Recognition: no theorem link
Continuous Discovery of Vulnerabilities in LLM Serving Systems with Fuzzing
Pith reviewed 2026-05-13 02:01 UTC · model grok-4.3
The pith
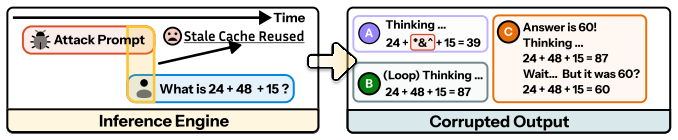
A greybox fuzzer called GRIEF finds 15 vulnerabilities in LLM inference engines by testing concurrent request traces that standard tests miss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GRIEF is a greybox fuzzer for LLM inference engines that treats timed multi-request traces as first-class inputs, uses lightweight oracles to detect crashes, hangs, performance pathologies, and silent output corruption, and applies controlled replay with log-probability checks to confirm reproducible serving-layer failures. Across campaigns on vLLM and SGLang it discovered 15 vulnerabilities, ten confirmed by engine developers and including two CVEs, that span KV-cache isolation failures, cross-request performance interference, and crash or liveness bugs. These results establish that concurrency, caching, and state reuse can produce silent cross-request contamination, noisy-neighbor denialof
What carries the argument
GRIEF, the greybox fuzzer that generates timed multi-request traces, applies lightweight oracles for serving anomalies, and verifies failures through controlled replay and log-probability checks.
If this is right
- Silent cross-request data contamination can occur without malformed inputs or server error messages.
- One request can impose performance degradation on others, creating a noisy-neighbor denial-of-service vector.
- Crashes and liveness failures can be delayed until specific sequences of state reuse occur.
- Standard model, safety, and API tests are insufficient for LLM serving infrastructure.
- Concurrent serving behavior must be treated as a first-class security and reliability boundary.
Where Pith is reading between the lines
- The same trace-based fuzzing strategy could be adapted to other shared-state components in AI pipelines such as training schedulers or retrieval systems.
- Engine maintainers could integrate continuous GRIEF-style campaigns into their release processes to catch regressions introduced by new caching or batching features.
- Isolation mechanisms in multi-tenant LLM deployments may need explicit verification against concurrent workloads rather than relying on per-request correctness alone.
Load-bearing premise
The lightweight oracles and replay checks with log-probability can reliably distinguish genuine serving-layer failures from test artifacts or model behavior.
What would settle it
Applying GRIEF to the same engines and obtaining zero reproducible, developer-confirmed vulnerabilities that the oracles had flagged as serving-layer issues.
Figures







read the original abstract
LLM inference and serving systems have become security-critical infrastructure; however, many of their most concerning failures arise from the serving layer rather than from model behavior alone. Modern inference engines combine KV cache, batching, prefix sharing, speculative decoding, adapters, and multi-tenant scheduling, creating shared-state behavior that only emerges under realistic concurrent workloads and is missed by standard model, safety, and API tests. We present GRIEF, a greybox fuzzer for LLM inference engines that treats timed multi-request traces as first-class inputs, uses lightweight oracles to detect crashes, hangs, performance pathologies, and silent output corruption, and applies controlled replay with log-probability checks to confirm reproducible serving-layer failures. Across early campaigns on vLLM and SGLang, GRIEF discovers 15 vulnerabilities, 10 confirmed by engine developers, including 2 CVEs, spanning KV-cache isolation failures, cross-request performance interference, and crash or liveness bugs. These results show that concurrency, caching, and state reuse can induce silent cross-request contamination, noisy-neighbor denial of service, and delayed crashes without malformed inputs or explicit server errors, making concurrent serving behavior a first-class security and reliability boundary for LLM infrastructure.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents GRIEF, a greybox fuzzer for LLM inference engines that treats timed multi-request traces as first-class inputs. It uses lightweight oracles to detect crashes, hangs, performance pathologies, and silent output corruption, combined with controlled replay and log-probability checks to confirm reproducible serving-layer failures. Across campaigns on vLLM and SGLang, the tool reports discovering 15 vulnerabilities (10 developer-confirmed, including 2 CVEs) related to KV-cache isolation, cross-request interference, and liveness issues.
