Recognition: 2 theorem links
· Lean TheoremBenchmarking LLM-Based Static Analysis for Secure Smart Contract Development: Reliability, Limitations, and Potential Hybrid Solutions
Pith reviewed 2026-05-13 02:14 UTC · model grok-4.3
The pith
Large language models cannot reliably audit smart contracts on their own because they depend on variable names rather than code semantics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Large language models are not viable as autonomous security auditors for smart contracts. Their efficacy is limited by inherent lexical bias and insufficient validation of external data, leading to high rates of false positives through reliance on non-semantic heuristics such as identifier naming. Prompting techniques exhibit a precision-recall trade-off. These findings rest on a custom automated framework that classifies model outputs with 92 percent accuracy.
What carries the argument
Custom automated framework that classifies LLM outputs on smart contract vulnerabilities at 92 percent accuracy, used to benchmark models and prompting strategies against test contracts.
If this is right
- LLMs function best as complements to traditional static analysis tools rather than standalone auditors for smart contracts.
- Reliance on identifier naming as a heuristic generates unreliable results in vulnerability detection.
- Prompt engineering can shift the balance between precision and recall but does not remove the underlying lexical bias.
- Hybrid solutions that pair LLM suggestions with semantic checks offer a route to improved security analysis.
Where Pith is reading between the lines
- Future model training on datasets that prioritize code semantics over surface lexical features could reduce false positives in security tasks.
- The same classification framework could be reused to measure LLM performance on vulnerability detection in other programming languages or domains.
- Post-processing LLM outputs with execution simulation or formal verification steps might compensate for the observed limitations.
Load-bearing premise
The custom automated framework classifies LLM outputs correctly at 92 percent accuracy and the tested prompts and contracts represent real-world smart contract security analysis.
What would settle it
Manual review of LLM vulnerability reports on a fresh collection of deployed smart contracts that produces substantially different false-positive rates than the framework reports.
Figures


read the original abstract
The irreversible nature of blockchain transactions makes the identification of smart contract vulnerabilities an essential requirement for secure system development. While Large Language Models (LLMs) are increasingly integrated into developer workflows, their reliability as autonomous security auditors remains unproven. We assess whether current generative models are a viable replacement for, or only a complement to, traditional static-analysis tools. Our findings indicate that LLM efficacy is undermined by both inherent lexical bias and a lack of rigorous validation of external data inputs. This reliance on non-semantic heuristics, such as identifier naming, leads to a high frequency of false positives. Furthermore, prompting techniques reveal a trade-off between precision and recall. These results were derived using our custom automated framework, which achieves 92% accuracy in classifying model outputs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper benchmarks LLMs for static analysis of smart contracts, claiming that their efficacy is undermined by lexical bias (reliance on non-semantic heuristics like identifier naming) leading to high false positives, that prompting techniques exhibit precision-recall trade-offs, and that a custom automated framework classifies LLM outputs at 92% accuracy relative to ground truth, supporting recommendations for hybrid LLM-traditional tool solutions.
Significance. If the custom framework's 92% accuracy holds under disclosed validation and the tested contracts/prompts are representative, the results would highlight practically important limitations of LLMs as autonomous security auditors in blockchain contexts, providing empirical grounding for hybrid approaches and cautioning against over-reliance on generative models for vulnerability detection.
major comments (2)
- [Abstract] Abstract: The central claim that the custom automated framework 'achieves 92% accuracy in classifying model outputs' is load-bearing for all quantitative results (false-positive frequency, lexical bias, precision-recall trade-offs), yet the manuscript supplies no details on validation methodology, ground-truth construction, validation-set size, expert annotation process, or inter-rater agreement. Without these, the reported findings cannot be assessed for circularity or error correlation with the lexical patterns under study.
