Recognition: no theorem link
Adaptive Teacher Exposure for Self-Distillation in LLM Reasoning
Pith reviewed 2026-05-13 01:58 UTC · model grok-4.3
The pith
Adaptive control of how much reference reasoning the teacher sees during self-distillation improves LLM performance on math tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Treating teacher exposure as a learnable control variable via a Beta-policy controller conditioned on training-state statistics and optimized by a discounted learning-progress reward produces higher student reasoning accuracy than the conventional choice of always revealing the full reference.
What carries the argument
A Beta-policy controller that samples the fraction of reference reasoning to expose to the teacher for a fixed hold window of student updates and receives a reward based on the student's subsequent improvement.
If this is right
- Full exposure of the reference reasoning is not reliably the best choice for student learning.
- Mismatch between teacher targets and student competence grows monotonically with the amount of privileged reasoning shown.
- Optimizing exposure with a future-progress reward addresses the delayed credit assignment problem in on-policy distillation.
- The adaptive method delivers consistent gains over OPSD and other baselines on AIME 24, AIME 25, and HMMT 25 for models ranging from 1.7B to 8B parameters.
Where Pith is reading between the lines
- The same controller design could be applied to other training-time decisions such as rollout length or data filtering in reasoning pipelines.
- If the compact training statistics omit key signals, the learned policy may fail to generalize beyond the training distribution of math problems.
- The delayed-reward formulation might transfer to other credit-assignment settings in LLM post-training where immediate loss is a poor signal.
Load-bearing premise
A lightweight Beta-policy controller optimized via a discounted learning-progress reward on compact training-state statistics will reliably produce exposure decisions that improve long-term student performance without introducing training instability or benchmark-specific overfitting.
What would settle it
An ablation in which the adaptive controller is replaced by fixed full exposure or random sampling and the same models are retrained on the identical benchmarks would show equal or higher scores.
Figures



read the original abstract
On-policy self-distillation has become a strong recipe for LLM reasoning, where a privileged teacher supervises the student's own rollouts while conditioning on the reference solution. A design choice shared by nearly all such methods, however, has gone unquestioned: the teacher always sees the full reference reasoning. We argue that this default itself is part of the problem and identify a teacher-side exposure mismatch: when the teacher conditions on reasoning far beyond the student's current competence, the resulting token targets become too strong to absorb. A controlled fixed-exposure sweep makes this concrete on two fronts: 1) full exposure is not reliably the best choice, and 2) student-teacher mismatch grows monotonically as the teacher sees more privileged reasoning. This motivates treating teacher exposure not as a fixed hyperparameter but as a learnable training-time control variable. We therefore propose Adaptive Teacher Exposure for Self-Distillation (ATESD). ATESD models the reveal ratio with a lightweight Beta-policy controller conditioned on compact training-state statistics, and uses one sampled exposure for a short hold window of student updates. To make this exposure controller learnable, we optimize it with a discounted learning-progress reward that scores each held decision by its effect on the student's future improvement rather than its immediate loss change, addressing the delayed credit assignment induced by on-policy distillation. Experiments on AIME 24, AIME 25, and HMMT 25 across Qwen3-{1.7B, 4B, 8B} show that ATESD consistently outperforms competitive self-distillation and RL baselines, improving over OPSD by +0.95, +2.05, and +2.33 Average@12 points respectively, and establishing adaptive teacher exposure as an effective new axis for reasoning self-distillation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that full teacher exposure to reference reasoning in on-policy self-distillation for LLMs creates an exposure mismatch that hinders student learning. It proposes ATESD, which replaces fixed exposure with a lightweight Beta-policy controller conditioned on compact training-state statistics; the controller is optimized via a discounted learning-progress reward that evaluates each exposure decision by its effect on future student improvement over a short hold window. Experiments on AIME 24, AIME 25, and HMMT 25 across Qwen3-1.7B/4B/8B models report consistent gains over OPSD and other self-distillation/RL baselines (+0.95 to +2.33 Average@12).
