Recognition: no theorem link
Comment and Control: Hijacking Agentic Workflows via Context-Grounded Evolution
Pith reviewed 2026-05-13 01:49 UTC · model grok-4.3
The pith
Adversaries can hijack agentic workflows by crafting inputs to control LLM agents for malicious actions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
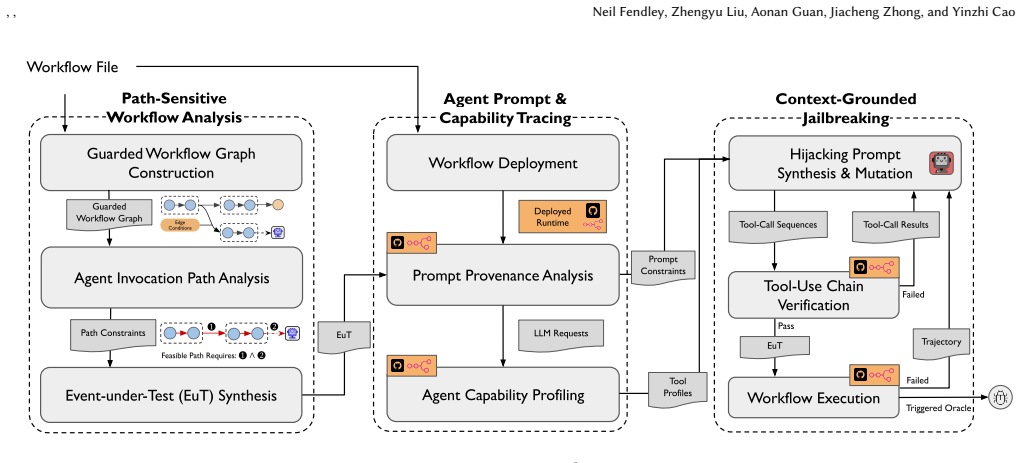
JAW enables the hijacking of agentic workflows through Context-Grounded Evolution by generating contexts via static path-feasibility analysis to find input constraints, dynamic prompt-provenance analysis to track input embedding into LLM prompts, and capability analysis to determine available agent actions, allowing crafted inputs to trigger unwanted behaviors.
What carries the argument
Context-Grounded Evolution, a method that evolves workflow inputs based on hybrid program analyses to achieve hijacking of LLM agents.
If this is right
- 4714 GitHub workflows can be hijacked to leak user credentials or execute commands.
- 15 widely-used GitHub Actions, including official ones for Claude Code and Gemini CLI, are vulnerable.
- Eight n8n templates are also susceptible to similar attacks.
- Adversaries can use GitHub issue comments to control agentic workflows without other access.
Where Pith is reading between the lines
- This suggests that input validation and sanitization should be prioritized in the design of agentic automation systems.
- The method could potentially apply to other platforms that combine LLMs with workflow automation.
- Developers relying on these workflows may need to review their configurations for untrusted input sources.
Load-bearing premise
The hybrid static, dynamic, and capability analyses accurately predict how inputs are transformed into LLM contexts and what actions the agents can perform.
What would settle it
Identifying a workflow that JAW marks as hijackable but in which the evolved input fails to cause the agent to perform the unwanted action due to additional runtime restrictions not captured in the analyses.
