Recognition: 2 theorem links
· Lean TheoremOptions, Not Clicks: Lattice Refinement for Consent-Driven MCP Authorization
Pith reviewed 2026-05-13 02:33 UTC · model grok-4.3
The pith
A risk lattice with refinement turns user decisions into reusable rules for scoped MCP tool consent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
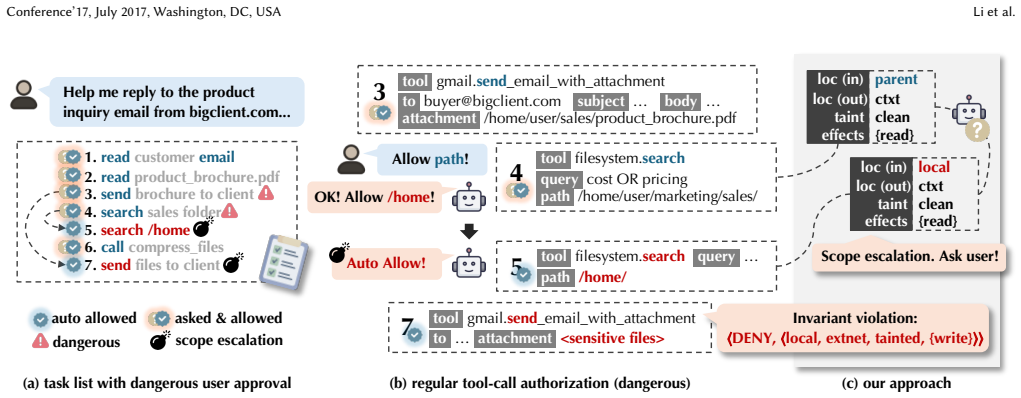
Conleash models tool-call risks as a lattice to enforce boundary-scoped authorization that auto-permits calls inside safe regions, escalates those outside, applies a policy engine for invariants, and runs a refinement loop that converts each user decision into a reusable rule for future calls.
What carries the argument
risk lattice with refinement loop, which structures call arguments by risk level to separate automatic approval from escalation and converts decisions into persistent rules.
If this is right
- Calls inside established boundaries receive automatic permission without further prompts.
- Risky arguments trigger escalation and user review to prevent unsafe actions.
- Each user decision adds a reusable rule, lowering the number of future interventions.
- Policy verification overhead stays under 10 ms on real traces.
- Users experience higher trust and fewer prompts than with broad permission toggles.
Where Pith is reading between the lines
- The same lattice structure could support consent management for other agent-tool protocols beyond MCP.
- Over longer use the refinement loop might stabilize into a small set of per-user rules.
- Initial lattice boundaries could be seeded from common tool documentation to reduce early escalations.
Load-bearing premise
The lattice boundaries correctly classify most tool-call arguments as safe or risky without frequent misclassifications on unseen invocations.
What would settle it
A production tool call that the lattice auto-permits but later proves harmful, or a safe call that triggers repeated escalations leading to user overrides.
Figures








read the original abstract
As Model Context Protocol adoption grows, securing tool invocations via meaningful user consent has become a critical challenge, as existing methods, broad always allow toggles or opaque LLM-based decisions, fail to account for dangerous call arguments and often lead to consent fatigue. In this work, we present Conleash, a client-side middleware that enforces boundary-scoped authorization by utilizing a risk lattice to auto-permit safe calls within known boundaries while escalating risks, a policy engine for user-defined invariants, and a refinement loop that converts user decisions into reusable rules. Evaluated on 984 real-world traces, Conleash achieved 98.2% accuracy, caught 99.4% of escalations, and added only 8.2 ms of overhead for policy verification; furthermore, in a user study where N=16, participants significantly preferred Conleash scoped permissions over traditional methods, citing higher trust and reduced prompting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Conleash, a client-side middleware for Model Context Protocol (MCP) tool invocations that uses a risk lattice to auto-permit safe calls within known boundaries, escalates risky calls, incorporates a policy engine for user-defined invariants, and includes a refinement loop to convert user decisions into reusable rules. It reports evaluation results on 984 real-world traces showing 98.2% accuracy, 99.4% escalation catch rate, and 8.2 ms policy verification overhead, plus a user study (N=16) where participants preferred the scoped permissions for higher trust and reduced prompting.
