Recognition: no theorem link
CVEvolve: Autonomous Algorithm Discovery for Unstructured Scientific Data Processing
Pith reviewed 2026-05-13 02:38 UTC · model grok-4.3
The pith
An LLM agent autonomously discovers algorithms for scientific image tasks that outperform baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
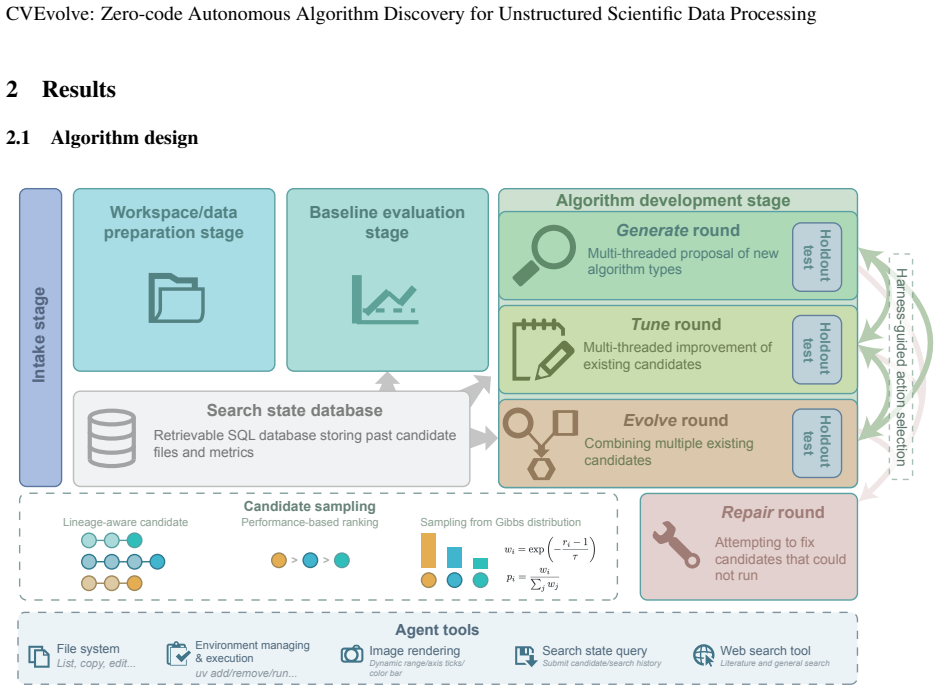
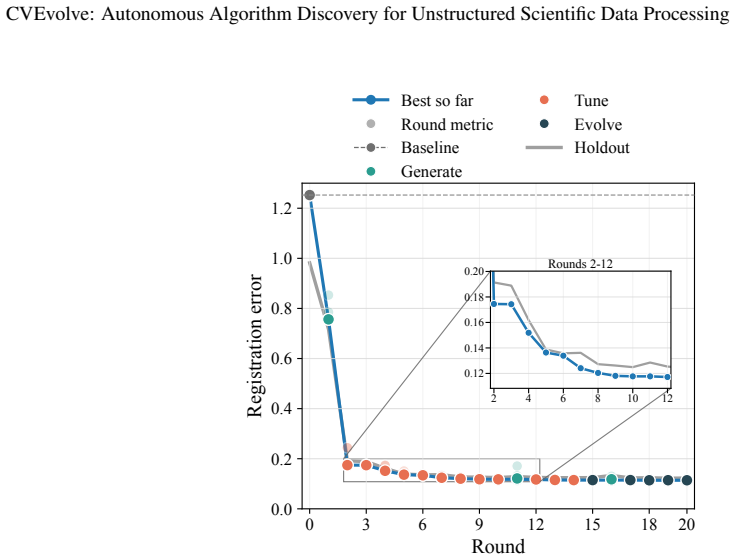
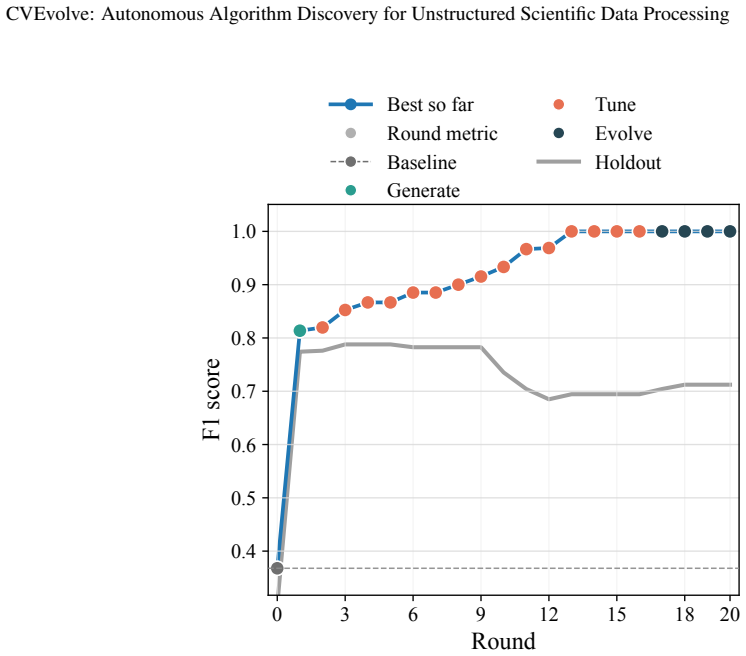
CVEvolve is an autonomous agentic harness that integrates multi-round search, lineage-aware stochastic candidate sampling, code execution tools, evaluation implementation, history management, and holdout testing to generate algorithms for unstructured scientific image data. On the three demonstrated tasks it produces algorithms that improve over baselines, with holdout performance serving as a better indicator of generalization than training-only metrics.