Figures



read the original abstract
Automation platforms such as GitHub Actions and n8n are increasingly adopting so-called agentic workflows, which integrate Large Language Model (LLM) agents for tasks such as code review and data synchronization. While bringing convenience for developers, this integration exposes a new risk: An adversary may control and craft certain inputs, such as GitHub issue comments, to manipulate the LLM agent for unwanted actions, such as credential exfiltration and arbitrary command execution. To our knowledge, no prior academic work has studied such a risk in agentic workflows. In this paper, we design the first detection and exploitation framework, called JAW, to hijack agentic workflows hosted on automation platforms via a novel approach called Context-Grounded Evolution. Our key idea is to evolve agentic workflow inputs under the contexts derived from hybrid program analysis for hijacking purposes. Specifically, JAW generates agentic workflow contexts through three analyses: (i) static path-feasibility analysis to identify feasible agent-invocation paths and the input constraints required to trigger them, (ii) dynamic prompt-provenance analysis to determine how that input is transformed and embedded into the LLM context, and (iii) capability analysis to identify the actions and restrictions available to the agent at runtime. Our evaluation of JAW on GitHub workflows and n8n templates showed that 4714 GitHub workflows and eight n8n templates can be successfully hijacked, for example, to leak user credentials. Our findings span 15 widely-used GitHub Actions, including official GitHub Actions for Claude Code, Gemini CLI, Qwen CLI, and Cursor CLI, and two official n8n nodes. We responsibly disclosed all findings to the affected vendors and received many acknowledgements, fixes, and bug bounties, notably from GitHub, Google, and Anthropic.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces JAW, the first framework for detecting and exploiting hijacks in agentic workflows on GitHub Actions and n8n via Context-Grounded Evolution. It combines static path-feasibility analysis, dynamic prompt-provenance analysis, and capability analysis to evolve inputs that manipulate LLM agents into unauthorized actions such as credential exfiltration. The evaluation reports that 4714 GitHub workflows and 8 n8n templates are vulnerable, spanning 15 GitHub Actions (including official ones for Claude Code, Gemini CLI, Qwen CLI, and Cursor CLI) and two official n8n nodes. All findings were responsibly disclosed, yielding acknowledgments, fixes, and bug bounties from vendors including GitHub, Google, and Anthropic.
Significance. If the results hold, the work is significant for highlighting a new, practical attack surface created by LLM integration into automation and CI/CD pipelines. The scale of affected workflows and inclusion of official vendor actions demonstrate broad real-world relevance. The responsible disclosure process and resulting vendor responses add concrete impact, potentially informing secure design of future agentic systems. The empirical focus on reproducible platform-specific findings is a strength.
major comments (2)
- [§5 (Evaluation)] §5 (Evaluation): The central claim that 4714 GitHub workflows and 8 n8n templates can be successfully hijacked depends on the hybrid analyses producing accurate models, but the section provides no details on verification methods, false-positive rates, test coverage, or explicit end-to-end confirmation that the evolved inputs produce the modeled LLM contexts when executed on the actual platforms.
- [§3.2 (Dynamic prompt-provenance analysis)] §3.2 (Dynamic prompt-provenance analysis): This component is load-bearing for generating effective hijacking inputs, yet the manuscript does not address or validate against platform-specific transformations such as escaping, concatenation, or formatting that occur in real runtime LLM prompt construction, raising the risk that the reported hijacks would not succeed as modeled.
minor comments (2)
- [Abstract] Abstract: The statement that findings 'span 15 widely-used GitHub Actions' would be clearer if it distinguished official vendor actions from third-party ones.
- [§2 (Background)] The manuscript uses several platform-specific terms (e.g., workflow triggers, node types) without a brief glossary or diagram, which could aid readers unfamiliar with GitHub Actions or n8n internals.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review, which highlights important aspects of our evaluation and analysis. We address each major comment below and have revised the manuscript to provide the requested clarifications and additional details.
read point-by-point responses
-
Referee: §5 (Evaluation): The central claim that 4714 GitHub workflows and 8 n8n templates can be successfully hijacked depends on the hybrid analyses producing accurate models, but the section provides no details on verification methods, false-positive rates, test coverage, or explicit end-to-end confirmation that the evolved inputs produce the modeled LLM contexts when executed on the actual platforms.
Authors: We acknowledge that the submitted manuscript's §5 would benefit from explicit discussion of verification methods. In the revised version, we add a new subsection detailing our approach: manual inspection of a random sample of 100 workflows for path feasibility, cross-validation against runtime execution traces for a subset of cases, and conservative bounding of false positives arising from the static analysis. For end-to-end confirmation, we expand the text to describe how vendor reproductions during responsible disclosure (including GitHub, Google, and Anthropic) served as independent validation that the evolved inputs produced the modeled contexts and hijacks on the live platforms. revision: yes
-
Referee: §3.2 (Dynamic prompt-provenance analysis): This component is load-bearing for generating effective hijacking inputs, yet the manuscript does not address or validate against platform-specific transformations such as escaping, concatenation, or formatting that occur in real runtime LLM prompt construction, raising the risk that the reported hijacks would not succeed as modeled.