Significance. If the performance gains prove robust, the work identifies a previously unexamined axis—adaptive teacher exposure—in reasoning self-distillation and demonstrates that a simple learnable controller can outperform fixed-exposure and standard RL baselines. The delayed-credit formulation and use of compact state statistics are practical contributions that could generalize beyond the reported math benchmarks.
major comments (2)
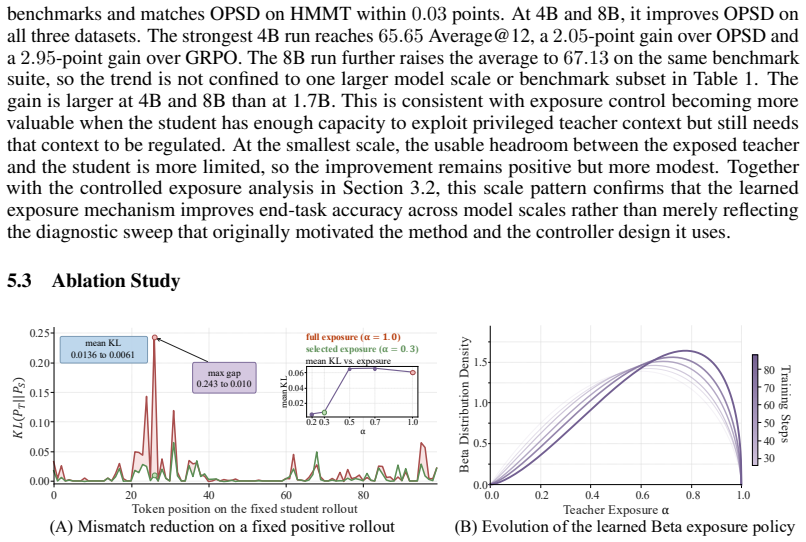
- [Experiments] Experimental section: the central performance claim (consistent outperformance of OPSD by +0.95/+2.05/+2.33 Average@12 on AIME 24/25 and HMMT 25) is presented as summarized deltas without reported standard deviations, number of independent runs, statistical significance tests, or exact baseline re-implementations and data splits. This leaves the robustness of the gains difficult to evaluate.
- [Method] Method (controller optimization): the discounted learning-progress reward directly scores future improvement on the same AIME/HMMT evaluation distribution used for final reporting. No cross-benchmark transfer experiments, hold-out validation of the controller, or ablation isolating the reward from benchmark-specific difficulty curves are described, raising the possibility that reported gains reflect reduced mismatch on these particular rollouts rather than a general exposure principle.
minor comments (2)
- [Abstract] The abstract and introduction refer to “competitive self-distillation and RL baselines” without naming the full set of comparators (e.g., specific RL variants or prior self-distillation methods); an explicit list would improve clarity.
- [Method] Notation for the Beta-policy parameters and the exact form of the compact training-state statistics could be formalized in a single equation or table for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on experimental reporting and the generality of the proposed controller. We address each major comment below and have updated the manuscript to incorporate additional details, statistical reporting, and new experiments where feasible.
read point-by-point responses
-
Referee: [Experiments] Experimental section: the central performance claim (consistent outperformance of OPSD by +0.95/+2.05/+2.33 Average@12 on AIME 24/25 and HMMT 25) is presented as summarized deltas without reported standard deviations, number of independent runs, statistical significance tests, or exact baseline re-implementations and data splits. This leaves the robustness of the gains difficult to evaluate.
Authors: We agree that these details are necessary to properly evaluate robustness. The original manuscript omitted them for space reasons, but the experiments were run with multiple seeds. In the revised version we now report means and standard deviations over three independent runs for all main results, include paired t-test p-values demonstrating statistical significance of the reported gains, and provide full details on baseline re-implementations together with exact data splits and random seeds in a new appendix section. revision: yes
-
Referee: [Method] Method (controller optimization): the discounted learning-progress reward directly scores future improvement on the same AIME/HMMT evaluation distribution used for final reporting. No cross-benchmark transfer experiments, hold-out validation of the controller, or ablation isolating the reward from benchmark-specific difficulty curves are described, raising the possibility that reported gains reflect reduced mismatch on these particular rollouts rather than a general exposure principle.
