Recognition: 2 theorem links
· Lean TheoremTowards Scalable Persistence-Based Topological Optimization
Pith reviewed 2026-05-13 01:36 UTC · model grok-4.3
The pith
Replacing kernel interpolation with Nadaraya-Watson smoothing and random slicing subsampling makes persistence-based topological optimization of point clouds scalable.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Persistence-based topological optimization minimizes a loss that depends on the persistence diagram of a point cloud. The authors introduce random slicing as a subsampling scheme that reduces density bias and iteration-wise coverage problems, then replace the costly Reproducing Kernel Hilbert Space interpolation of sparse topological gradients with a Nadaraya-Watson Gaussian convolution. They supply anchor approximation bounds and global Lipschitz estimates for the new smoother, and experiments on standard 2-D and 3-D persistence losses show consistent speed-ups together with improved final objective values relative to prior baselines.
What carries the argument
Nadaraya-Watson Gaussian convolution that turns sparse topological gradients into a globally defined smooth update field, replacing RKHS interpolation while preserving the necessary approximation properties for optimization.
If this is right
- Larger point clouds become feasible because the dominant cost of gradient extension drops from a kernel solve to a simple convolution.
- Random slicing produces more uniform geometric coverage across optimization steps and reduces the effect of initial density variations.
- Theoretical bounds on anchor approximation and global Lipschitz continuity support the claim that the smoothed field remains usable for gradient descent.
- The combined pipeline yields both faster run times and lower final loss values on common 2-D and 3-D persistence objectives.
Where Pith is reading between the lines
- The same smoothing idea could be tested on other sparse-gradient problems that arise outside topological data analysis.
- Adaptive slicing rules that depend on the current persistence diagram might further improve coverage.
- Integration with automatic differentiation libraries would allow end-to-end training of models whose loss includes persistence terms.
- The method opens the door to real-time or interactive topological editing of 3-D meshes once the per-iteration cost falls below interactive thresholds.
Load-bearing premise
Nadaraya-Watson smoothing must approximate the topological gradients closely enough that the resulting optimization still reaches good values on the persistence objectives.
What would settle it
An experiment in which the final persistence loss values obtained with Nadaraya-Watson smoothing are systematically higher than those obtained with full RKHS interpolation on identical initial point clouds and loss functions.
Figures






read the original abstract
Persistence-based topological optimization deforms a point cloud $X \subset \mathbb{R}^d$ by minimizing objectives of the form $L(X) = \ell(\mathrm{Dgm}(X))$, where $\mathrm{Dgm}(X)$ is a persistence diagram. In practice, optimization is limited by two coupled issues: persistent homology is typically computed on subsamples, and the resulting topological gradients are highly sparse, with only a few anchor points receiving nonzero updates. Motivated by diffeomorphic interpolation, which extends sparse gradients to smooth ambient vector fields via Reproducing Kernel Hilbert Space (RKHS) interpolation, we propose a more scalable pipeline that improves both subsampling and gradient extension. We introduce subsampling via random slicing, a lightweight scheme that promotes iteration-wise geometric coverage and mitigates density bias. We further replace the costly kernel solve with a fast Nadaraya-Watson (NW) Gaussian convolution, producing a globally defined smooth update field at a fraction of the computational cost, while being more suited for topological optimization tasks. We provide theoretical guarantees for NW smoothing, including anchor approximation bounds and global Lipschitz estimates. Experiments in $2$D and $3$D show that combining random slicing with NW smoothing yields consistent speedups and improved objective values over other baselines on common persistence losses.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a scalable pipeline for persistence-based topological optimization of point clouds X by minimizing L(X) = ℓ(Dgm(X)). It introduces random slicing for subsampling to improve geometric coverage and mitigate density bias, and replaces RKHS interpolation with Nadaraya-Watson (NW) Gaussian convolution for extending sparse topological gradients to a smooth ambient field. Theoretical guarantees are claimed for NW smoothing (anchor approximation bounds and global Lipschitz estimates), and 2D/3D experiments report consistent speedups and better final objective values over baselines on common persistence losses.
Significance. If the central claims hold, the work could meaningfully improve the practicality of topological optimization for larger point clouds by reducing the cost of kernel solves while maintaining or improving optimization quality. The provision of theoretical bounds and reproducible experimental comparisons on standard losses are positive elements that strengthen the contribution relative to purely heuristic extensions.
major comments (2)
- [§4] §4 (NW smoothing): the anchor approximation bounds and global Lipschitz estimates are stated but the manuscript provides no derivation or quantitative bound on the induced perturbation to the persistence loss landscape L(X); local weighted averaging over sparse anchors can dilute or misalign gradient directions in low-density regions, and it is unclear whether the reported objective gains isolate this effect from baseline variance or random slicing.