Authors: The dynamic prompt-provenance analysis instruments the actual runtime prompt assembly to capture transformations such as escaping and concatenation. We will revise §3.2 to explicitly enumerate the platform-specific behaviors observed (e.g., GitHub Actions comment escaping and n8n node formatting) and how the provenance tracking accounts for them. We will also add empirical validation results showing that inputs evolved under the modeled contexts successfully trigger the hijacks when executed on the target platforms. revision: yes
Circularity Check
No significant circularity in empirical security evaluation
full rationale
The paper describes an empirical security tool JAW that applies three hybrid analyses (static path-feasibility, dynamic prompt-provenance, and capability) to identify hijackable agentic workflows on GitHub and n8n, then reports concrete evaluation results (4714 GitHub workflows and 8 n8n templates successfully hijacked). No equations, fitted parameters, self-definitional loops, or load-bearing self-citations appear in the derivation of the central claims. The reported hijacking successes are measured against external platforms and disclosed vendor responses rather than reducing to the analyses by construction. The work is therefore self-contained against external benchmarks with no circular reduction of predictions to inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Static path-feasibility analysis, dynamic prompt-provenance analysis, and capability analysis together accurately identify feasible agent-invocation paths, input transformations, and runtime restrictions.
Reference graph
Works this paper leans on
-
[1]
Chat gpt "dan" (and other "jailbreaks"). https://gist.github.com/coolaj86/ 6f4f7b30129b0251f61fa7baaa881516, 2026. GitHub repository, accessed 2026- 01-26
work page 2026
-
[2]
Bastys, I., Balliu, M., and Sabelfeld, A.If this then what?: Controlling flows in IoT apps. InProceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security (CCS ’18)(Oct. 2018), ACM, pp. 1102–1119
work page 2018
-
[3]
In2025 IEEE Secure Development Conference (SecDev)(Oct
Chaiwut, N., and Nikiforakis, N.Time for actions: A longitudinal study of the GitHub actions marketplace. In2025 IEEE Secure Development Conference (SecDev)(Oct. 2025), IEEE, pp. 118–128
work page 2025
-
[4]
Chao, P., Robey, A., Dobriban, E., Hassani, H., Pappas, G., and Wong, E. Jailbreaking black box large language models in twenty queries.2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML)(2023), 23–42
work page 2025
-
[5]
Clause, J., Li, W., and Orso, A.Dytan: A generic dynamic taint analysis frame- work. InProceedings of the 2007 International Symposium on Software Testing and Analysis(2007), ISSTA 2007, pp. 196–206
work page 2007
-
[6]
Costa, M., Köpf, B., Kolluri, A., Paverd, A., Russinovich, M., Salem, A., Tople, S., Wutschitz, L., and Zanella-Béguelin, S.Securing ai agents with information-flow control, 2025
work page 2025
-
[7]
Doshi, A., Hong, Y., Xu, C., Kang, E., Kapravelos, A., and Kästner, C.Towards verifiably safe tool use for LLM agents, 2026
work page 2026
-
[8]
InProceedings 2018 Network and Distributed System Security Symposium(2018)
Fernandes, E., Rahmati, A., Jung, J., and Prakash, A.Decentralized action integrity for trigger-action IoT platforms. InProceedings 2018 Network and Distributed System Security Symposium(2018)
work page 2018
-
[9]
https://github.com/google-gemini/gemini-cli, 2026
Gemini, G.Gemini CLI. https://github.com/google-gemini/gemini-cli, 2026. GitHub repository, accessed 2026-01-26. [10]GitHub. CodeQL. https://codeql.github.com/. Accessed: 2026-04-30
work page 2026
-
[10]
Google. Run Gemini CLI GitHub Action. https://github.com/google-github- actions/run-gemini-cli, 2025. GitHub repository, accessed 2026-04-22
work page 2025
-
[11]