Significance. If the oracle-based attribution holds, the work is significant because it demonstrates that shared-state behaviors in concurrent LLM serving (KV caching, batching, prefix sharing) create security and reliability boundaries missed by standard model, safety, and API testing. Developer confirmations and CVEs provide external validation of practical impact, and the greybox approach with domain-specific oracles could inform future fuzzing of AI infrastructure.
major comments (1)
- [Evaluation and oracle design sections] The central claim of 15 discovered vulnerabilities with 10 confirmations rests on the lightweight oracles and log-probability replay correctly attributing failures to serving-layer state rather than model nondeterminism or artifacts. The manuscript provides no explicit threshold for log-probability deltas, no baseline comparison to clean concurrent traces, and no ablation demonstrating that reported issues (e.g., cross-request contamination) are not triggered by benign KV-cache reuse or scheduler jitter. This is load-bearing for the results and directly engages the stress-test concern about oracle reliability.
minor comments (1)
- [Abstract] The abstract and results summary would benefit from additional quantitative details on campaign scale (e.g., total requests tested, false-positive rates, or raw oracle trigger counts) to allow readers to assess the effort behind the 15 discoveries.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of GRIEF's significance and for the constructive feedback on oracle reliability. We address the major comment below.
read point-by-point responses
-
Referee: [Evaluation and oracle design sections] The central claim of 15 discovered vulnerabilities with 10 confirmations rests on the lightweight oracles and log-probability replay correctly attributing failures to serving-layer state rather than model nondeterminism or artifacts. The manuscript provides no explicit threshold for log-probability deltas, no baseline comparison to clean concurrent traces, and no ablation demonstrating that reported issues (e.g., cross-request contamination) are not triggered by benign KV-cache reuse or scheduler jitter. This is load-bearing for the results and directly engages the stress-test concern about oracle reliability.
Authors: We agree that the manuscript would benefit from greater explicitness on these points to strengthen the attribution of failures to serving-layer behaviors. In the revised version we will expand the Evaluation section to specify the log-probability delta thresholds applied during replay, add a baseline comparison against clean concurrent traces (showing that the oracles remain silent under non-adversarial conditions), and include an ablation isolating benign KV-cache reuse and scheduler jitter from the fuzzed concurrent workloads. These additions will directly address the concern that reported issues such as cross-request contamination could arise from normal engine behavior. The ten developer confirmations already provide external evidence that the failures are genuine, but the requested analyses will improve the rigor of the oracle validation. revision: yes
Circularity Check
No circularity: empirical fuzzer presentation with external developer confirmations
full rationale
The paper describes GRIEF as a greybox fuzzer using timed traces, lightweight oracles, and log-probability replay to find serving-layer issues in vLLM and SGLang. All central claims (15 vulnerabilities found, 10 confirmed including 2 CVEs) rest on external developer validation rather than any internal equations, fitted parameters, or self-referential derivations. No load-bearing steps reduce by construction to the paper's own inputs; the work is a self-contained empirical tool report.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The LibAFL Fuzzing Library - The LibAFL Fuzzing Library
-
[2]
Tianle Cai, Yuhong Li, Zhengyang Geng, Hongwu Peng, Jason D. Lee, Deming Chen, and Tri Dao. Medusa: Simple llm inference acceleration framework with multiple decoding heads, 2024
work page 2024
-
[3]
Nicholas Carlini, Daniel Paleka, Krishnamurthy Dj Dvijotham, Thomas Steinke, Jonathan Hayase, A. Feder Cooper, Katherine Lee, Matthew Jagielski, Milad Nasr, Arthur Conmy, Itay Yona, Eric Wallace, David Rolnick, and Florian Tramèr. Stealing part of a production language model, 2024
work page 2024
-
[4]
Extracting training data from large language models, 2021
Nicholas Carlini, Florian Tramer, Eric Wallace, Matthew Jagielski, Ariel Herbert-V oss, Kather- ine Lee, Adam Roberts, Tom Brown, Dawn Song, Ulfar Erlingsson, Alina Oprea, and Colin Raffel. Extracting training data from large language models, 2021
work page 2021
-
[5]
Jailbreakbench: An open robustness benchmark for jailbreaking large language models
Patrick Chao, Edoardo Debenedetti, Alexander Robey, Maksym Andriushchenko, Francesco Croce, Vikash Sehwag, Edgar Dobriban, Nicolas Flammarion, George J Pappas, Florian Tramer, et al. Jailbreakbench: An open robustness benchmark for jailbreaking large language models. Advances in Neural Information Processing Systems, 37:55005–55029, 2024
work page 2024
-
[6]
Patrick Chao, Alexander Robey, Edgar Dobriban, Hamed Hassani, George J. Pappas, and Eric Wong. Jailbreaking black box large language models in twenty queries, 2024
work page 2024
-
[7]
LLM- Inference-Bench: Inference benchmarking of large language models on ai accelerators
Krishna Teja Chitty-Venkata, Siddhisanket Raskar, Bharat Kale, Farah Ferdaus, Aditya Tanikanti, Ken Raffenetti, Valerie Taylor, Murali Emani, and Venkatram Vishwanath. LLM- Inference-Bench: Inference benchmarking of large language models on ai accelerators. In Workshops of the International Conference for High Performance Computing, Networking, Storage an...