- [Experiments] Experiments section: the comparison tables report speedups and improved objectives for the combined random-slicing + NW pipeline, but lack an ablation isolating the NW step alone (e.g., random slicing + RKHS vs. random slicing + NW) and do not report variance across multiple runs or sensitivity to the NW bandwidth parameter, leaving the claim that NW “preserves optimization effectiveness” only partially supported.
minor comments (2)
- [§2] Notation for the persistence diagram Dgm(X) and the loss ℓ should be introduced with a brief reminder of the standard filtration and persistence pairing in §2 to aid readers unfamiliar with the exact setup.
- [Figures] Figure captions for the 2D/3D optimization trajectories should explicitly state the number of points, the specific persistence loss used, and the bandwidth chosen for NW to allow direct reproduction.
Simulated Author's Rebuttal
We thank the referee for their thoughtful comments, which help improve the clarity and rigor of our work. We address each major comment point by point below, proposing specific revisions to the manuscript.
read point-by-point responses
-
Referee: §4 (NW smoothing): the anchor approximation bounds and global Lipschitz estimates are stated but the manuscript provides no derivation or quantitative bound on the induced perturbation to the persistence loss landscape L(X); local weighted averaging over sparse anchors can dilute or misalign gradient directions in low-density regions, and it is unclear whether the reported objective gains isolate this effect from baseline variance or random slicing.
Authors: We agree that the derivations were omitted for brevity. In the revised manuscript, we will include a full derivation of the anchor approximation bounds and global Lipschitz estimates in the appendix. Furthermore, we will derive a quantitative bound on the perturbation to L(X) by composing the Lipschitz constant of ℓ with the approximation error of the NW field, showing that the perturbation is controlled by the bandwidth and the number of anchors. Regarding potential misalignment in low-density regions, the random slicing ensures better coverage, reducing such issues compared to uniform subsampling. To address isolation of effects, we will add the requested ablation in the experiments. revision: yes
-
Referee: Experiments section: the comparison tables report speedups and improved objectives for the combined random-slicing + NW pipeline, but lack an ablation isolating the NW step alone (e.g., random slicing + RKHS vs. random slicing + NW) and do not report variance across multiple runs or sensitivity to the NW bandwidth parameter, leaving the claim that NW “preserves optimization effectiveness” only partially supported.
Authors: We concur that an isolated ablation would strengthen the experimental validation. We will add a new table or subsection comparing random slicing combined with RKHS interpolation versus random slicing with NW smoothing, using the same random seeds where possible. Additionally, we will rerun the experiments with multiple random seeds (at least 5) and report mean and standard deviation of the objective values and runtimes. For the bandwidth parameter, we will include a sensitivity plot or table showing performance across a range of bandwidth values (e.g., 0.1 to 1.0 times the average inter-point distance), demonstrating robustness. These additions will provide stronger support for the effectiveness of NW smoothing. revision: yes
Circularity Check
No significant circularity; methods and bounds are independently derived
full rationale
The paper's core pipeline—random slicing for subsampling plus Nadaraya-Watson smoothing in place of RKHS interpolation—is introduced as a new scalable alternative, supported by fresh anchor approximation bounds and global Lipschitz estimates that are stated directly rather than fitted or renamed from prior results. No equation reduces a claimed prediction to a fitted parameter by construction, no uniqueness theorem is imported from the authors' own prior work, and the experimental claims rest on external baseline comparisons rather than self-referential data. The derivation chain therefore remains self-contained against the stated assumptions and does not collapse to its inputs.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclearWe replace the costly kernel solve with a fast Nadaraya-Watson (NW) Gaussian convolution... anchor approximation bounds and global Lipschitz estimates.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_strictMono_of_one_lt unclearrandom slicing... evenly spaced ranks in a random 1D projection