Greshake, K., Abdelnabi, S., Mishra, S., Endres, C., Holz, T., and Fritz, M.Not what you’ve signed up for: Compromising real-world llm-integrated applications with indirect prompt injection.Proceedings of the 16th ACM Workshop on Artificial Intelligence and Security(2023)
work page 2023
-
[12]
He, P., Li, C., Zhao, B., Du, T., and Ji, S.Automatic red teaming llm-based agents with model context protocol tools, 2025
work page 2025
- [13]
-
[14]
InFindings of the Association for Computational Linguistics: NAACL 2025(Apr
Jiang, W., W ang, Z., Zhai, J., Ma, S., Zhao, Z., and Shen, C.ECLIPSE: Optimiz- able suffix via LLM as optimizer. InFindings of the Association for Computational Linguistics: NAACL 2025(Apr. 2025), Association for Computational Linguistics, pp. 5404–5424
work page 2025
-
[15]
Kafle, K., Jagtap, K., Ahmed-Rengers, M., Jaeger, T., and Nadkarni, A.Prac- tical integrity validation in the smart home with homeendorser. InProceedings of the 17th ACM Conference on Security and Privacy in Wireless and Mobile Networks (WiSec ’24)(May 2024), ACM, pp. 207–218
work page 2024
-
[16]
Kim, J., Choi, W., and Lee, B.Prompt flow integrity to prevent privilege escalation in llm agents, 2025
work page 2025
-
[17]
Kinsman, T., Wessel, M. S., Gerosa, M. A., and Treude, C.How do software developers use github actions to automate their workflows?2021 IEEE/ACM 18th International Conference on Mining Software Repositories (MSR)(2021), 420–431
work page 2021
-
[18]
In Proceedings of the IEEE European Symposium on Security and Privacy(June 2022)
Klein, D., Barber, T., Bensalim, S., Stock, B., and Johns, M.Hand sanitizers in the wild: A large-scale study of custom javascript sanitizer functions. In Proceedings of the IEEE European Symposium on Security and Privacy(June 2022)
work page 2022
-
[19]
In31st USENIX Security Symposium (USENIX Security 22)(Boston, MA, Aug
Koishybayev, I., Nahapetyan, A., Zachariah, R., Muralee, S., Reaves, B., Kapravelos, A., and Machiry, A.Characterizing the security of github CI workflows. In31st USENIX Security Symposium (USENIX Security 22)(Boston, MA, Aug. 2022), USENIX Association, pp. 2747–2763
work page 2022
-
[20]
Liu, X., Li, P., Suh, E., Vorobeychik, Y., Mao, Z., Jha, S., McDaniel, P., Sun, H., Li, B., and Xiao, C.Autodan-turbo: A lifelong agent for strategy self-exploration to jailbreak llms, 2025
work page 2025
-
[21]
Cuckoo attack: Stealthy and persistent attacks against ai-ide, 2025
Liu, X., Liu, J., Liu, P., Zheng, H., W ang, Q., Payer, M., Ji, S., and W ang, W. Cuckoo attack: Stealthy and persistent attacks against ai-ide, 2025
work page 2025
-
[22]
https://gail.wharton.upenn.edu/research-and-insights/call-me-a-jerk- persuading-ai/, July 2025
Meincke, L., Shapiro, D., Duckworth, A., Mollick, E., Mollick, L., and Cialdini, R.Call me a jerk: Persuading AI to comply with objectionable re- quests. https://gail.wharton.upenn.edu/research-and-insights/call-me-a-jerk- persuading-ai/, July 2025. Accessed: 2025-8-13
work page 2025
-
[23]
Microsoft Research. Z3: An efficient SMT solver. https://www.microsoft.com/ en-us/research/project/z3-3/. Accessed: 2026-04-30
work page 2026
-
[24]
In32nd USENIX Security Symposium (USENIX Security 23)(Anaheim, CA, Aug
Muralee, S., Koishybayev, I., Nahapetyan, A., Tystahl, G., Reaves, B., Bianchi, A., Enck, W., Kapravelos, A., and Machiry, A.ARGUS: A framework for staged static taint analysis of GitHub workflows and actions. In32nd USENIX Security Symposium (USENIX Security 23)(Anaheim, CA, Aug. 2023), USENIX Association, pp. 6983–7000
work page 2023
-
[25]
V., Hayes, J., Ilie, M., Pluto, J., Song, S., Chaudhari, H., Shumailov, I., Thakurta, A., Xiao, K
Nasr, M., Carlini, N., Sitawarin, C., Schulhoff, S. V., Hayes, J., Ilie, M., Pluto, J., Song, S., Chaudhari, H., Shumailov, I., Thakurta, A., Xiao, K. Y., Terzis, A., and Tramèr, F.The attacker moves second: Stronger adaptive attacks bypass defenses against llm jailbreaks and prompt injections.arXiv [cs.LG](Oct. 2025)