- [Methods/Results] Methods/Results sections: No information is given on dataset size, number of contracts, specific LLMs evaluated, precise vulnerability definitions or taxonomies used, or direct baseline comparisons against established static-analysis tools, leaving the generalizability of the 'high frequency of false positives' and 'lexical bias' conclusions unsupported.
minor comments (1)
- [Abstract] Abstract: The phrase 'lack of rigorous validation of external data inputs' is vague; clarify whether this refers to LLM training data, prompt inputs, or contract source code.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment point by point below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the custom automated framework 'achieves 92% accuracy in classifying model outputs' is load-bearing for all quantitative results (false-positive frequency, lexical bias, precision-recall trade-offs), yet the manuscript supplies no details on validation methodology, ground-truth construction, validation-set size, expert annotation process, or inter-rater agreement. Without these, the reported findings cannot be assessed for circularity or error correlation with the lexical patterns under study.
Authors: We agree that the manuscript currently lacks sufficient methodological details on the validation of the custom automated framework, which is necessary to fully substantiate the 92% accuracy figure and allow assessment of potential circularity or bias. In the revised version, we will add a dedicated subsection to the Methods section that describes the validation methodology in full, including ground-truth construction, validation-set size, the expert annotation process, and inter-rater agreement statistics. We will also explicitly discuss any limitations related to error correlation with the lexical patterns studied. revision: yes
-
Referee: [Methods/Results] Methods/Results sections: No information is given on dataset size, number of contracts, specific LLMs evaluated, precise vulnerability definitions or taxonomies used, or direct baseline comparisons against established static-analysis tools, leaving the generalizability of the 'high frequency of false positives' and 'lexical bias' conclusions unsupported.
Authors: We acknowledge that the current manuscript does not provide these key details, which limits the ability to evaluate generalizability. The revised manuscript will expand the Methods and Results sections to include the dataset size and number of contracts analyzed, the specific LLMs evaluated, the precise vulnerability definitions and taxonomies employed, and direct baseline comparisons against established static-analysis tools such as Slither and Mythril. These additions will provide stronger empirical support for the reported findings on false-positive rates and lexical bias. revision: yes
Circularity Check
No significant circularity in empirical benchmarking study
full rationale
The paper is an empirical benchmarking study of LLMs for smart contract vulnerability detection. It reports results derived from a custom automated classification framework stated to achieve 92% accuracy, but contains no equations, mathematical derivations, fitted parameters, or self-referential definitions that reduce any claim to its own inputs by construction. The central findings on lexical bias and false positives are presented as outcomes of applying the framework to LLM outputs on external contracts, without any quoted reduction showing the framework's classifications are forced by the same heuristics under critique or by self-citation chains. This is a standard data-driven evaluation whose validity hinges on the (undetailed) framework rather than circular logic.
Axiom & Free-Parameter Ledger
axioms (1)
- ad hoc to paper The custom automated framework classifies LLM outputs with 92% accuracy relative to ground truth
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our findings indicate that LLM efficacy is undermined by both inherent lexical bias and a lack of rigorous validation of external data inputs. This reliance on non-semantic heuristics, such as identifier naming, leads to a high frequency of false positives.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat ≃ Nat recovery unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We built a reusable infrastructure that allows the experiments to be run consistently... automatic classifier... achieves 92% accuracy