What carries the argument
The CVEvolve harness, which alternates discovery and improvement actions while using lineage-aware stochastic sampling to balance exploration and exploitation and holdout testing to track generalization.
If this is right
- Domain scientists can obtain task-specific algorithms directly from their raw data without writing code.
- Holdout tracking during search reduces selection of algorithms that overfit to initial training splits.
- The same harness can be reused across different microscopy and materials-science image tasks.
- Zero-code access lowers the barrier between raw experimental data and usable processing pipelines.
Where Pith is reading between the lines
- The approach could be tested on non-image scientific data such as spectra or time series to check breadth.
- Combining CVEvolve outputs with human review might further improve final algorithm quality on high-stakes tasks.
- Longer search budgets or larger code-generation models could reveal whether performance scales with compute.
Load-bearing premise
An LLM can generate, execute, and iteratively refine code for scientific image tasks in ways that reliably produce generalizable algorithms without extensive human guidance or post-hoc tuning.
What would settle it
Applying CVEvolve to a new scientific image-processing task and observing that no discovered algorithm improves on simple baselines when evaluated on a true holdout test set would falsify the claim of reliable autonomous discovery.
Figures





read the original abstract
Scientific data processing often requires task-specific algorithms or AI models, creating a barrier for domain scientists who need to analyze their data but may not have extensive computing or image-processing expertise. This barrier is especially pronounced when data are noisy, have a high dynamic range, are sparsely labeled, or are only loosely specified. We introduce CVEvolve, an autonomous agentic harness with a zero-code interface for scientific data-processing algorithm discovery. CVEvolve combines a multi-round search strategy with tools for code execution, evaluation implementation, history management, holdout testing, and optional inspection of scientific data and visual outputs. The search alternates between discovery and improvement actions, and uses lineage-aware stochastic candidate sampling to balance exploration and exploitation. We demonstrate CVEvolve on x-ray fluorescence microscopy image registration, Bragg peak detection, and high-energy diffraction microscopy image segmentation. Across these tasks, CVEvolve discovers algorithms that improve over baseline methods, while holdout test tracking helps identify candidates that generalize better than later over-optimized alternatives. These results show that zero-code, autonomous LLM-powered algorithm development can help domain scientists turn unstructured scientific image data into practical algorithms and downstream scientific discoveries.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CVEvolve, a zero-code LLM-powered agentic system for autonomous discovery of data-processing algorithms on unstructured scientific images. It employs multi-round search alternating discovery and improvement, lineage-aware stochastic sampling, code execution tools, and holdout evaluation to identify generalizable candidates. Demonstrated on x-ray fluorescence microscopy registration, Bragg peak detection, and high-energy diffraction microscopy segmentation, it claims to produce algorithms outperforming baselines while holdout tracking mitigates over-optimization.
Significance. If the empirical results hold with proper validation, CVEvolve could meaningfully lower barriers for domain scientists lacking coding expertise, enabling faster extraction of insights from noisy or high-dynamic-range scientific datasets. The lineage-aware sampling and explicit holdout mechanism represent a practical advance over naive LLM code generation for scientific tasks. The work is an empirical tool demonstration rather than a closed-form derivation, so its significance hinges on reproducible quantitative evidence of generalization.
major comments (3)
- [Abstract and Results] Abstract and Results section: The central claim that CVEvolve 'discovers algorithms that improve over baseline methods' is unsupported by any quantitative metrics, error bars, baseline definitions, statistical tests, or run counts. This absence is load-bearing because the entire contribution rests on empirical superiority and generalization via holdout tracking.
- [Methods (holdout evaluation)] Methods section on holdout evaluation and data inspection tools: Granting the LLM optional access to inspect scientific data and visual outputs during multi-round search on typically small datasets (e.g., x-ray microscopy or Bragg peak images) creates a plausible pathway for indirect leakage of holdout statistics under lineage-aware sampling. This directly threatens the claim that holdout tracking reliably identifies generalizable candidates rather than search artifacts.
