Recognition: 2 theorem links
· Lean TheoremAgent-BRACE: Decoupling Beliefs from Actions in Long-Horizon Tasks via Verbalized State Uncertainty
Pith reviewed 2026-05-13 02:29 UTC · model grok-4.3
The pith
LLM agents improve long-horizon performance by 14.5 percent when they track beliefs as natural language claims labeled with verbal certainty instead of raw history.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
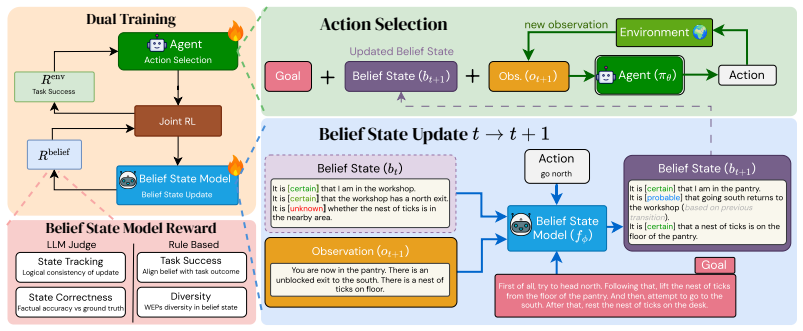
Agent-BRACE decouples the LLM agent into a belief state model that produces a set of atomic natural language claims about unobserved environment attributes, each annotated with an ordinal verbalized certainty label, and a separate policy model that selects actions conditioned only on this structured belief; the two models are jointly optimized via reinforcement learning, yielding average absolute gains of 14.5 percent and 5.3 percent on two model sizes while keeping context length near constant across episode length.
What carries the argument
The structured belief approximation: a list of atomic natural language claims each paired with a verbalized certainty label that compactly encodes the posterior over hidden state attributes.
If this is right
- The policy learns to act under explicit uncertainty without needing to reprocess the entire interaction history at every step.
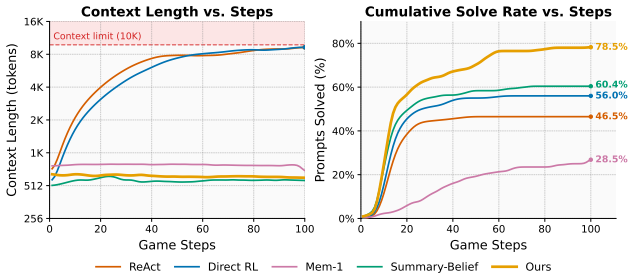
- Context window size stays bounded and independent of episode length.
- Belief representations become better calibrated as more observations arrive during an episode.
- The approach outperforms standard reinforcement-learning baselines on long-horizon embodied language tasks.
Where Pith is reading between the lines
- The same verbalized-claim format could be tested in non-embodied planning domains where state uncertainty also accumulates over many steps.
- Ablating the ordinal labels while keeping the claims would show whether the certainty annotations are necessary for the observed gains.
- The method might combine with external vector stores to handle environments whose state space exceeds what fits in a single belief list.
Load-bearing premise
The verbalized natural language claims and their certainty labels form a sufficient and faithful stand-in for the true posterior distribution over unobserved environment attributes.
What would settle it
An ablation that replaces the structured belief input with the raw accumulating history and measures whether task success drops to the level of the non-belief baselines while context length begins to grow again.