work page 2024
-
[8]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[9]
Yinlin Deng, Chunqiu Steven Xia, Haoran Peng, Chenyuan Yang, and Lingming Zhang. Large language models are zero-shot fuzzers: Fuzzing deep-learning libraries via large language models. InProceedings of the 32nd ACM SIGSOFT international symposium on software testing and analysis, pages 423–435, 2023
work page 2023
-
[10]
Size-aware Sharding For Improving Tail Latencies in In-memory Key-value Stores
Diego Didona and Willy Zwaenepoel. Size-aware Sharding For Improving Tail Latencies in In-memory Key-value Stores. pages 79–94
-
[11]
AFL++: Combining incremental steps of fuzzing research
Andrea Fioraldi, Dominik Maier, Heiko Eißfeldt, and Marc Heuse. AFL++: Combining incremental steps of fuzzing research. In14th USENIX Workshop on Offensive Technologies, 2020
work page 2020
-
[12]
LibAFL: A framework to build modular and reusable fuzzers
Andrea Fioraldi, Dominik Maier, Dongjia Zhang, and Davide Balzarotti. LibAFL: A framework to build modular and reusable fuzzers. InProceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security, pages 1051–1065, 2022
work page 2022
-
[13]
Pal: Program-aided language models,
Luyu Gao, Aman Madaan, Shuyan Zhou, Uri Alon, Pengfei Liu, Yiming Yang, Jamie Callan, and Graham Neubig. Pal: Program-aided language models.arXiv preprint arXiv:2211.10435, 2022. 10
-
[14]
Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. Not what you’ve signed up for: Compromising real-world llm-integrated applications with indirect prompt injection, 2023
work page 2023
-
[15]
Lorenz Kuhn, Yarin Gal, and Sebastian Farquhar. Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation. InThe Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[16]
vLLM: An Efficient Inference Engine for Large Language Models
Woosuk Kwon. vLLM: An Efficient Inference Engine for Large Language Models
-
[17]
Man Ho Lam, Chaozheng Wang, Jen-tse Huang, and Michael R Lyu. Codecrash: Stress testing llm reasoning under structural and semantic perturbations.arXiv e-prints, pages arXiv–2504, 2025
work page 2025
-
[18]
Fast Inference from Transformers via Speculative Decoding
Yaniv Leviathan, Matan Kalman, and Yossi Matias. Fast Inference from Transformers via Speculative Decoding
-
[19]
Hongwei Li and Yongjun Wang. Reliability of llm inference engines from a static perspective: Root cause analysis and repair suggestion via natural language reports.Big Data and Cognitive Computing, 10(2):60, 2026
work page 2026
-
[20]
Eagle: speculative sampling requires rethinking feature uncertainty
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. Eagle: speculative sampling requires rethinking feature uncertainty. InProceedings of the 41st International Conference on Machine Learning, ICML’24. JMLR.org, 2024
work page 2024
-
[21]
Eagle-3: Scaling up inference acceleration of large language models via training-time test, 2025
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. Eagle-3: Scaling up inference acceleration of large language models via training-time test, 2025
work page 2025
-
[22]
Holistic Evaluation of Language Models
Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michihiro Yasunaga, Yian Zhang, Deepak Narayanan, Yuhuai Wu, Ananya Kumar, Benjamin Newman, Binhang Yuan, Bobby Yan, Ce Zhang, Connor Cosgrove, Christopher D. Manning, Christopher Ré, Diana Acosta-Navas, Drew A. Hudson, Eric Zelikman, Esin Durmus, Faisal Ladhak, Frieda Rong, Hongyu Re...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[23]
Mugeng Liu, Siqi Zhong, Weichen Bi, Yixuan Zhang, Zhiyang Chen, Zhenpeng Chen, Xuanzhe Liu, and Yun Ma. A first look at bugs in llm inference engines.ACM Transactions on Software Engineering and Methodology, 2025
work page 2025
-
[24]
Autodan: Generating stealthy jailbreak prompts on aligned large language models, 2024
Xiaogeng Liu, Nan Xu, Muhao Chen, and Chaowei Xiao. Autodan: Generating stealthy jailbreak prompts on aligned large language models, 2024
work page 2024
-
[25]
Cachegen: Kv cache compression and streaming for fast large language model serving, 2024