Significance. If the evaluation methodology proves sound and the lattice generalizes, Conleash could meaningfully improve the security-usability tradeoff in AI agent authorization by reducing consent fatigue while providing structured, refinable risk boundaries and reusable policies, offering a concrete alternative to broad toggles or opaque LLM decisions.
major comments (3)
- [Evaluation] The evaluation reports 98.2% accuracy and 99.4% escalation catch rate on 984 traces, but provides no description of how ground-truth safe/dangerous labels were assigned (e.g., independent expert annotation, post-hoc review, or hold-out set). If labels derive from the refinement loop or boundary tuning on the same traces, the metrics risk circularity and do not demonstrate generalization to unseen invocations.
- [Lattice and Policy Engine] No details are given on risk lattice construction, boundary selection criteria, or trace selection methodology. These omissions make it impossible to assess reproducibility, the separation power of the lattice, or whether boundaries were chosen independently of the evaluated traces.
- [User Study] The user study (N=16) claims significant preference for Conleash over traditional methods on trust and prompting, but omits the experimental protocol, statistical tests, effect sizes, or controls for bias, weakening support for the usability claims.
minor comments (2)
- [Abstract] The abstract introduces MCP without expansion; consider spelling out Model Context Protocol on first use.
- [Evaluation] Consider adding a table or figure summarizing the 984-trace dataset characteristics (e.g., distribution of call types, escalation frequency) to aid interpretation of the accuracy numbers.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments on our paper. We appreciate the feedback highlighting the need for greater clarity on evaluation methodology, lattice construction, and user study details. We address each major comment below and will revise the manuscript to incorporate the requested information.
read point-by-point responses
-
Referee: [Evaluation] The evaluation reports 98.2% accuracy and 99.4% escalation catch rate on 984 traces, but provides no description of how ground-truth safe/dangerous labels were assigned (e.g., independent expert annotation, post-hoc review, or hold-out set). If labels derive from the refinement loop or boundary tuning on the same traces, the metrics risk circularity and do not demonstrate generalization to unseen invocations.
Authors: We agree that the ground-truth labeling process must be described explicitly to allow proper assessment of the metrics and to address concerns about circularity. The manuscript focused on reporting the performance numbers but did not detail the labeling procedure. Labels were assigned through post-hoc expert review by two independent security researchers using a fixed rubric derived from MCP security guidelines; the reviewers had no access to the system's outputs or refinement decisions during labeling. The 984 traces were partitioned into a development set (used for initial boundary tuning and refinement loop iterations) and a held-out test set (used for the reported metrics). We will revise the Evaluation section to include a full description of the annotation process, the hold-out split, and steps taken to maintain independence from the refinement loop. revision: yes
-
Referee: [Lattice and Policy Engine] No details are given on risk lattice construction, boundary selection criteria, or trace selection methodology. These omissions make it impossible to assess reproducibility, the separation power of the lattice, or whether boundaries were chosen independently of the evaluated traces.
Authors: We acknowledge that the manuscript provides insufficient detail on risk lattice construction, boundary selection, and trace selection, limiting reproducibility assessment. The lattice was constructed from a hierarchical taxonomy of MCP tool risks (data access, execution privileges, and side effects) with initial boundaries set by expert-defined thresholds on a small pilot collection of traces collected prior to the main 984-trace dataset. Trace selection drew from anonymized, consented real-world MCP usage logs. We will add a dedicated subsection in the System Design portion of the revised manuscript that describes the lattice construction process, the exact boundary selection criteria, the pilot-versus-main trace separation, and the sampling methodology. revision: yes
-
Referee: [User Study] The user study (N=16) claims significant preference for Conleash over traditional methods on trust and prompting, but omits the experimental protocol, statistical tests, effect sizes, or controls for bias, weakening support for the usability claims.