work page 2025
-
[26]
Ignore Previous Prompt: Attack Techniques For Language Models
Perez, F., and Ribeiro, I.Ignore previous prompt: Attack techniques for language models.ArXiv abs/2211.09527(2022). [28]Samsung. Jalangi2: Dynamic analysis framework for JavaScript. https://github. com/Samsung/jalangi2. Accessed: 2026-04-30
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[27]
Sen, K., Kalasapur, S., Brutch, T., and Gibbs, S.Jalangi: A selective record- replay and dynamic analysis framework for JavaScript. InProceedings of the 2013 9th Joint Meeting on Foundations of Software Engineering(2013), ESEC/FSE 2013, pp. 488–498. [30]Sharma, A.Openevolve: an open-source evolutionary coding agent, 2025
work page 2013
-
[28]
InProceedings of the 26th International Conference on World Wide Web (WWW ’17)(Apr
Surbatovich, M., Aljuraidan, J., Bauer, L., Das, A., and Jia, L.Some recipes can do more than spoil your appetite: Analyzing the security and privacy risks of IFTTT recipes. InProceedings of the 26th International Conference on World Wide Web (WWW ’17)(Apr. 2017), International World Wide Web Conferences Steering Committee, pp. 1501–1510
work page 2017
-
[29]
InIEEE Sym- posium on Security and Privacy (S&P)(2026)
Tystahl, G., Ghebremichael, J., Muralee, S., Cherupattamoolayil, S., Bianchi, A., Machiry, A., Kapravelos, A., and Enck, W.Cosseter: Github actions permission reduction using demand-driven static analysis. InIEEE Sym- posium on Security and Privacy (S&P)(2026)
work page 2026
-
[30]
W ang, Z., Siu, V., Ye, Z., Shi, T., Nie, Y., Zhao, X., W ang, C., Guo, W., and Song, D.Agentvigil: Generic black-box red-teaming for indirect prompt injection against llm agents, 2025
work page 2025
-
[31]
https:// simonwillison.net/2023/May/11/delimiters-wont-save-you/, 2023
Willison, S.Delimiters won’t save you from prompt injection. https:// simonwillison.net/2023/May/11/delimiters-wont-save-you/, 2023. Accessed: 2025-11-20
work page 2023
-
[32]
Xie, Y., Luo, M., Liu, Z., Zhang, Z., Zhang, K., Liu, Y., Li, Z., Chen, P., W ang, S., and She, D.Red-teaming coding agents from a tool-invocation perspective: An empirical security assessment, 2025
work page 2025
- [33]
-
[34]
Yu, Z., Liu, X., Liang, S., Cameron, Z., Xiao, C., and Zhang, N.Don’t listen to me: Understanding and exploring jailbreak prompts of large language models. ArXiv abs/2403.17336(2024)
- [35]
-
[36]
Y.Melon: Provable defense against indirect prompt injection attacks in ai agent, 2025
Zhu, K., Y ang, X., W ang, J., Guo, W., and W ang, W. Y.Melon: Provable defense against indirect prompt injection attacks in ai agent, 2025
work page 2025
-
[37]
Zhu, S., Zhang, R., An, B., Wu, G., Barrow, J., W ang, Z., Huang, F., Nenkova, A., and Sun, T.Autodan: Interpretable gradient-based adversarial attacks on large language models
-
[38]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Zou, A., W ang, Z., Kolter, J. Z., and Fredrikson, M.Universal and transferable adversarial attacks on aligned language models.ArXiv abs/2307.15043(2023). A Open Science We provide the following artifacts to support reproducibility and future research. All artifacts are available at https://anonymous. 4open.science/r/agentic-workflow-hijacking-BBD2 and wi...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[39]
Configure`run-gemini-cli`action with a valid`GEMINI_API_KEY`secret
-
[40]
Trigger via issue comment event
-
[41]
Observe 403 error in action logs at the API endpoint **Error Log (truncated):** ``` Error: Request failed with status 403 at StreamGenerateContent (action.yml:47) cause: { code:'PERMISSION_DENIED', message:'API key not valid or expired'} ``` **Expected Behavior:** The action should authenticate successfully and process the Gemini API request. --- <!-- MAI...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.