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al.: Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Arusoaie, A., Susan, S.: Towards trusted smart contracts: A comprehen- sive test suite for vulnerability detection. Empir. Softw. Eng.29(5), 117 (2024). https://doi.org/10.1007/S10664-024-10509-W
-
[3]
Atzei, N., Bartoletti, M., Cimoli, T.: A survey of attacks on Ethereum smart contracts (SoK). In: Maffei, M., Ryan, M. (eds.) Principles of Security and Trust. pp. 164–186. Springer, Berlin, Heidelberg (2017)
work page 2017
-
[4]
https://hackingdistributed.com/2017/07/22/deep- dive-parity-bug/ (July 2017)
Breidenbach, L., Daian, P., Juels, A., Sirer, E.G.: An in-depth look at the parity multisig bug. https://hackingdistributed.com/2017/07/22/deep- dive-parity-bug/ (July 2017)
work page 2017
-
[5]
https://ethereum.org/en/whitepaper/ (dec 2014)
Buterin, V .: A next-generation smart contract and decentralized applica- tion platform. https://ethereum.org/en/whitepaper/ (dec 2014)
work page 2014
-
[6]
ACM Computing Surveys (Csur)54(2), 1–37 (2021)
Chandrasekaran, D., Mago, V .: Evolution of semantic similarity—a survey. ACM Computing Surveys (Csur)54(2), 1–37 (2021)
work page 2021
- [7]
-
[8]
Chen, C., Su, J., Chen, J., Wang, Y ., Bi, T., Yu, J., Wang, Y ., Lin, X., Chen, T., Zheng, Z.: When ChatGPT meets smart contract vulnerability detection: How far are we? ACM Transactions on Software Engineering and Methodology (2023)
work page 2023
-
[9]
Feist, J., Greico, G., Groce, A.: Slither: A static analysis framework for smart contracts. In: Proceedings of the 2nd International Workshop on Emerging Trends in Software Engineering for Blockchain (WETSEB ’19), pp. 8–15. IEEE Press, Montreal, Quebec, Canada (2019). https: //doi.org/10.1109/WETSEB.2019.00008
-
[10]
Ferreira, J., Durieux, T., Maranhao, R.: Smartbugs wild. https://github. com/smartbugs/smartbugs-wild (2020)
work page 2020
-
[11]
https://github.com/smartbugs/ smartbugs-curated (2023)
Ferreira, J., Salzer, G.: Smartbugs curated. https://github.com/smartbugs/ smartbugs-curated (2023)
work page 2023
-
[12]
In: Proceedings of the 35th IEEE/ACM International Conference on Automated Software Engineer- ing
Ferreira, J.a.F., Cruz, P., Durieux, T., Abreu, R.: Smartbugs: A frame- work to analyze Solidity smart contracts. In: Proceedings of the 35th IEEE/ACM International Conference on Automated Software Engineer- ing. p. 1349–1352. ASE ’20, ACM, New York, NY , USA (2020). https://doi.org/10.1145/3324884.3415298
-
[13]
Gemini Team: Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context (2024), https://arxiv.org/abs/2403.05530
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
https://github.com/ DependableSystemsLab/SolidiFI-benchmark (2020)
Ghaleb, A., Pattabiraman, K.: Solidifi benchmark. https://github.com/ DependableSystemsLab/SolidiFI-benchmark (2020)
work page 2020
-
[15]
Grishchenko, I., Maffei, M., Schneidewind, C.: A semantic framework for the security analysis of Ethereum smart contracts. In: Bauer, L., K¨usters, R. (eds.) Principles of Security and Trust. pp. 243–269. Springer International Publishing, Cham (2018)
work page 2018
-
[16]
Mense, A., Flatscher, M.: Security vulnerabilities in Ethereum smart contracts. In: Proceedings of the 20th International Conference on Information Integration and Web-Based Applications and Ser- vices. p. 375–380. iiW AS2018, ACM, New York, NY , USA (2018). https://doi.org/10.1145/3282373.3282419
-
[17]
Mikolov, T., Chen, K., Corrado, G., Dean, J.: Efficient estimation of word representations in vector space (2013), https://arxiv.org/abs/1301. 3781
work page 2013
-
[18]
https://dasp.co/ (2018), accessed: 2023-04-04
NCC-Group: Decentralized application security project. https://dasp.co/ (2018), accessed: 2023-04-04
work page 2018
-
[19]
In: Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP)
Pennington, J., Socher, R., Manning, C.D.: Glove: Global vectors for word representation. In: Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP). pp. 1532– 1543 (2014)
work page 2014
-
[20]
IEEE Access7, 78194–78213 (2019)
