and Low Ping and the Game of Pong , url =
Wikstrand, Greger , urldate =. High and Low Ping and the Game of Pong , url =
-
[43]
The human factors of consistency maintenance in multiplayer computer games
-
[44]
A forecasting algorithm for latency compensation in indirect human-computer interactions , url =
Ushirobira, Rosane and Efimov, Denis and Casiez, Géry and Roussel, Nicolas and Perruquetti, Wilfrid , urldate =. A forecasting algorithm for latency compensation in indirect human-computer interactions , url =. 2016 European Control Conference (. doi:10.1109/ECC.2016.7810433 , abstract =
-
[45]
doi:10.1145/3132272.3134138 , shorttitle =
Le, Huy Viet and Schwind, Valentin and Göttlich, Philipp and Henze, Niels , date =. doi:10.1145/3132272.3134138 , shorttitle =
-
[46]
Lee, Wai-Kiu and Chang, Rocky K. C. , urldate =. Evaluation of lag-related configurations in first-person shooter games , isbn =. Proceedings of the 2015 International Workshop on Network and Systems Support for Games , publisher =
work page 2015
-
[47]
and Gutwin, Carl and Brown, Michelle , date =
Savery, Cheryl and Graham, T.C. and Gutwin, Carl and Brown, Michelle , date =. The effects of consistency maintenance methods on player experience and performance in networked games , doi =
-
[48]
Savery, Cheryl and Graham, T. C. , urldate =. Timelines: simplifying the programming of lag compensation for the next generation of networked games , volume =. doi:10.1007/s00530-012-0271-3 , shorttitle =
-
[49]
Lee, Kyungmin and Chu, David and Cuervo, Eduardo and Kopf, Johannes and Degtyarev, Yury and Grizan, Sergey and Wolman, Alec and Flinn, Jason , urldate =. Outatime: Using Speculation to Enable Low-Latency Continuous Interaction for Mobile Cloud Gaming , isbn =. Proceedings of the 13th Annual International Conference on Mobile Systems, Applications, and Ser...
-
[50]
and Stach, Tadeusz and Gutwin, Carl , urldate =
Bateman, Scott and Mandryk, Regan L. and Stach, Tadeusz and Gutwin, Carl , urldate =. Target assistance for subtly balancing competitive play , isbn =. Proceedings of the. doi:10.1145/1978942.1979287 , series =
-
[51]
Quantifying and Mitigating the Negative Effects of Local Latencies on Aiming in 3D Shooter Games
-
[52]
Sabet, Saeed Shafiee and Schmidt, Steven and Zadtootaghaj, Saman and Naderi, Babak and Griwodz, Carsten and Möller, Sebastian , urldate =. A latency compensation technique based on game characteristics to mitigate the influence of delay on cloud gaming quality of experience , isbn =. Proceedings of the 11th. doi:10.1145/3339825.3391855 , series =
-
[53]
Streamline Performance Analyzer , url =
-
[54]
Perceptual model for adaptive local shading and refresh rate
-
[55]
Qualcomm Snapdragon 888 levels up mobile gaming , url =
-
[56]
Yadav, Himanshu and Annappa, B , urldate =. Adaptive. 2017 Conference on Information and Communication Technology (. doi:10.1109/INFOCOMTECH.2017.8340641 , abstract =
-
[57]
Kreis, Roland , urldate =. Issues of spectral quality in clinical 1H-magnetic resonance spectroscopy and a gallery of artifacts , volume =. doi:10.1002/nbm.891 , abstract =
-
[58]
Cadik, M. and Slavik, P. , urldate =. Evaluation of two principal approaches to objective image quality assessment , url =. Proceedings. Eighth International Conference on Information Visualisation, 2004. doi:10.1109/IV.2004.1320193 , abstract =
-
[59]
Nguyen, T. B and Ziou, D , urldate =. Contextual and non-contextual performance evaluation of edge detectors , volume =. doi:10.1016/S0167-8655(00)00045-3 , abstract =
-
[60]
2010 20th International Conference on Pattern Recognition , author =