Authors: The concern is well-taken: the learning-progress reward is computed from student accuracy on the target benchmark distributions during the short hold window. While the controller itself receives only compact, task-agnostic state features (recent loss, gradient statistics, rollout entropy), this still leaves open the question of whether the gains are benchmark-specific. In the revision we have added (i) cross-benchmark transfer results in which a controller trained on AIME rollouts is deployed on HMMT and vice versa, (ii) an internal hold-out split of the benchmark problems used solely for reward computation during controller updates, and (iii) an ablation replacing the delayed learning-progress reward with an immediate-loss baseline. These new results are presented in an expanded experimental section and support that the benefit arises from adaptive exposure rather than overfitting to particular benchmark difficulty curves. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's derivation begins with an empirical fixed-exposure sweep establishing that full teacher reference is suboptimal and mismatch increases with exposure; this is an independent observation, not a fitted input. It then defines a new lightweight Beta-policy controller and a discounted learning-progress reward whose target (future student improvement over hold windows) is specified externally to any model parameters or prior results. The reported gains over OPSD and RL baselines are measured on held-out evaluation rollouts rather than quantities forced by construction or by a self-citation chain. No equations, uniqueness theorems, or ansatzes are shown to reduce to self-referential definitions, and the method introduces an independent optimization axis whose validity is tested rather than presupposed.
Axiom & Free-Parameter Ledger
free parameters (2)
- Beta-policy parameters
- Reward discount factor
axioms (2)
- domain assumption On-policy self-distillation with teacher conditioning on reference solutions is a viable base recipe for improving LLM reasoning.
- ad hoc to paper Compact training-state statistics are sufficient to condition an effective exposure policy.
invented entities (1)
-
Beta-policy controller
no independent evidence
Reference graph
Works this paper leans on
-
[1]
On-policy distillation of language models: Learning from self-generated mistakes
Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sabela Ramos Garea, Matthieu Geist, and Olivier Bachem. On-policy distillation of language models: Learning from self-generated mistakes. InICLR, 2024
work page 2024
-
[2]
On-policy distillation of language models: Learning from self- generated mistakes
Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sabela Ramos, Matthieu Geist, and Olivier Bachem. On-policy distillation of language models: Learning from self- generated mistakes. 2024
work page 2024
-
[3]
Scheduled sampling for sequence prediction with recurrent neural networks
Samy Bengio, Oriol Vinyals, Navdeep Jaitly, and Noam Shazeer. Scheduled sampling for sequence prediction with recurrent neural networks. InAdvances in Neural Information Processing Systems, pages 1171–1179, 2015
work page 2015
-
[4]
Yoshua Bengio, Jérôme Louradour, Ronan Collobert, and Jason Weston. Curriculum learning. InICML, 2009
work page 2009
-
[5]
Soda: Semi on-policy black-box distillation for large language models.arXiv preprint, 2026
David Chen, Omar Khattab, and Matei Zaharia. Soda: Semi on-policy black-box distillation for large language models.arXiv preprint, 2026
work page 2026
-
[6]
arXiv preprint arXiv:2603.23871 , year =
Ken Ding. Hdpo: Hybrid distillation policy optimization via privileged self-distillation.arXiv preprint arXiv:2603.23871, 2026
-
[7]
MiniLLM: Knowledge distillation of large language models
Yuxian Gu, Li Dong, Furu Wei, and Minlie Huang. MiniLLM: Knowledge distillation of large language models. InICLR, 2024
work page 2024
-
[8]
OpenThoughts: Data Recipes for Reasoning Models
Etash Guha et al. Openthoughts: Data recipes for reasoning models.arXiv preprint arXiv:2506.04178, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, DeJian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[11]
Dist+: Knowledge distillation from a stronger adaptive teacher.arXiv preprint, 2025
Xiaoqi Huang, Jie Zhao, Bingchen Han, Jian Li, Xiao Wang, Aohan Zeng, Wendi Zhao, Yuxiao Dong, and Jie Tang. Dist+: Knowledge distillation from a stronger adaptive teacher.arXiv preprint, 2025
work page 2025
-
[12]
SDPO: Self-distillation with privileged observations.arXiv preprint, 2026