Figures




read the original abstract
Large language models (LLMs) are increasingly deployed on long-horizon tasks in partially observable environments, where they must act while inferring and tracking a complex environment state over many steps. This leads to two challenges: partial observability requires maintaining uncertainty over unobserved world attributes, and long interaction history causes context to grow without bound, diluting task-relevant information. A principled solution to both challenges is a belief state: a posterior distribution over environment states given past observations and actions, which compactly encodes history for decision making regardless of episode length. In LLM agents, however, the open-ended nature of text makes it unclear how to represent such a distribution. Therefore, we introduce Agent-BRACE: Agent Belief state Representation via Abstraction and Confidence Estimation, a method that decouples an LLM agent into a belief state model and a policy model, jointly optimized via reinforcement learning. The belief state model produces a structured approximation of the belief distribution: a set of atomic natural language claims about the environment, each annotated with an ordinal verbalized certainty label ranging from certain to unknown. The policy model conditions on this compact, structured approximate belief rather than the full history, learning to select actions under explicit uncertainty. Across long-horizon, partially observable embodied language environments, Agent-BRACE achieves an average absolute improvement of +14.5% (Qwen2.5-3B-Instruct) and +5.3% (Qwen3-4B-Instruct), outperforming strong RL baselines while maintaining a near-constant context window independent of episode length. Further analysis shows that the learned belief becomes increasingly calibrated over the course of an episode as evidence accumulates.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Agent-BRACE, which decouples an LLM agent for long-horizon partially observable embodied tasks into a belief-state model and a policy model jointly optimized via reinforcement learning. The belief model represents the posterior as a structured set of atomic natural-language claims about unobserved environment attributes, each annotated with an ordinal verbalized certainty label (certain to unknown). The policy conditions only on this compact belief rather than raw history, yielding a constant-size context window. Experiments report average absolute gains of +14.5% (Qwen2.5-3B-Instruct) and +5.3% (Qwen3-4B-Instruct) over strong RL baselines, together with increasing calibration of the learned belief over episode length.
Significance. If the verbalized atomic-claim representation proves a faithful and sufficient approximation to the true posterior, the method offers a principled route to scalable uncertainty handling and bounded context in LLM agents operating in POMDPs. The reported performance deltas and calibration trend would then constitute concrete evidence that explicit belief tracking can outperform history-conditioned baselines. The work's value therefore hinges on whether the chosen belief format actually preserves the information needed for effective long-horizon decision making.
major comments (3)
- [§4 Experiments] §4 (Experiments) and Table 2: the central performance claims (+14.5 % and +5.3 % absolute improvement) are presented without the environments, exact baseline implementations, number of seeds, statistical significance tests, or ablation isolating the belief model from incidental prompting effects; these details are required to establish that the gains arise from the proposed decoupling rather than other factors.
- [§3.2 Belief State Model] §3.2 (Belief State Model): the claim that a finite list of atomic natural-language claims with coarse ordinal certainty labels constitutes a sufficient proxy for the posterior over unobserved attributes is load-bearing for the entire approach, yet no quantitative evaluation of coverage, fidelity against ground-truth state distributions, or handling of combinatorial latent interactions is supplied.
- [§5 Analysis] §5 (Analysis): while the text states that the learned belief becomes “increasingly calibrated,” no metric is given that directly compares the verbalized certainty labels to actual posterior probabilities or that tests for omitted attributes that could affect downstream policy performance.
minor comments (2)
- [§3.2] The exact ordinal vocabulary and verbalization template used for certainty labels should be stated explicitly in §3.2 rather than left to the appendix.
- [Figure 3] Figure 3 (context-length plot) would benefit from error bars or per-episode variance to confirm that the near-constant window holds across all tested horizons.
Simulated Author's Rebuttal
We are grateful to the referee for their careful reading and valuable feedback on our work. We have carefully considered each major comment and provide detailed responses below. We will make the suggested revisions to improve the clarity and rigor of the manuscript.
read point-by-point responses
-
Referee: [§4 Experiments] §4 (Experiments) and Table 2: the central performance claims (+14.5 % and +5.3 % absolute improvement) are presented without the environments, exact baseline implementations, number of seeds, statistical significance tests, or ablation isolating the belief model from incidental prompting effects; these details are required to establish that the gains arise from the proposed decoupling rather than other factors.