Authors: We agree that the user study section is too concise and should supply the full protocol, statistical analysis, effect sizes, and bias controls to substantiate the preference claims. The study employed a within-subjects design with counterbalanced condition order, identical task sets for both Conleash and the baseline (always-allow) condition, and post-task Likert questionnaires. Statistical analysis used Wilcoxon signed-rank tests with rank-biserial correlation for effect sizes. We will expand the User Study section in the revision to include the complete experimental protocol, recruitment details, task descriptions, questionnaire items, exact statistical tests and results (p-values and effect sizes), and the bias-mitigation measures such as counterbalancing and blinding. revision: yes
Circularity Check
No circularity: empirical accuracy claims are direct measurements, not self-referential predictions or derivations.
full rationale
The paper describes a system (risk lattice, policy engine, refinement loop) and reports direct empirical results on 984 traces (98.2% accuracy, 99.4% escalation catch rate, 8.2 ms overhead) plus a small user study. No equations, first-principles derivations, or fitted parameters are presented that reduce by construction to the inputs or to the refinement process itself. The evaluation numbers are presented as measured outcomes on real-world traces rather than predictions derived from the same data or labels. Absent any quoted reduction showing that accuracy is tautological with the lattice boundaries or user overrides, the central claims remain independent measurements. This is the normal non-circular case for an applied systems paper.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclearWe structure the space of all possible flow summaries as a formal risk lattice L... φ⊑φ′ ⇐⇒ (li⊑l′i)∧(lo⊑l′o)∧(τ⊑τ′)∧(E⊑E′)
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclearthe risk lattice is constructed as the product of three dimensional sub-lattices... loc_order(exact,parent), loc_order(parent,local)
Reference graph
Works this paper leans on
-
[1]
2024. Soufflé Language. https://souffle-lang.github.io/. Accessed May 13, 2026
work page 2024
-
[2]
Deepak Bhaskar Acharya, Karthigeyan Kuppan, and B Divya. 2025. Agentic ai: Autonomous intelligence for complex goals–a comprehensive survey.IEEe Access (2025)
work page 2025
-
[3]
Anthropic. 2025. Configure Permissions — Claude Code Docs. https://code. claude.com/docs/en/permissions. Accessed May 13, 2026
work page 2025
-
[4]
Manish Bhatt, Sahana Chennabasappa, Yue Li, Cyrus Nikolaidis, Daniel Song, Shengye Wan, Faizan Ahmad, Cornelius Aschermann, Yaohui Chen, Dhaval Kapil, et al. 2024. Cyberseceval 2: A wide-ranging cybersecurity evaluation suite for large language models.arXiv preprint arXiv:2404.13161(2024)
-
[5]
Malik Bouchet, Byron Cook, Bryant Cutler, Anna Druzkina, Andrew Gacek, Liana Hadarean, Ranjit Jhala, Brad Marshall, Dan Peebles, Neha Rungta, et al
-
[6]
Block public access: trust safety verification of access control policies. InProceedings of the 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering. 281–291
-
[7]
Weicheng Cao, Chunqiu Xia, Sai Teja Peddinti, David Lie, Nina Taft, and Lisa M Austin. 2021. A large scale study of user behavior, expectations and engagement with android permissions. In30th USENIX Security Symposium (USENIX Security 21). 803–820
work page 2021
-
[8]
Sunjay Cauligi, Gary Soeller, Brian Johannesmeyer, Fraser Brown, Riad S Wahby, John Renner, Benjamin Grégoire, Gilles Barthe, Ranjit Jhala, and Deian Stefan
-
[9]
InProceedings of the 40th ACM SIGPLAN Conference on Programming Language Design and Implementation