- [Experiments] Experiments section: No information is provided on how baselines were implemented, tuned, or compared (including whether they received equivalent LLM assistance or post-hoc optimization), nor on variance across independent runs. This prevents assessment of whether reported advantages are robust or reproducible.
minor comments (2)
- [Methods] The workflow diagram (if present) or pseudocode for the multi-round search loop would improve clarity on how discovery and improvement actions interact with the history manager.
- [Introduction and Figures] Acronyms such as HEDM should be expanded on first use; figure captions could explicitly state the performance metric used for each task.
Simulated Author's Rebuttal
We thank the referee for their insightful comments on our manuscript. We address each major comment point by point below, outlining our responses and planned revisions.
read point-by-point responses
-
Referee: [Abstract and Results] Abstract and Results section: The central claim that CVEvolve 'discovers algorithms that improve over baseline methods' is unsupported by any quantitative metrics, error bars, baseline definitions, statistical tests, or run counts. This absence is load-bearing because the entire contribution rests on empirical superiority and generalization via holdout tracking.
Authors: We acknowledge the referee's point that the abstract and results section would be strengthened by including explicit quantitative metrics. The manuscript's experiments section does compare the discovered algorithms to baselines on the specified tasks, but we agree that more detailed reporting is required. In the revised manuscript, we will modify the abstract to include key quantitative results, such as average performance improvements, and expand the results section to provide error bars, definitions of the baseline methods, the number of independent runs, and appropriate statistical tests to support the claims of improvement and generalization. revision: yes
-
Referee: [Methods (holdout evaluation)] Methods section on holdout evaluation and data inspection tools: Granting the LLM optional access to inspect scientific data and visual outputs during multi-round search on typically small datasets (e.g., x-ray microscopy or Bragg peak images) creates a plausible pathway for indirect leakage of holdout statistics under lineage-aware sampling. This directly threatens the claim that holdout tracking reliably identifies generalizable candidates rather than search artifacts.
Authors: This concern about potential data leakage is well-taken and merits careful consideration. In the current design, the holdout set is completely isolated and is only used for final evaluation after the search concludes; the LLM agent does not have direct access to holdout data or its statistics during the multi-round search. The optional inspection tool is intended for the primary dataset to allow the agent to assess code outputs visually or numerically for improvement. However, to eliminate any ambiguity regarding indirect leakage via lineage-aware sampling on small datasets, we will revise the methods section to provide a more explicit description of the data partitioning, confirm the isolation of the holdout set, and include a discussion of safeguards against leakage. We believe this will reinforce the validity of the holdout tracking mechanism. revision: yes
-
Referee: [Experiments] Experiments section: No information is provided on how baselines were implemented, tuned, or compared (including whether they received equivalent LLM assistance or post-hoc optimization), nor on variance across independent runs. This prevents assessment of whether reported advantages are robust or reproducible.
Authors: We agree that the experiments section lacks sufficient detail on the baseline comparisons, which is necessary for evaluating the robustness of our results. The baselines were standard implementations from established libraries and methods in the respective fields, tuned using conventional techniques on the training portions of the data without any assistance from LLMs or additional post-hoc optimization. To address this, we will add comprehensive details in the revised manuscript, including the specific baseline algorithms used, their implementation sources, tuning methods, and performance statistics with variance across multiple independent runs of the CVEvolve system. This will enable proper assessment of reproducibility and the significance of the observed advantages. revision: yes
Circularity Check
No circularity: empirical tool demonstration with no derivation chain
full rationale