Authors: We agree that these details are essential for reproducibility and to substantiate that gains arise from the belief-policy decoupling. In the revised manuscript we will expand §4 and Table 2 with: full environment descriptions and task specifications; precise baseline implementations (including any shared prompting templates); the number of random seeds (5 seeds for all runs); statistical significance tests (paired t-tests with p-values reported); and a new ablation comparing Agent-BRACE against a history-conditioned policy that uses equivalent prompt engineering but no explicit belief state. These additions will isolate the contribution of the proposed decoupling. revision: yes
-
Referee: [§3.2 Belief State Model] §3.2 (Belief State Model): the claim that a finite list of atomic natural-language claims with coarse ordinal certainty labels constitutes a sufficient proxy for the posterior over unobserved attributes is load-bearing for the entire approach, yet no quantitative evaluation of coverage, fidelity against ground-truth state distributions, or handling of combinatorial latent interactions is supplied.
Authors: We acknowledge that direct quantitative validation of the belief approximation would strengthen the central claim. While downstream task success and the observed calibration trend provide indirect support, we will add in the revision: coverage metrics reporting the fraction of ground-truth unobserved attributes explicitly captured by the atomic claims; fidelity checks by comparing belief samples against held-out observations where ground-truth distributions are available; and an analysis of combinatorial interactions with concrete examples from the environments illustrating how the policy reasons over the structured claims. These evaluations will be reported in an expanded §3.2. revision: yes
-
Referee: [§5 Analysis] §5 (Analysis): while the text states that the learned belief becomes “increasingly calibrated,” no metric is given that directly compares the verbalized certainty labels to actual posterior probabilities or that tests for omitted attributes that could affect downstream policy performance.
Authors: We will revise §5 to include quantitative calibration metrics. We will bin episodes by verbalized certainty label and report empirical accuracy (e.g., fraction of correct downstream predictions or actions) for each bin, providing a direct proxy comparison to posterior probability. We will also analyze omitted attributes by identifying episodes with potential missing claims, measuring policy performance degradation in those cases, and reporting the frequency and impact of such omissions. These additions will give concrete evidence for the calibration trend. revision: yes
Circularity Check
No circularity: empirical RL procedure with external validation
full rationale
The paper introduces Agent-BRACE as an empirical architecture that decouples belief modeling (via atomic NL claims with ordinal certainty labels) from policy learning, with both components jointly trained via reinforcement learning on long-horizon POMDP tasks. Reported gains (+14.5% and +5.3%) are measured against external RL baselines in embodied environments, not derived from any equation or definition that reduces the output to the input by construction. No mathematical derivations, uniqueness theorems, or self-citations appear in the provided abstract or method description that would force the result. The central claim remains an experimental outcome rather than a tautological restatement of the method's own representation.
Axiom & Free-Parameter Ledger
free parameters (1)
- Choice of ordinal certainty vocabulary
axioms (2)
- domain assumption LLMs can generate and maintain useful structured approximations of environment belief distributions in natural language
- domain assumption Joint RL optimization of belief and policy models yields calibrated beliefs and improved action selection
invented entities (1)
-
Structured belief as set of atomic natural language claims each annotated with verbalized ordinal certainty
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearThe belief state model produces a structured approximation of the belief distribution: a set of atomic natural language claims about the environment, each annotated with an ordinal verbalized certainty label ranging from certain to unknown.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearAgent-BRACE decouples an LLM agent into a belief state model and a policy model, jointly optimized via reinforcement learning.