Image Quality Metrics:. 2010 20th International Conference on Pattern Recognition , author =. doi:10.1109/ICPR.2010.579 , shorttitle =
-
[61]
Simon Kallweit and Petrik Clarberg and Craig Kolb and Tom\'. The. 2022 , month =
work page 2022
- [62]
- [63]
- [64]
-
[65]
Cabrera, Gerardo Delgado , date =
-
[66]
Soundararajan, Rajiv and Bovik, Alan C. , urldate =. Video Quality Assessment by Reduced Reference Spatio-Temporal Entropic Differencing , volume =. doi:10.1109/TCSVT.2012.2214933 , abstract =
-
[67]
Digital twins in health care: ethical implications of an emerging engineering paradigm,
Zadtootaghaj, Saman and Barman, Nabajeet and Schmidt, Steven and Martini, Maria G. and Möller, Sebastian , urldate =. 2018. doi:10.1109/ISM.2018.00031 , shorttitle =
-
[68]
doi:10.1007/s11042-020-09144-6 , abstract =
-
[69]
and Li, Zhi and Mantiuk, Rafał K
Hammou, Dounia and Krasula, Lukáš and Bampis, Christos G. and Li, Zhi and Mantiuk, Rafał K. , urldate =. The Effect of Viewing Distance and Display Peak Luminance —. 2024 16th International Conference on Quality of Multimedia Experience (. doi:10.1109/QoMEX61742.2024.10598289 , abstract =
-
[70]
Chen, Bowen and Lee, Cheng-han and Chen, Yixu and Shang, Zaixi and Wei, Hai and Bovik, Alan C. , urldate =. doi:10.48550/arXiv.2505.21831 , shorttitle =. 2505.21831 [cs] , keywords =
-
[71]
2017 IEEE International Conference on Image Processing (ICIP) , pages=
A frame rate dependent video quality metric based on temporal wavelet decomposition and spatiotemporal pooling , author=. 2017 IEEE International Conference on Image Processing (ICIP) , pages=. 2017 , organization=
work page 2017
-
[72]
and Raake, Alexander and Möller, Sebastian , urldate =
Zadtootaghaj, Saman and Barman, Nabajeet and Rao, Rakesh Rao Ramachandra and Göring, Steve and Martini, Maria G. and Raake, Alexander and Möller, Sebastian , urldate =. 2020. doi:10.1109/MMSP48831.2020.9287080 , shorttitle =
-
[73]
Ruderman, D. L. , urldate =. The statistics of natural images , volume =. doi:10.1088/0954-898X/5/4/006 , abstract =
-
[74]
Quality Assessment of In-the-Wild Videos , url =
Li, Dingquan and Jiang, Tingting and Jiang, Ming , urldate =. Quality Assessment of In-the-Wild Videos , url =. Proceedings of the 27th. doi:10.1145/3343031.3351028 , abstract =. 1908.00375 [cs] , keywords =
-
[75]
doi:10.1109/TIP.2018.2831899 , shorttitle =
Talebi, Hossein and Milanfar, Peyman , urldate =. doi:10.1109/TIP.2018.2831899 , shorttitle =. 1709.05424 [cs] , keywords =
-
[76]
Yu, Xiangxu and Ying, Zhenqiang and Birkbeck, Neil and Wang, Yilin and Adsumilli, Balu and Bovik, Alan C. , journal=. Subjective and Objective Analysis of Streamed Gaming Videos , year=
-
[77]
nofu — A Lightweight No-Reference Pixel Based Video Quality Model for Gaming Content , url =
Göring, Steve and Rao, Rakesh Rao Ramachandra and Raake, Alexander , urldate =. nofu — A Lightweight No-Reference Pixel Based Video Quality Model for Gaming Content , url =. 2019 Eleventh International Conference on Quality of Multimedia Experience (. doi:10.1109/QoMEX.2019.8743262 , abstract =
-
[78]
ACM Transactions on Graphics , author=
Perceptual Model for Adaptive Local Shading and Refresh Rate , volume=. ACM Transactions on Graphics , author=. doi:10.1145/3478513.3480514 , number=
-
[79]
Vining, N. and Majercik, Z. and Gu, F. and Takikawa, T. and Trusty, T. and Lalonde, P. and McGuire, M. and Sheffer, A. , year=. FastAtlas: Real‐Time Compact Atlases for Texture Space Shading , ISSN=. doi:10.1111/cgf.70010 , journal=
-
[80]
The NETFLIX Tech Blog , volume=
Dynamic Optimizer---A Perceptual Video Encoding Optimization Framework , author=. The NETFLIX Tech Blog , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.