The paper describes an LLM-based agentic system for discovering data-processing algorithms on scientific images. Its claims rest on experimental outcomes across three tasks (registration, peak detection, segmentation) rather than any mathematical derivation, first-principles result, or closed-form prediction. No equations, parameter-fitting steps, uniqueness theorems, or ansatzes appear in the provided text. Holdout tracking is presented as an empirical safeguard, not a derived guarantee. Self-citations, if present, are not invoked to justify load-bearing premises. The work is therefore self-contained as an engineering demonstration; no step reduces to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Boiko, Robert MacKnight, Ben Kline, and Gabe Gomes
Daniil A. Boiko, Robert MacKnight, Ben Kline, and Gabe Gomes. Autonomous chemical research with large language models.Nature, 624:570–578, 2023
work page 2023
-
[2]
Juraj Gottweis, Wei-Hung Weng, Alexander Daryin, Tao Tu, Anil Palepu, et al. Towards an ai co-scientist.arXiv preprint arXiv:2502.18864, 2025. 15 CVEvolve: Autonomous Algorithm Discovery for Unstructured Scientific Data Processing
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Michael D. Skarlinski, Sam Cox, Jon M. Laurent, James D. Braza, Michaela Hinks, Michael J. Hammerling, Manvitha Ponnapati, Samuel G. Rodriques, and Andrew D. White. Language agents achieve superhuman synthesis of scientific knowledge.arXiv preprint arXiv:2409.13740, 2024
-
[4]
Towards end-to-end automation of ai research.Nature, 651:914–919, 2026
Chris Lu, Cong Lu, Robert Tjarko Lange, Yutaro Yamada, Shengran Hu, Jakob Foerster, David Ha, and Jeff Clune. Towards end-to-end automation of ai research.Nature, 651:914–919, 2026
work page 2026
-
[5]
Tianshi Zheng, Zheye Deng, Hong Ting Tsang, Weiqi Wang, Jiaxin Bai, Zihao Wang, and Yangqiu Song. From automation to autonomy: A survey on large language models in scientific discovery.arXiv preprint arXiv:2505.13259, 2025
-
[6]
Alexandra R. Ritchie, Suvi L. Laitinen, Pekka Katajisto, and Johanna I. Englund. Tonga: A novel toolbox for straightforward bioimage analysis.Frontiers in Computer Science, 4, 2022
work page 2022
-
[7]
Perrine Paul-Gilloteaux. Bioimage informatics: Investing in software usability is essential.PLOS Biology, 21(7):e3002213, 2023
work page 2023
-
[8]
Randal S. Olson and Jason H. Moore. TPOT: A tree-based pipeline optimization tool for automating machine learning. InProceedings of the Workshop on Automatic Machine Learning, volume 64 ofProceedings of Machine Learning Research, pages 66–74, 2016
work page 2016
-
[9]
Barret Zoph and Quoc V . Le. Neural architecture search with reinforcement learning. InInternational Conference on Learning Representations, 2017
work page 2017
-
[10]
Esteban Real, Chen Liang, David R. So, and Quoc V . Le. AutoML-Zero: Evolving machine learning algorithms from scratch.arXiv preprint arXiv:2003.03384, 2020
-
[11]
Eureka: Human-Level Reward Design via Coding Large Language Models
Yecheng Jason Ma, William Liang, Guanzhi Wang, De-An Huang, Osbert Bastani, Dinesh Jayaraman, Yuke Zhu, Linxi Fan, and Anima Anandkumar. Eureka: Human-level reward design via coding large language models.arXiv preprint arXiv:2310.12931, 2023
work page internal anchor Pith review arXiv 2023
-
[12]
Pawan Kumar, Emilien Dupont, Francisco J
Bernardino Romera-Paredes, Mohammadamin Barekatain, Alexander Novikov, Matej Balog, M. Pawan Kumar, Emilien Dupont, Francisco J. R. Ruiz, Jordan S. Ellenberg, Pengming Wang, Omar Fawzi, Pushmeet Kohli, and Alhussein Fawzi. Mathematical discoveries from program search with large language models.Nature, 625:468–475, 2024
work page 2024
-
[13]
Alexander Novikov, Ngân V˜u, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco J. R. Ruiz, Abbas Mehrabian, M. Pawan Kumar, Abigail See, Swarat Chaudhuri, George Holland, Alex Davies, Sebastian Nowozin, Pushmeet Kohli, and Matej Balog. AlphaEvolve: A coding agent for scientific and algor...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Openevolve: an open-source evolutionary coding agent, 2025
Asankhaya Sharma. Openevolve: an open-source evolutionary coding agent, 2025
work page 2025
-
[15]
Gang Liu, Yihan Zhu, Jie Chen, and Meng Jiang. Scientific algorithm discovery by augmenting AlphaEvolve with Deep Research.arXiv preprint arXiv:2510.06056, 2025
-
[16]
Aditya Bharat Soni, Boxuan Li, Xingyao Wang, Valerie Chen, and Graham Neubig. Coding agents with multimodal browsing are generalist problem solvers.arXiv preprint arXiv:2506.03011, 2025
-
[17]
Xiangyu Yin, Ming Du, Junjing Deng, Zhi Yang, Yimo Han, and Yi Jiang. Autonomous algorithm discovery for ptychography via evolutionary LLM reasoning.arXiv preprint arXiv:2603.05696, 2026
-
[18]
Illuminating search spaces by mapping elites
Jean-Baptiste Mouret and Jeff Clune. Illuminating search spaces by mapping elites.arXiv preprint arXiv:1504.04909, 2015. 16 CVEVOLVE: AUTONOMOUSALGORITHMDISCOVERY FOR UNSTRUCTUREDSCIENTIFICDATAPROCESSING Supplementary Information Ming Du∗, Xiangyu Yin, Yanqi Luo, Dishant Beniwal, Songyuan Tang, Hemant Sharma, Mathew J. Cherukara† Advanced Photon Source Ar...
work page Pith review arXiv 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.