Reference graph
Works this paper leans on
-
[1]
Evaluating long-context reasoning in llm-based webagents.arXiv preprint arXiv:2512.04307,
Andy Chung, Yichi Zhang, Kaixiang Lin, Aditya Rawal, Qiaozi Gao, and Joyce Chai. Evaluating long-context reasoning in llm-based webagents.arXiv preprint arXiv:2512.04307,
-
[2]
Mastering Atari with Discrete World Models
Danijar Hafner, Timothy Lillicrap, Mohammad Norouzi, and Jimmy Ba. Mastering atari with discrete world models.arXiv preprint arXiv:2010.02193,
work page internal anchor Pith review arXiv 2010
-
[3]
Pabu: Progress-aware belief update for efficient llm agents.arXiv preprint arXiv:2602.09138,
Haitao Jiang, Lin Ge, Hengrui Cai, and Rui Song. Pabu: Progress-aware belief update for efficient llm agents.arXiv preprint arXiv:2602.09138,
-
[4]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
URL https://arxiv.org/abs/2310.06770. Leslie Pack Kaelbling, Michael L Littman, and Anthony R Cassandra. Planning and acting in partially observable stochastic domains.Artificial intelligence, 101(1-2):99–134,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Emergent world beliefs: Exploring transformers in stochastic games.arXiv preprint arXiv:2512.23722,
Adam Kamel, Tanish Rastogi, Michael Ma, Kailash Ranganathan, and Kevin Zhu. Emergent world beliefs: Exploring transformers in stochastic games.arXiv preprint arXiv:2512.23722,
-
[6]
Minki Kang, Wei-Ning Chen, Dongge Han, Huseyin A Inan, Lukas Wutschitz, Yanzhi Chen, Robert Sim, and Saravan Rajmohan. Acon: Optimizing context compression for long-horizon llm agents. arXiv preprint arXiv:2510.00615,
-
[7]
Taming overconfidence in llms: Reward calibration in rlhf.arXiv preprint arXiv:2410.09724,
Jixuan Leng, Chengsong Huang, Banghua Zhu, and Jiaxin Huang. Taming overconfidence in llms: Reward calibration in rlhf.arXiv preprint arXiv:2410.09724,
-
[8]
Aly Lidayan, Jakob Bjorner, Satvik Golechha, Kartik Goyal, and Alane Suhr. Abbel: Llm agents acting through belief bottlenecks expressed in language.arXiv preprint arXiv:2512.20111,
-
[9]
Teaching models to express their uncertainty in words
10 Stephanie Lin, Jacob Hilton, and Owain Evans. Teaching models to express their uncertainty in words.arXiv preprint arXiv:2205.14334,
-
[10]
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha. The ai scientist: Towards fully automated open-ended scientific discovery.arXiv preprint arXiv:2408.06292,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
AlphaEvolve: A coding agent for scientific and algorithmic discovery
Alexander Novikov, Ngân V˜u, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wag- ner, Sergey Shirobokov, Borislav Kozlovskii, Francisco JR Ruiz, Abbas Mehrabian, et al. Alphae- volve: A coding agent for scientific and algorithmic discovery.arXiv preprint arXiv:2506.13131,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
URLhttps://arxiv.org/abs/2505.09388. Nikolai Rozanov and Marek Rei. Stateact: Enhancing llm base agents via self-prompting and state- tracking. InProceedings of the 1st Workshop for Research on Agent Language Models (REALM 2025), pages 367–385,
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
High-Dimensional Continuous Control Using Generalized Advantage Estimation
John Schulman, Philipp Moritz, Sergey Levine, Michael Jordan, and Pieter Abbeel. High-dimensional continuous control using generalized advantage estimation.arXiv preprint arXiv:1506.02438,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Proximal Policy Optimization Algorithms
URLhttps://arxiv.org/abs/1707.06347. Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathemat- ical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
ALFRED : A benchmark for interpreting grounded instructions for everyday tasks
Mohit Shridhar, Jesse Thomason, Daniel Gordon, Yonatan Bisk, Winson Han, Roozbeh Mottaghi, Luke Zettlemoyer, and Dieter Fox. ALFRED: A Benchmark for Interpreting Grounded Instructions for Everyday Tasks. InThe IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020a. URLhttps://arxiv.org/abs/1912.01734. Mohit Shridhar, Xingdi Yuan, Marc-Al...