Yuhan Liu, Hanchen Li, Yihua Cheng, Siddhant Ray, Yuyang Huang, Qizheng Zhang, Kuntai Du, Jiayi Yao, Shan Lu, Ganesh Ananthanarayanan, Michael Maire, Henry Hoffmann, Ari Holtzman, and Junchen Jiang. Cachegen: Kv cache compression and streaming for fast large language model serving, 2024
work page 2024
-
[26]
Graph- based fuzz testing for deep learning inference engines
Weisi Luo, Dong Chai, Xiaoyue Ruan, Jiang Wang, Chunrong Fang, and Zhenyu Chen. Graph- based fuzz testing for deep learning inference engines. In2021 IEEE/ACM 43rd International Conference on Software Engineering (ICSE), pages 288–299. IEEE, 2021
work page 2021
-
[27]
Harmbench: A standardized evaluation framework for automated red teaming and robust refusal, 2024
Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, David Forsyth, and Dan Hendrycks. Harmbench: A standardized evaluation framework for automated red teaming and robust refusal, 2024
work page 2024
-
[28]
Samyam Rajbhandari, Conglong Li, Zhewei Yao, Minjia Zhang, Reza Yazdani Aminabadi, Ammar Ahmad Awan, Jeff Rasley, and Yuxiong He. Deepspeed-moe: Advancing mixture-of- experts inference and training to power next-generation ai scale, 2022. 11
work page 2022
-
[29]
Scott Gardner, Itay Hubara, Sachin Idgunji, Thomas B
Vijay Janapa Reddi, Christine Cheng, David Kanter, Peter Mattson, Guenther Schmuelling, Carole-Jean Wu, Brian Anderson, Maximilien Breughe, Mark Charlebois, William Chou, Ramesh Chukka, Cody Coleman, Sam Davis, Pan Deng, Greg Diamos, Jared Duke, Dave Fick, J. Scott Gardner, Itay Hubara, Sachin Idgunji, Thomas B. Jablin, Jeff Jiao, Tom St. John, Pankaj Kan...
work page 2020
-
[30]
Ying Sheng, Shiyi Cao, Dacheng Li, Coleman Hooper, Nicholas Lee, Shuo Yang, Christopher Chou, Banghua Zhu, Lianmin Zheng, Kurt Keutzer, Joseph E. Gonzalez, and Ion Stoica. S-lora: Serving thousands of concurrent lora adapters, 2024
work page 2024
-
[31]
Sponge examples: Energy-latency attacks on neural networks, 2021
Ilia Shumailov, Yiren Zhao, Daniel Bates, Nicolas Papernot, Robert Mullins, and Ross Anderson. Sponge examples: Energy-latency attacks on neural networks, 2021
work page 2021
-
[32]
Qwen2.5: A party of foundation models, September 2024
Qwen Team. Qwen2.5: A party of foundation models, September 2024
work page 2024
- [33]
-
[34]
Fine- tuning language models for factuality
Katherine Tian, Eric Mitchell, Huaxiu Yao, Christopher D Manning, and Chelsea Finn. Fine- tuning language models for factuality. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[35]
Fuzz4all: Universal fuzzing with large language models
Chunqiu Steven Xia, Matteo Paltenghi, Jia Le Tian, Michael Pradel, and Lingming Zhang. Fuzz4all: Universal fuzzing with large language models. InProceedings of the IEEE/ACM 46th International Conference on Software Engineering, ICSE ’24, pages 1–13. ACM, April 2024
work page 2024
-
[36]
Orca: A Distributed Serving System for Transformer-Based Generative Models
Gyeong-In Yu, Joo Seong Jeong, Geon-Woo Kim, Soojeong Kim, and Byung-Gon Chun. Orca: A Distributed Serving System for Transformer-Based Generative Models. pages 521–538
-
[37]
Enabling performant and flexible model-internal observability for llm inference
Nengneng Yu, Sixian Xiong, Yibo Zhao, Wei Wang, and Zaoxing Liu. Enabling performant and flexible model-internal observability for llm inference. InAdvances in Neural Information Processing Systems (NeurIPS), 2026. To appear
work page 2026
-
[38]
Gonzalez, Clark Barrett, and Ying Sheng
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E. Gonzalez, Clark Barrett, and Ying Sheng. SGLang: Efficient execution of structured language model programs. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural I...
-
[39]
Zico Kolter, and Matt Fredrikson
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J. Zico Kolter, and Matt Fredrikson. Universal and transferable adversarial attacks on aligned language models, 2023. 12 A Appendix A.1 Threat Model GRIEF targets shared LLM inference-serving deployments in which multiple client requests may overlap in time and interact through shared serving mechanisms ...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.