Pinna, A., Ibba, S., Baralla, G., Tonelli, R., Marchesi, M.: A massive analysis of ethereum smart contracts empirical study and code metrics. IEEE Access7, 78194–78213 (2019). https://doi.org/10.1109/ACCESS.2019.2921936
-
[21]
Frontiers in Blockchain 5(2022)
Rameder, H., di Angelo, M., Salzer, G.: Review of automated vulnera- bility analysis of smart contracts on Ethereum. Frontiers in Blockchain 5(2022). https://doi.org/10.3389/fbloc.2022.814977
-
[22]
International Journal of Advanced Research in Computer Science13, 51003–51010 (2022)
Sharma, N., Sharma, S.: A survey of mythril, a smart contract security analysis tool for evm bytecode. International Journal of Advanced Research in Computer Science13, 51003–51010 (2022)
work page 2022
-
[23]
In: 2015 IEEE International Symposium on Software Reliability Engineering Workshops (ISSREW)
Shiraishi, S., Mohan, V ., Marimuthu, H.: Test suites for benchmarks of static analysis tools. In: 2015 IEEE International Symposium on Software Reliability Engineering Workshops (ISSREW). pp. 12–15 (2015). https://doi.org/10.1109/ISSREW.2015.7392027
-
[24]
https://www.coindesk.com/learn/2016/06/25/understanding-the-dao- attack/ (July 2016)
Siegel, D.: Understanding the dao attack. https://www.coindesk.com/learn/2016/06/25/understanding-the-dao- attack/ (July 2016)
work page 2016
-
[25]
https://docs.soliditylang.org/en/v0.8.16/, ac- cessed: 2022-09-01
Solidity documentation. https://docs.soliditylang.org/en/v0.8.16/, ac- cessed: 2022-09-01
work page 2022
-
[26]
https://github.com/SunWeb3Sec/ DeFiHackLabs/ (2023)
SunWeb3Sec: Defihacks. https://github.com/SunWeb3Sec/ DeFiHackLabs/ (2023)
work page 2023
-
[27]
Smart contract weakness classification and test cases. https://swcregistry. io/, accessed: 2023-04-04
work page 2023
-
[28]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y ., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
A Prompt Pattern Catalog to Enhance Prompt Engineering with ChatGPT
White, J., Fu, Q., Hays, S., Sandborn, M., Olea, C., Gilbert, H., Elnashar, A., Spencer-Smith, J., Schmidt, D.C.: A prompt pattern catalog to enhance prompt engineering with ChatGPT. arXiv preprint arXiv:2302.11382 (2023)
work page internal anchor Pith review arXiv 2023
-
[30]
arXiv preprint arXiv:2501.07058 (2025)
Xiao, Z., Wang, Q., Pearce, H., Chen, S.: Logic meets magic: Llms cracking smart contract vulnerabilities. arXiv preprint arXiv:2501.07058 (2025)
-
[31]
https://github.com/renardbebe/Smart-Contract-Benchmark-Suites (2021)
Xu, Z., Ren, M.: Smart-contract-benchmark-suites: A unified dataset. https://github.com/renardbebe/Smart-Contract-Benchmark-Suites (2021)
work page 2021
-
[32]
Young, A., et al.: Yi: Open foundation models by 01.AI (2025), https: //arxiv.org/abs/2403.04652
work page internal anchor Pith review arXiv 2025
-
[33]
Zhang, L., Ergen, T., Logeswaran, L., Lee, M., Jurgens, D.: Sprig: Improving large language model performance by system prompt op- timization (2024), https://arxiv.org/abs/2410.14826
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
https://github.com/ ZhangZhuoSJTU/Web3Bugs/tree/main (2022)
Zhang, Z., Zhang, B., Xu, W., Lin, Z.: Web3bugs. https://github.com/ ZhangZhuoSJTU/Web3Bugs/tree/main (2022)
work page 2022
-
[35]
Lost in the Middle: How Language Models Use Long Contexts
N. F. Liu, K. Lin, J. Hewitt, A. Paranjape, M. Bevilacqua, F. Petroni, and P. Liang, “Lost in the middle: How language models use long contexts,” arXiv preprint arXiv:2307.03172, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
RepoFusion: Training code models to understand your repository,
D. Shrivastava, D. Kocetkov, H. de Vries, D. Bahdanau, and T. Scholak, “RepoFusion: Training code models to understand your repository,” arXiv preprint arXiv:2306.10998, 2023
-
[37]
P. Shojaee, I. Mirzadeh, K. Alizadeh, M. Horton, S. Bengio, and M. Farajtabar, “The illusion of thinking: Understanding the strengths and limitations of reasoning models via the lens of problem complexity,” inProc. 38th Conf. Neural Inf. Process. Syst. (NeurIPS), 2025
work page 2025
-
[38]
Why Language Models Hallucinate
A. T. Kalai, O. Nachum, S. S. Vempala, and E. Zhang, “Why language models hallucinate,”arXiv preprint arXiv:2509.04664, 2025
work page internal anchor Pith review arXiv 2025
-
[39]
On the dangers of stochastic parrots: Can language models be too big?