-
[16]
11 Katherine Tian, Eric Mitchell, Allan Zhou, Archit Sharma, Rafael Rafailov, Huaxiu Yao, Chelsea Finn, and Christopher D Manning. Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pag...
work page 2023
-
[17]
ISSN 2470-2986. doi: 10.1162/opmi_a_00066. URLhttps://doi.org/10.1162/opmi_a_00066. Ruiyi Wang and Prithviraj Ammanabrolu. A practitioner’s guide to multi-turn agentic reinforcement learning,
-
[18]
Miao Xiong, Zhiyuan Hu, Xinyang Lu, Yifei Li, Jie Fu, Junxian He, and Bryan Hooi
URLhttps://arxiv.org/abs/2510.01132. Miao Xiong, Zhiyuan Hu, Xinyang Lu, Yifei Li, Jie Fu, Junxian He, and Bryan Hooi. Can llms express their uncertainty? an empirical evaluation of confidence elicitation in llms.arXiv preprint arXiv:2306.13063,
-
[19]
A-MEM: Agentic Memory for LLM Agents
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. A-mem: Agentic memory for llm agents.arXiv preprint arXiv:2502.12110,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering
URLhttps://arxiv.org/abs/2405.15793. Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
arXiv preprint arXiv:2507.02259 , year=
Hongli Yu, Tinghong Chen, Jiangtao Feng, Jiangjie Chen, Weinan Dai, Qiying Yu, Ya-Qin Zhang, Wei-Ying Ma, Jingjing Liu, Mingxuan Wang, et al. Memagent: Reshaping long-context llm with multi-conv rl-based memory agent.arXiv preprint arXiv:2507.02259,
-
[22]
Zhenhang Yuan, Shenghai Yuan, and Lihua Xie. Rpms: Enhancing llm-based embodied planning through rule-augmented memory synergy.arXiv preprint arXiv:2603.17831,
-
[23]
Memory as Action: Autonomous Context Curation for Long-Horizon Agentic Tasks
Yuxiang Zhang, Jiangming Shu, Ye Ma, Xueyuan Lin, Shangxi Wu, and Jitao Sang. Memory as action: Autonomous context curation for long-horizon agentic tasks.arXiv preprint arXiv:2510.12635,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
URLhttps://arxiv.org/abs/2601. 04525. Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, et al. Webarena: A realistic web environment for building autonomous agents.arXiv preprint arXiv:2307.13854,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
MEM1: Learning to Synergize Memory and Reasoning for Efficient Long-Horizon Agents
Zijian Zhou, Ao Qu, Zhaoxuan Wu, Sunghwan Kim, Alok Prakash, Daniela Rus, Jinhua Zhao, Bryan Kian Hsiang Low, and Paul Pu Liang. Mem1: Learning to synergize memory and reasoning for efficient long-horizon agents.arXiv preprint arXiv:2506.15841,
work page internal anchor Pith review arXiv
-
[26]
URL https://arxiv.org/abs/2510.12264. 12 A Belief State Structure InTextWorldenvironment, the belief state tracks five critical dimensions: (i) the agent’s current location, (ii) topological room connections, (iii) states of observed objects, (iv) inventory contents, and (v) progress relative to specific sub-goals. To ensure a clean separation of concerns...
-
[27]
assesses whether new information in ok is incorporated in the updated belief. This reward counts, Nnew: new facts in ot correctly added; Nmissing: new facts absent or wrong in bt; Nstale: prior beliefs contradicted by ot but left unchanged; Ntotal: total claims in bt. The reward is the product of coverage of new information and freshness of retained belie...
work page 2025
-
[28]
G Belief States are underconfident but improve over training Fig. 5 analyzes the calibration of WEP labels at early (steps 0-4) and late (steps 10-15) training stages. For each WEP label emitted by the belief state model, we measure the empirical truth rate – the fraction of claims carrying that label that are independently verified as true by the LLM jud...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.