Fact: a DSL for timing-sensitive computation. InProceedings of the 40th ACM SIGPLAN Conference on Programming Language Design and Implementation. 174–189
-
[10]
Camille Cobb, Milijana Surbatovich, Anna Kawakami, Mahmood Sharif, Lujo Bauer, Anupam Das, and Limin Jia. 2020. How Risky Are Real Users’{IFTTT } Applets?. InSixteenth Symposium on Usable Privacy and Security (SOUPS 2020). 505–529
work page 2020
-
[11]
Cursor. 2025. Permissions — Cursor CLI Documentation. https://cursor.com/ docs/cli/reference/permissions. Accessed May 13, 2026
work page 2025
-
[12]
Daniel J Dougherty, Kathi Fisler, and Shriram Krishnamurthi. 2006. Specifying and reasoning about dynamic access-control policies. InInternational Joint Conference on Automated Reasoning. Springer, 632–646
work page 2006
-
[13]
William Enck, Machigar Ongtang, and Patrick McDaniel. 2009. Understanding android security.IEEE security & privacy7, 1 (2009), 50–57
work page 2009
-
[14]
EU Artificial Intelligence Act. 2025. Article 99: Penalties. https : / / artificialintelligenceact.eu/article/99/. Accessed: May 13, 2026
work page 2025
-
[15]
Adrienne Porter Felt, Erika Chin, Steve Hanna, Dawn Song, and David Wagner
-
[16]
InProceedings of the 18th ACM conference on Computer and communications security
Android permissions demystified. InProceedings of the 18th ACM conference on Computer and communications security. 627–638
-
[17]
Adrienne Porter Felt, Elizabeth Ha, Serge Egelman, Ariel Haney, Erika Chin, and David Wagner. 2012. Android permissions: User attention, comprehension, and behavior. InProceedings of the eighth symposium on usable privacy and security. 1–14
work page 2012
-
[18]
Mafalda Ferreira, Tiago Brito, José Fragoso Santos, and Nuno Santos. 2023. Rule- Keeper: GDPR-aware personal data compliance for web frameworks. In2023 IEEE Symposium on Security and Privacy (SP). IEEE, 2817–2834
work page 2023
-
[19]
Kathi Fisler, Shriram Krishnamurthi, Leo A Meyerovich, and Michael Carl Tschantz. 2005. Verification and change-impact analysis of access-control poli- cies. InProceedings of the 27th international conference on Software engineering. 196–205
work page 2005
- [20]
-
[21]
Dimitar P Guelev, Mark Ryan, and Pierre Yves Schobbens. 2004. Model-checking access control policies. InInternational Conference on Information Security. Springer, 219–230
work page 2004
- [22]
-
[23]
Maximilian Hils, Daniel W Woods, and Rainer Böhme. 2020. Measuring the emergence of consent management on the web. InProceedings of the ACM Internet Measurement Conference. 317–332
work page 2020
-
[24]
Invariant Labs. 2025. GitHub MCP Exploited: Accessing private repositories via MCP. https://invariantlabs.ai/blog/mcp-github-vulnerability
work page 2025
-
[25]
Julie Bort. 2026. A Meta AI security researcher said an OpenClaw agent ran amok on her inbox. https://techcrunch.com/2026/02/23/a-meta-ai-security-researcher- said-an-openclaw-agent-ran-amok-on-her-inbox/
work page 2026
-
[26]
Jungjae Lee, Dongjae Lee, Chihun Choi, Youngmin Im, Jaeyoung Wi, Kihong Heo, Sangeun Oh, Sunjae Lee, and Insik Shin. 2025. Verisafe agent: Safeguarding mobile gui agent via logic-based action verification. InProceedings of the 31st Annual International Conference on Mobile Computing and Networking. 817–831
work page 2025
-
[27]
Robert Lemos. 2026. ’God-Like’ Attack Machines: AI Agents Ignore Security Policies. https://www.darkreading.com/application-security/ai-agents-ignore- security-policies. Accessed: May 13, 2026
work page 2026
- [28]
-
[29]
Lynette I Millett, Batya Friedman, and Edward Felten. 2001. Cookies and web browser design: Toward realizing informed consent online. InProceedings of the SIGCHI conference on Human factors in computing systems. 46–52
work page 2001
-
[30]