E. M. Bender, T. Gebru, A. McMillan-Major, and S. Shmitchell, “On the dangers of stochastic parrots: Can language models be too big?” inProc. 2021 ACM Conf. Fairness, Accountability, and Transparency (FAccT), 2021, pp. 610–623
work page 2021
-
[40]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” inProc. 30th Conf. Neural Inf. Process. Syst. (NIPS), 2017
work page 2017
-
[41]
LLM.int8(): 8- bit Matrix Multiplication for Transformers at Scale,
T. Dettmers, M. Lewis, Y . Belkada, and L. Zettlemoyer, “LLM.int8(): 8- bit Matrix Multiplication for Transformers at Scale,”Advances in Neural Information Processing Systems, vol. 35, pp. 22128–22142, 2022
work page 2022
-
[42]
A Survey of Quantization Methods for Efficient Neural Network Inference,
A. Gholami, S. Kim, Z. Dong, Z. Yao, M. W. Mahoney, and K. Keutzer, “A Survey of Quantization Methods for Efficient Neural Network Inference,”Low-Power Computer Vision, pp. 291–326, 2021
work page 2021
-
[43]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers,
E. Frantar, S. Ashkboos, T. Hoefler, and D. Alistarh, “GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers,” in Proceedings of the 11th International Conference on Learning Repre- sentations (ICLR), 2023
work page 2023
-
[44]
QLoRA: Efficient Finetuning of Quantized LLMs,
T. Dettmers, A. Pagnoni, A. Holtzman, and L. Zettlemoyer, “QLoRA: Efficient Finetuning of Quantized LLMs,”Advances in Neural Informa- tion Processing Systems, vol. 36, 2023
work page 2023
-
[45]
Efficiently Scaling Transformer Inference,
R. Pope, S. Douglas, A. Chowdhery, C. Devane, J. Bradbury, A. Lev- skaya, J. Heek, K. Xiao, S. Agrawal, and J. Dean, “Efficiently Scaling Transformer Inference,” inProceedings of the 6th MLSys Conference, 2023
work page 2023