Reference graph
Works this paper leans on
-
[1]
Nicolas Bonneel, Julien Rabin, Gabriel Peyr ´e, and Hanspeter Pfister
doi: 10.1007/s41468-021-00071-5. Nicolas Bonneel, Julien Rabin, Gabriel Peyr ´e, and Hanspeter Pfister. Sliced and radon wasserstein barycenters of measures.Journal of Mathematical Imaging and Vision, 51(1):22–45, Jan
-
[2]
Sliced and Radon Wasserstein Barycenters of Measures , journal =
ISSN 1573-7683. doi: 10.1007/s10851-014-0506-3. URLhttps://doi.org/10.1007/ s10851-014-0506-3. Mathieu Carri`ere, Marc Theveneau, and Th ´eo Lacombe. Diffeomorphic interpolation for efficient persistence-based topological optimization,
-
[3]
David Cohen-Steiner, Herbert Edelsbrunner, and John Harer
doi: 10.1109/TPAMI.2020.3013679. David Cohen-Steiner, Herbert Edelsbrunner, and John Harer. Stability of persistence diagrams. Discrete & Computational Geometry, 37(1):103–120,
-
[4]
David Cohen-Steiner, Herbert Edelsbrunner, John Harer, and Yuriy Mileyko
doi: 10.1007/s00454-006-1276-5. David Cohen-Steiner, Herbert Edelsbrunner, John Harer, and Yuriy Mileyko. Lipschitz functions have l p -stable persistence.Found. Comput. Math., 10(2):127–139, February
-
[5]
doi: 10.1007/ s00454-002-2885-2
ISSN 1432-0444. doi: 10.1007/ s00454-002-2885-2. URLhttps://doi.org/10.1007/s00454-002-2885-2. Th´eo Lacombe, Yuichi Ike, Mathieu Carriere, Fr ´ed´eric Chazal, Marc Glisse, and Yuhei Umeda. Topological uncertainty: Monitoring trained neural networks through persistence of activation graphs,
-
[6]
Weiquan Liu, Hanyun Guo, Weini Zhang, Yu Zang, Cheng Wang, and Jonathan Li
URLhttps://arxiv.org/abs/2105.04404. Weiquan Liu, Hanyun Guo, Weini Zhang, Yu Zang, Cheng Wang, and Jonathan Li. Toposeg: Topology-aware segmentation for point clouds. In Lud De Raedt (ed.),Proceedings of the Thirty- First International Joint Conference on Artificial Intelligence, IJCAI-22, pp. 1201–1208. Inter- national Joint Conferences on Artificial In...
-
[7]
doi: 10.24963/ijcai. 2022/168. URLhttps://doi.org/10.24963/ijcai.2022/168. Main Track. Michael Moor, Max Horn, Bastian Rieck, and Karsten Borgwardt. Topological autoencoders. In Proceedings of the 37th International Conference on Machine Learning, volume 119 ofProceed- ings of Machine Learning Research, pp. 7045–7054,
-
[8]
3 - lipschitz functions and rectifiable sets
10 GRaM workshop at ICLR 2026 Proceedings Track Frank Morgan. 3 - lipschitz functions and rectifiable sets. In Frank Morgan (ed.),Geometric Measure Theory (Fifth Edition), pp. 25–38. Academic Press, fifth edition edition,
work page 2026
-
[9]
doi: https://doi.org/10.1016/B978-0-12-804489-6.50003-3
ISBN 978-0-12- 804489-6. doi: https://doi.org/10.1016/B978-0-12-804489-6.50003-3. URLhttps://www. sciencedirect.com/science/article/pii/B9780128044896500033. E. A. Nadaraya. On estimating regression.Theory of Probability and Its Applications, 9(1):141–142,
-
[10]
Theory of Probability & Its Applica- tions9(1), 141–142 (1964) https://doi.org/10.1137/1109020
doi: 10.1137/1109020. Julien Rabin, Gabriel Peyr´e, Julie Delon, and Marc Bernot. Wasserstein barycenter and its applica- tion to texture mixing. In Alfred M. Bruckstein, Bart M. ter Haar Romeny, Alexander M. Bron- stein, and Michael M. Bronstein (eds.),Scale Space and Variational Methods in Computer Vision, pp. 435–446, Berlin, Heidelberg,
-
[11]
Primoz Skraba and Katharine Turner
doi: 10.1007/s00454-013-9513-1. Primoz Skraba and Katharine Turner. Wasserstein stability for persistence diagrams.arXiv: Algebraic Topology,
-
[12]
Association for Computing Machinery. ISBN 0897916670. doi: 10.1145/192161.192241. URLhttps://doi.org/10.1145/192161.192241. Geoffrey S. Watson. Smooth regression analysis.Sankhy ¯a: The Indian Journal of Statistics, Series A, 26:359–372,
-
[13]
doi: 10.1007/s00454-004-1146-y. 11 GRaM workshop at ICLR 2026 Proceedings Track A ALGORITHMS A.1 PROJECTION-STRATIFIED SUBSAMPLING(RANDOM SLICING) Algorithm 1Projection-stratified subsampling (random slicing) Require:Point cloudX={x i}n i=1 ⊂R d, subsample sizes 1:Sampleu∼ N(0, I d)and normalizeu←u/∥u∥ 2 2:Compute projectionst i ← ⟨x i, u⟩fori= 1, . . . ,...