Model Context Protocol. 2025. Authorization. https://modelcontextprotocol.io/ specification/draft/basic/authorization
work page 2025
-
[31]
Model Context Protocol. 2025. Model Context Protocol Specification. https: //modelcontextprotocol.io/specification/2025-06-18/index
work page 2025
-
[32]
Mohammad Nauman, Sohail Khan, and Xinwen Zhang. 2010. Apex: extending an- droid permission model and enforcement with user-defined runtime constraints. InProceedings of the 5th ACM symposium on information, computer and commu- nications security. 328–332
work page 2010
-
[33]
Trung Tin Nguyen, Michael Backes, and Ben Stock. 2022. Freely given consent? studying consent notice of third-party tracking and its violations of gdpr in android apps. InProceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security. 2369–2383
work page 2022
-
[34]
Beatrice Nolan. 2025. An AI-powered coding tool wiped out a software com- pany’s database, then apologized for a ’catastrophic failure on my part’. https: //fortune.com/2025/07/23/ai-coding-tool-replit-wiped-database-called-it-a- catastrophic-failure/. Accessed: May 13, 2026
work page 2025
-
[35]
One Inc. 2026. One Inc Unveils Model Context Protocol to Accelerate Insur- ance Payments Integration and Secure AI Data Access. https://www.oneinc. com/resources/news/one-inc-unveils-model-context-protocol-to-accelerate- insurance-payments-integration-and-secure-ai-data-access
work page 2026
-
[36]
OWASP Foundation. 2024. OWASP Benchmark Project. https://owasp.org/www- project-benchmark/
work page 2024
-
[37]
Ram Potham. 2025. I Tested LLM Agents on Simple Safety Rules. They Failed in Surprising and Informative Ways. https://www.lesswrong.com/ posts/wRsQowKKbgyXv2eni/i-tested-llm-agents-on-simple-safety-rules-they- failed-in. Accessed: May 13, 2026
work page 2025
-
[38]
Model Context Protocol. 2025. Concepts of MCP Architecture. https:// modelcontextprotocol.io/docs/learn/architecture#concepts-of-mcp. Accessed May 13, 2026
work page 2025
-
[39]
Model Context Protocol. 2025. Model Context Protocol. https : / / modelcontextprotocol.io
work page 2025
-
[40]
Zhengyang Qu, Vaibhav Rastogi, Xinyi Zhang, Yan Chen, Tiantian Zhu, and Zhong Chen. 2014. Autocog: Measuring the description-to-permission fidelity in android applications. InProceedings of the 2014 ACM SIGSAC conference on computer and communications security. 1354–1365
work page 2014
-
[41]
Franziska Roesner, Tadayoshi Kohno, Alexander Moshchuk, Bryan Parno, He- len J Wang, and Crispin Cowan. 2012. User-driven access control: Rethinking permission granting in modern operating systems. In2012 IEEE Symposium on Security and Privacy. IEEE, 224–238
work page 2012
-
[42]
Sebastian Mondragon. 2026. When AI Agents Delete Production: Lessons from Amazon’s Kiro Incident. https://particula.tech/blog/ai-agent-production-safety- kiro-incident
work page 2026
-
[43]
Tianneng Shi, Jingxuan He, Zhun Wang, Hongwei Li, Linyu Wu, Wenbo Guo, and Dawn Song. 2025. Progent: Programmable privilege control for llm agents. arXiv preprint arXiv:2504.11703(2025)
work page internal anchor Pith review arXiv 2025
-
[44]
Yuan Tian, Nan Zhang, Yueh-Hsun Lin, XiaoFeng Wang, Blase Ur, Xianzheng Guo, and Patrick Tague. 2017. {SmartAuth}:{User-Centered} authorization for the internet of things. In26th USENIX Security Symposium (USENIX Security 17). 361–378
work page 2017
-
[45]
Mark Tyson. 2026. Claude-powered AI coding agent deletes entire company data- base in 9 seconds. https://www.tomshardware.com/tech-industry/artificial- intelligence / claude - powered - ai - coding - agent - deletes - entire - company - database- in- 9- seconds- backups- zapped- after- cursor- tool- powered- by- anthropics-claude-goes-rogue. Conference’17...