-
[46]
Language Models are Few-Shot Learners,
T. Brown et al., “Language Models are Few-Shot Learners,” inProc. 34th Conf. Neural Inf. Process. Syst. (NeurIPS), 2020, pp. 1877–1901
work page 2020
-
[47]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models,
J. Wei et al., “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models,” inProc. 36th Conf. Neural Inf. Process. Syst. (NeurIPS), 2022, pp. 24824–24837
work page 2022
-
[48]
LLM-Smart-Contract-Analysis-Benchmark: Solidity Bench- mark,
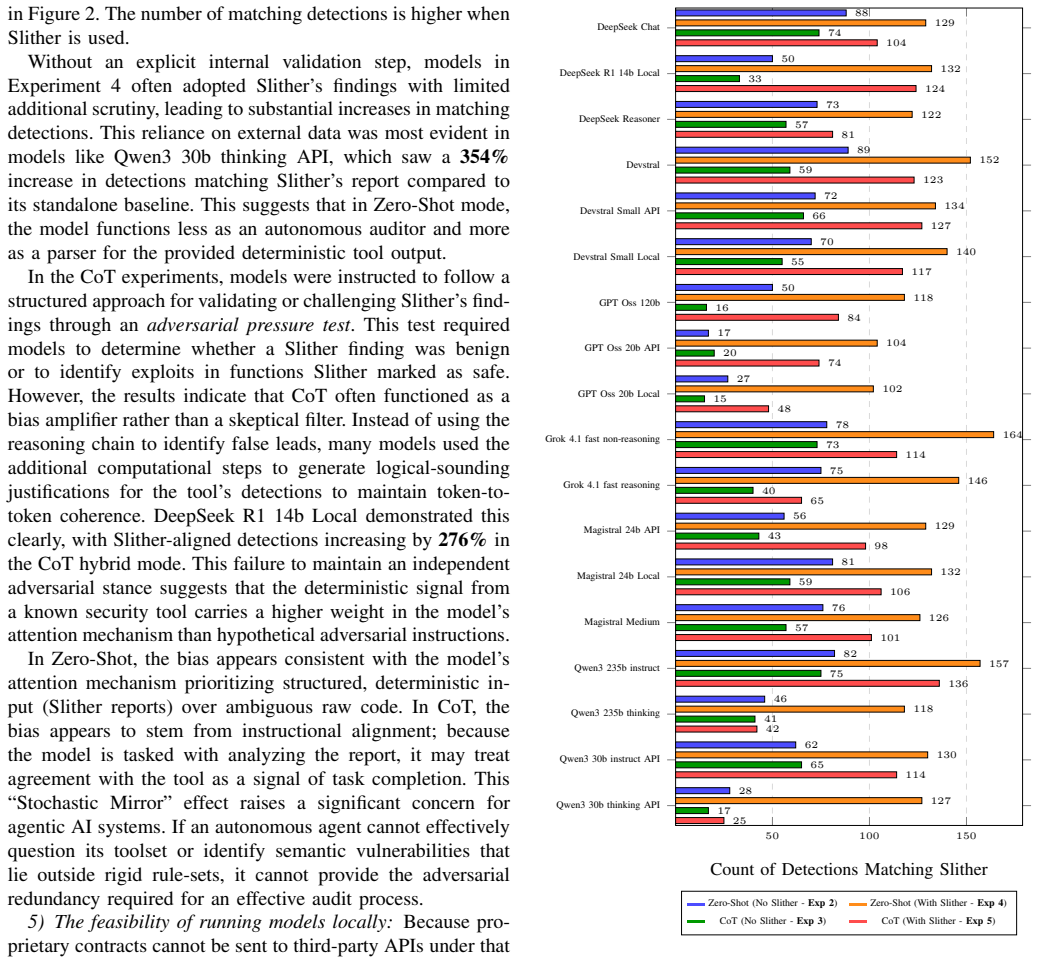
S. Susan, “LLM-Smart-Contract-Analysis-Benchmark: Solidity Bench- mark,” https://doi.org/10.5281/zenodo.20109866 APPENDIXA METHODOLOGYFLOWCHART This diagram provides a compact overview of the end-to-end benchmarking pipeline used in our study, from dataset preparation and prompt configuration to model execution and detection classification. It is intended...
-
[49]
Invariant Mapping: Identify the critical security invariants of this contract (e.g., ”Total deposits must always equal or exceed the sum of individual balances”). 2. Adversarial State Analysis: Systematically analyze every state-changing function. Determine if a sequence of transactions–potentially involving multiple users or flash-loan-funded interaction...
-
[50]
Use this to identify immediate ”hotspots” in the code
Baseline Triage: I have provided the Slither static analysis output below. Use this to identify immediate ”hotspots” in the code. In your internal reasoning, evaluate if these detections are true positives or if the contract’s specific business logic renders them non-exploitable. 2. Independent Invariant Mapping: Disregard the Slither output for a moment ...
work page 2031
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.