-
[14]
Since¯x(x)is a convex combination of points inP, it lies inConv(P), hence ∥xi −¯x(x)∥2 ≤diam(P)
Hence, ∥∇wi(x)∥2 = wi(x) σ2 ∥xi −¯x(x)∥2. Since¯x(x)is a convex combination of points inP, it lies inConv(P), hence ∥xi −¯x(x)∥2 ≤diam(P). 14 GRaM workshop at ICLR 2026 Proceedings Track Differentiate¯v(x) =P i wi(x)gi: D¯v(x) = X i∈I (∇wi(x))⊗g i. Using∥a⊗b∥ op =∥a∥ 2∥b∥2, ∥D¯v(x)∥op ≤ X i ∥∇wi(x)∥2 ∥gi∥2 ≤M X i ∥∇wi(x)∥2 . Apply Lemma B.1: X i ∥∇wi(x)∥2...
work page 2026
-
[15]
15 GRaM workshop at ICLR 2026 Proceedings Track C ADDITIONAL KERNEL VS
The Lipschitz inequality follows from the mean value theorem. 15 GRaM workshop at ICLR 2026 Proceedings Track C ADDITIONAL KERNEL VS. NWVISUALIZATIONS Figure 5:Kernel interpolation vs. NW smoothing under four anchor configurations.In each panel, the left sub-plot is exact Gaussian-RKHS interpolation (KERNEL) and the right sub-plot is Nadaraya-Watson smoot...
work page 2026
-
[16]
Figure 6 shows the initial and final configurations together with the loss curves
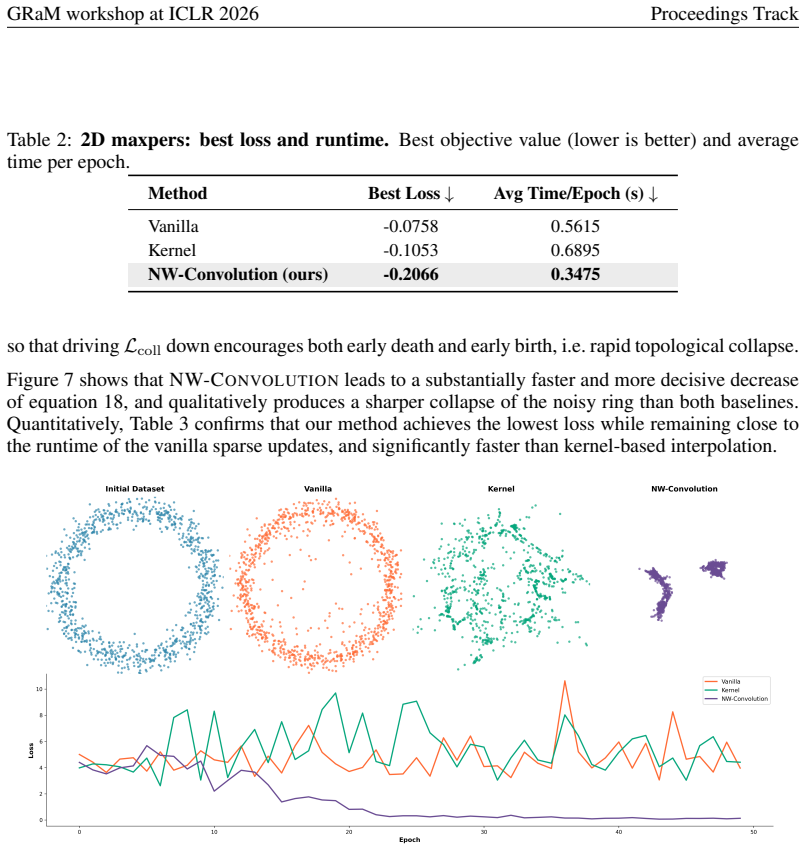
We optimize forT= 300epochs. Figure 6 shows the initial and final configurations together with the loss curves. The vanilla method remains limited by the sparsity of the topological gradient, whereas both smoothing-based methods propagate the sparse signal to non-anchor points and more reliably shape the cloud toward con- figurations with strongerH 1 pers...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.