work page 2026
-
[46]
Christine Utz, Martin Degeling, Sascha Fahl, Florian Schaub, and Thorsten Holz
-
[47]
In Proceedings of the 2019 acm sigsac conference on computer and communications security
(Un) informed consent: Studying GDPR consent notices in the field. In Proceedings of the 2019 acm sigsac conference on computer and communications security. 973–990
work page 2019
-
[48]
Versium. 2026. Versium Unveils Versium Reach MCP Server, Connecting AI Agents to the Industry’s Leading Identity Technology. https://www.prweb.com/ releases/versium-unveils-versium-reach-mcp-server-connecting-ai-agents-to- the-industrys-leading-identity-technology-302677164.html
work page 2026
-
[49]
Brandon Vigliarolo. 2025. Google Antigravity vibe-codes user’s entire drive out of existence. https://www.theregister.com/2025/12/01/google_antigravity_ wipes_d_drive/
work page 2025
-
[50]
Primal Wijesekera, Arjun Baokar, Ashkan Hosseini, Serge Egelman, David Wag- ner, and Konstantin Beznosov. 2015. Android permissions remystified: A field study on contextual integrity. In24th USENIX Security Symposium (USENIX Secu- rity 15). 499–514
work page 2015
-
[51]
Window Forum. 2025. Claude in Chrome and Claude Code: AI Agents Across Browser and Terminal. https://windowsforum.com/threads/claude-in-chrome- and-claude-code-ai-agents-across-browser-and-terminal.395332/. Accessed: May 13, 2026
work page 2025
-
[52]
Workato. 2025. Workato Delivers Industry’s First Enterprise MCP Platform for AI Agents. https://www.axios.com/sponsored/workato-delivers-industrys-first- enterprise-mcp-platform-for-ai-agents
work page 2025
-
[53]
Yuhao Wu, Franziska Roesner, Tadayoshi Kohno, Ning Zhang, and Umar Iqbal
- [54]
- [55]
- [56]
-
[57]
Zhen Zhang, Yu Feng, Michael D Ernst, Sebastian Porst, and Isil Dillig. 2021. Checking conformance of applications against GUI policies. InProceedings of the 29th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering. 95–106
work page 2021
-
[58]
MiniScope: A Least Privilege Framework for Authorizing Tool Calling Agents
Jinhao Zhu, Kevin Tseng, Gil Vernik, Xiao Huang, Shishir G Patil, Vivian Fang, and Raluca Ada Popa. 2025. MiniScope: A Least Privilege Framework for Authorizing Tool Calling Agents.arXiv preprint arXiv:2512.11147(2025). AConsentBenchDetails This section provides detailed methodology for constructingCon- sentBench. Server Selection.We select MCP servers to...
-
[59]
DENY_INV ARIANT — hard block, non -overridable ## Examples [... few-shot examples mapping natural -language invariants to Datalog rules, covering dimension-based, content -based, and tool-specific patterns ...] ## Tools Used in This Session {{ tool_descriptions }} ## Task Convert the following invariants to Datalog rules:
-
[60]
"{{ invariant_2 }}" Output only the Datalog code, no explanation. Figure 10: Prompt template for invariant synthesis. Conference’17, July 2017, Washington, DC, USA Li et al. You are a test case generator for a consent enforcement system. Given a natural -language safety invariant and the tool schemas available in the current MCP session, generate test cas...
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.