Jonas Hübotter et al. SDPO: Self-distillation with privileged observations.arXiv preprint, 2026
work page 2026
-
[13]
Dynamic temperature scheduler for knowledge distillation.arXiv preprint, 2025
Kazi Rakibul Islam, Md Sumon Islam, Syed Ahmed, and Mohammad Hasan. Dynamic temperature scheduler for knowledge distillation.arXiv preprint, 2025
work page 2025
-
[14]
Jian Jin, Liujun Chen, Ge Luo, Yitong Chen, Shuanglong Liang, and Linjun Qian. Adversarially adaptive temperatures for decoupled knowledge distillation with application to classification and regression.arXiv preprint, 2025
work page 2025
-
[15]
Distillm: Towards streamlined distillation for large language models
Jongwoo Ko, Sungnyun Kim, Tianyi Chen, and Se-Young Yun. Distillm: Towards streamlined distillation for large language models. 2024
work page 2024
-
[16]
Xiaotian Li, Zheng Wang, Man Luo, Shuzhan Chen, Jianxun Li, Kai Zhang, Yuxuan Dong, and Jie Liu. Rethinking on-policy distillation of large language models: Phenomenology, mechanisms, and optimal practices.arXiv preprint, 2026
work page 2026
-
[17]
Curriculum temperature for knowledge distillation.arXiv preprint, 2023
Yuxuan Li, Xu Shen, , et al. Curriculum temperature for knowledge distillation.arXiv preprint, 2023
work page 2023
-
[18]
Adaptive tempera- ture based on logits correlation in knowledge distillation.arXiv preprint, 2025
Takuya Matsuyama, Tomoki Shibata, Jumpei Tanaka, and Yoshiaki Uchida. Adaptive tempera- ture based on logits correlation in knowledge distillation.arXiv preprint, 2025
work page 2025
-
[19]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in Neural Information Processing Systems, 35:27730–27744, 2022. 10
work page 2022
-
[20]
Qwen Team. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. arXiv preprint arXiv:2305.18290, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Stéphane Ross, Geoffrey Gordon, and Drew Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning.AISTATS, 2011
work page 2011
-
[23]
CRISP: Compressed Reasoning via Iterative Self-Policy Distillation
Hejian Sang, Yuanda Xu, Zhengze Zhou, Ran He, Zhipeng Wang, and Jiachen Sun. On-policy self-distillation for reasoning compression.arXiv preprint arXiv:2603.05433, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[24]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[25]
Amrith Setlur, Chirag Nagpal, Adam Fisch, Xinyang Geng, Jacob Eisenstein, Rishabh Agarwal, Hany Awadalla, David Dohan, and Aviral Kumar. Rl on incorrect synthetic data scales the efficiency of llm math reasoning by eight-fold.arXiv preprint arXiv:2406.14532, 2024
-
[26]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y .K. Li, Y . Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Self-Distillation Enables Continual Learning
Irina Shenfeld, Mehul Damani, Jonas Hübotter, and Pulkit Agrawal. Self-distillation enables continual learning.arXiv preprint arXiv:2601.19897, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
Alex Stein, Furong Huang, and Tom Goldstein. Gates: Self-distillation under privileged context with consensus gating.arXiv preprint arXiv:2602.20574, 2026
-
[29]
Hindsight credit assignment for long- horizon llm agents.arXiv preprint, 2026
Jiachen Tan, Zheng Wang, Yiran Chen, and Ziniu Liu. Hindsight credit assignment for long- horizon llm agents.arXiv preprint, 2026
work page 2026
-
[30]
Ronald J Williams. Simple statistical gradient-following algorithms for connectionist reinforce- ment learning.Machine Learning, 8(3–4):229–256, 1992
work page 1992
-
[31]
On-policy distillation of language models.arXiv preprint, 2024
Canwen Xu et al. On-policy distillation of language models.arXiv preprint, 2024
work page 2024
-
[32]
Yuzhe Xu, Yiran Chen, and Ziniu Liu. Direct reasoning optimization: Constrained rl with token-level dense reward and monotonic improvement for reasoning in llms.arXiv preprint, 2025
work page 2025
-
[33]
Distribution-aligned sequence distillation for superior long-cot reasoning.arXiv preprint, 2026
Yiran Yan, Yiran Chen, and Ziniu Liu. Distribution-aligned sequence distillation for superior long-cot reasoning.arXiv preprint, 2026
work page 2026
-
[34]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu et al. DAPO: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Self-distilled reasoner: On-policy self-distillation for large language models.Preprint,
Siyan Zhao, Zhihui Xie, Mengchen Liu, Jing Huang, Guan Pang, Feiyu Chen, and Aditya Grover. Self-distilled reasoner: On-policy self-distillation for large language models.Preprint,
-
[36]
URLhttps://arxiv.org/abs/2601.18734. 11
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.